
托管于: https://chat.langchain.com
仓库: https://github.com/langchain-ai/chat-langchain
简介
LangChain 将大型语言模型的力量以及围绕它们的整个工具生态系统整合到一个软件包中。这种整合最终简化了 LLM 应用程序的构建,但也意味着有很多功能需要学习。
为了帮助大家了解 LangChain,我们决定使用 LangChain 来解释 LangChain。
在这篇文章中,我们将构建一个聊天机器人,通过索引和搜索 Python 文档 和 API 参考,来回答关于 LangChain 的问题。我们将这个机器人称为 Chat LangChain。在解释架构时,我们将涉及如何:
- 使用 Indexing API 持续将向量存储同步到数据源
- 使用 LangChain 表达式语言 (LCEL) 定义 RAG 链
- 评估 LLM 应用程序
- 部署 LangChain 应用程序
- 监控 LangChain 应用程序
到最后,您将看到从头开始引导一个智能聊天机器人是多么容易。这个过程也可以适用于其他知识库。让我们深入了解一下!
架构
数据摄取
为了执行 RAG,我们需要在关于 LangChain 的某些信息源上创建一个索引,以便在运行时进行查询。数据摄取是指加载、转换和索引相关数据源的过程。
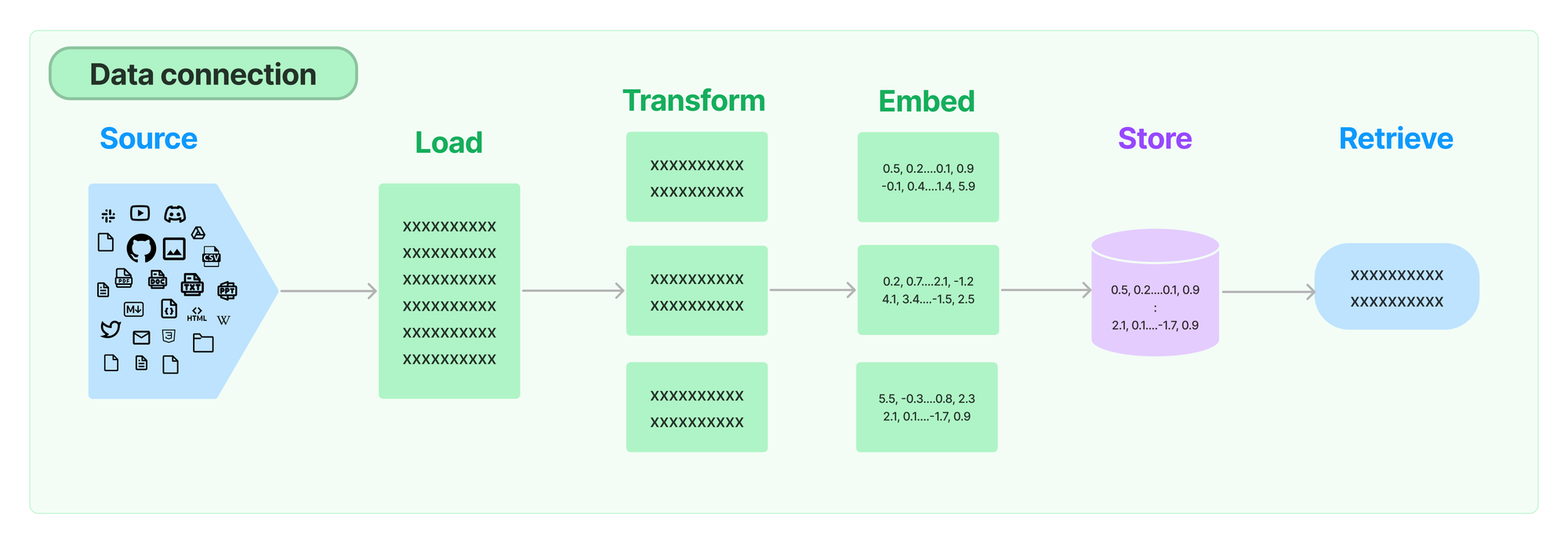
首先,我们尝试索引 Python 文档、API 参考和 Python 仓库。我们发现,直接检索代码块通常不如更具上下文和更详细的来源(如文档)有效,因此我们从检索源中删除了代码库。
最终的数据摄取管道如下所示
加载:SitemapLoader + RecursiveURLLoader — 我们首先通过抓取相关的网页来加载我们的文档。我们这样做而不是直接从仓库加载,因为 1) 我们的文档和 API 参考的部分内容是从代码和笔记本自动生成的,以及 2) 这是一种更通用的方法。
为了加载 Python 文档,我们使用了 SitemapLoader,它从站点地图 XML 文件中查找所有要抓取的相关链接。这里的大部分工作是由 langchain_docs_extractor 方法完成的,这是一个由 Jesús Vélez Santiago 贡献的令人惊叹的自定义 HTML -> 文本解析器
docs = SitemapLoader(
"https://python.langchain.ac.cn/sitemap.xml",
filter_urls=["https://python.langchain.ac.cn/"],
parsing_function=langchain_docs_extractor,
default_parser="lxml",
