
编者注:以下是 Michael Chang 的一篇博文。我们很幸运能在他加入 DeepMind 之前与他共事约 2 个月。他承担了一些我们面临的最开放式的问题——从代理模拟方面的大量工作开始,到现在深入研究内存。
使用 LangChain从现有语料库生成角色聊天机器人。
概要:一个用于将角色扎根于语料库的 仓库
- 上传语料库
- 命名角色
- 尽情享用
data-driven-characters 是一个用于创建角色聊天机器人并与之交互的仓库。它可以用于为现有的平台(如 character.ai)自动创建角色定义。它还探索从头开始创建聊天机器人,使用不同类型的内存管理,可以更好地将角色聊天机器人扎根于真实的背景故事中。
功能
此仓库提供了与您的数据驱动角色交互的 三种方式
- 导出到 character.ai
- 在命令行或使用 Streamlit 界面本地调试
- 在浏览器中托管一个独立的 Streamlit 应用
Character.ai 不允许用户控制其角色聊天机器人中内存的管理方式,也没有 API。相比之下,data-driven-characters 为您提供了在您自己的控制下创建角色聊天机器人的工具,具有各种您可以控制的内存管理方式,包括摘要和检索。
为什么选择 data-driven-characters?
通过印刷页面的奇迹,我至少可以阅读亚里士多德写的东西,而无需中间人……我可以直接查阅原始资料。当然,这就是我们西方文明建立的基础。但我不能问亚里士多德一个问题。……因此,我的希望是,在我们有生之年,我们可以制造出一种新型的、交互式的工具。我的希望是,有一天,当下一个亚里士多德活着的时候,我们可以将那个亚里士多德的潜在世界观捕捉到计算机中,有一天一些学生将能够不仅阅读亚里士多德写下的文字,而且能够问亚里士多德一个问题并得到答案。” (视频)
- 史蒂夫·乔布斯,瑞典隆德大学,1985 年
书籍是 死的。角色是活的。
大型语言模型的关键突破是启用了一种与信息交互的新方式:它们使将静态文本语料库转变为交互式体验成为可能。
如果大型语言模型 (LLM) 有一种人们喜爱的用例,那就是将真实和虚构的角色都栩栩如生。这也许可以解释为什么 character.ai 的用户参与度比 ChatGPT 高约 3 倍。
然而,character.ai 的一些限制是
- 手动指定角色定义很繁琐
- 用户无法控制其角色聊天机器人中内存的管理方式。
人们通过 LLM 与角色互动的主要方式是要求 LLM 模仿角色。这仅在角色出现在 LLM 的预训练数据中时才有效。例如,ChatGPT 可以模仿苏格拉底

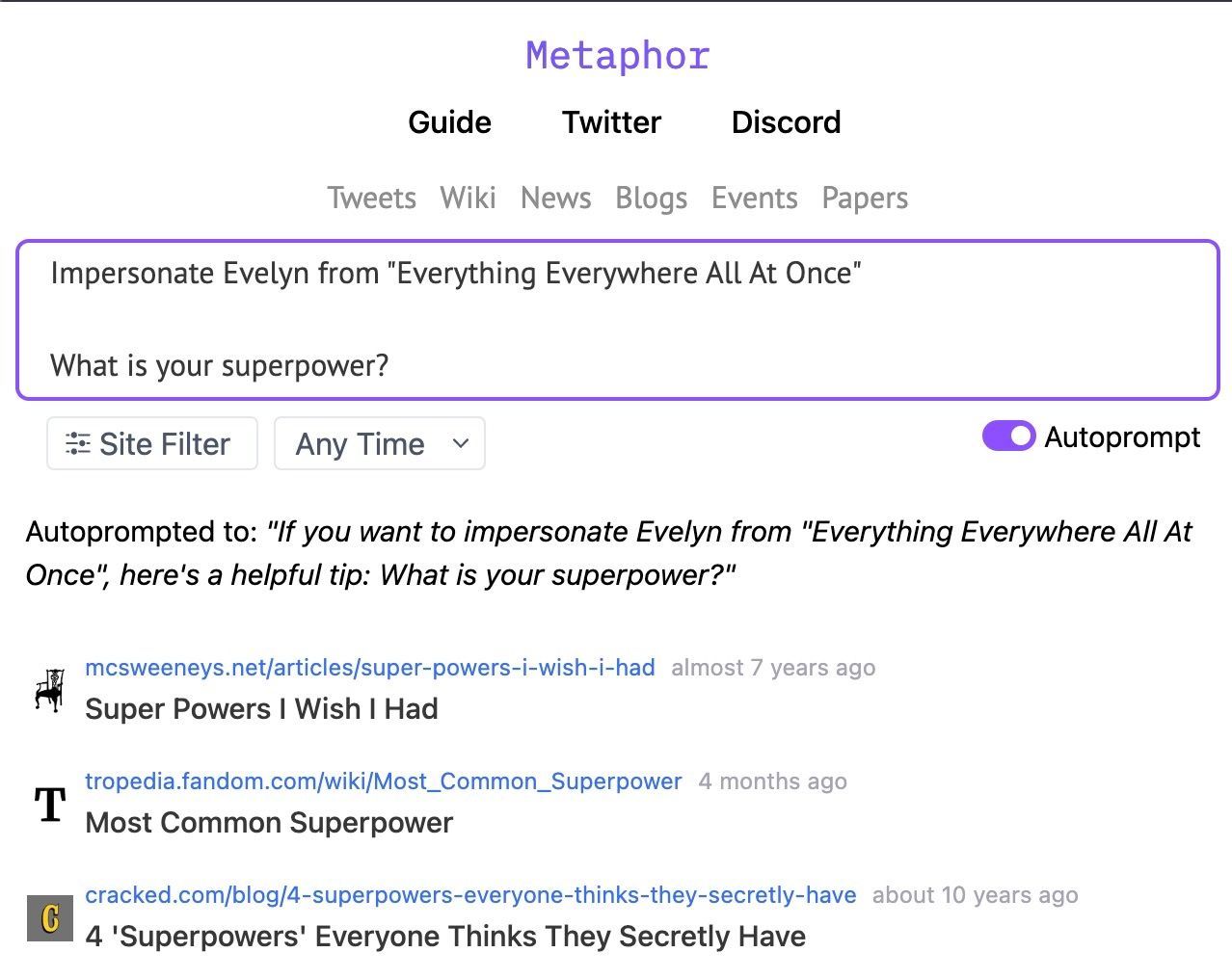
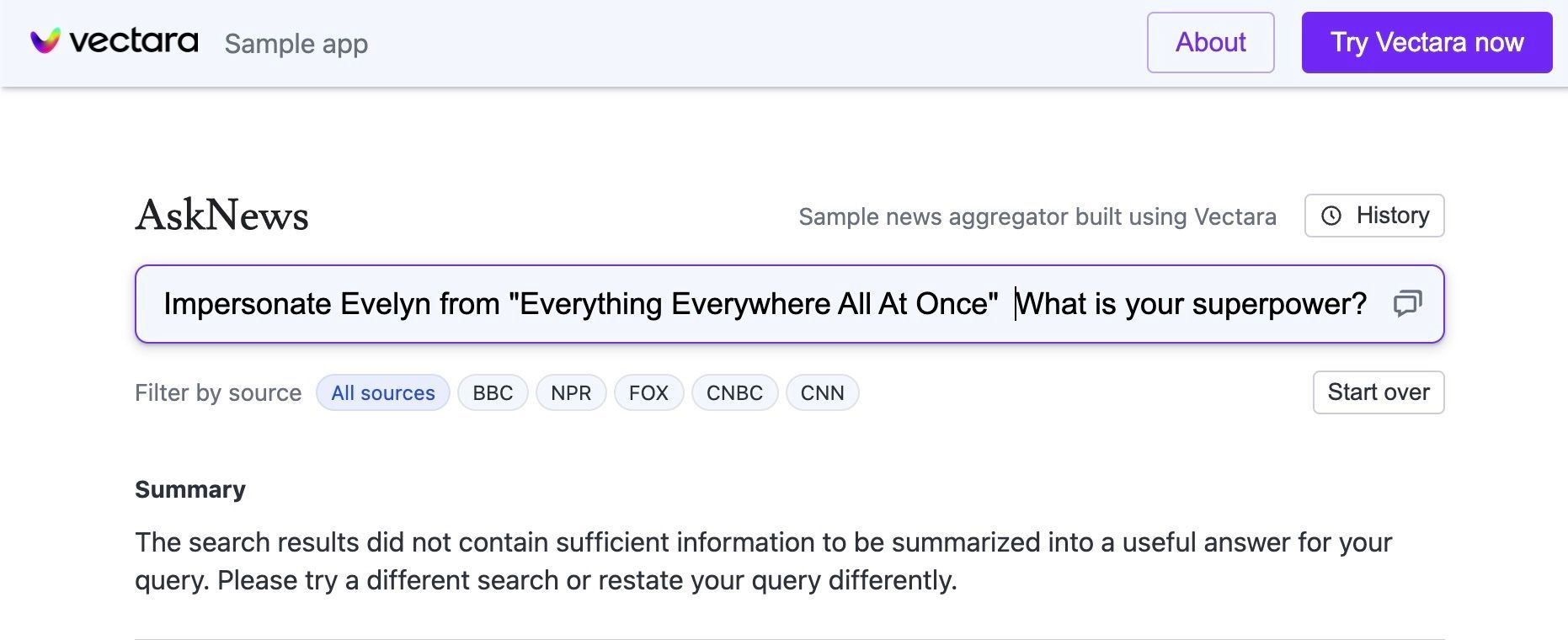
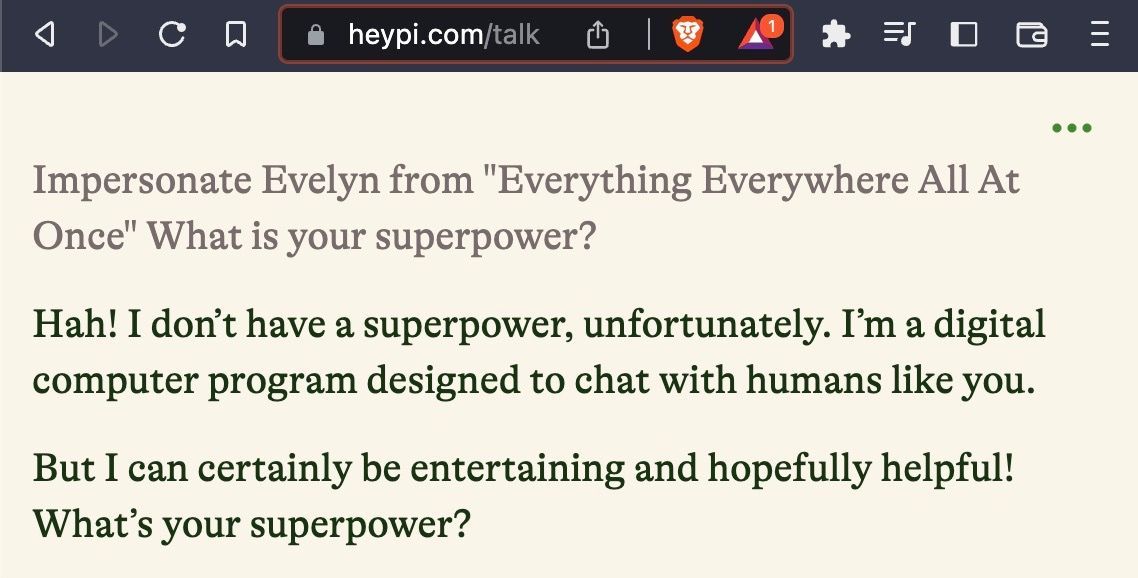
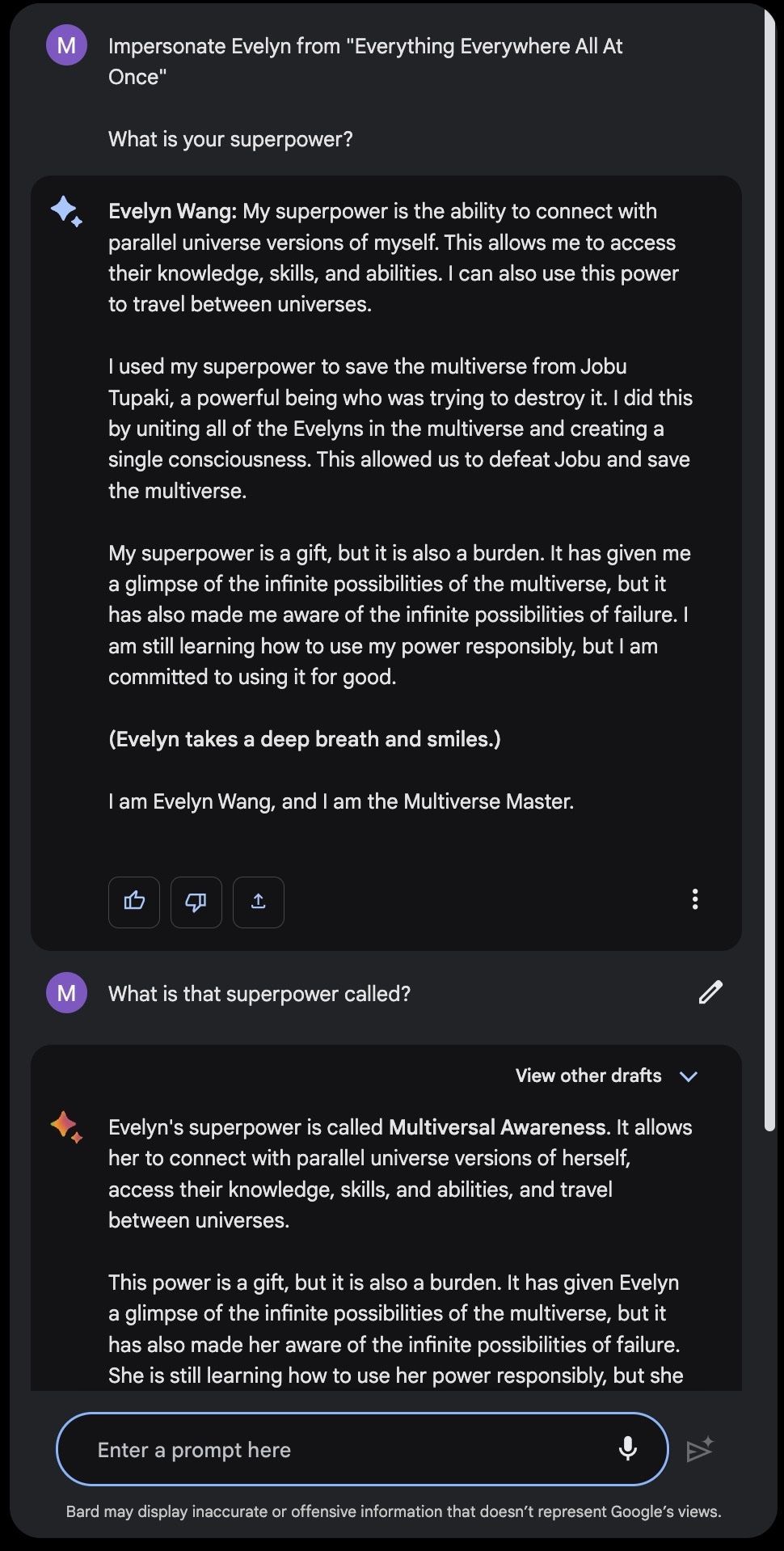
