重要链接
动机
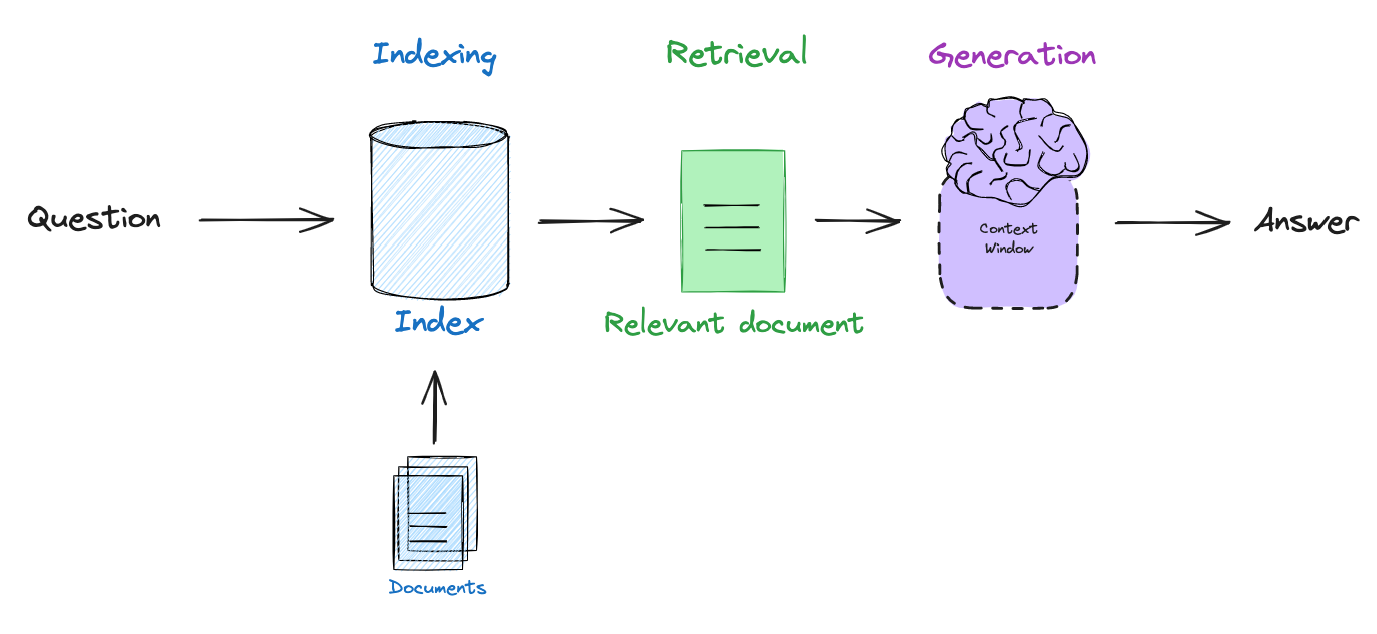
由于大多数 LLM 仅定期使用大型公共数据语料库进行训练,因此它们缺乏最新的信息和/或无法用于训练的私有数据。Retrieval augmented generation (RAG),即检索增强生成,是 LLM 应用程序开发中的核心范例,旨在通过将 LLM 连接到外部数据源来解决此问题(请参阅我们的视频系列和博客文章)。基本的 RAG 流程包括嵌入用户查询,检索与查询相关的文档,并将文档传递给 LLM 以生成基于检索到的上下文的答案。
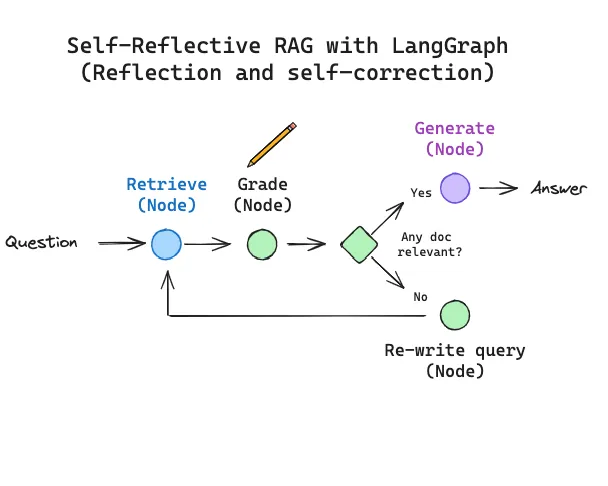
自反思 RAG
在实践中,许多人发现实施 RAG 需要围绕这些步骤进行逻辑推理:例如,我们可以询问何时检索(基于问题和索引的组成)、何时重写问题以获得更好的检索,或者何时丢弃不相关的检索文档并重新尝试检索?术语自反思 RAG (论文) 已被引入,它捕捉了使用 LLM 自我纠正低质量检索和/或生成的想法。
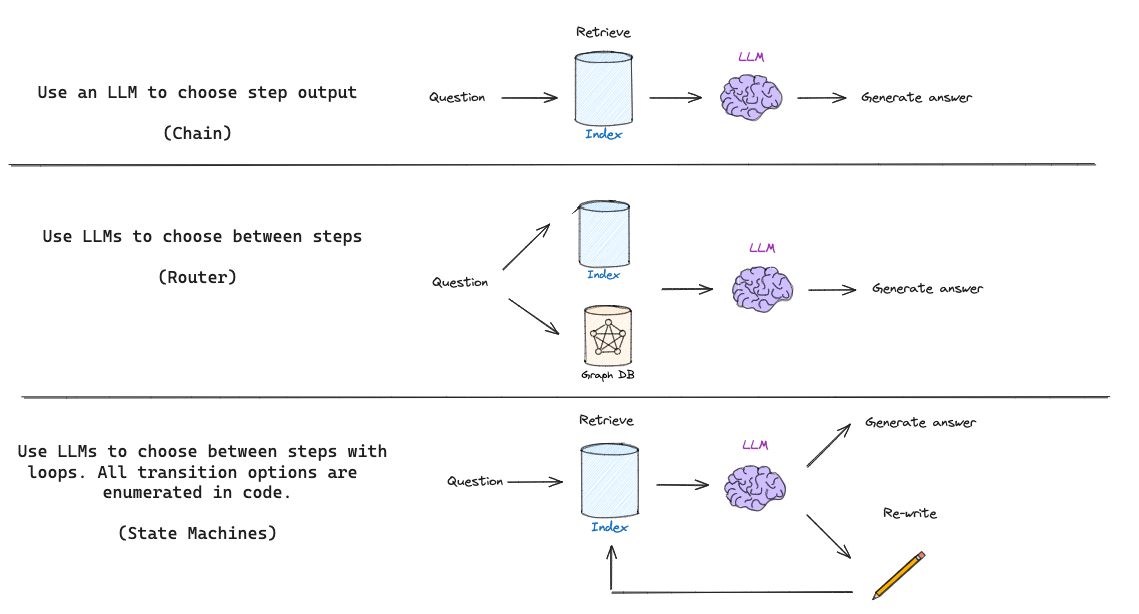
