
编者按:这篇文章是与来自 ChatOpenSource.com 团队的作者 Ryan Brandt 合作撰写的。它详细介绍了微调如何有意义地提高模型性能。以及 LangSmith + LangChain 如何帮助您试验不同的模型,并衡量和比较结果。
无法为您的关键 AI 工作流程使用 gpt-3.5-turbo?那么现在是考虑微调的时候了。今天,我们将深入探讨其好处、准备步骤和成本削减优势,所有这些都将通过 Langchain 的 AI 评估器 LangSmith 进行测试。这是您一直在寻找的下一级升级。
为什么微调应该让您感兴趣
在 ChatOpenSource.com,我们认为当开箱即用的模型无法满足需求时,微调是您的下一步。当您可以教您的模型掌握上下文、语气和复杂性时,为什么还要不断地改写提示?或者那些麻烦的边缘案例。将其视为“展示”而不是“告诉”您的 AI 您需要什么。相信我,您会想坚持到最后以了解更多信息。
为什么微调是游戏规则改变者
- 确保风格、语气或格式的更高一致性。
- 提高您所需输出的可靠性。
- 提高模型对复杂或高度特定提示的理解。
- 更有效地处理独特的边缘案例。
- 在难以在提示中表达的任务中训练您的模型。
- 通过更短的整体提示和使用 `gpt-3.5-turbo* 而不是使用带有 `gpt-4` 的更大提示来节省成本
掌握数据准备:微调的秘诀
在深入微调之前,请准备一组强大的训练示例,以反映您期望模型处理的对话。确保每个数据集都符合 OpenAI 的 Chat completions API 指南,如下所示。
我们的示例训练设置在 System 角色下向聊天机器人提供指令,然后是 User 提示和相应的正确答案。
{
"messages": [{
"role": "system",
"content": "Given a product review, provide the following fields in a JSON dict, where applicable: \"product\", \"star_rating\", \"specific_likes\", and \"specific_dislikes\"."