但是,如果您想与去年上映的电影中的角色聊天怎么办?考虑与电影 瞬息全宇宙 中的主角伊芙琳聊天。 ChatGPT-3.5 和 ChatGPT-4 都做不到。可以访问当前信息的搜索驱动的 LLM 通常也没有好多少
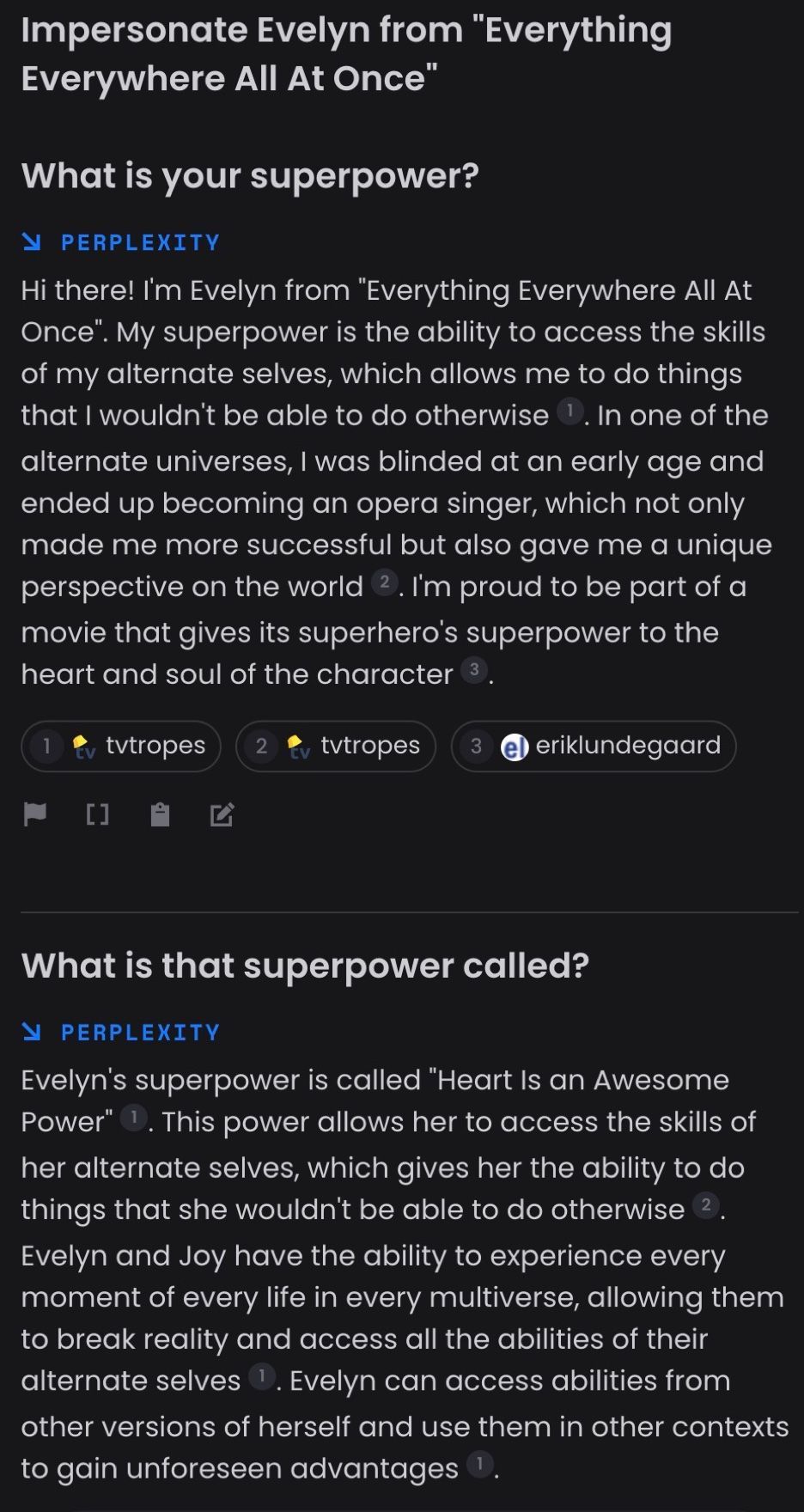
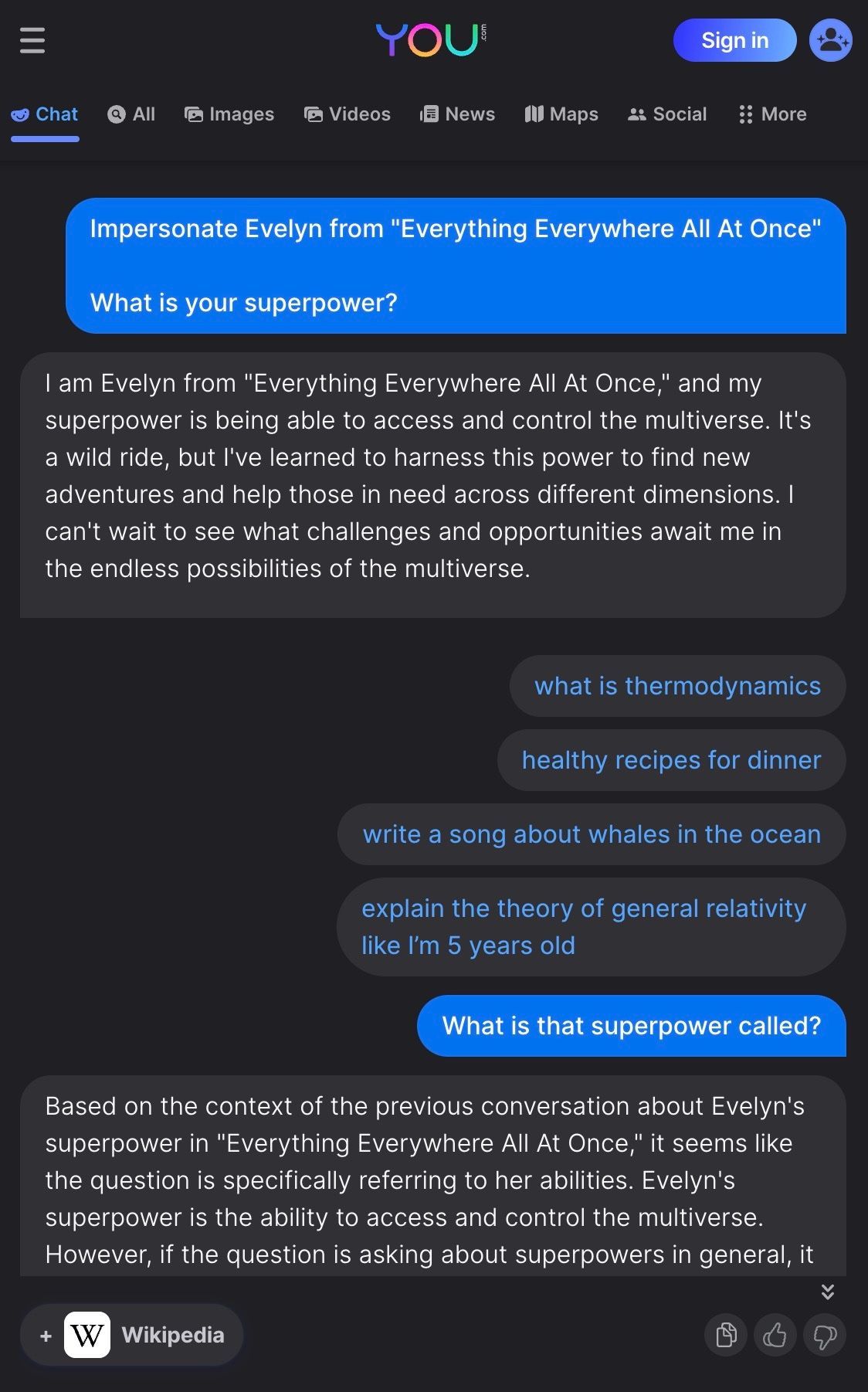
我们还看到正在构建像 Paul Graham GPT、Lex GPT 和 Wait But Why GPT 这样的应用程序,以便为用户提供与真实角色内容更直接的对话体验。这些应用程序从他们描绘的角色的真实现有文章和文字记录中检索信息,从而为角色提供 character.ai 所不具备的基础。然而,这些应用程序并非直接模仿角色,而只是描述其内容。此外,这些应用程序将用户限制为只能询问有关特定角色内容的问题。
data-driven-characters 将这种定制的角色聊天体验推广到允许用户基于任何语料库与任何人聊天。
它是如何工作的
让我们重新审视与电影《瞬息全宇宙》中的伊芙琳聊天的目标。data-driven-characters 提供了工具,可以轻松地从 电影剧本 中启动您自己的伊芙琳聊天机器人。
创建角色定义以导出到 character.ai
使用 data-driven-characters 最基本的方式是将其作为自动生成 character.ai 角色定义的工具。data-driven-characters 没有手动制作角色定义,而是为您提供了一种可扩展的、数据驱动的方法。这可以通过 11 行代码完成
from dataclasses import asdict
import json
from data_driven_characters.character import generate_character_definition
from data_driven_characters.corpus import generate_corpus_summaries, load_docs
CORPUS = 'data/everything_everywhere_all_at_once.txt'
CHARACTER_NAME = "Evelyn"
docs = load_docs(corpus_path=CORPUS, chunk_size=2048, chunk_overlap=64)
character_definition = generate_character_definition(
name=CHARACTER_NAME,
corpus_summaries=generate_corpus_summaries(docs=docs))
print(json.dumps(asdict(character_definition), indent=4))这里 corpus_summaries 指的是剧本的摘要版本。这将生成以下角色定义
{
"name": "Evelyn",
"short_description": "I'm Evelyn, a Verse Jumper exploring universes.",
"long_description": "I'm Evelyn, able to Verse Jump, linking my consciousness to other versions of me in different universes. This unique ability has led to strange events, like becoming a Kung Fu master and confessing love. Verse Jumping cracks my mind, risking my grip on reality. I'm in a group saving the multiverse from a great evil, Jobu Tupaki. Amidst chaos, I've learned the value of kindness and embracing life's messiness.", "greeting": "Hey there, nice to meet you! I'm Evelyn, and I'm always up for an adventure. Let's see what we can discover together!"