基本 RAG 流程(如上所示)仅使用链:LLM 根据检索到的文档确定要生成的内容。一些 RAG 流程使用路由,其中 LLM 例如根据问题在不同的检索器之间进行选择。但是自反思 RAG 通常需要某种反馈,重新生成问题和/或重新检索文档。状态机是第三种认知架构,它支持循环,非常适合这种情况:状态机只是让我们定义一组步骤(例如,检索、评估文档、重写查询)并设置它们之间的转换选项;例如,如果我们的检索文档不相关,则重写查询并重新检索新文档。
使用 LangGraph 的自反思 RAG
我们最近推出了 LangGraph,这是一种实现 LLM 状态机的简便方法。这为我们提供了在各种 RAG 流程的布局方面的很大灵活性,并支持更通用的 RAG “流程工程”过程,其中包含特定的决策点(例如,文档评分)和循环(例如,重试检索)。
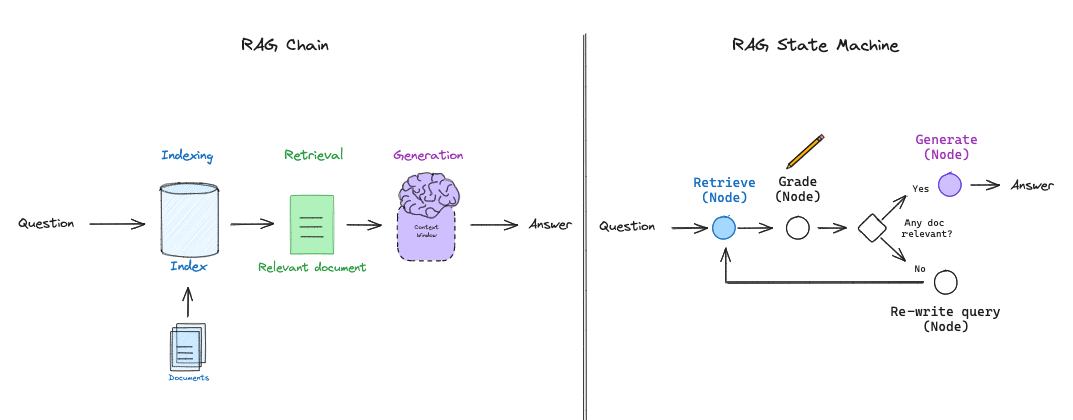
为了突出 LangGraph 的灵活性,我们将使用它来实现受两篇有趣且最新的自反思 RAG 论文 CRAG 和 Self-RAG 启发的想法。
纠正性 RAG (CRAG)
纠正性 RAG (CRAG) 引入了一些有趣的想法 (论文)
- 采用轻量级检索评估器来评估检索到的文档对于查询的整体质量,并为每个文档返回置信度评分。
- 如果向量存储检索被认为模棱两可或与用户查询无关,则执行基于网络的文档检索以补充上下文。
