重要链接
LangChain 公共基准评估笔记本
动机
检索增强生成 (RAG) 是 LLM 应用程序开发中最重要的概念之一。 多种类型 的文档可以传递到 LLM 的上下文窗口中,从而实现交互式聊天或问答助手。对表格中的信息进行推理是 RAG 的一个重要应用,因为表格在白皮书、财务报告和/或技术手册等文档中很常见。
方法
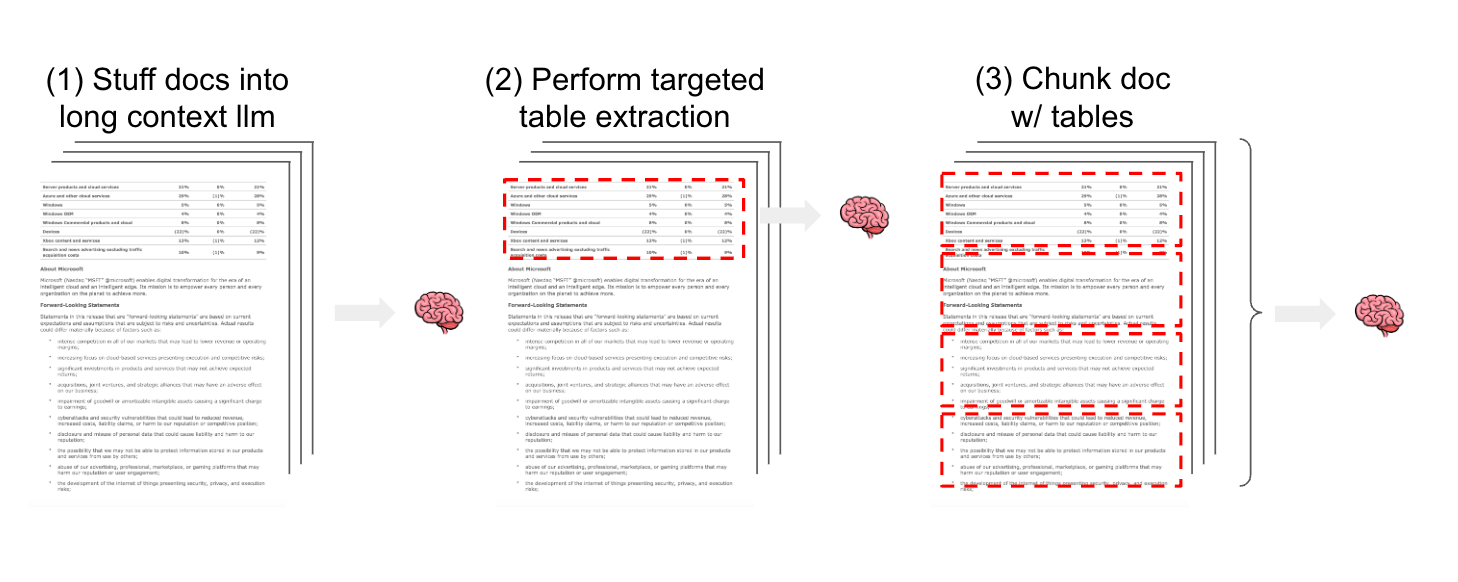
至少有 3 种策略可以考虑用于对非结构化文本和结构化表格的混合进行半结构化 RAG。(1) 将包括表格在内的半结构化文档传递到 LLM 上下文窗口中(例如,使用像 GPT-4 128k 或 Claude2.1 这样的长上下文 LLM)。(2) 使用有针对性的方法来检测和提取文档中的表格(例如,使用模型来检测表格以进行提取)。(3) 拆分文档(例如,使用文本拆分),以便表格元素保留在文本块内部。