编者按:这篇博文是与 Airbyte 合作撰写的。他们的 全新向量数据库目标 使数据能够通过 LangChain 非常容易地检索相关上下文,以用于问答用例。我们看到越来越多的团队寻求整合各种数据源的方法,并自动保持数据最新,而这是一种绝佳的方式!
除了此处强调的特定用例之外,我们也对这种集成感到非常兴奋。它结合了 AirByte 中数百个数据源及其强大的调度和编排框架,并利用了 LangChain 中的高级转换逻辑以及 LangChain 的 50 多个嵌入提供商集成和 50 多个向量存储集成。
了解如何构建一个 Slack 连接器开发支持机器人,它能记住您的所有 API、开放的功能请求和以前的 Slack 对话
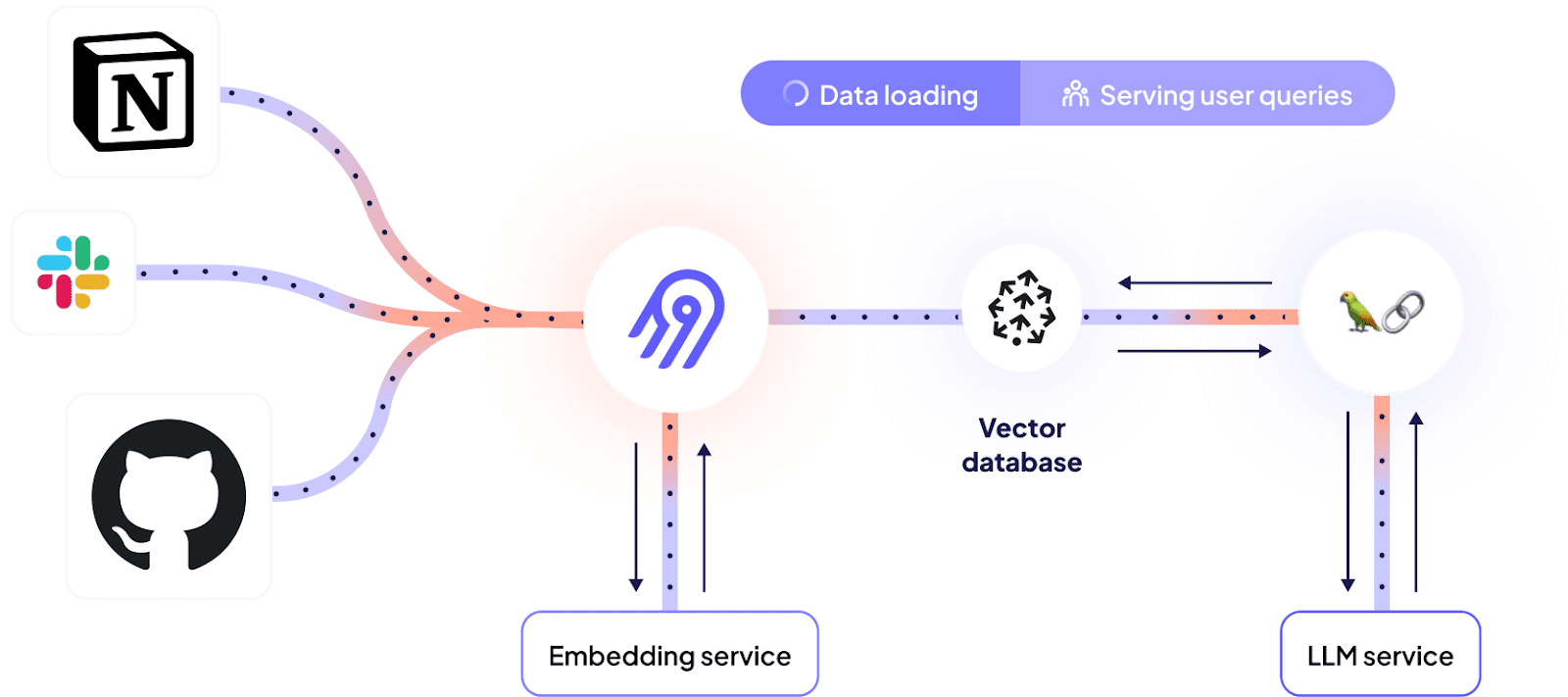
在 之前的一篇文章 中,我们解释了如何利用 Dagster 和 Airbyte 为 LLM 支持的用例提供动力。我们新推出的 向量数据库目标 使这变得更加容易,因为它消除了手动编排分块和嵌入的需求 - 相反,数据源可以直接通过 Airbyte 连接连接到向量数据库。
本教程将引导您完成一个真实世界的用例,了解如何利用向量数据库和 LLM 来理解您的非结构化数据。在本教程结束时,您将
- 了解如何使用 Airbyte 从各种来源提取非结构化数据
- 了解如何使用 Airbyte 将数据高效加载到向量数据库中,从而为后续的 LLM 使用准备数据
- 了解如何将向量数据库集成到您的 LLM 中,以询问有关您的专有数据的问题
我们将构建什么
为了更好地说明这在实践中是什么样子,让我们使用一些与 Airbyte 本身相关的东西。
Airbyte 是一个高度可扩展的系统,允许用户开发自己的连接器,从任何 API 或内部系统提取数据。连接器开发人员的有用信息可以在不同的地方找到