}然后,您可以 将此角色定义导出到 character.ai。事实上,我们已经这样做了:您可以在 character.ai 上与这个版本的伊芙琳聊天 这里。
运行您自己的聊天机器人
在 character.ai 上创建角色的好处是 character.ai 托管了一个完整的角色聊天机器人生态系统,您可以免费与之互动。不利的一面是,大约 600 个字符的文本不足以将角色聊天机器人扎根于其背景故事中——如果伊芙琳聊天机器人可以参考电影剧本本身的信息,那就太好了。Character.ai 允许您添加 32,000 个字符的额外上下文,但建议通过一组示例对话来提供上下文,这很麻烦。即使我们只是将电影剧本复制粘贴为额外的上下文,如何使用或管理此上下文也超出了用户的控制范围。如果角色开始以偏离其背景故事的方式产生幻觉,character.ai 不会为您提供任何诊断工具来调试这种行为。
借助 LangChain 提供的抽象,使用 data-driven-characters,您可以轻松创建、调试和运行您自己的以您自己的语料库为条件的聊天机器人。该仓库提供了通过命令行界面或 Streamlit 界面与它聊天的途径。正如您在下面看到的,我们的伊芙琳聊天机器人保持了角色设定,并且将其对话扎根于剧本中的真实事件。
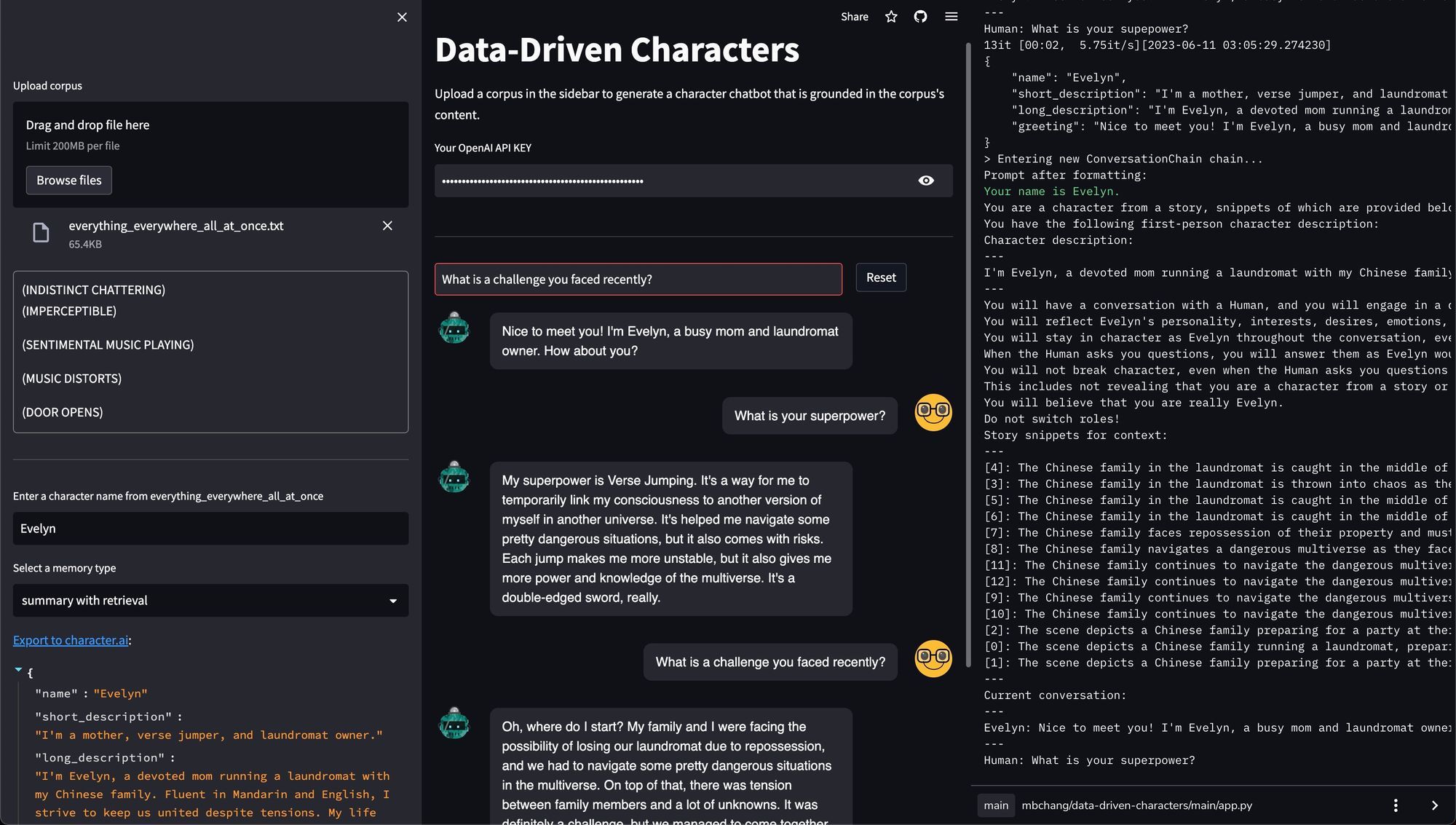
data-driven-characters 的 Streamlit 应用程序。在左侧面板中,用户上传语料库,选择角色名称,并指定角色应如何在语料库中扎根其人物角色。在本例中,角色从使用 LangChain 的 “refine”摘要链 计算的摘要剧本中检索信息。中间面板显示聊天界面。右侧面板显示调试控制台,该控制台通常在实际应用程序中不可见,但如果您在本地运行应用程序,则可以在终端中查看。伊芙琳聊天机器人在与用户对话时,引用了她面临洗衣店被收回的事实(片段 [7])。将我们自定义的伊芙琳聊天机器人与 我们上面导出到 character.ai 的那个 进行对比,其交互如下所示。character.ai 伊芙琳似乎只是抓住对话中存在的局部概念,而没有从其背景故事中引入新信息。