对于方法 2 和 3,提取的表格或包含表格的文档拆分可以被嵌入和存储,以便在 RAG 应用程序中进行语义检索。
基准测试
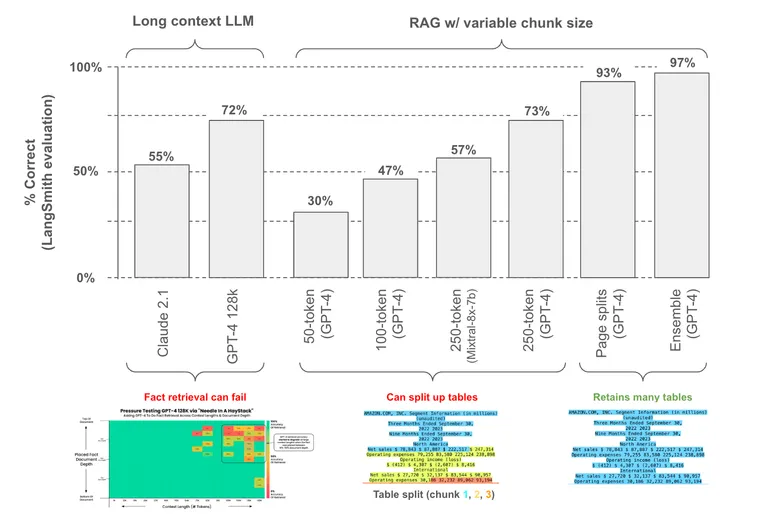
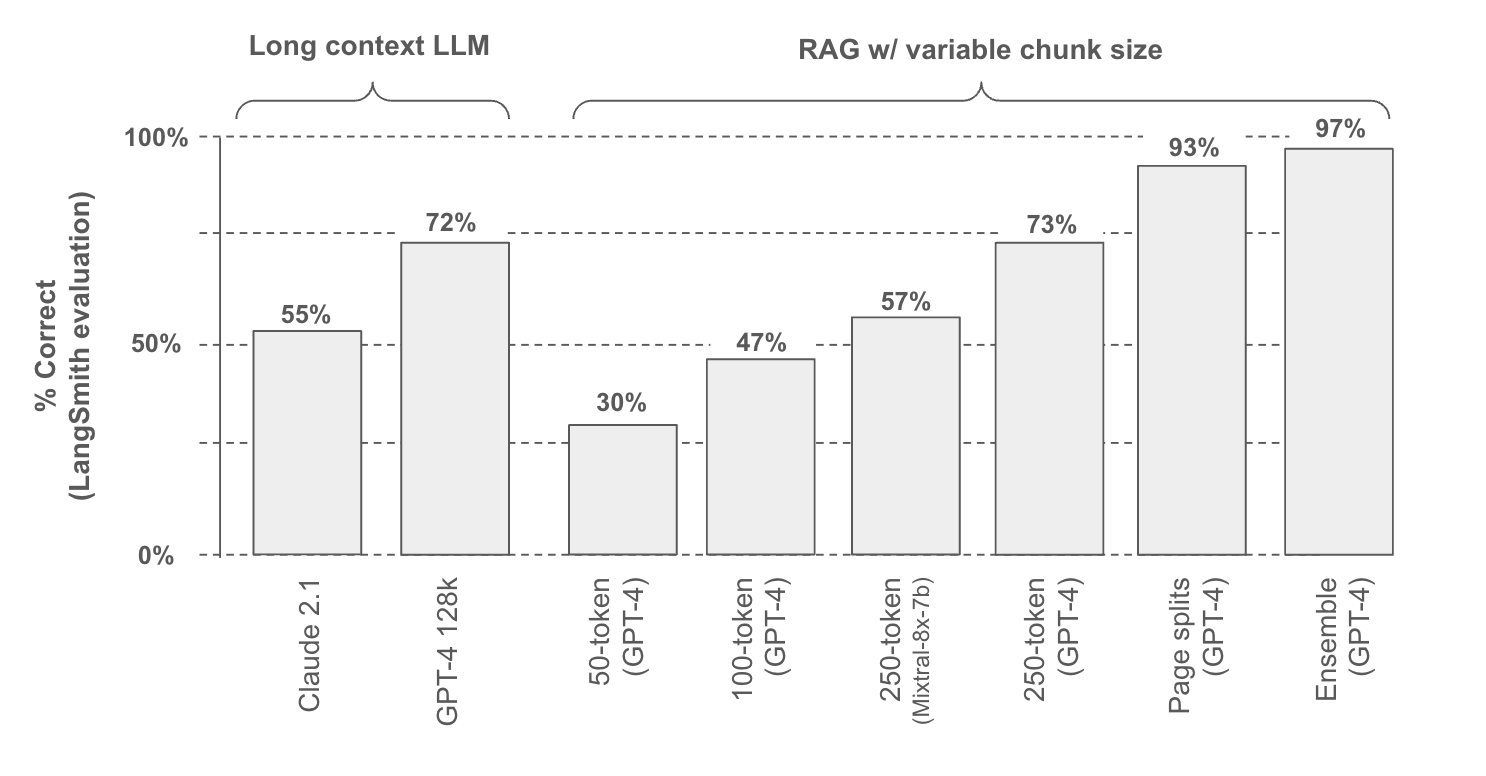
为了测试这些方法,我们构建了一个公共 LangSmith 基准,其中包含来自 6 个文档(2 份白皮书和 4 份盈利报告)的 30 个问题;其中 25 个问题专门从这些文档中的表格元素中提取。
我们测试了两种不同的长上下文 LLM 以及各种文档分块方法。我们使用 LangSmith 来评分相对于基准中提供的真实答案的响应(下图,运行此处)。
方法 1:长上下文 LLM
