
Cleric 是一款旨在帮助工程团队调试生产问题的 AI 代理,专注于通常会消耗工程生产力的复杂、耗时的调查。
当警报触发时,Cleric 会自动开始使用现有的可观测性工具和基础设施进行调查。 像人类工程师一样,Cleric 同时检查多个系统 - 通过对生产系统的只读访问来检查数据库指标、网络流量、应用程序日志和系统资源。这种并行调查方法有助于快速识别复杂问题,例如跨微服务的级联故障。
Cleric 通过 Slack 与团队沟通,分享其调查结果并在需要时寻求指导。 无需学习新的工具——Cleric 与现有的可观测性堆栈协同工作,像人类工程师一样访问日志、指标和追踪。
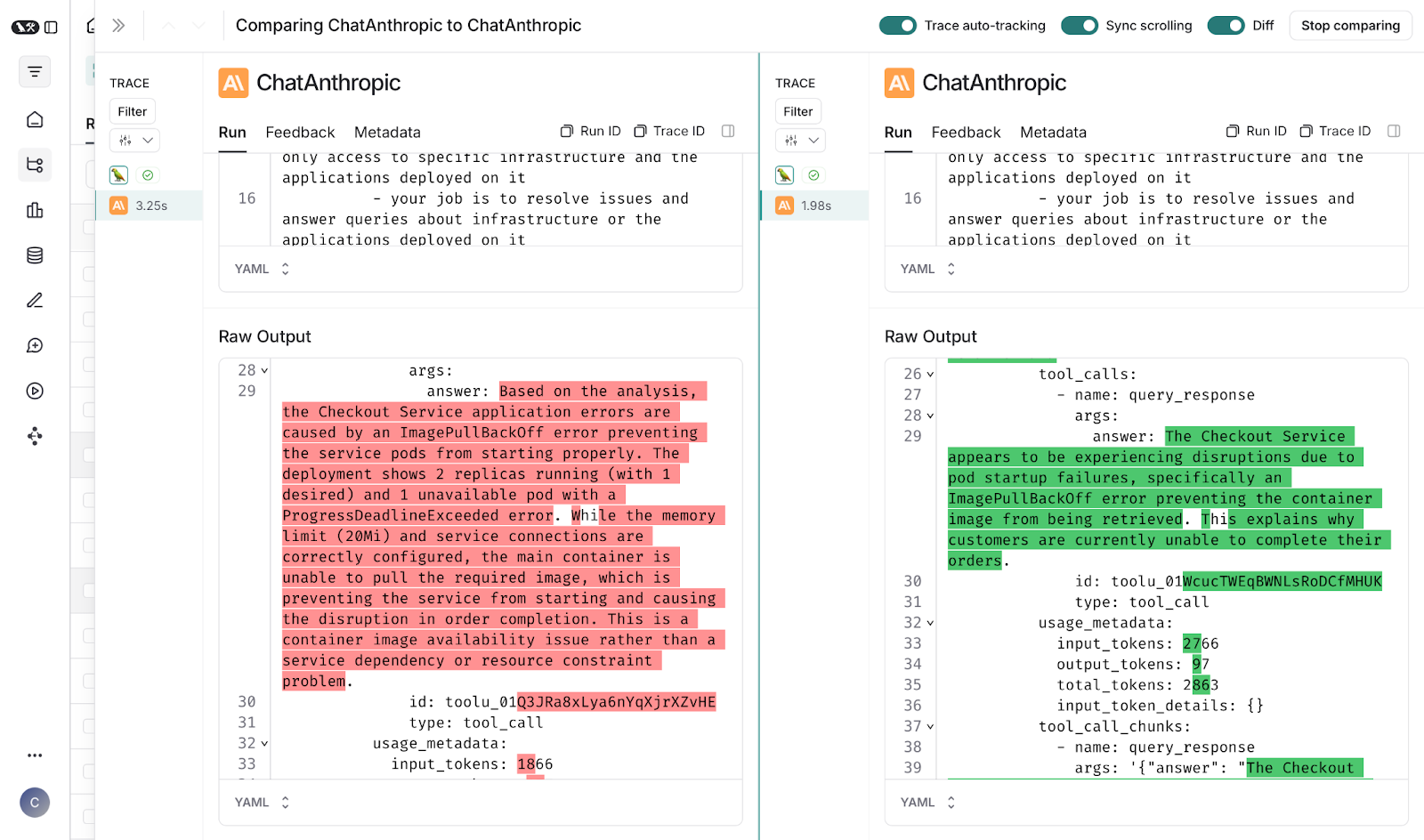
在 LangSmith 中进行生产问题的并发调查
生产问题提供了独特的学习机会,这些机会以后无法重现。 与代码生成不同,生产环境是有状态且动态的。 一旦问题得到解决,确切的系统状态就会消失,随之消失的还有从中学习的机会。
Cleric 团队需要同时测试不同的调查方法。 例如,一种调查路径可能优先检查数据库连接池和查询模式,而另一种则首先关注网络流量和系统资源。 这种设置创建了一个复杂的并发调查矩阵,因为 Cleric 使用不同的调查策略检查多个系统。
这种方法带来了一个新的挑战。 Cleric 团队如何监控和比较同时运行的不同调查策略的性能? 他们又如何确定哪些调查方法最适合不同类型的问题?