bs_kwargs={
"parse_only": SoupStrainer(
name=("article", "title", "html", "lang", "content")
),
},
meta_function=metadata_extractor,
).load()为了加载 API 参考(它没有非常有用的站点地图),我们使用了 RecursiveUrlLoader,它从页面递归加载子链接,直到一定的深度。
api_ref = RecursiveUrlLoader(
"https://python-api.langchain.ac.cn/en/latest/",
max_depth=8,
extractor=simple_extractor,
prevent_outside=True,
use_async=True,
timeout=600,
check_response_status=True,
exclude_dirs=(
"https://python-api.langchain.ac.cn/en/latest/_sources",
"https://python-api.langchain.ac.cn/en/latest/_modules",
),
).load()转换:RecursiveCharacterTextSplitter — 当我们的文档加载完成时,我们已经完成了大量的 HTML 到文本和元数据解析。我们加载的一些页面非常长,因此我们需要对它们进行分块。这很重要,因为 1) 它可以提高检索性能;如果相似性搜索也包含大量不相关的信息,则可能会错过相关文档,2) 节省了我们不必担心检索到的文档是否适合模型的上下文窗口。
我们使用简单的 RecursiveCharacterTextSplitter 将内容划分为大致相等大小的块
transformed_docs = RecursiveCharacterTextSplitter(
chunk_size=4000,
chunk_overlap=200,
).split_documents(docs + api_ref)嵌入 + 存储:OpenAIEmbeddings,Weaviate — 为了理解这些文本数据并实现有效的检索,我们利用了 OpenAI 的嵌入。这些嵌入使我们能够将每个块表示为 Weaviate 向量存储中的一个向量,从而创建一个结构化的知识库,为检索做好准备。
client = weaviate.Client(
url=WEAVIATE_URL,
auth_client_secret=weaviate.AuthApiKey(api_key=WEAVIATE_API_KEY),
)
embedding = OpenAIEmbeddings(chunk_size=200)
