LangSmith 的推出目标是让 LLM 应用程序更容易从原型走向生产。这里的主要障碍之一是提高应用程序的性能,使其比仅仅是一个 Twitter 更可靠。
有几种方法可以做到这一点。最基本的是,仔细查看数据并建立对链在何处表现不佳的直觉很有用。
- Jason Wei, OpenAI
除此之外,拥有一个测试用例数据集来运行你的链以衡量其性能是很有帮助的。接下来,你可以使用诸如少样本提示之类的技术进行上下文学习,以提高模型的性能。作为更高级的步骤,你可以在一些示例上微调模型。
请注意,所有这些技术都需要拥有特定于你的应用程序的数据点。而大多数人一开始通常没有!LLM 的主要好处之一是,与传统的机器学习相比,它们使开始构建应用程序变得异常容易——你不需要拥有数据集来训练模型,你只需开始使用 API 即可。这对于入门非常棒,但是当你开始深入研究并想要改进你的链时,会带来一些挑战。
为了帮助解决其中一些问题,我们正在发布 LangSmith 的一项新功能:数据标注队列。它旨在让用户轻松查看日志、提供关于这些日志的反馈以及从这些日志创建数据集。与此同时,我们很高兴重点介绍 langfree,这是一个来自 Hamel Husain 的 OSS 软件包,旨在在本地实现此功能的一部分。
数据标注队列