直接将包含表格的文档传递到长上下文 LLM 上下文窗口中具有相当大的吸引力:它很简单。但挑战是双重的:(1) 这种方法无法扩展到非常大的语料库;128k tokens 大于 100 页,但这相对于许多数据集的大小来说仍然很小。(2) 这些 LLM 在性能方面随着输入的大小以及细节在输入中的位置而出现一些下降,正如 Greg Kamradt 在此处 和 此处 很好地展示的那样。
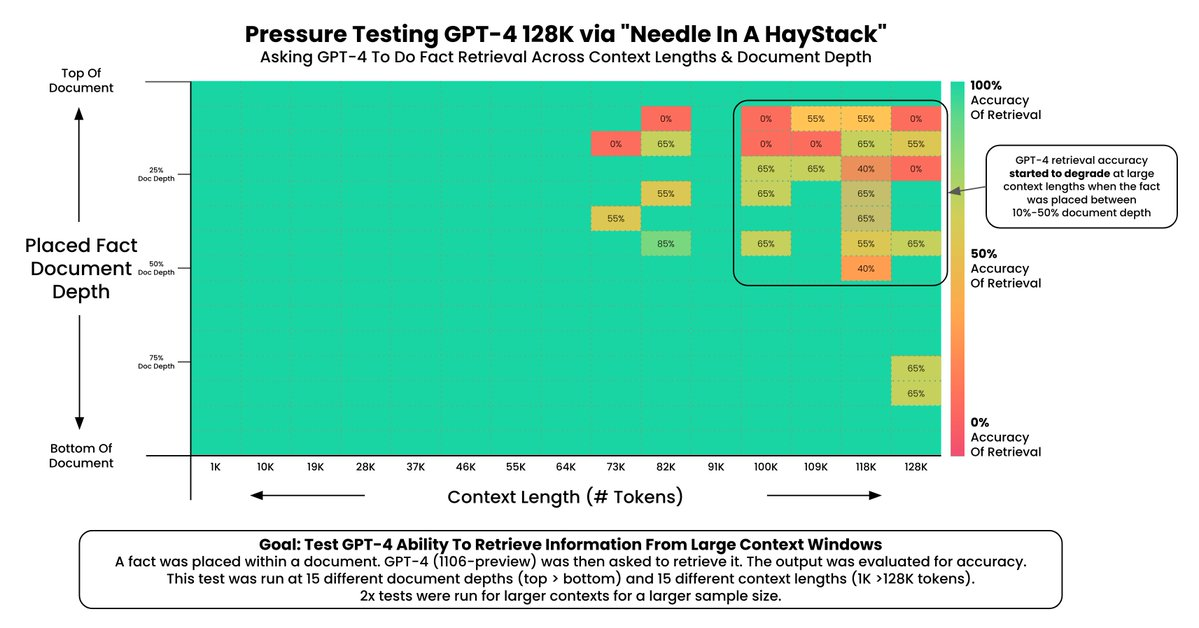
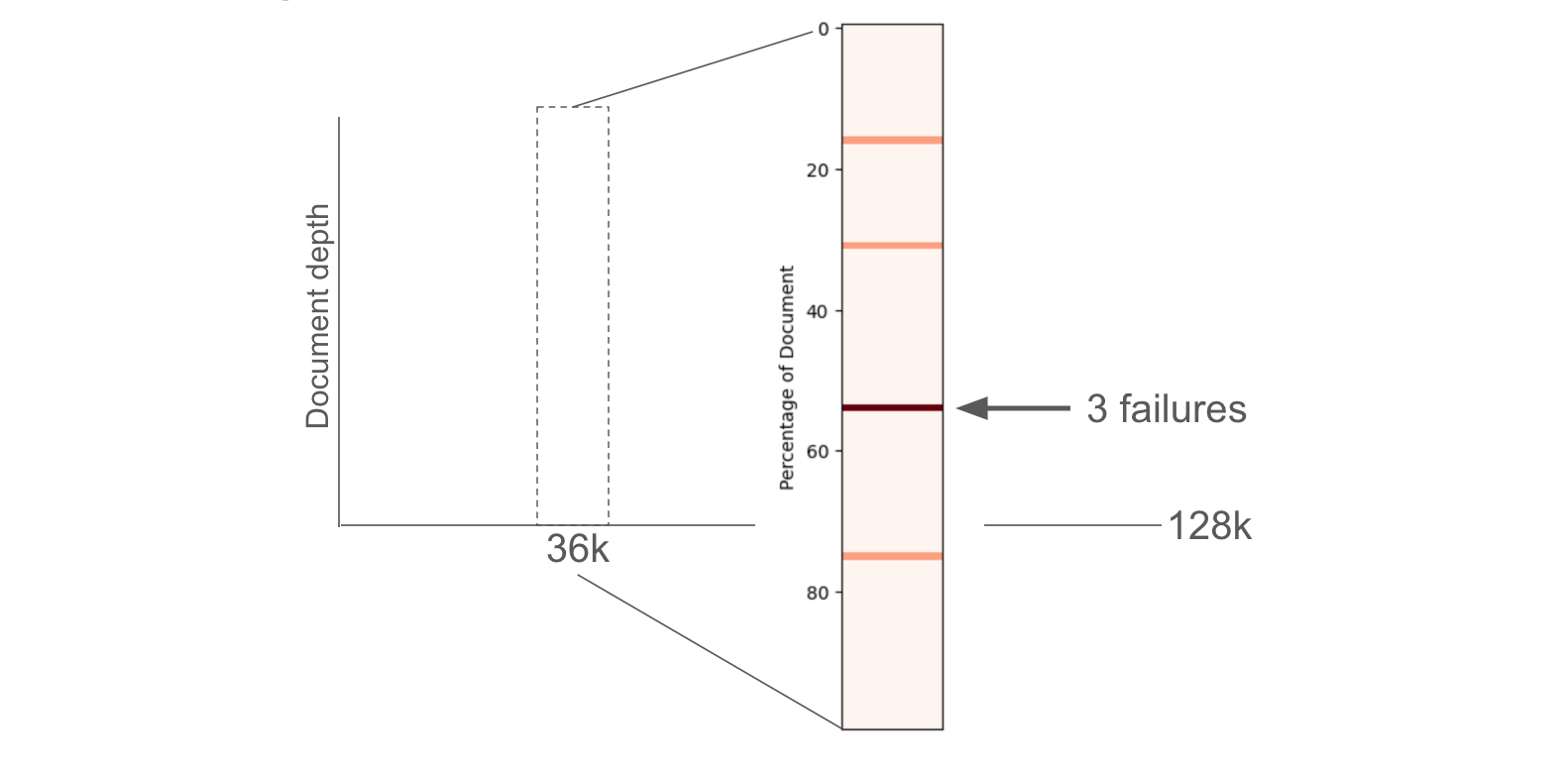
来自所有 6 个文档的串联文本仅约 36,000 个 tokens,远低于 GPT-4 的 128k token 上下文限制。根据上述报告,我们还研究了关于文档深度的失败(参见此处的结果以及下图所示)。这将受益于更仔细的检查,以更好地理解为什么以及何时长上下文 LLM 无法恢复表格中的信息。
方法 2:有针对性的表格提取