- 官方连接器开发文档网站
- Github 问题,记录了现有的功能请求、已知错误和正在进行的工作
- 社区 Slack 帮助频道
本文介绍了如何将所有这些不同的来源联系在一起,以提供一个单一的聊天界面来访问有关连接器开发的信息 - 一个可以以简单的英语回答有关代码库、文档和参考以前对话的问题的机器人
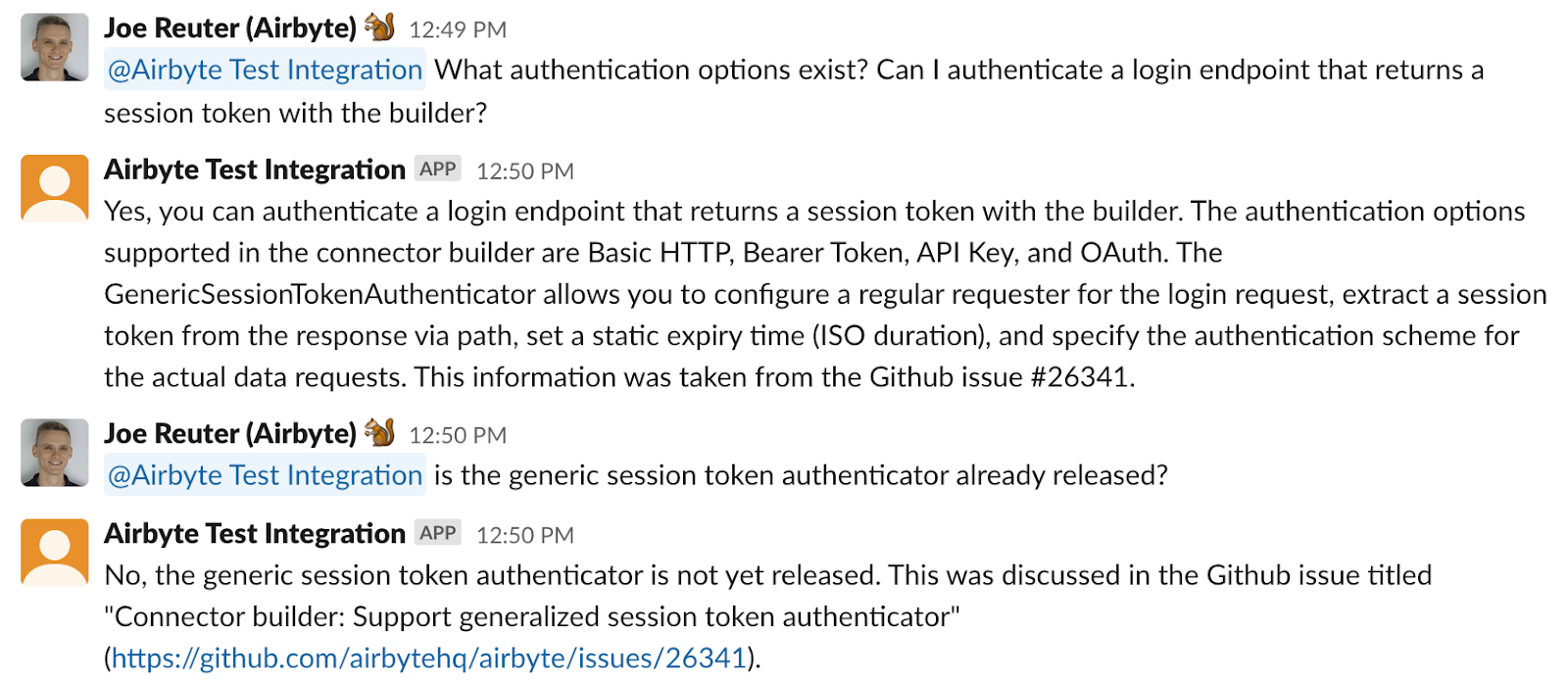
在这些示例中,来自文档网站和现有 Github 问题的信息被组合在一个答案中。
先决条件
为了完成整个过程,您将需要以下帐户。但是,您也可以使用自己的自定义来源,并使用本地向量存储来避免除 OpenAI 帐户之外的所有其他帐户
步骤 1 - 获取 Github 问题
Airbyte 的功能和错误跟踪由 Airbyte 开源存储库的 Github 问题跟踪器 处理。这些问题包含人们需要定期查找的重要信息。
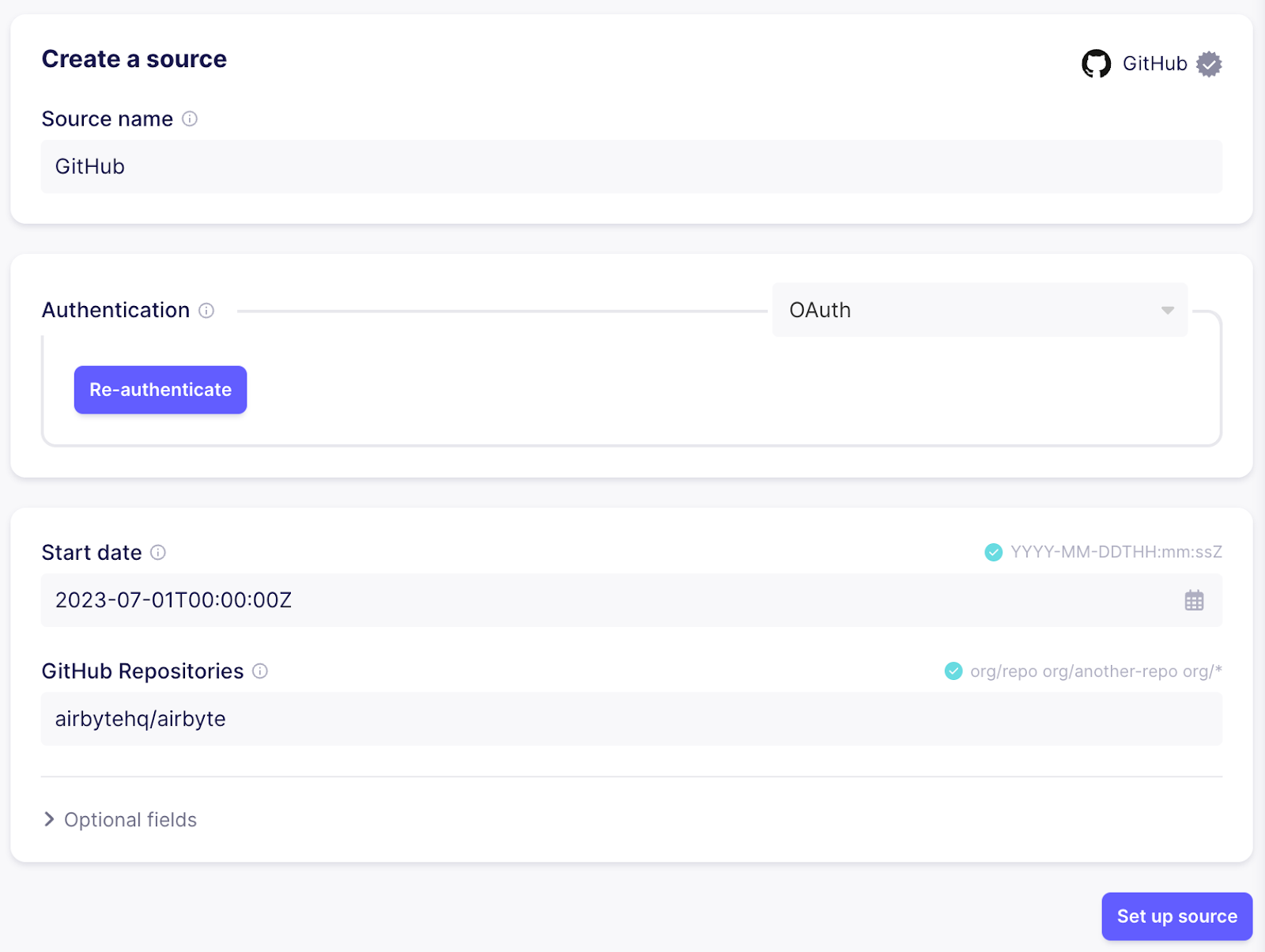
要获取 Github 问题,请使用 Github 连接器创建一个新的来源。
如果您使用的是 Airbyte Cloud,您可以轻松地使用“验证您的 GitHub 帐户”进行身份验证,否则请按照右侧文档中的说明操作,了解如何在 Github UI 中设置 个人访问令牌。
接下来,配置问题的截止日期,并指定应同步的存储库。在本例中,我选择 “2023-07-01T00:00:00Z” 和 “airbytehq/airbyte” 以同步来自主要 Airbyte 存储库的最新问题
步骤 2 - 加载到向量数据库
现在我们已经准备好第一个来源,但 Airbyte 还不知道将数据放在哪里。下一步是配置目标。为此,请选择 “Pinecone” 连接器。Airbyte 正在为您进行一些预处理,以便数据可以进行向量化处理