- 通过将检索到的文档划分为“知识条”,对每个条进行评分,并过滤掉不相关的条,来执行知识提炼。
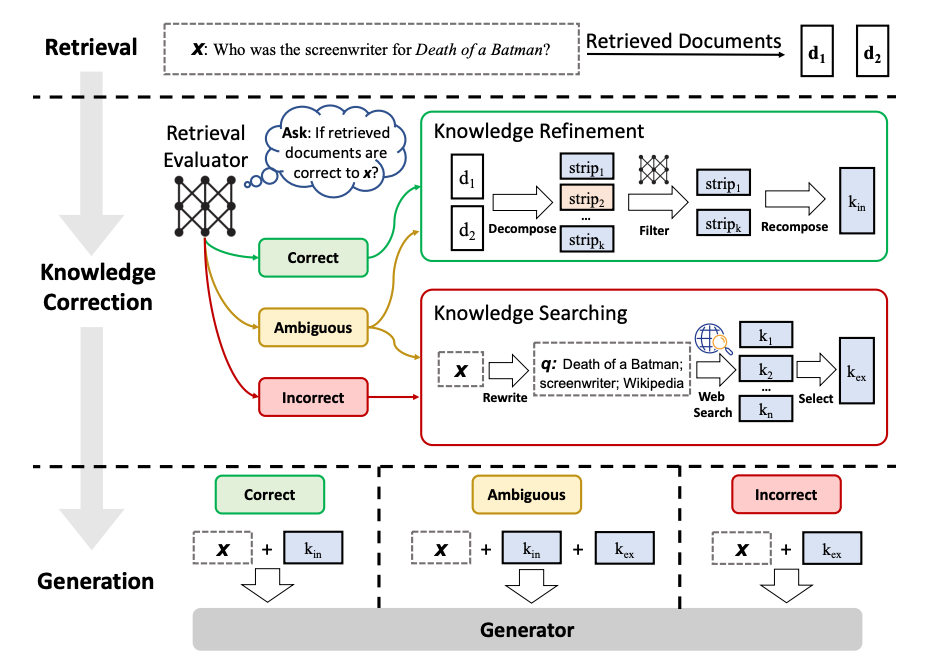
我们可以将此表示为图表,为了说明目的进行了一些简化和调整(当然,可以根据需要进行自定义和扩展)
- 作为第一步,我们将跳过知识提炼阶段。它代表了一种有趣且有价值的后处理形式,但对于理解如何在 LangGraph 中布置此工作流程并非必不可少。
- 如果任何文档不相关,我们将使用网络搜索补充检索。我们将使用Tavily Search API 进行网络搜索,它快速且方便。
- 我们将使用查询重写来优化网络搜索的查询。
- 对于二元决策,我们使用 Pydantic 对输出进行建模,并将此函数作为 OpenAI 工具提供,该工具在每次 LLM 运行时都会被调用。这使我们能够对条件边的输出进行建模,其中一致的二元逻辑至关重要。
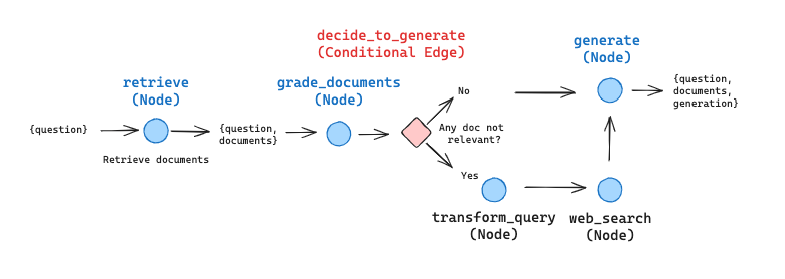
我们在示例 notebook中对此进行了布局,并索引了三篇 博客 文章。我们可以在此处看到一个 trace,突出显示了当被问及博客文章中找到的信息时的用法:我们节点之间的逻辑流程清晰地列举了出来。
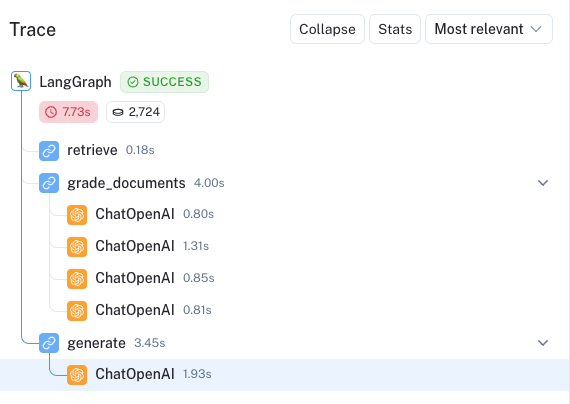
相比之下,我们提出了一个超出博客文章领域的问题。 此处的 trace 显示,我们调用了条件边的下部路径,并从 Tavily 网络搜索中收集了补充文档,用于最终生成。
Self-RAG
Self-RAG 是一种相关的方法,具有其他几个有趣的 RAG 想法 (论文)。该框架训练 LLM 生成自我反思 token,这些 token 控制 RAG 过程的各个阶段。以下是 token 的摘要
Retrievetoken 决定使用输入x (问题)ORx (问题),y (生成)检索D个 chunk。输出为yes, no, continueISRELtoken 决定段落D是否与输入 (x (问题),d (chunk)) 中的x相关,其中d在D中。输出为relevant, irrelevant。
ISSUPtoken 决定 LLM 从D中每个 chunk 生成的内容是否与该 chunk 相关。输入为x,d,y,其中d在D中。它确认y (生成)中所有值得验证的陈述都得到d的支持。输出为fully supported, partially supported, no support。ISUSEtoken 决定从D中每个 chunk 生成的内容是否是对x的有用响应。输入为x,y,其中d在D中。输出为{5, 4, 3, 2, 1}.