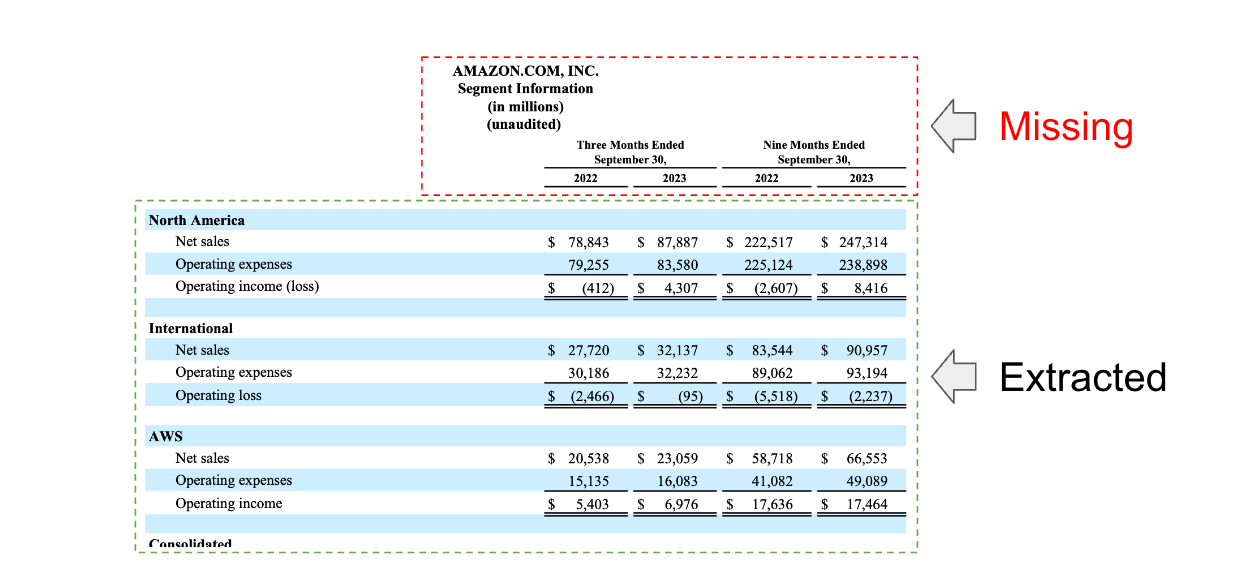
直接从文档中提取表格很有吸引力:它将允许我们使用像 多向量检索器 这样的方法来索引每个表格。一些检测文档中表格的方法是可用的,并且像 Unstructured 或 Docugami 这样的软件包也是可用的。我们将跟进一些专注于这些软件包的具体分析。然而,值得指出的是,由于表格表示的可变性,表格提取具有挑战性。例如,在我们的评估中,我们看到了一些案例,其中表格标题没有使用其中一些方法正确提取(如下)。虽然具有挑战性,但这些方法可能具有最高的性能上限,特别是对于复杂的表格类型,并且值得仔细研究。
方法 3:分块
虽然有针对性的表格提取专门关注查找和提取表格,但文档分块天真地根据指定的 token 限制拆分文档。这里的挑战很直接:如果我们以破坏表格结构的方式对文档进行分块,那么我们将无法回答有关它的问题。