- 分离文本和元数据字段,并将记录拆分为多个文档,以使每个文档都专注于单个主题,并确保文本适合将用于问答的 LLM 的上下文窗口
- 使用配置的嵌入服务嵌入每个文档的文本,将文本转换为向量以进行相似性搜索
- 将文档索引到向量数据库中(从嵌入服务上传向量以及元数据对象)
除了 Pinecone 之外,Airbyte 还支持将数据加载到 Weaviate、Milvus、Qdrant 和 Chroma 中。
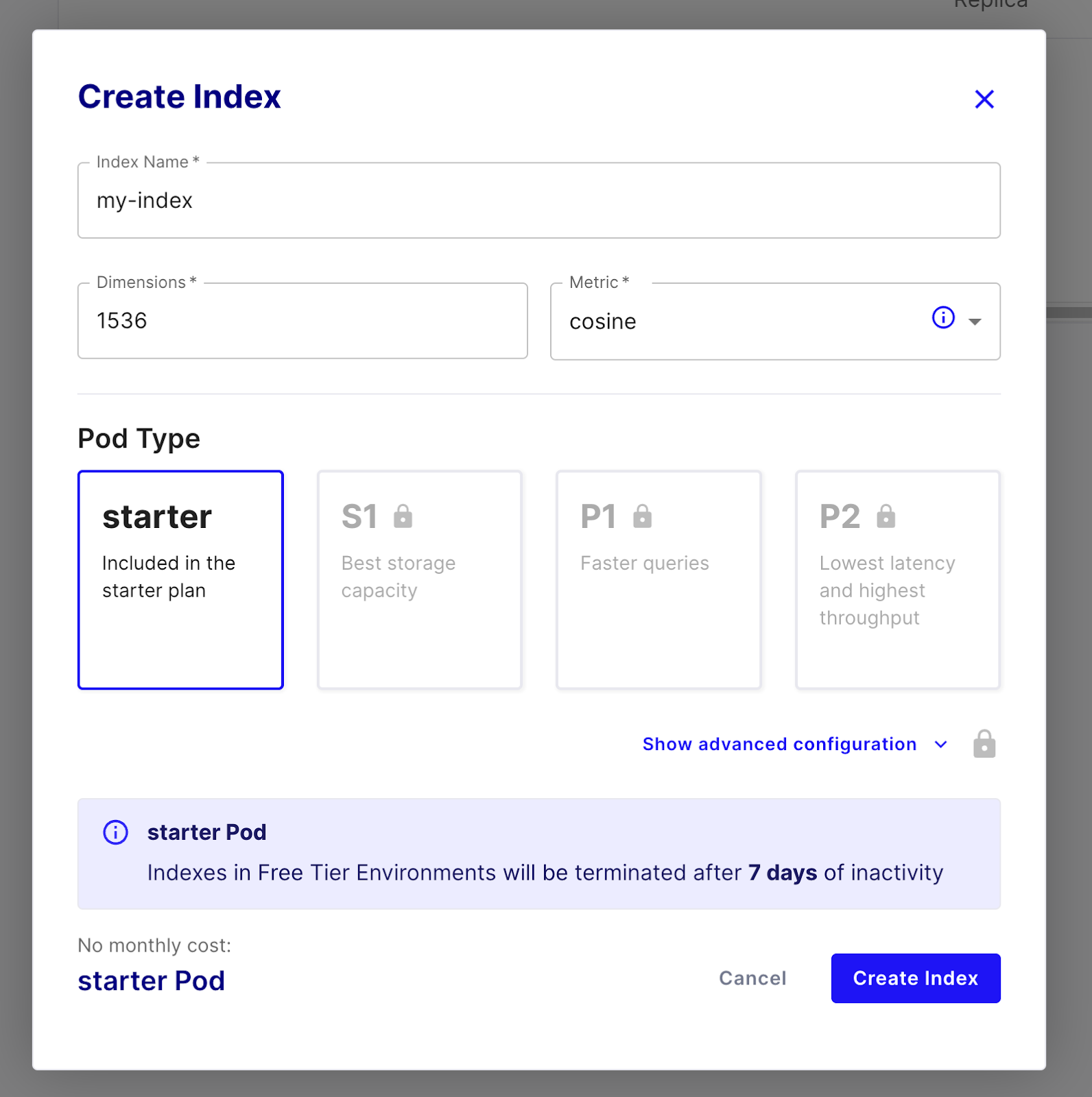
要使用 Pinecone,请注册一个 免费试用帐户,并使用入门级 Pod 创建一个索引。将维度设置为 1536,因为这是我们将要使用的 OpenAI 嵌入的大小
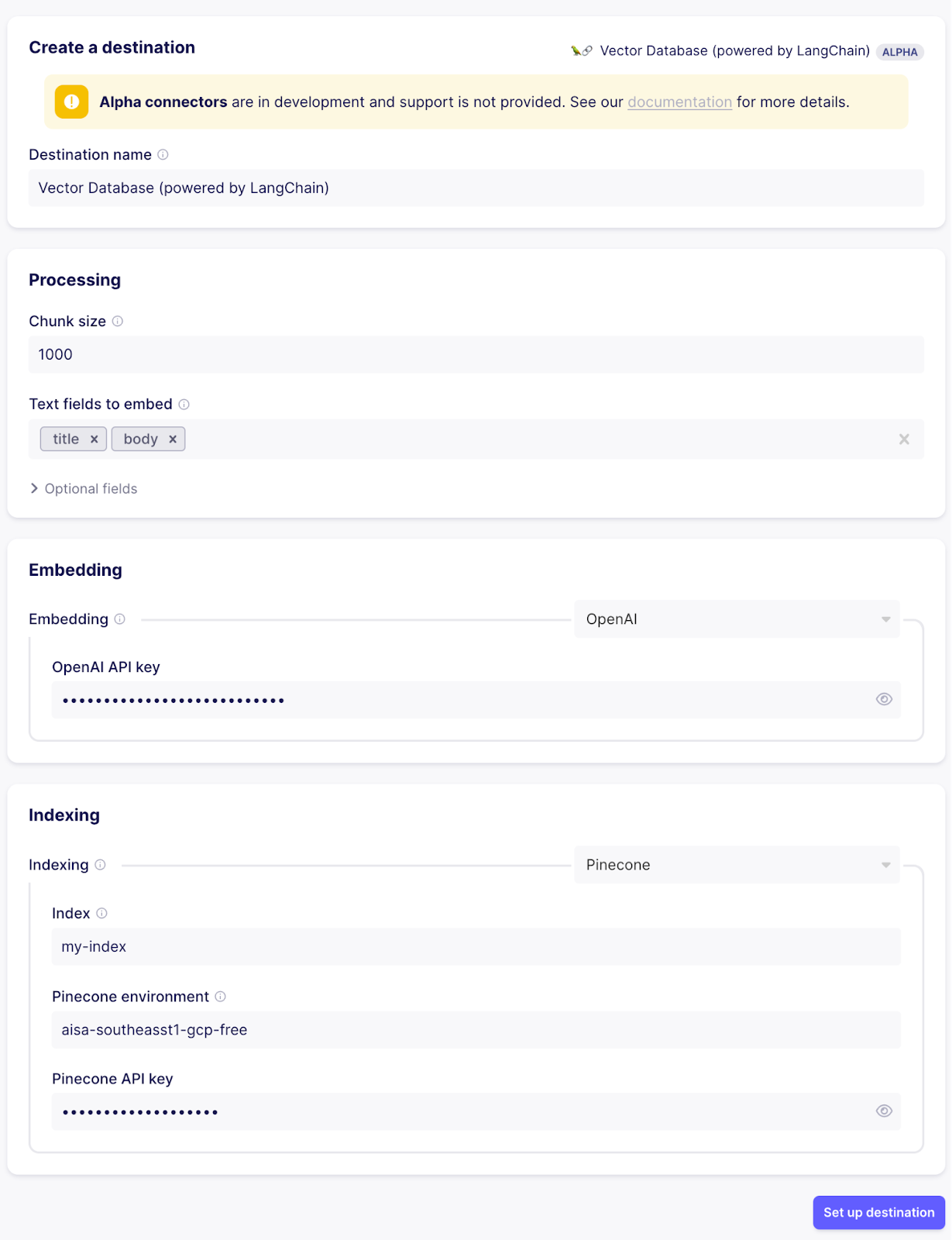
索引准备就绪后,在 Airbyte 中配置向量数据库目标
- 将块大小设置为 1000(大小是指令牌的数量,而不是字符数,因此大约为 4KB 的文本。最佳分块取决于您正在处理的数据)
- 配置要视为将嵌入的文本字段的记录字段。所有其他字段将作为元数据处理。目前,将其设置为 “title” 和 “body”,因为这些是 Github 来源的问题流中的相关字段
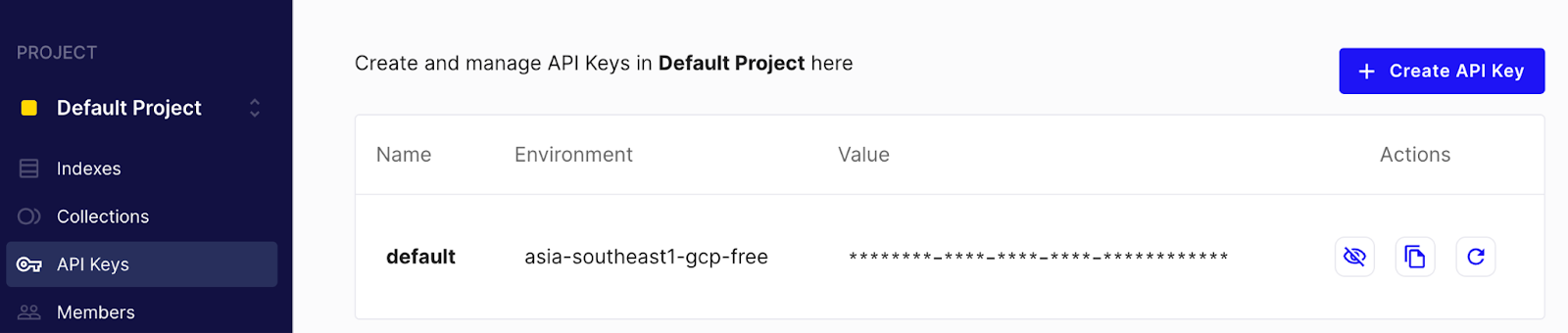
- 设置您的 OpenAI api 密钥,用于支持嵌入服务。您可以在 platform.openai.com/account 页面的 API 密钥部分找到您的 API 密钥
- 对于索引步骤,从 Pinecone UI 复制索引、环境和 api 密钥。您可以在 UI 的 “API 密钥” 部分找到 API 密钥和环境
步骤 3 - 创建连接
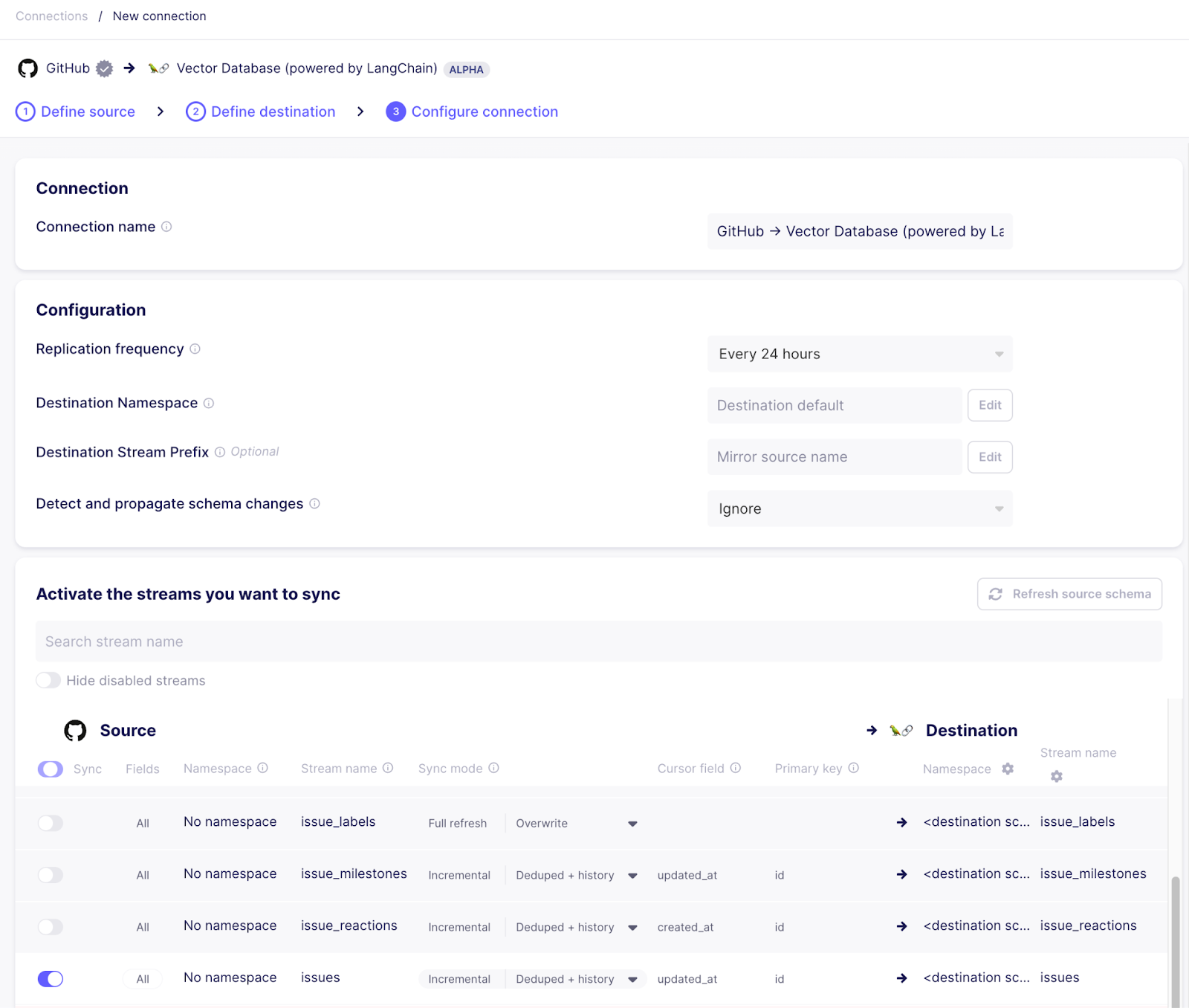