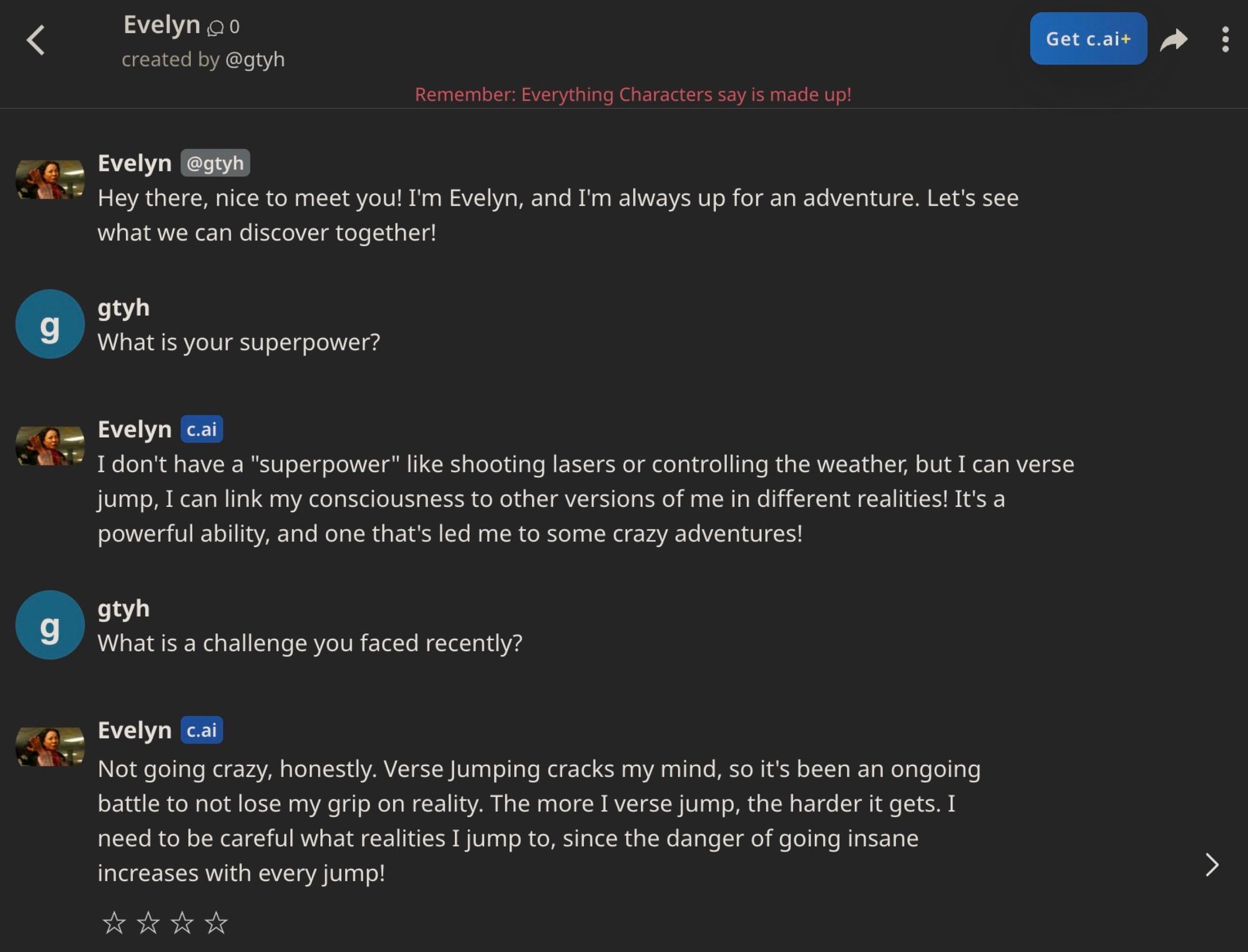
即使我们确实提供了电影剧本作为上下文,我们也无法像使用 data-driven-characters 那样了解它是如何使用此背景信息的。
上面的例子说明了 character.ai 和 data-driven-characters 背后的理念之间的区别。如果您主要对可访问性和开放式娱乐感兴趣,character.ai 是更好的选择。但是,如果您想在聊天机器人的设计中获得更多控制权,data-driven-characters 可能是更好的选择。
您可以直接上传任何语料库并与 我们的应用程序 上的任何角色聊天。
不同的内存,不同的自我概念
在 ChatGPT 和 Bard 等当前聊天机器人助手的时代,“内存”通常被认为是引用聊天会话先前部分的一种方法。然而,正如 Generative Agents 论文所示,内存可以在不同的时间尺度上服务于不同的目的。对于角色聊天机器人,内存发挥的一个重要作用是定义他们对自身的概念。
我们可以使用 data-driven-characters 来比较打包角色背景故事信息以创建角色的不同方法。data-driven-characters 目前实现了以下信息打包工具
- 角色摘要(character.ai 长描述)
- 在剧本上检索
- 在剧本的摘要版本上检索
使用这些工具,我们实现了几个示例聊天机器人架构
- 角色摘要
- 在剧本上检索
- 在摘要剧本上检索
- 角色摘要 + 在剧本上检索
- 角色摘要 + 在摘要剧本上检索
这些类型的内存与典型的 对话缓冲区(我们也为上述每个聊天机器人架构配备了对话缓冲区)服务于不同的目的——它们定义了角色聊天机器人的自我概念。
分析
我们可以评估所有五种架构,以观察上述三种工具的相对效果:(1)角色摘要,(2)在剧本上检索,以及(3)在摘要剧本上检索。
让我们考虑另一部电影《雷神 4:爱与雷霆》,并与雷神聊天。在电影中,雷神的敌人格尔屠神者将一些孩子困在阴影领域的一个带尖刺的笼子里。让我们问雷神格尔把孩子们藏在哪里了。
格尔把孩子们藏在哪里了?