作为一个例子,我们看到 50 token 块大小的性能最低(30% 的准确率),我们可以使用 Greg Kamradt 的 chunkviz 可视化这一点:这显然以有问题的方式破坏了我们的示例表格之一,并降低了性能。

因此,问题是:我们如何设置分块大小以最大限度地提高我们保留表格的可能性?性能随着分块大小的增加而提高,正如预期的那样,因为表格更可能在更大的块中被保留。我们还测试了 GPT-4 和 Mixtral-8x-7b(通过 Fireworks.ai),这表明 LLM 的选择将通过改变答案质量来影响性能(参见此处的详细信息)。
最终,我们发现一个明显的分块策略效果很好:沿页面拆分文档。许多文档表格被设计为遵守页面边界,以提高人类的可读性。当然,这种方法在表格跨越页面边界的情况下会失效(促使了有针对性的提取方法)。
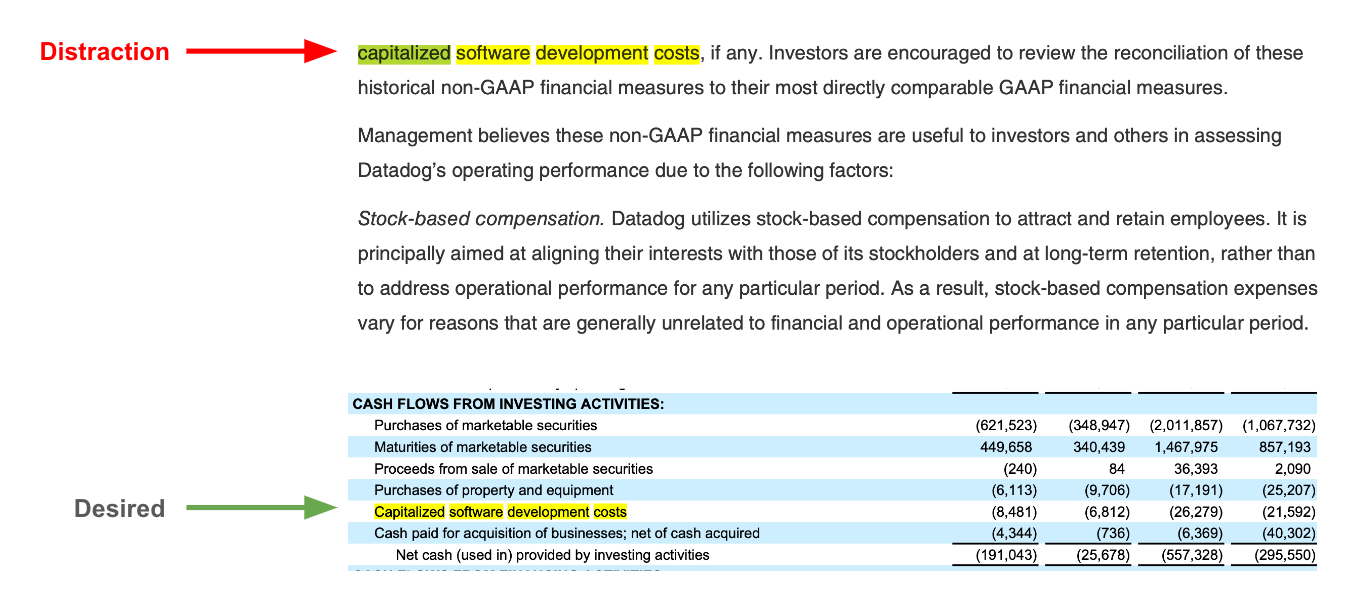
然而,我们发现了另一个问题:来自表格的块(其中包含我们最有价值的信息)可能会与来自文档文本主体的块竞争。这是一个跟踪,突出了这个问题:我们想要 Datadog 在我们的文档之一中的资本化软件费用,但未能检索到表格块,因为这个关键词出现在文本主体的很多地方,起到了分散注意力的作用。
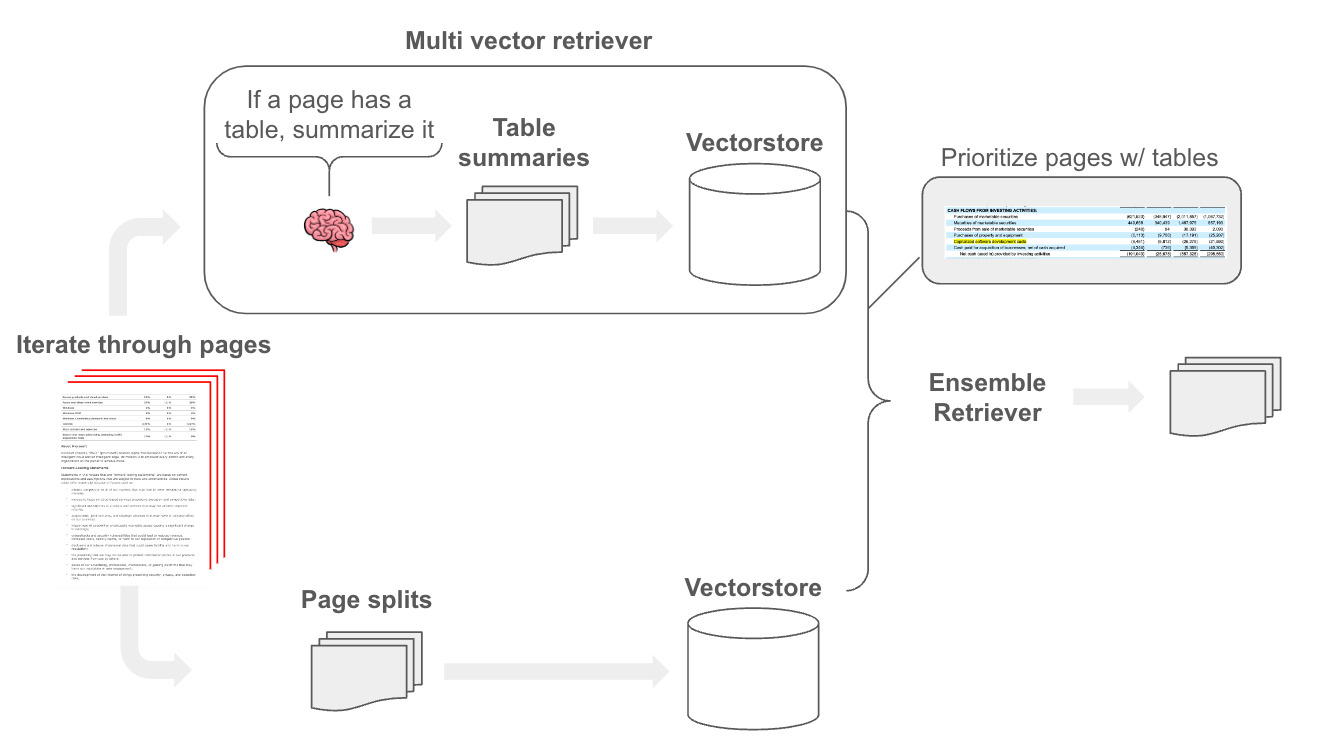
为了解决这个问题,我们发现一个简单的方法效果很好:构建一个专注于表格的检索器。为此,我们使用 LLM 扫描每个页面,并总结页面中的任何表格。然后,我们索引这些摘要以进行检索,并将包含表格的原始页面文本与多向量检索器一起存储。最后,我们将检索到的表格块与原始文本块集成。关于集成检索器的好处是我们可以优先考虑某些来源,这允许我们确保任何相关的表格块都被传递给 LLM。
简而言之,集成检索器将来自不同检索器的排名组合成一个单一的、统一的排名。每个检索器提供一个文档列表(或搜索结果),这些文档列表根据其与查询的相关性进行排名。我们可以应用权重来调整每个检索器对最终组合排名的贡献。在这里,我们简单地给表格导出的块更高的权重,以确保它们的检索。
结论
虽然长上下文 LLM 提供了简单性,但事实回忆可能会受到上下文长度和表格在文档中位置的挑战。有针对性的表格提取可能具有最高的性能上限,特别是对于复杂的表格类型,但需要特定的软件包,这可能会增加复杂性,并且可能在识别各种表格类型时遇到故障模式。后续工作将详细检查这些方法。分块是一种简单的方法,但分块大小的选择是一个挑战。对于此用例,我们发现沿页面边界分块是保留块内表格的合理方法,但承认存在诸如多页表格之类的故障模式。我们还发现,诸如集成之类的技巧可以优先考虑表格导出的文本块,以提高性能。