成功设置目标后,建立从 Github 来源到向量数据库目标的连接。在配置流程中,选择现有的来源和目标。配置连接时,请确保仅使用 “issues” 流,因为这是我们感兴趣的。
旁注:Airbyte 允许在生产环境中更有效地进行此同步
- 为了使元数据集中,您可以单击流名称以选择要同步的各个字段。例如,如果 “assignee” 或 “milestone” 字段对您来说永远不相关,您可以取消选中它,它将不会同步到目标。
- 同步模式可用于增量同步问题,同时对向量数据库中的记录进行去重,因此在搜索中不会显示过时的数据
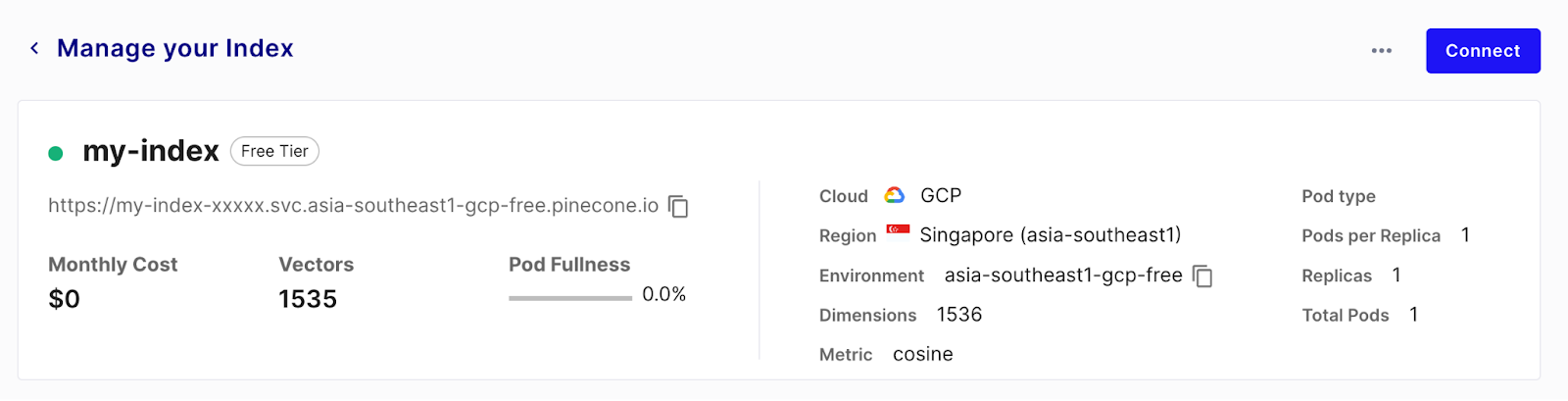
如果一切顺利,现在应该有一个连接正在运行,将数据从 Github 同步到通过向量存储目标的 Pinecone。让同步运行几分钟。首次运行完成后,您可以查看 Pinecone 索引管理页面,查看大量已索引的向量,可以进行查询。
每个向量都与一个元数据对象相关联,该对象填充了在目标配置中未提及为 “文本字段” 的字段。这些字段将与嵌入的文本一起检索,并可在稍后的章节中被我们的聊天机器人利用。这就是从 Pinecone 检索向量时带有元数据的样子
{
"id": "599d75c8-517c-4f37-88df-ff16576bd607",
"values": [0.0076571689, ..., 0.0138477711],
"metadata": {
"_ab_stream": "issues",
"_ab_record_id": 1556650122,
"author_association": "CONTRIBUTOR",
"comments": 3,
"created_at": "2023-01-25T13:21:50Z",
// ...