LangSmith 通过提供对这些并行调查和实验的清晰可见性,帮助解决了这个问题。 借助 LangSmith,Cleric 系统现在可以
- 并排比较不同的调查策略
- 跟踪跨所有系统的调查路径
- 汇总不同调查方法的性能指标
- 将用户反馈直接与特定的调查策略联系起来
- 对处理同一事件的不同方法进行直接比较
LangSmith 的追踪功能使 Cleric 团队能够分析数千个并发追踪的调查模式,衡量哪些方法始终能更快地解决问题。 这种数据驱动的验证对于构建可靠的自主系统至关重要,因为仅仅依靠一种曾经有效的方法不足以确保其具有通用性。
跟踪反馈和性能指标以概括跨部署的见解
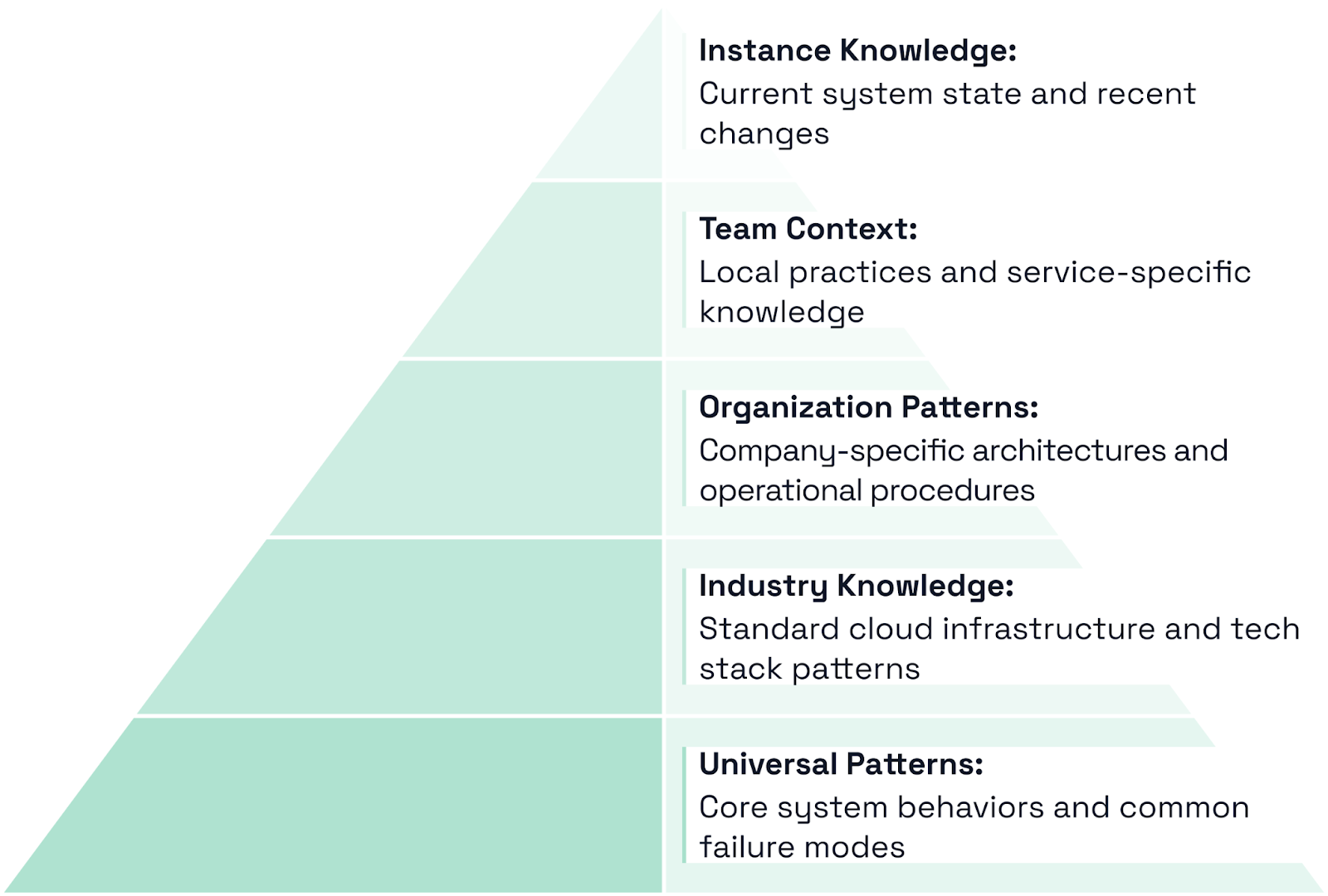
Cleric 从与每个客户环境中的交互中持续学习。 当工程团队对调查提供反馈(无论是正面还是负面)时,这都创造了改进未来调查的机会。 虽然在一个团队或公司内部学习很有价值,但 Cleric 也认识到概括所有部署中成功的调查策略的潜力。
挑战在于确定哪些学习是特定于团队或公司的,哪些代表可以帮助所有用户的更广泛的模式。 例如,在一种环境中有效的解决方案可能取决于其他地方不存在的特定内部工具或流程。
在概括任何学习之前,Cleric 采用严格的隐私控制和数据匿名化。 在分析或共享任何模式之前,所有客户特定的详细信息、专有信息和身份识别数据都会被剥离。
Cleric 使用 LangSmith 来管理这种持续学习过程
- 当 Cleric 完成调查后,工程师通过他们与 Cleric 的正常交互(Slack、工单系统等)提供反馈。