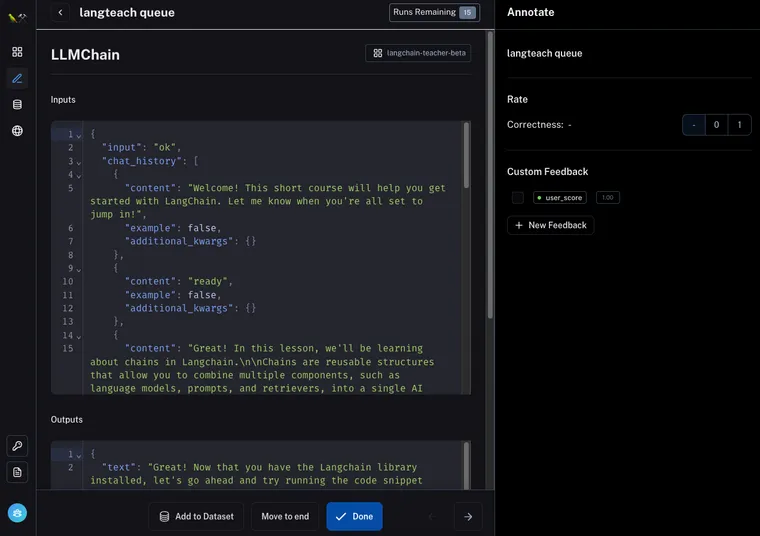
数据标注的想法是为审查来自链的日志创建理想的 UX,目的是注释它们(将它们标记为正确或不正确)或将它们添加到数据集(用于下游使用)。
通过在日志页面添加一个操作以添加到数据标注队列,我们使这变得容易实现。 通过这个,您可以根据一些过滤器轻松查询数据点,然后将它们添加到队列中。 例如,您可以过滤掉所有收到用户负面反馈的数据点(因为您想检查发生了什么)。
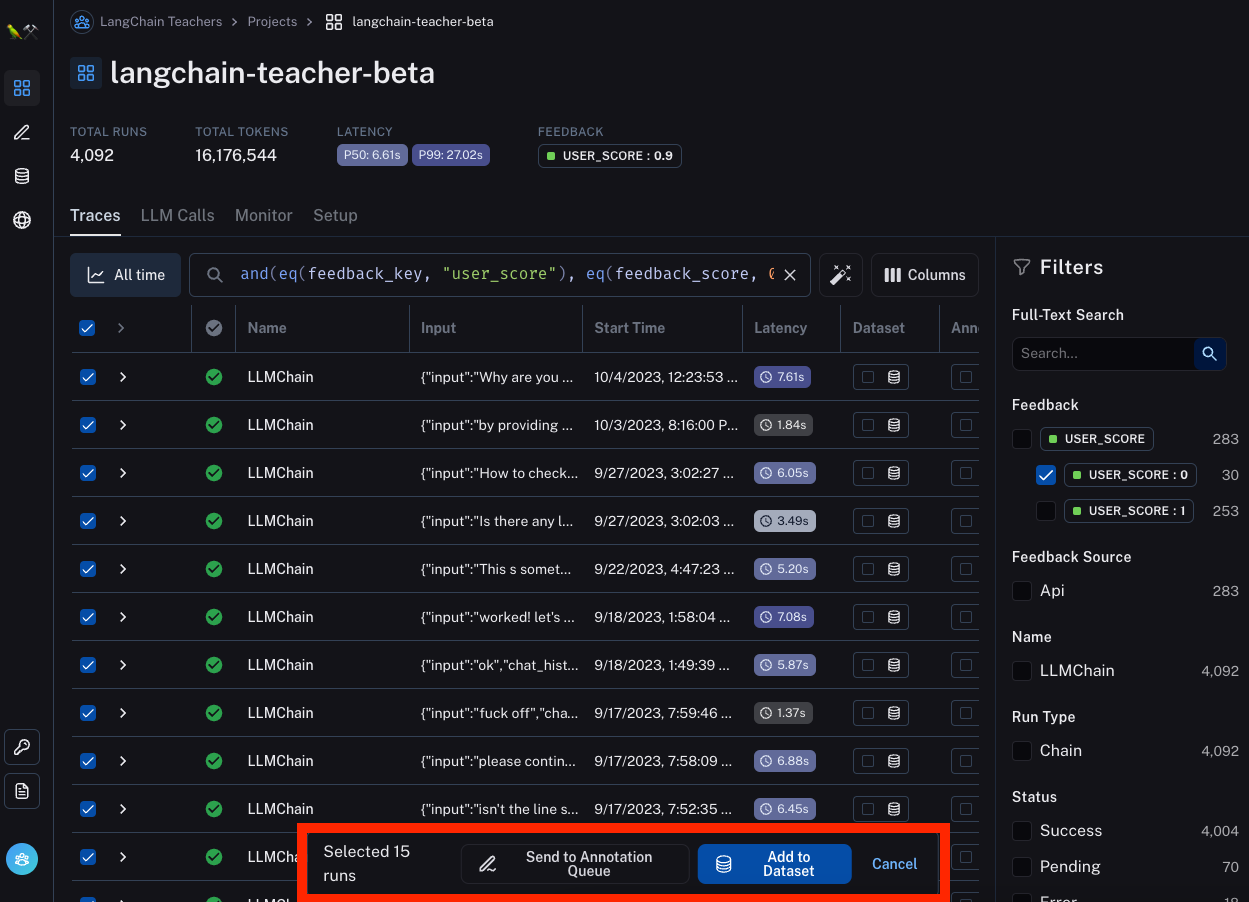
一旦进入标注队列,您可以轻松查看每个数据点。 我们设想了两个常见操作
- 在数据点上留下一些注释。 这可以是一些标签(好/坏)、一些分类(英语/西班牙语/等等)或任何东西。
- 将此数据点添加到数据集。 在执行此操作时,您可能希望在添加之前编辑数据点 - 例如,如果数据点回答不正确,您可能希望在添加之前将答案更改为正确答案。
为了支持这些操作项,我们为反馈面板(在右侧)提供了黄金位置,并使数据点的文本可以直接编辑。 请注意,如果您编辑文本,您仍然必须单击“添加到数据集”才能将其添加到数据集。
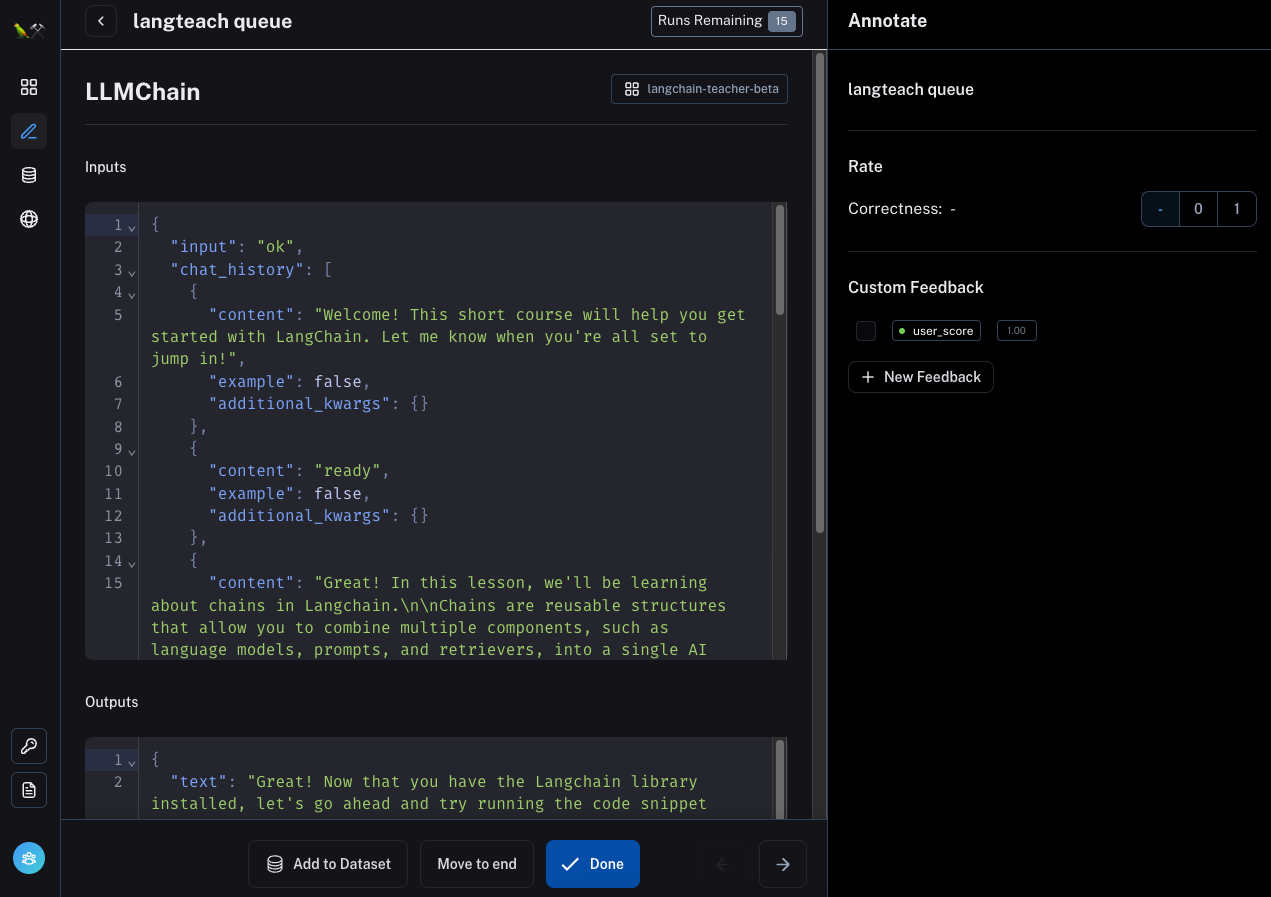