vectorstore = Weaviate(
client=client,
index_name=WEAVIATE_DOCS_INDEX_NAME,
text_key="text",
embedding=embedding,
by_text=False,
attributes=["source", "title"],
)索引 + 记录管理:SQLRecordManager — 我们希望能够重新运行我们的数据摄取管道,以使聊天机器人与最新的 LangChain 版本和文档保持同步。我们还希望能够随着时间的推移改进我们的数据摄取逻辑。为了做到这一点,而无需每次都从头开始重新索引我们所有的文档,我们使用了 LangChain Indexing API。这使用 RecordManager 来跟踪对任何向量存储的写入,并处理来自同一来源的文档的去重和清理。为了我们的目的,我们使用了 Supabase PostgreSQL 支持的记录管理器
record_manager = SQLRecordManager(
f"weaviate/{WEAVIATE_DOCS_INDEX_NAME}", db_url=RECORD_MANAGER_DB_URL
)
record_manager.create_schema()
indexing_stats = index(
transformed_docs,
record_manager,
vectorstore,
cleanup="full",
source_id_key="source",
)瞧!我们现在已经创建了我们的文档和 API 参考的可查询向量存储索引。
持续数据摄取
我们相当定期地添加和改进 LangChain 功能。为了确保我们的聊天机器人与 LangChain 提供的最新和最棒的功能保持同步,我们需要定期重新索引文档。为此,我们在仓库中添加了一个计划的 Github Action ,每天运行数据摄取管道:查看 这里。
问答
我们的问答链有两个简单的组件。首先,我们获取问题,将其与当前聊天会话中的过去消息结合起来,并编写一个独立的搜索查询。因此,如果用户问“我如何使用 Anthropic LLM”,然后跟进“VertexAI 怎么样”,聊天机器人可能会将最后一个问题重写为“我如何使用 VertexAI LLM”,并使用它来查询检索器,而不是“VertexAI 怎么样”。您可以在 这里 查看我们用于重新措辞问题的提示。
condense_question_chain = (
PromptTemplate.from_template(REPHRASE_TEMPLATE)
| llm
| StrOutputParser()
).with_config(
run_name="CondenseQuestion",
)