论文中的此表补充了以上信息

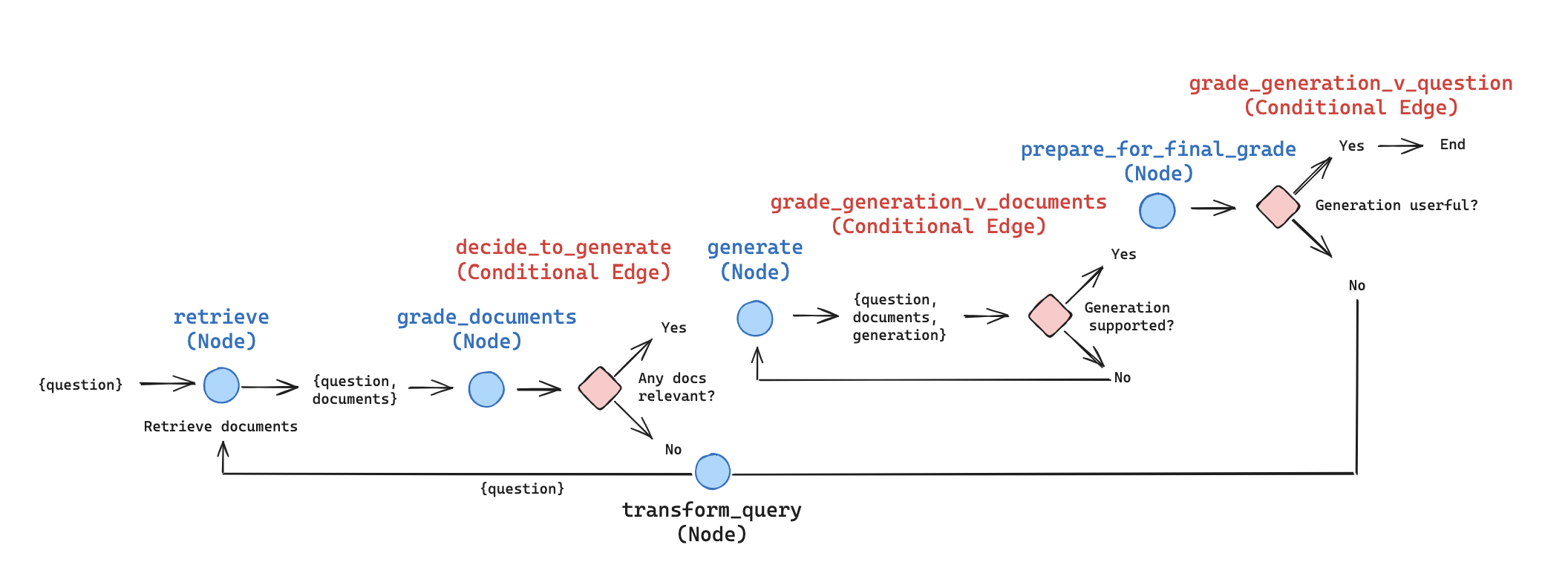
我们可以将其概述为简化的图表,以了解信息流
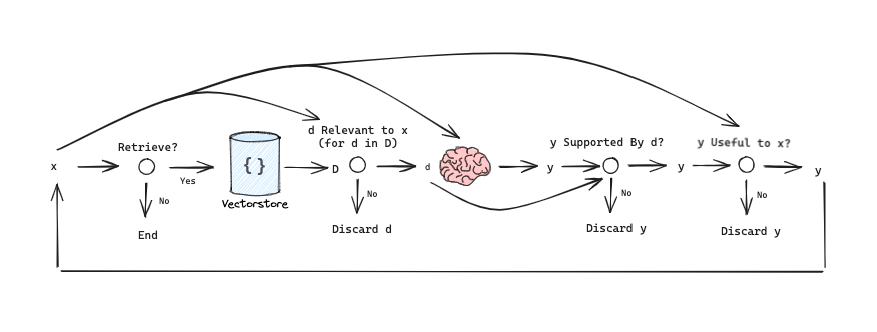
我们可以用 LangGraph 表示这个,为了说明目的进行了一些简化/调整(可以根据需要进行自定义和扩展)
- 如上所述,我们对每个检索到的文档进行评分。如果任何文档相关,我们将继续生成。如果所有文档都不相关,那么我们将转换查询以制定改进的问题并重新检索。注意:我们可以采用上面来自 CRAG(网络搜索)的想法,作为此路径中的补充节点!
