
Wordsmith 是一款面向企业内部法律团队的 AI 助手,它使用由客户知识库驱动的 LLM 来审查法律文档、起草电子邮件和生成合同。与其他法律 AI 工具不同,Wordsmith 拥有来自领先律师事务所的深厚领域知识,并且易于安装和使用。它无缝集成到电子邮件和消息系统中,自动为法律团队起草回复,模拟与团队中另一人合作的感觉。
在过去几个月中,WordSmith 的 LLM 驱动功能呈指数级增长,其工程团队需要更好地了解 LLM 的性能和交互。LangSmith 对于理解生产环境中发生的情况以及衡量实验对关键参数的影响至关重要。下面,我们将详细介绍 LangSmith 如何在产品开发生命周期的每个阶段提供价值。
原型设计与开发:通过分层追踪应对复杂性
Wordsmith 的第一个功能是用于 Slack 的可配置 RAG 管道。现在它已发展为支持跨各种数据源和目标的复杂多阶段推理。Wordsmith 摄取 Slack 消息、Zendesk 工单、拉取请求和法律文档,在异构领域和 NLP 任务集上提供准确的结果。除了获得正确的结果外,他们的团队还需要使用来自 OpenAI、Anthropic、Google 和 Mistral 的 LLM 来优化成本和延迟。