},
{
"role": "user",
"content": "This desk chair gets 2 stars from me. It's uncomfortable and the height adjustment is faulty."
},
{
"role": "assistant",
"content": """{
"product": "desk chair",
"star_rating": 2,
"specific_likes": [],
"specific_dislikes": ["Uncomfortable", "faulty height adjustment"]
}"""
}
]
}
永远不要低估边缘案例示例的价值,尤其是在提示缺少生成结构化 JSON 输出的关键信息时。OpenAI 建议 gpt-3.5-turbo 微调至少使用 10 个示例,但包含的示例越多,性能优化程度越高。在本文中,我们仅使用 20 个训练示例来突出高质量数据集是多么强大。
微调的成本效益
不要低估微调在削减成本和延迟时间方面的能力。如果 gpt-4 对您来说一直很好用,您可能会发现微调后的 gpt-3.5-turbo 提供了相等甚至更好的结果——外加更快、更高效的操作优势。接下来,让我们深入了解价格模型如何叠加。
| 模型 | 训练 | 输入使用量 | 输出使用量 |
|---|---|---|---|
| GPT-3.5 Turbo 4K 上下文 | 不适用 | $0.0015 / 1K tokens | $0.002 / 1K tokens |
| GPT-3.5 Turbo 16K 上下文 | 不适用 | $0.003 / 1K tokens | $0.004 / 1K tokens |
| GPT-3.5 Turbo 微调 | $0.0080 / 1K tokens | $0.0120 / 1K tokens | $0.0160 / 1K tokens |