"text": "...The acceptance-test-config.yml file is in a legacy format. Please migrate to the latest format...",
"updated_at": "2023-07-17T09:20:56Z",
}
}在后续运行中,Airbyte 将仅重新嵌入和更新自上次同步以来已更改的问题的向量 - 这将加快后续运行速度,同时确保您的数据始终是最新的并且可用。
步骤 4 - 聊天界面
数据已准备就绪,现在让我们将其与我们的 LLM 连接起来,以自然语言回答问题。由于我们已经将 OpenAI 用于嵌入,因此最简单的方法是也将其用于问答。
我们将使用 Langchain 作为编排框架,将所有部分联系在一起。
首先,在本地安装一些 pip 包
pip install pinecone-client langchain openai这里的基本功能按以下方式工作
- 用户提出问题
- 使用与在向量数据库中生成向量相同的模型(在本例中为 OpenAI)嵌入问题
- 问题向量被发送到向量数据库,并返回具有相似向量的文档 - 由于向量代表文本的含义,因此问题和问题的答案将具有非常相似的向量,并且将返回相关文档
- 所有具有相关元数据的文档的文本组合成一个字符串,并与用户提出的问题以及根据提供的上下文回答用户问题的指令一起发送给 LLM
- LLM 根据提供的上下文回答问题
- 答案呈现给用户
此流程通常被称为 检索增强生成。Langchain 框架中的 RetrievalQA 类已经实现了基本交互。我们问答机器人的最简单版本只需要提供向量存储和使用的 LLM
# chatbot.py
import os
import pinecone
from langchain.chains import RetrievalQA
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.vectorstores import Pinecone
embeddings = OpenAIEmbeddings()
pinecone.init(api_key=os.environ["PINECONE_KEY"], environment=os.environ["PINECONE_ENV"])
index = pinecone.Index(os.environ["PINECONE_INDEX"])
vector_store = Pinecone(index, embeddings.embed_query, "text")
qa = RetrievalQA.from_chain_type(llm=OpenAI(temperature=0), chain_type="stuff", retriever=vector_store.as_retriever())
print("Connector development help bot. What do you want to know?")
while True:
query = input("")
answer = qa.run(query)
print(answer)
print("\nWhat else can I help you with:")要运行此脚本,您需要将 OpenAI 和 Pinecone 凭据设置为环境变量
export OPENAI_API_KEY=...
export PINECONE_KEY=...
export PINECONE_ENV=...
export PINECONE_INDEX=...
python chatbot.py这通常有效,但它有一些限制。默认情况下,只有文本字段被传递到 LLM 的提示中,因此它不知道文本的上下文是什么,也无法提供返回到它找到其信息的参考
Connector development help bot. What do you want to know?
> Can you give me information about how to authenticate via a login endpoint that returns a session token?
Yes, the GenericSessionTokenAuthenticator should be supported in the UI[...]从这里开始,有很多微调工作要做,以优化我们的聊天机器人。例如,我们可以改进提示,使其包含更多基于元数据字段的信息,并更具体地针对我们的用例
prompt_template = """You are a question-answering bot operating on Github issues and documentation pages for a product called connector builder. The documentation pages document what can be done, the issues document future plans and bugs. Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Always state were you got this information from (and the github issue number if applicable).
If the answer is based on a Github issue that's not closed yet, add 'This issue is not closed yet - the feature might not be shipped yet' to the answer.
{context}
Question: {question}
Helpful Answer:"""
prompt = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
class ConnectorDevelopmentPrompt(PromptTemplate):
def format_document(doc: Document, prompt: PromptTemplate) -> str:
if doc.metadata["_ab_stream"] == "issues":
return f"Excerpt from Github issue: {doc.page_content}, issue number: {doc.metadata['number']}, issue state: {doc.metadata['state']}"
else:
return super().format_document(doc, prompt)
document_prompt = ConnectorDevelopmentPrompt(input_variables=["page_content"], template="{page_content}")
qa = RetrievalQA.from_chain_type(llm=OpenAI(temperature=0), chain_type="stuff", retriever=vector_store.as_retriever(), chain_type_kwargs={"prompt": prompt, "document_prompt": document_prompt})完整的脚本也可以在 Github 上找到
此修订版本的 RetrievalQA 链自定义了在检索上下文后发送给 LLM 的提示
- 基本提示模板设置了更广泛的上下文,即此问题是关于什么的(以前 LLM 必须从文档中猜测)
- 它还更改了将文档添加到提示的方式 - 默认情况下,仅添加文本,但 ConnectorDevelopmentPrompt 实现设置了数据来源的上下文,并向提示添加了相关的元数据,以便 LLM 可以基于不仅仅是文本来回答问题
Connector development help bot. What do you want to know?
> Can you give me information about how to authenticate via a login endpoint that returns a session token?
You can use the GenericSessionTokenAuthenticator to authenticate via a login endpoint that returns a session token. This is documented in the Connector Builder documentation with an example of how the request flow functions (e.g. metabase). This issue is not closed yet - the feature might not be shipped yet (Github issue #26341).
步骤 5 - 放入 Slack
到目前为止,此助手只能在本地使用。但是,使用 python slack sdk 可以很容易地将其变成 Slack 机器人本身。
为此,我们需要首先设置一个 Slack “应用”。转到 https://api.slack.com/apps 并基于 此处 的清单创建一个新应用(这为您节省了一些手动配置权限的工作)。设置好您的应用后,将其安装到您想要集成的工作区。这将生成一个您需要记下的 “Bot User OAuth 访问令牌”。之后,转到您应用的 “基本信息” 页面,向下滚动到 “应用级令牌”,然后创建一个新令牌。也记下此 “应用级令牌”。
在常规 Slack 客户端中,可以通过单击频道名称并转到 “集成” 选项卡,将您的应用添加到 Slack 频道
在此之后,您的 Slack 应用已准备好接收来自用户的 ping 以回答问题 - 下一步是从 python 代码中调用 Slack,因此我们需要安装 python 客户端库
pip install slack_sdk之后,我们可以使用 Slack 集成扩展我们现有的聊天机器人脚本
from slack_sdk import WebClient
from slack_sdk.socket_mode import SocketModeClient
from slack_sdk.socket_mode.request import SocketModeRequest
from slack_sdk.socket_mode.response import SocketModeResponse
slack_web_client = WebClient(token=os.environ["SLACK_BOT_TOKEN"])
handled_messages = {}
def process(client: SocketModeClient, socket_mode_request: SocketModeRequest):
if socket_mode_request.type == "events_api":
event = socket_mode_request.payload.get("event", {})
client_msg_id = event.get("client_msg_id")
if event.get("type") == "app_mention" and not handled_messages.get(client_msg_id):
handled_messages[client_msg_id] = True
channel_id = event.get("channel")
text = event.get("text")
result = qa.answer(text)
slack_web_client.chat_postMessage(channel=channel_id, text=result)
return SocketModeResponse(envelope_id=socket_mode_request.envelope_id)
socket_mode_client = SocketModeClient(
app_token=os.environ["SLACK_APP_TOKEN"],
web_client=slack_web_client
)
socket_mode_client.socket_mode_request_listeners.append(process)
socket_mode_client.connect()
print("listening")
from threading import Event
Event().wait()完整的脚本也可以在 Github 上找到
要运行该脚本,还需要将 slack 机器人令牌和应用令牌的环境变量作为环境变量添加
export SLACK_BOT_TOKEN=...
export SLACK_APP_TOKEN=...