LangSmith 已成为 Wordsmith 增长的关键,使工程师能够快速而自信地工作。凭借其作为追踪服务的基础性附加价值,LangSmith 帮助 Wordsmith 团队透明地评估LLM 在其复杂的多阶段推理链的每个步骤中接收和产生的内容。推理的分层组织结构使他们能够在开发周期中快速迭代,远快于他们仅依赖 Cloudwatch 日志进行调试时。
考虑以下代理工作流的快照,其中 GPT-4 制作了一个错误的 Dynamo 查询:
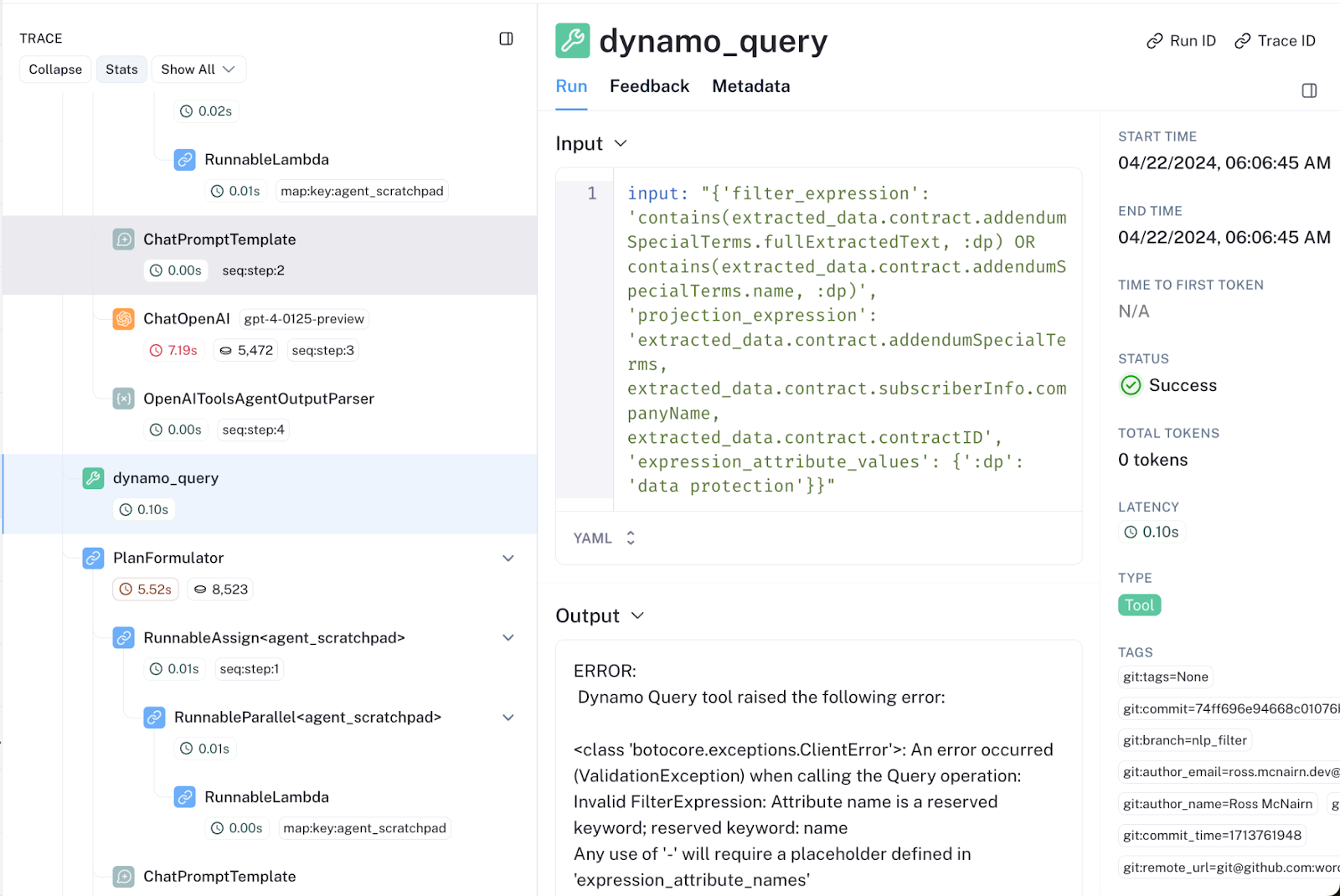
这些工作流可能包含多达 100 个嵌套推理,使得筛选通用日志以查找错误响应的根本原因既耗时又痛苦。借助 LangSmith 开箱即用的追踪界面,诊断中间步骤的性能不佳变得无缝衔接,从而大大加快了功能开发速度。
性能衡量:使用 LangSmith 数据集建立基线
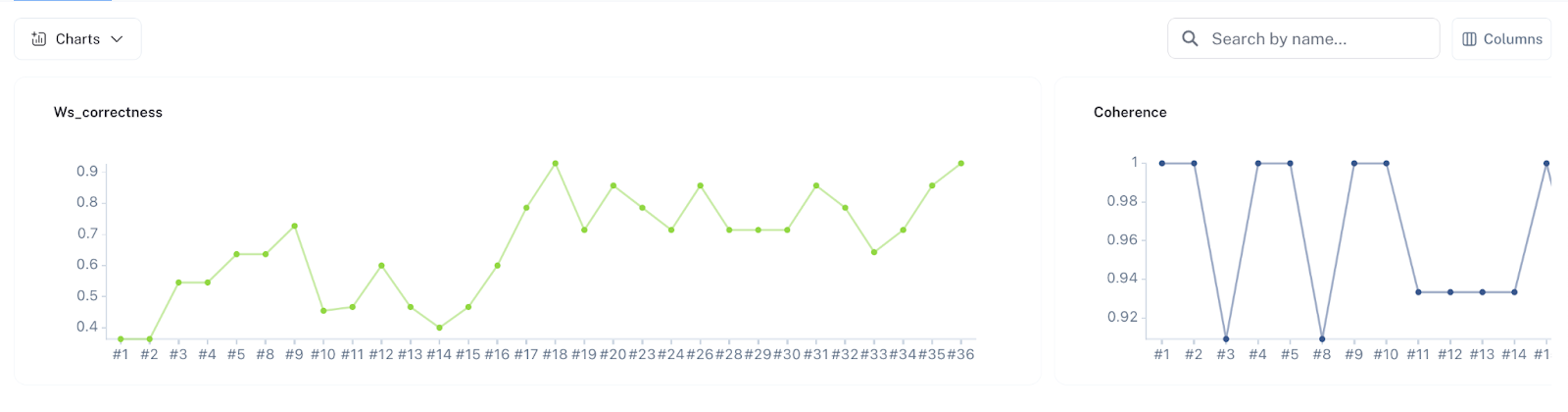
可复现的衡量标准有助于区分有前景的 GenAI 演示与可用于生产的产品。使用 LangSmith,Wordsmith 发布了各种评估集,用于各种任务,如 RAG、代理工作负载、属性提取,甚至基于 XML 的变更集目标——从而促进了它们在生产环境中的部署。
这些静态评估集提供以下关键优势:
- 评估集明确了 Wordsmith 功能的需求。通过迫使团队编写一组正确的问题和答案,他们为 LLM 设定了明确的期望和要求。