retriever_chain = condense_question_chain | retriever一旦我们制定了搜索查询并检索到相关文档,我们就使用 这个提示 将原始问题、聊天历史记录和检索到的上下文传递给模型。请注意,提示指示模型引用其来源。这样做是为了 1) 尝试减轻幻觉,以及 2) 使最终用户可以轻松地探索相关文档本身。
_context = RunnableMap(
{
"context": retriever_chain | format_docs,
"question": itemgetter("question"),
"chat_history": itemgetter("chat_history"),
}
).with_config(run_name="RetrieveDocs")
prompt = ChatPromptTemplate.from_messages(
[
("system", RESPONSE_TEMPLATE),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
]
)
response_synthesizer = (prompt | llm | StrOutputParser()).with_config(
run_name="GenerateResponse",
)
answer_chain = _context | response_synthesizer评估
构建可靠的聊天机器人需要多次调整。我们最初的原型有很多不足之处。它自信地 幻想着与 LangChain 上下文无关的内容,或者它 无法响应 许多常见问题。通过在整个开发过程中使用 LangSmith,我们可以快速迭代管道中的不同步骤,快速识别链中最薄弱的环节。我们典型的流程是与应用程序交互,查看不良示例的跟踪,将责任归咎于不同的组件(检索器、响应生成器等),以便我们知道要更新什么,然后重复。 每当机器人在我们的某个问题上失败时,我们会将运行添加到数据集中,以及我们期望收到的答案。这很快使我们获得了一个可用的 V0,并“免费”给了我们基准数据集,每当我们对链结构进行进一步更改时,我们都可以使用它来检查我们的性能。
我们采用了我们的问题和手写答案数据集,并使用 LangSmith 来基准测试我们机器人的每个版本。对于像问答这样的任务,响应有时可能很长或包含代码,选择正确的指标可能是一个挑战。在检查嵌入或字符串距离评估器的评估结果时,两者都不足以匹配我们对评分的期望,因此使用了 LangChain 的 QA 评估器,以及一个自定义的“幻觉”评估器,该评估器将响应与文档进行比较,以查看是否存在未在检索到的文档中找到依据的内容。这样做使我们能够自信地更改机器人的提示、检索器和整体架构。
聊天应用程序