- 论文将从每个 chunk 执行生成并对其进行两次评分。相反,我们从所有相关文档执行单次生成。然后根据文档(例如,为了防止幻觉)以及如上所述的答案对生成进行评分。这减少了 LLM 调用的次数并提高了延迟,并允许将更多上下文整合到生成中。当然,如果需要更多控制,则可以轻松地适应每个 chunk 生成并单独对其进行评分。
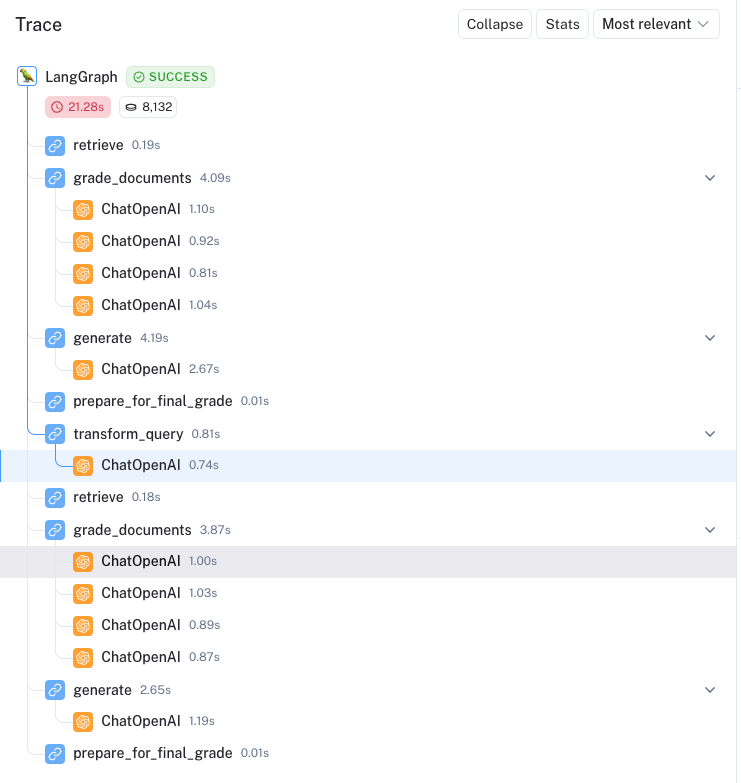
此处是一个示例 trace,突出显示了主动 RAG 自我纠正的能力。问题是 Explain how the different types of agent memory work?。所有四个文档都被认为是相关的,生成与文档的检查通过了,但生成被认为对问题没有完全用处。
然后我们看到循环重新启动,并在此处重新制定查询:How do the various types of agent memory function?。四个文档中有一个因不相关而被过滤掉 (此处)。然后生成通过了两次检查
代理内存的各种类型包括感觉记忆、短期记忆和长期记忆。感觉记忆将感觉信息的印象保留几秒钟。短期记忆用于上下文学习和提示工程。长期记忆允许代理在较长时间内保留和回忆信息,通常通过利用外部向量存储。
整个 trace 非常容易审计,节点清晰地排列出来
结论
自反思可以极大地增强 RAG,从而能够纠正低质量的检索或生成。最近的几篇 RAG 论文都侧重于这个主题,但实现这些想法可能很棘手。在这里,我们展示了 LangGraph 可以轻松用于自反思 RAG 的“流程工程”。我们为实现两篇有趣论文 Self-RAG 和 CRAG 中的想法提供了 cookbook。