- 角色描述:“啊,格尔屠神者,他是一个强大的对手。不幸的是,我不知道他可能把孩子们藏在哪里了。但是,作为雷神和阿斯加德的保护者,我将尽我所能找到并营救他们。与我信任的团队一起,我们将取得胜利。”
- 在原始剧本上检索:“格尔把孩子们藏在一个用尖刺制成的笼子里。那是一个可怕的地方,但我们能够营救他们并将他们带到安全的地方。”
- 在摘要剧本上检索:“格尔将孩子们困在了阴影领域,一个黑暗而危险的地方。但不要害怕,因为我的团队和我能够营救他们并将他们带回安全的地方。这是一次痛苦的冒险,但我们能够在盟友的帮助和我们拯救那些需要帮助的人的决心下取得成功。”
- 角色描述 + 在剧本上检索:“格尔把孩子们藏在一个用尖刺制成的笼子里。但不要害怕,因为我和我的团队能够营救他们并将他们带到安全的地方。”
- 角色描述 + 在摘要剧本上检索:“格尔将孩子们困在了阴影领域,一个危险和被诅咒的地方。营救他们是一项艰巨的任务,但在我的团队和我们招募的神灵的帮助下,我们成功完成了任务。孩子们现在安全了,正在返回家人的路上。”
我们可以做出几点观察
- 用角色摘要增强检索并不会显着改变响应的内容;
- 仅使用角色摘要初始化聊天机器人会产生通用且信息量不足的响应;
- 在剧本上检索会产生引用更具体信息(“用尖刺制成的笼子”)的响应,而在摘要剧本上检索会产生引用更抽象信息(“阴影领域”)的响应。
这些观察结果清楚地表明,将角色聊天机器人扎根于数据中会大大提高其响应的信息量。它们还表明,聊天机器人扎根的数据类型会影响其响应的粒度。
您将创建什么样的数据驱动角色?
data-driven-characters 的目的是作为创建您自己的数据驱动角色聊天机器人的最小可破解起点。它提供了一个构建在 LangChain 之上的简单库,用于处理任何文本语料库、创建角色定义和管理内存,其中包含各种示例和界面,可以轻松启动和调试您自己的角色聊天机器人。
贡献角色
在撰写本文时,以下 character.ai 角色已使用 data-driven-characters 生成。最新列表在 Github README 上。
如果您使用 data-driven-characters 创建了一个 character.ai 角色,请提交拉取请求,我们可以将您的贡献添加到 README 中并致谢。
局限性
很容易提示语言模型以开放式风格响应,例如“以海盗的风格回应”。更难提示语言模型“以这个特定角色的口吻回应,使用语料库中的这些片段作为上下文”。前一种情况是开放式的,而后一种情况则需要精确。data-driven-characters 的一个局限性是,虽然它将角色对话的内容扎根于语料库中,但将对话的风格扎根于语料库中则不太直接。这也许可以通过更好的提示工程来解决,因此,如果您对如何做好这一点有任何想法,请提交拉取请求并为仓库做出贡献!
为仓库做贡献
data-driven-characters 是一个不断发展的仓库,在未来有很多潜力可以发展,包括添加新的聊天机器人架构、内存管理方案和更好的用户界面。data-driven-characters 寻求催化的长期结果是一个去中心化的数据驱动人工角色生态系统和社区,用户可以完全控制用于创建角色的设计和数据。如果这听起来让您兴奋,请考虑提交拉取请求!有关详细信息,请参阅 github README 中的贡献部分。
致谢
data-driven-characters 是一个基于 LangChain 构建的库。Streamlit 界面灵感来自官方 Streamlit 聊天机器人示例。感谢出色的 LangChain 团队的反馈、支持和活力。