此外,您可以使用底部的按钮执行更多操作
- “移至末尾” - 将此数据点移至队列末尾,本质上是暂时忽略它,但表示您想稍后返回它
- “完成” - 标记您已完成审查特定数据点
Langfree
在发布数据标注队列的同时,我们也很高兴分享 langfree,这是一个由 Hamel Husain 开发的类似方向的开源软件包。
与数据标注队列的目标相似,这提供了一个开源替代方案,如果您想以任何方式自定义注释或数据集管理工作流程,这将很有帮助。 我们很高兴分享这一点,因为我们认识到这个旅程还处于非常早期的阶段,并且拥有用于执行这些任务的开源和可定制工具非常宝贵 - 感谢 Hamel 添加了这个!
Hamel 一直是一个出色的合作资源,一路为数据标注队列提供了很多反馈! Hamel 还运营 Parlance Labs - 我们最喜欢的合作伙伴之一 - 我们强烈建议与他合作。
结论
数据标注队列旨在使团队可以轻松地探索数据、注释示例和创建数据集。 当希望将 LLM 应用程序从原型推向生产时,这种类型的数据探索和数据集管理非常宝贵。
而且入门也不需要那么多数据点! 我们已经看到团队仅用几个示例就建立了有价值的基准。 关键在于它 (1) 针对您的用例,以及 (2) 高质量的数据点。 如果您想在此过程中获得帮助,也请随时直接联系!