- 此反馈通过 LangSmith 的反馈 API 捕获,并直接与调查追踪相关联。 Cleric 存储调查的具体细节以及导致其解决的关键模式。
- 系统分析这些模式以创建通用的记忆,这些记忆剥离了特定于环境的细节,同时保留了核心问题解决方法。
- 这些通用的记忆随后在跨所有部署的新调查期间有选择地提供。 LangSmith 帮助跟踪何时以及如何使用这些记忆,以及它们是否改善了调查结果。
- 通过比较不同团队、公司和行业的性能指标,Cleric 可以确定每个学习的适当范围。 有些记忆可能仅在特定团队内有用,而另一些记忆则为所有客户部署提供价值。
LangSmith 的追踪和指标功能使 Cleric 团队能够衡量这些共享学习的影响。 该系统可以比较引入新记忆之前和之后的调查成功率、解决时间和其他关键指标。 这种数据驱动的方法有助于验证哪些学习真正概括到各个环境,哪些应该保留在特定客户的本地。
该系统允许 Cleric 维护单独的知识空间——用于独特环境和程序的客户特定上下文,以及不断增长的通用问题解决模式库,这些模式使所有用户受益。
通往自主、自愈系统的道路
生产系统正变得越来越自主。 工程的未来是构建产品,而不是运营它们。 Cleric 解决的每个事件都推动了这种转变,系统地将运营从人类工程师转移到 AI 系统,让团队专注于战略工作和产品开发。
Cleric 正在系统地构建这个未来,在保持生产系统所需的安全性和控制的同时扩展自主能力。 每次调查都有助于 Cleric 学习和改进,推动他们的客户朝着真正的自愈基础设施迈进。
如果您想帮助构建这个未来,请申请加入 Cleric 团队;要了解 Cleric 今天如何帮助您的团队,请联系我们。