对于任何聊天应用程序,“首个令牌时间”都需要最小化,这意味着端到端异步流式传输支持是必须的。对于我们的应用程序,我们还希望流式传输参考知识,以便用户可以查看源文档以获取更多信息。由于我们使用 LangChain Runnables 构建了我们的聊天机器人,因此我们可以免费获得所有这些。
我们的聊天机器人使用 astream_log 方法异步流式传输来自检索器和响应生成链的响应到 Web 客户端。
stream = answer_chain.astream_log(
{
"question": question,
"chat_history": converted_chat_history,
},
config={"metadata": metadata},
include_names=["FindDocs"],
include_tags=["FindDocs"],
)
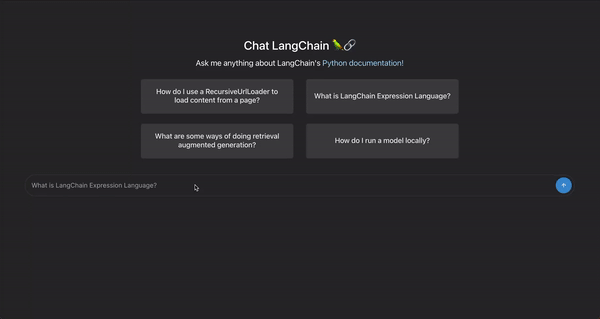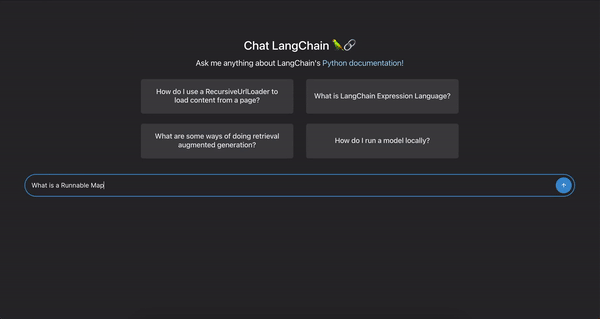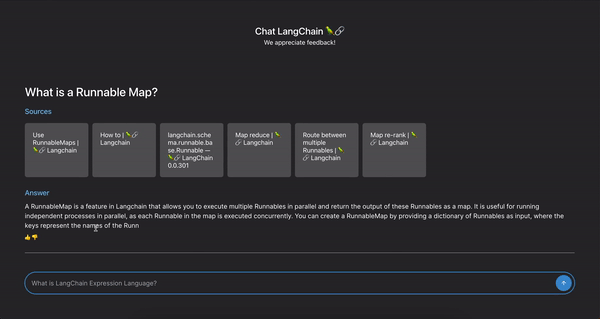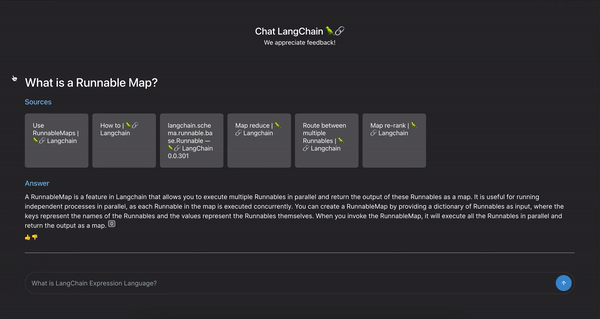
这创建了一个生成器,该生成器从选定的 发出操作,我们可以轻松地将其分为
- 响应内容(答案)
- 检索到的文档元数据(用于引用)
- LangSmith 跟踪的运行 ID(用于反馈)
由此,客户端可以在文档卡可用后立即渲染文档卡,流式传输聊天响应,并捕获运行 ID 以用于记录用户反馈。
反馈端点是一个简单的行,它从 Web 客户端获取运行 ID 和分数,并将值记录到 LangSmith
client.create_feedback(run_id, "user_score", score=score)监控
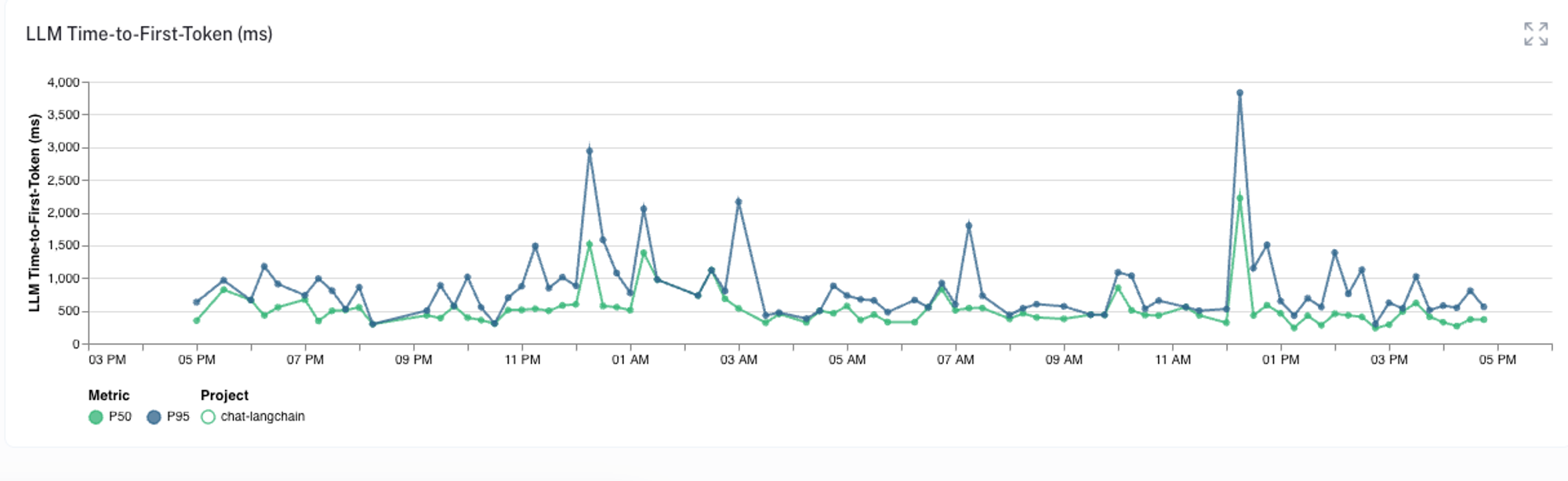
随着聊天机器人的投入生产,LangSmith 可以轻松地聚合和监控相关指标,以便我们可以跟踪应用程序的运行状况。例如,我们可以检查首个令牌时间指标,该指标捕获从查询发送到聊天机器人到第一个响应令牌发送回用户之间的时间延迟。
或者我们可以监控跟踪中何时出现任何错误
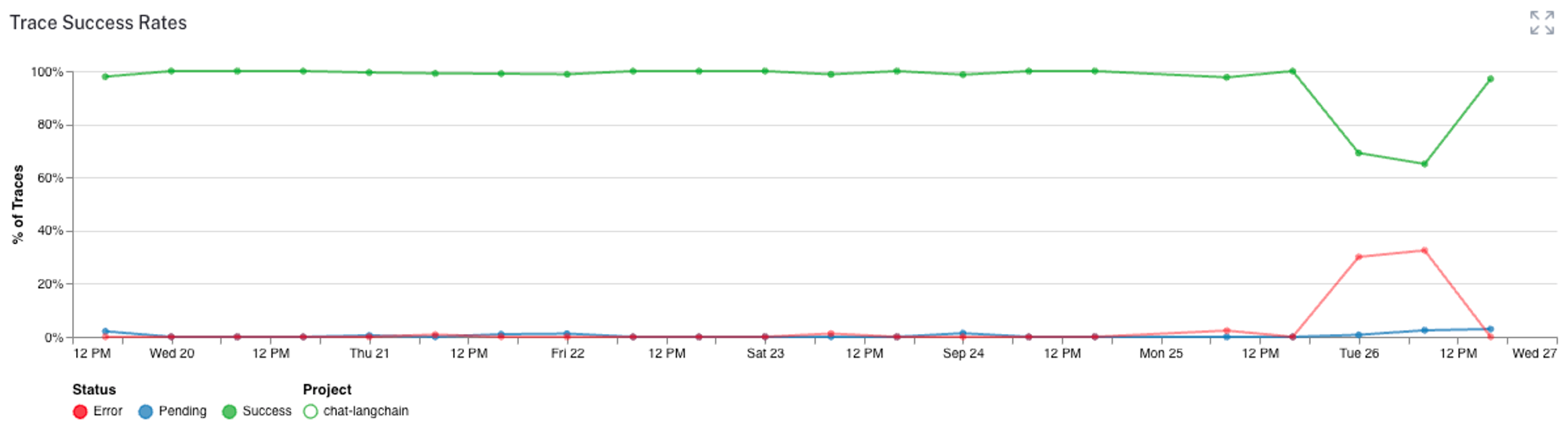
我们还可以跟踪用户反馈指标、令牌计数和各种其他分析,以确保我们的聊天机器人按预期运行。所有这些信息都有助于我们检测、过滤和改进机器人。
结论
前往 https://chat.langchain.com 试用已部署的版本。要深入了解,请查看 源代码,克隆它,并结合您自己的文档以进一步探索其功能。
如果您正在探索构建应用程序并想聊天,我很乐意促成此事 :) 在 Twitter 上私信我 @mollycantillon