python chatbot.py运行此脚本后,您应该能够在您添加到频道的开发机器人应用程序中像用户一样 ping 它,它将通过运行 RetrievalQA 链来响应问题,该链从向量数据库加载相关上下文并使用 LLM 来制定一个好的答案

所有代码也可以在 Github 上找到
步骤 6 - 其他数据源:抓取文档网站
Github 问题很有帮助,但我们希望我们的开发机器人了解更多信息。
连接器开发文档页面 是回答问题非常重要的信息来源,因此绝对需要包含在内。确保机器人具有与已发布信息相同的信息的最简单方法是抓取网站。对于这种情况,我们将使用 Apify 服务来处理抓取并将网站转换为结构良好的数据集。可以使用 Airbyte Apify Dataset 来源连接器提取此数据集。
首先,登录 Apify 并导航到商店。选择 “Web Scraper” Actor 作为基础 - 它已经实现了我们所需的大部分功能
接下来,创建一个新任务并将其配置为抓取文档的所有页面,提取页面标题和所有内容
- 将起始 URL 设置为 https://docs.airbyte.com/connector-development/connector-builder-ui/overview/,文档的介绍页面链接到其他页面
- 将链接选择器设置为 a[href] 以跟踪每个页面的所有链接
- 将 Glob 模式设置为 https://docs.airbyte.com/connector-development/connector-builder-ui/* 以限制抓取工具停留在文档中,而不是抓取整个互联网
- 配置页面函数以提取页面标题和内容 - 在这种情况下,可以使用 CSS 类名找到内容元素
async function pageFunction(context) {
const $ = context.jQuery;
const pageTitle = $('title').first().text();
const content = $('.markdown').first().text();
return {
url: context.request.url,
pageTitle,
content
};
}运行此 Actor 将快速完成,并为我们提供一个易于使用的数据集,其中包含页面标题和内容的列
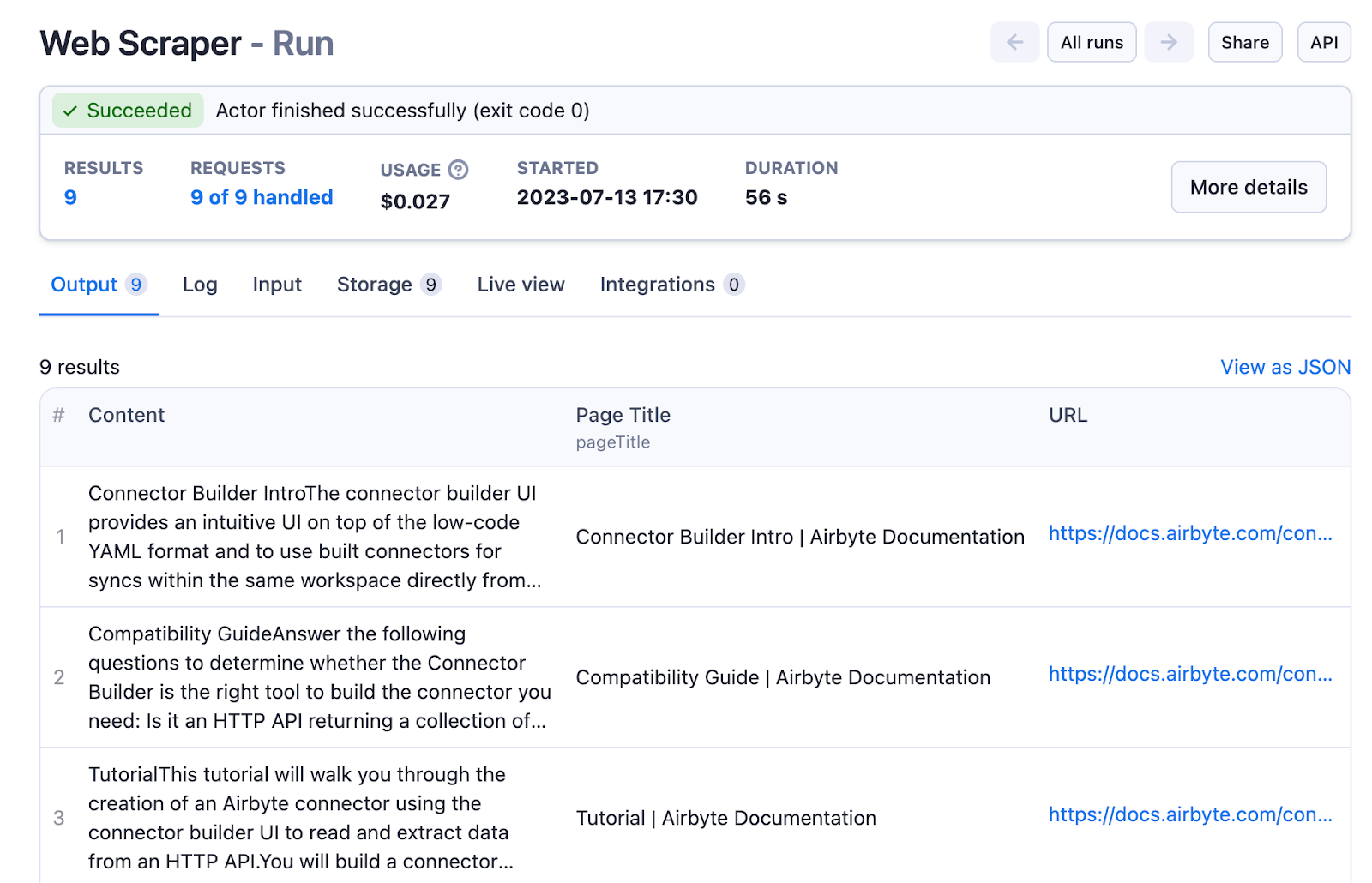
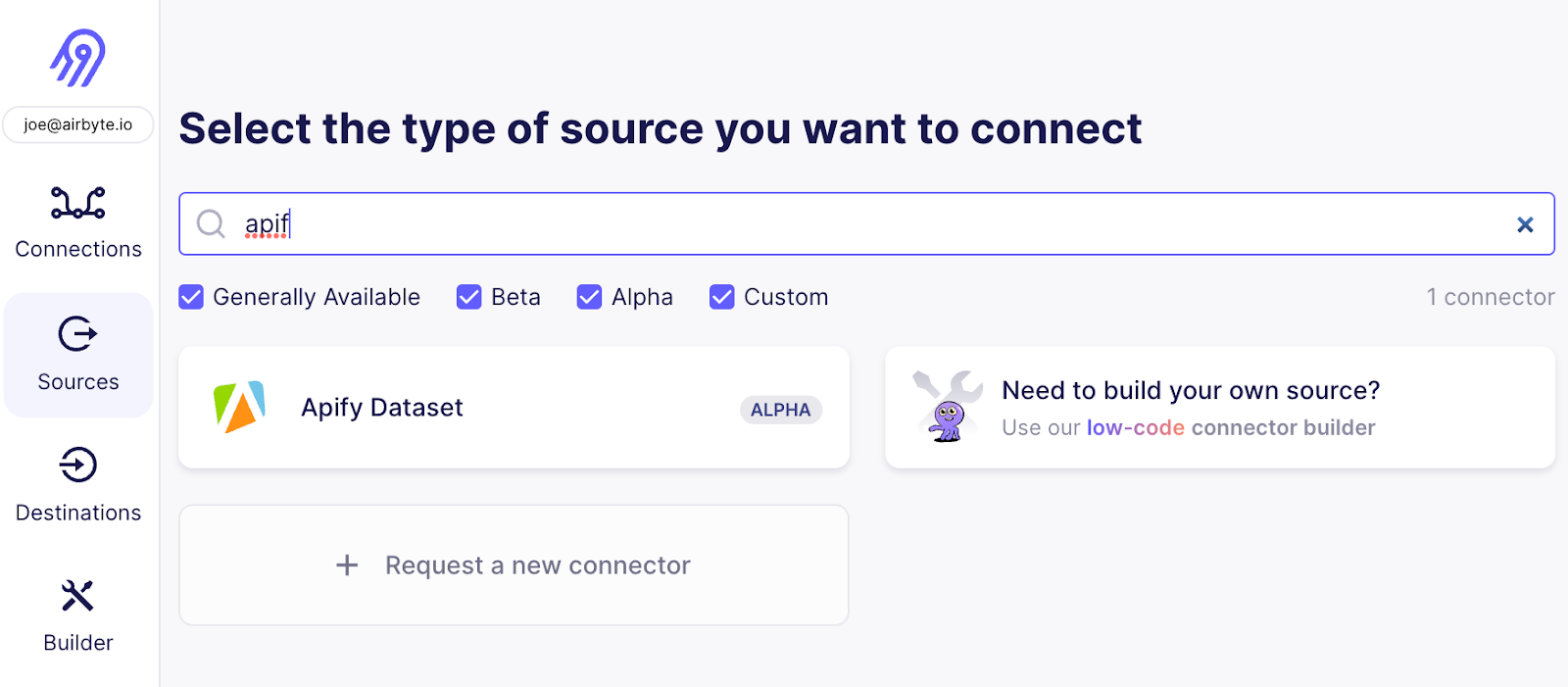
现在是时候将 Airbyte 连接到 Apify 数据集了 - 转到 Airbyte Web UI 并添加您的第二个来源 - 选择 “Apify Dataset”
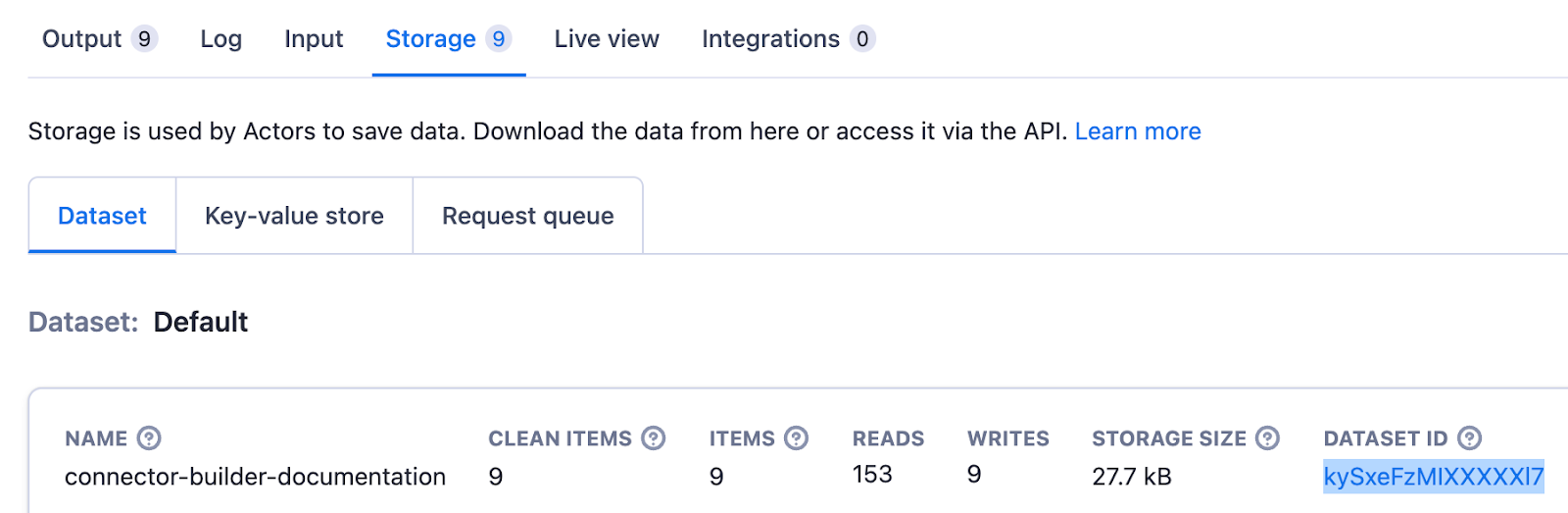
要设置来源,您只需要复制 Apify UI 中 “Run” 的 “Storage” 选项卡中显示的数据集 ID
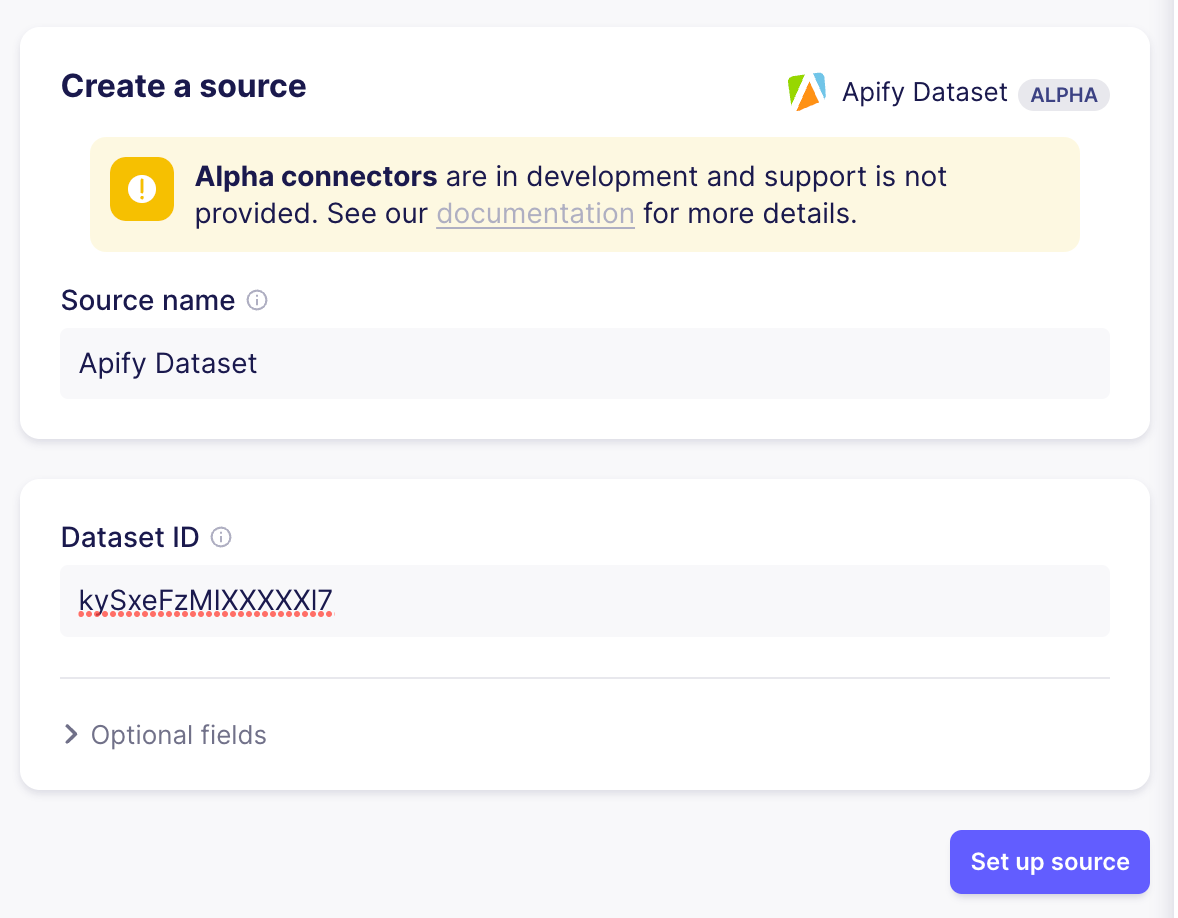