- 评估集使工程团队能够快速而自信地迭代。例如,当 Claude 3.5 发布时,Wordsmith 团队能够在 1 小时内将其性能与 GPT-4o 进行比较,并在当天将其发布到生产环境。如果没有明确定义的评估集,他们将不得不依赖临时查询,缺乏标准基线来自信地评估拟议的更改是否改善了用户结果。
- 评估集使 Wordsmith 团队能够在以准确性为关键约束的情况下优化成本和延迟。任务复杂性并非统一的,并且在可能的情况下使用更快、更便宜的模型已将特定任务的成本降低了高达 10 倍。与 (2) 类似,如果没有预定义的评估标准集,这种优化将非常耗时且容易出错。
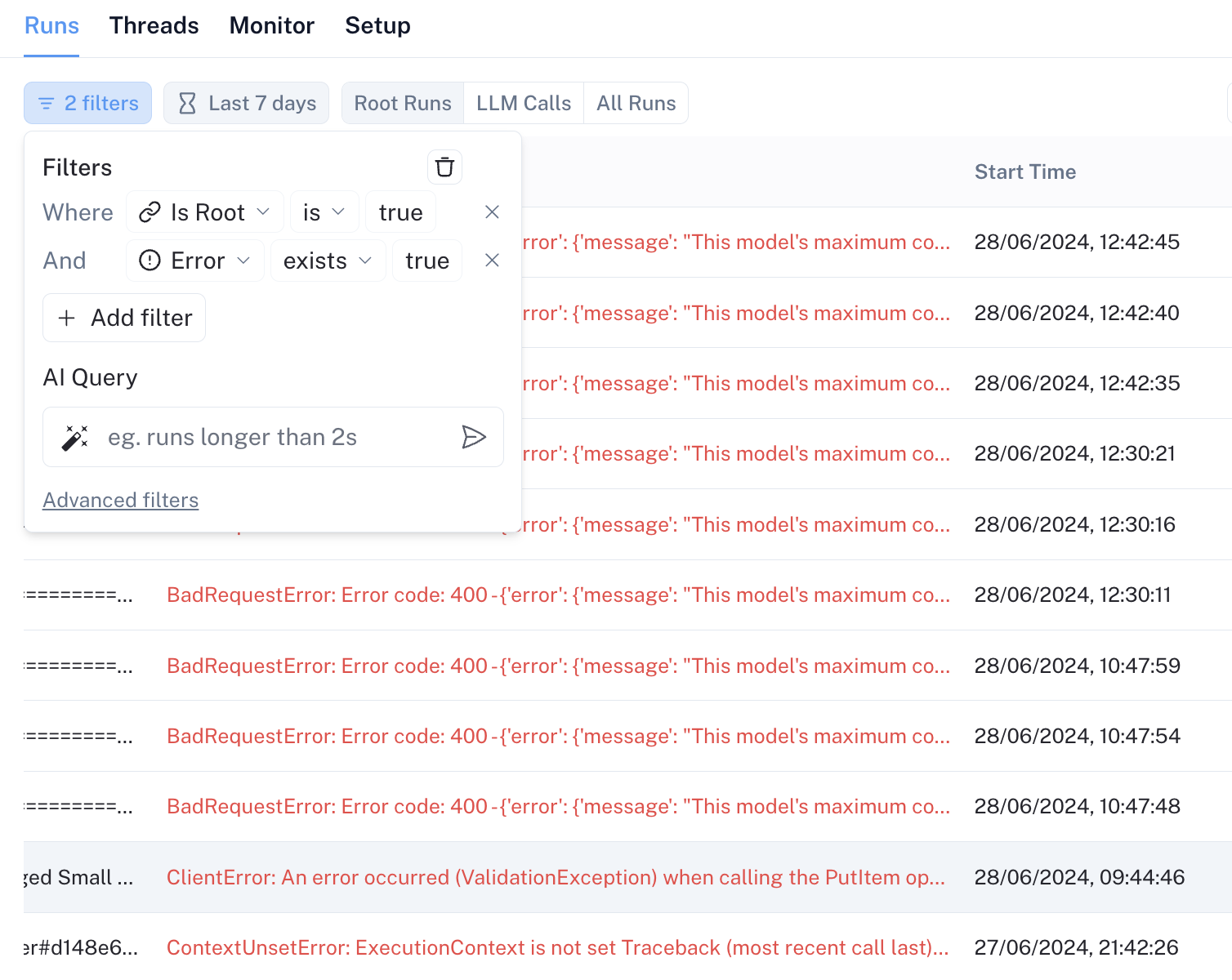
运营监控:通过 LangSmith 过滤器快速调试
使 LangSmith 成为开发理想选择的相同可见性功能也使其成为 Wordsmith 在线监控套件的核心组成部分。团队可以立即将生产错误链接到其 LangSmith 追踪,通过简单地遵循 LangSmith URL 而不是浏览日志,将调试推理的时间从几分钟缩短到几秒钟。
LangSmith 的索引查询也使其易于隔离与推理问题相关的生产错误:
在线实验:通过标签启用实验分析
Wordsmith 使用 Statsig 作为其功能标志/实验暴露库。利用 LangSmith 标签,可以轻松地将每次暴露映射到 LangSmith 中的相应标签,从而简化实验分析。