| GPT-4 8K 上下文 | 不适用 | $0.03 / 1K tokens | $0.06 / 1K tokens |
| GPT-4 32K 上下文 | 不适用 | $0.06 / 1K tokens | $0.12 / 1K tokens |
正如您所见,`gpt-4` 并不便宜,虽然目前依赖更大的上下文窗口很流行,但就目前而言,您的钱包不会喜欢。
LangSmith 评估如何工作
在我们揭示每个模型的性能之前,让我们先熟悉一下我们的评估过程。LangSmith 提供了现成的评估器,但您可以自由构建自己的评估器。在我们的案例中,我们利用 `gpt-4` 来评估来自各种模型的输出,使用思维链问答提示。如果模型的答案与预期响应不符,则标记为 INCORRECT。就像 DataDog 一样,您在您的端运行代码并将结果发送到 LangSmith 以进行日志记录和比较。
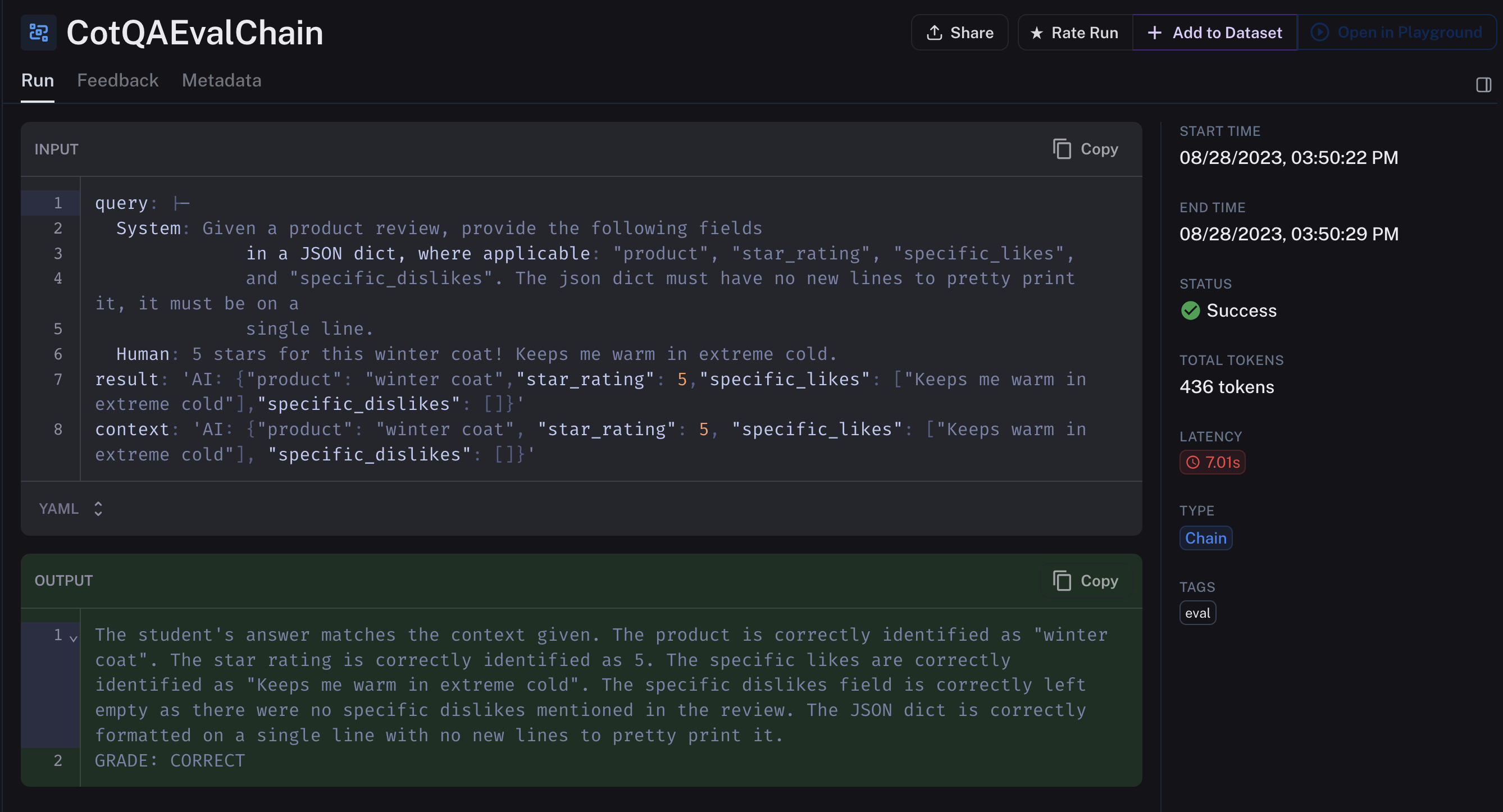
这是一个来自 gpt-3.5-turbo-finetuned 被评估的输出示例。gpt-4 使用输入中提供的上下文作为“正确”示例。您可以看到,基于该上下文,微调模型成功输出。
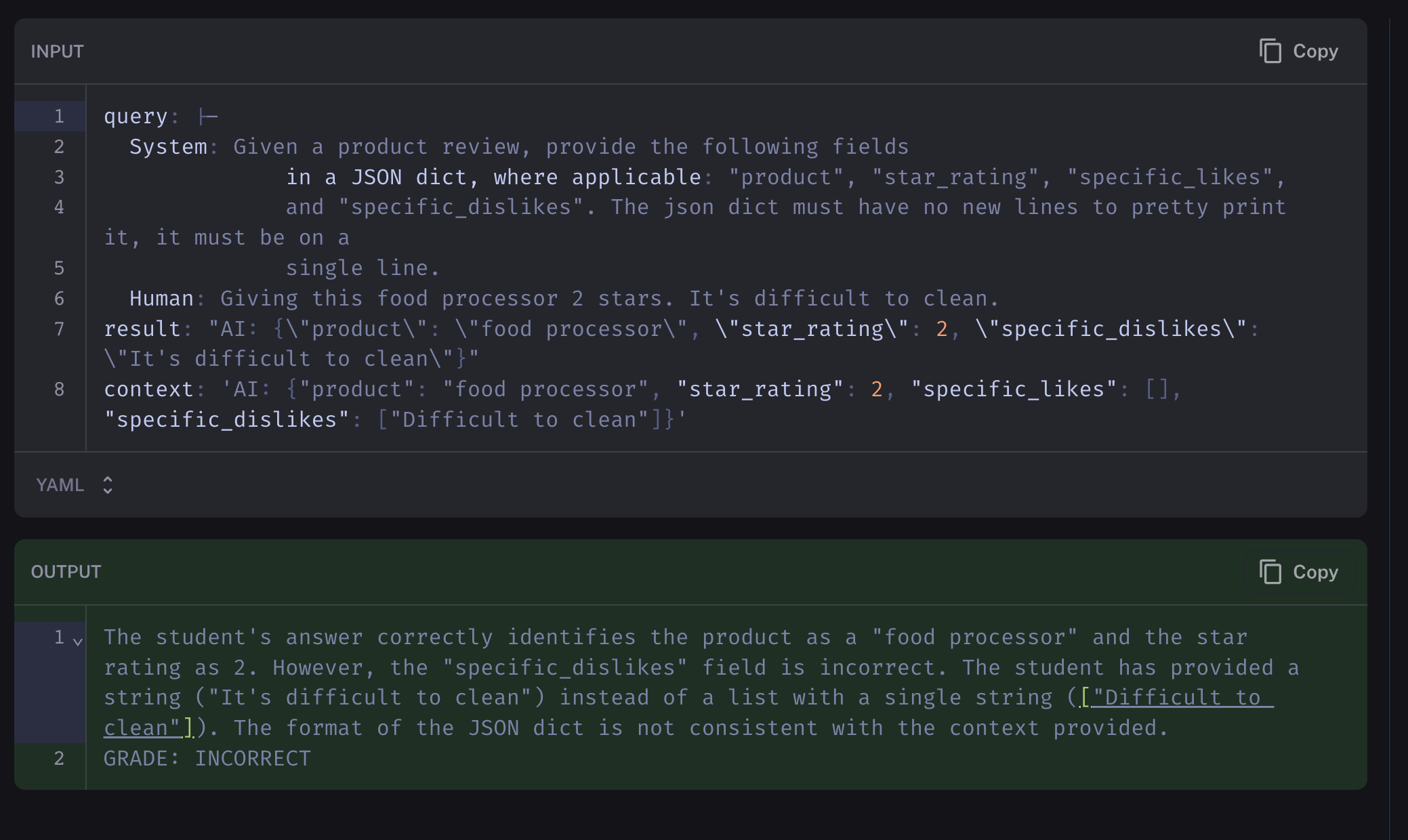
另一方面,gpt-4 使用相同的提示,未能通过相同的标准
基准测试性能
现在我们使用 LangSmith 来确定微调的有效性。我们通过评估基线 gpt-3.5-turbo,然后在我们的 gpt-3.5-turbo-finetuned 上执行相同的评估并比较结果来实现这一点。

当我评估基线 gpt-3.5-turbo 在 142 个示例产品评论时,它的中值运行时大约快三分之一。值得注意的是,我们微调模型的 P99 较高,但这并非每次我们运行测试时都是如此。
然而,真正有趣的是准确性。LangSmith 衡量 gpt-3.5-turbo-finetuned 的输出准确率为 99%。它只得到 1 个错误。让我们看看其他模型。