设置好来源后,按照与 Github 来源相同的步骤设置连接,将数据从 Apify 数据集移动到向量存储。由于相关的文本内容位于不同的字段中,因此您还需要更新向量存储目标 - 将 data.pageTitle 和 data.content 添加到目标的 “文本字段” 中并保存。
步骤 7 - 其他数据源:获取 Slack 消息
另一个与连接器开发相关的有价值信息来源是来自公共帮助频道的 Slack 消息。这些可以以非常相似的方式加载。使用 Slack 连接器创建一个新来源。使用云时,您可以使用 “验证您的 Slack 帐户” 按钮进行身份验证以进行简单设置,否则请按照右手边文档中的说明操作,了解如何创建具有所需权限的 Slack “应用” 并将其添加到您的工作区。为避免从所有频道获取消息,请将频道名称过滤器设置为正确的频道。
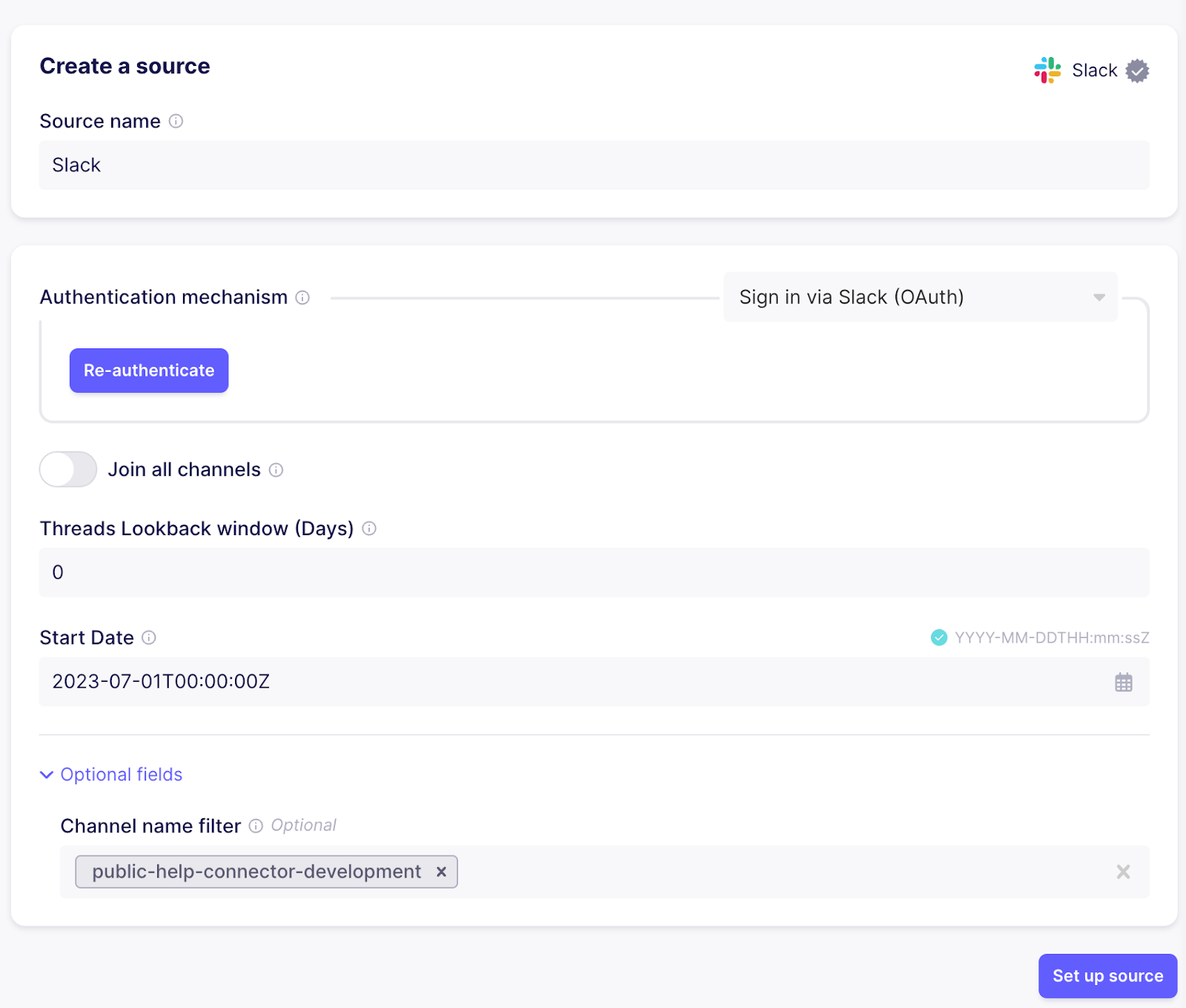
对于 Apify 和 Github,需要创建一个新连接,以将数据从 Slack 移动到 Pinecone。还将 text 添加到目标的 “文本字段” 中,以确保相关数据得到正确嵌入,以便相似性搜索能够产生正确的结果。
如果一切顺利,现在应该有三个连接,所有连接都将其各自来源的数据同步到使用 Pinecone 索引的集中式向量存储目标。
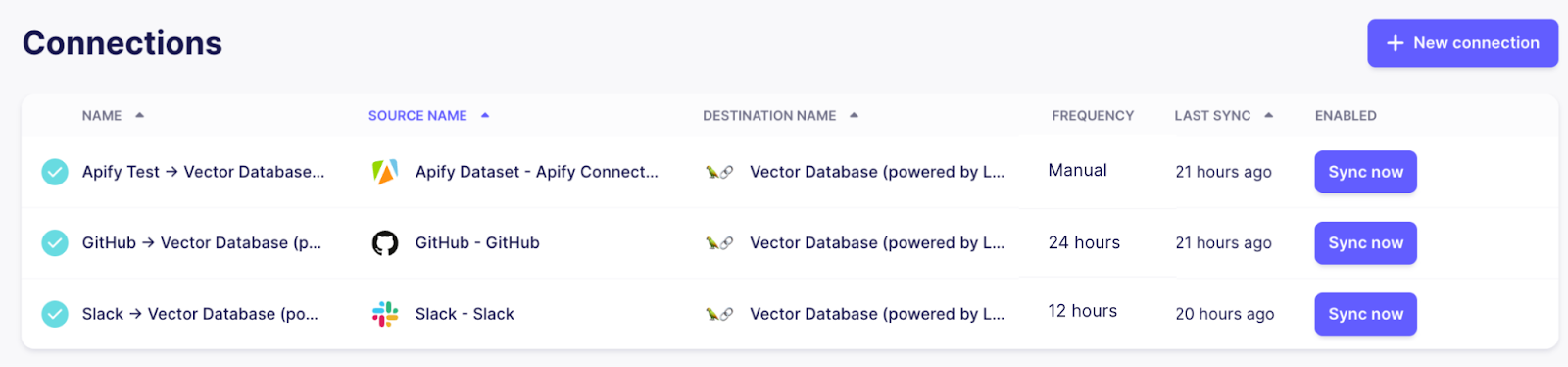
通过调整连接的频率,您可以控制 Airbyte 重新运行连接的频率,以确保我们的聊天机器人的知识库保持最新。由于 Github 和 Slack 经常更新并支持高效的增量更新,因此将其设置为每天或更高的频率是有意义的。文档页面不会经常更改,因此可以将其保持在较低的频率,甚至可以在有更改时按需触发。
由于我们现在有更多来源,让我们改进我们的提示,以确保 LLM 具有所有必要的信息来制定一个好的答案
class ContextualRetriever(VectorStoreRetriever):
def _get_relevant_documents(self, query: str, *, run_manager):
docs = super()._get_relevant_documents(query, run_manager=run_manager)
return [self.format_doc(doc) for doc in docs]
def format_doc(self, doc: Document) -> Document:
if doc.metadata["_ab_stream"] == "item_collection":
doc.page_content = f"Excerpt from documentation page: {doc.page_content}"
elif doc.metadata["_ab_stream"] == "issues":
doc.page_content = f"Excerpt from Github issue: {doc.page_content}, issue number: {int(doc.metadata['number']):d}, issue state: {doc.metadata['state']}"