只需几行代码,我们就可以将每次实验暴露与相应的 LangSmith 标签关联起来
在 LangSmith 中,这些暴露可以通过标签进行查询,从而实现实验组之间的无缝分析和比较
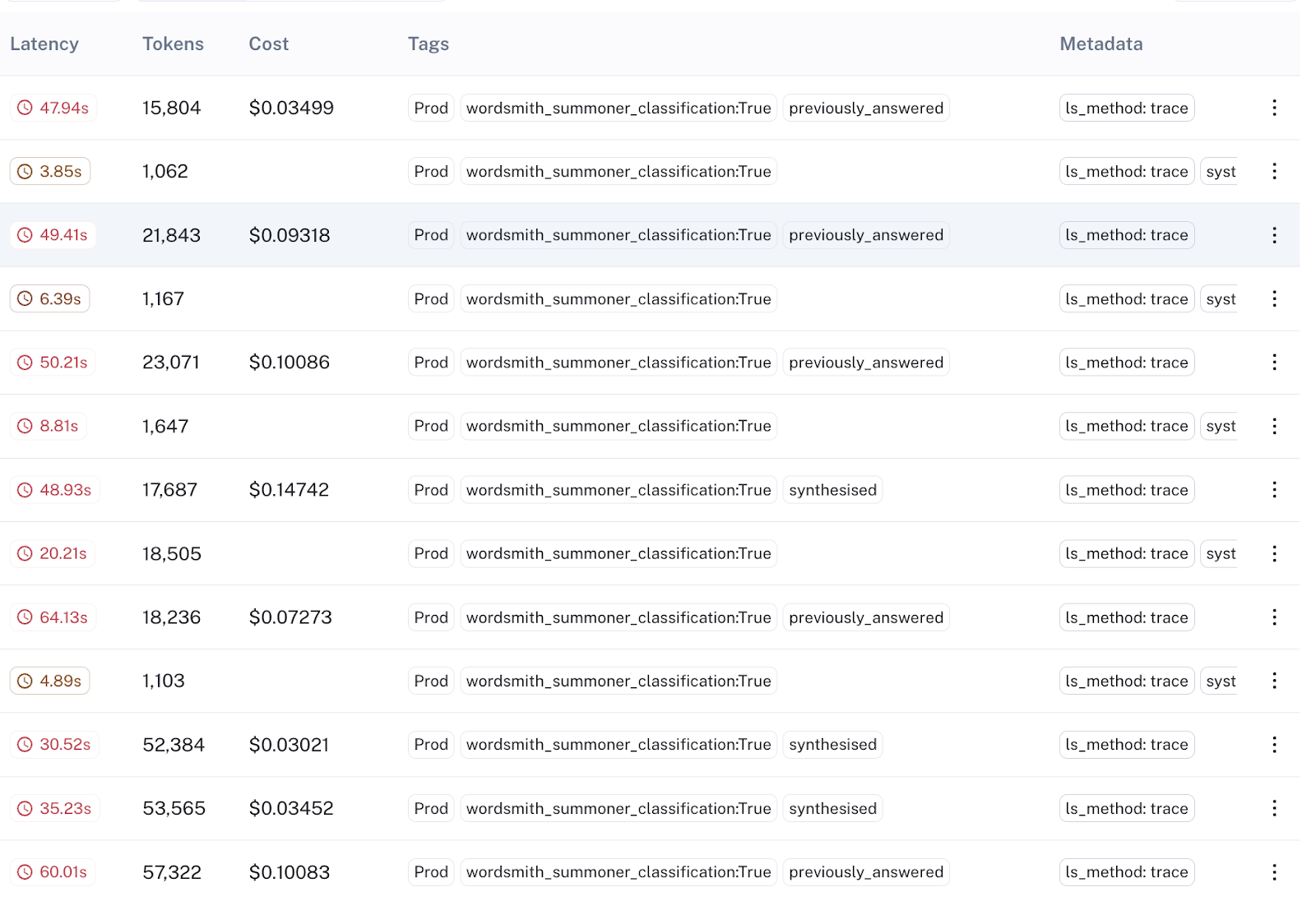
使用基本过滤器,他们可以在 LangSmith 中获取所有实验暴露,将其保存到新数据集中,并导出数据集以进行下游分析。因此,LangSmith 在 Wordsmith 产品的迭代实验和改进中起着至关重要的作用。
下一步:客户特定的超参数优化
在产品生命周期的每个阶段,LangSmith 都提高了 Wordsmith 团队的速度和产品质量的可见性。展望未来,他们计划将 LangSmith 更深入地集成到产品生命周期中,并应对更复杂的优化挑战。
Wordsmith 的 RAG 管道包含广泛且不断增加的参数集,这些参数控制管道的工作方式。这些参数包括嵌入模型、分块大小、排名和重新排名配置等。通过将这些超参数映射到 LangSmith 标签(使用类似于其在线实验的技术),Wordsmith 旨在创建在线数据集,以便为每个客户和用例优化这些参数。随着数据集的增长,他们设想一个世界,其中每个客户的 RAG 体验都将根据其数据集和查询模式自动优化。