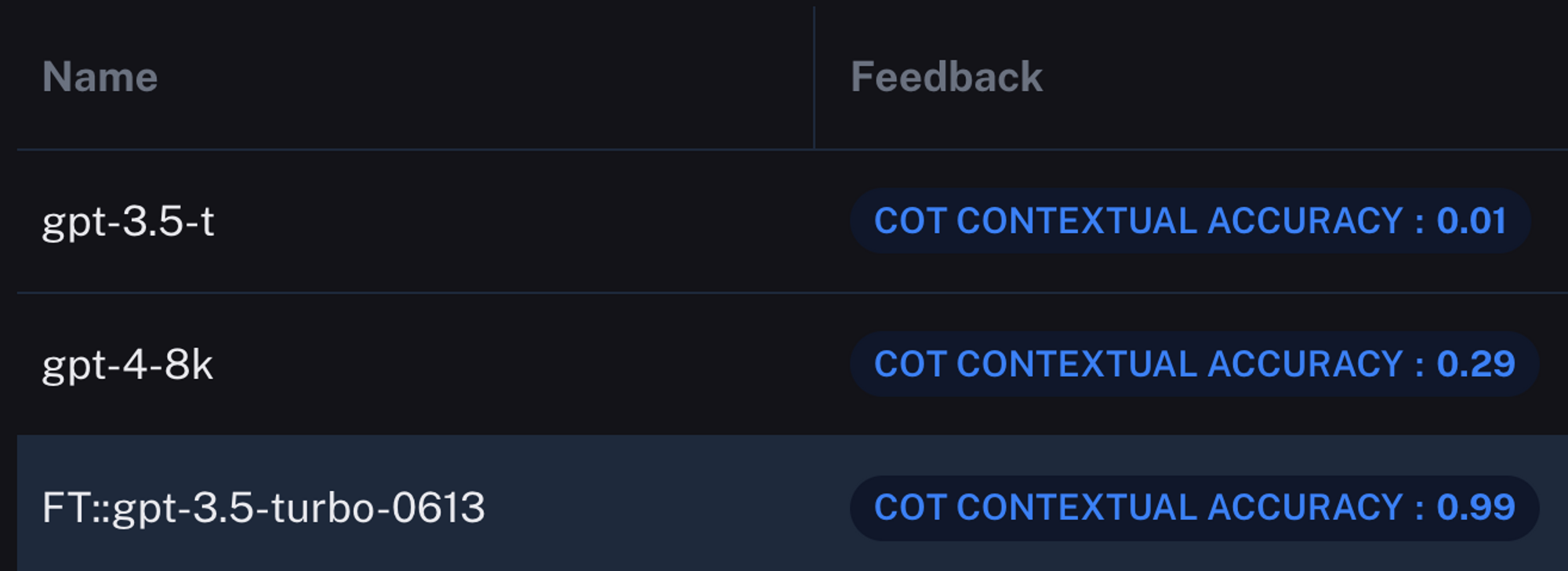
结果是……令人惊讶的。我们微调的模型在输出性能方面绝对超过了其基线自身及其升级后的 gpt-4。诚然,通过更大的提示,gpt-4 和可能的 3.5 可能已经达到了与微调模型相同的性能,但我们的测试对每个模型使用相同的提示,以强调结果的差异。
让我们插入之前的成本数字,以显示每次运行之间成本的差异,假设在低交易量生产环境中的使用情况
| 模型 | 输入 tokens | 输出 tokens | 输入成本 ($) | 输出成本 ($) | 训练成本 ($) | 总成本 ($) |
|---|---|---|---|---|---|---|
| gpt-3.5-t | 3,000,000 | 1,000,000 | 4.5 | 2 | 0 | 6.5 |
| ft:gpt-3.5-turbo-0613 | 3,000,000 | 1,000,000 | 36 | 16 | 0.2 | 52.20 |
| gpt-4-8k | 3,000,000 | 1,000,000 | 90 | 60 | 0 | 150 |
因此我们可以看到,虽然微调比基线贵了近 9 倍,但它大约比 gpt-4 便宜 3 倍,具有明显更高的准确性,并且中值响应时间快了近 4 倍。这些是巨大的数字!
结论
对于寻求优化其 AI 模型的组织而言,微调不仅是一种选择,而且是一种战略必需品。我们通过 LangSmith 证明,微调后的 gpt-3.5-turbo 模型在准确性、响应时间和成本效益方面可以显著优于其基线,甚至 gpt-4。不要错过为您的 LLM 增压的机会——这是您的公司一直等待的 AI 提升。
在 ChatOpenSource.com,我们是微调 OpenAI 和 llaama-2 等开源模型的首选专家。不要让 AI 革命将您的组织抛在后面。我们是定制高性能开源 AI 模型以适应您的数据的专家——所有这些都只需构建内部 ML 团队成本的一小部分。通过 www.ChatOpenSource.com 保持领先地位。