elif doc.metadata["_ab_stream"] == "threads" or doc.metadata["_ab_stream"] == "channel_messages":
doc.page_content = f"Excerpt from Slack thread: {doc.page_content}"
return doc默认情况下,RetrievalQA 链检索前 5 个匹配的文档,因此如果适用,答案将同时基于多个来源
Connector development help bot. What do you want to know?
> What different authentication methods are supported by the builder? Can I authenticate a login endpoint that returns a session token?
The authentication methods supported by the builder are Basic HTTP, Bearer Token, API Key, and OAuth. The builder does not currently support authenticating a login endpoint that returns a session token, but this feature is planned and can be tracked in the Github issue #26341. This issue is not closed yet - the feature might not be shipped yet.关于基本 HTTP、Bearer Token、API Key 和 OAuth 的第一句话是从 关于身份验证的文档页面 中检索的,而第二句话指的是与之前相同的 Github 问题。
总结
我们在这里涵盖了很多内容 - 回顾一下,我们完成了以下部分
- 设置一个管道,将来自多个来源的非结构化数据加载到向量数据库中
- 实现一个应用程序,该应用程序可以以通用方式回答有关非结构化数据的纯文本问题
- 将此应用程序公开为 Slack 机器人
通过数据流经此系统,Airbyte 将确保您的向量数据库中的数据始终是最新的,同时仅同步连接来源中已更改的记录,从而最大限度地减少嵌入和向量数据库服务的负载,同时还提供正在运行的管道的当前状态的概览。
此设置未使用封装所有细节并使我们对调整行为和控制数据处理的选择有限的单个黑盒服务 - 相反,它由多个组件组成,这些组件可以在各个位置轻松扩展
- Airbyte 大量的来源目录和用于集成专用来源的连接器构建器允许使用单个工具轻松地将几乎任何数据加载到向量数据库中
- Langchain 非常可扩展,允许您以各种方式利用 LLM,而不仅仅是此简单应用程序,包括丰富来自其他来源的数据、保留聊天记录以进行完整对话等等
如果您有兴趣利用 Airbyte 将数据传输到基于 LLM 的应用程序,请花一点时间 填写我们的调查,以便我们可以确保优先考虑最重要的功能。