
编者注:此文章与 Epsilla 团队合作撰写。随着越来越多的应用程序依赖检索增强生成 (RAG) 在专有数据之上构建个性化应用程序,向量数据库变得越来越重要。我们对 Epsilla 在帮助构建者快速准确地获取最相关的文档和数据点方面所做的工作感到非常兴奋。
通过利用 LLM 和向量数据库的优势,这种集成有望提供更丰富、更准确和更具上下文意识的答案。
人工智能的格局日新月异。随着开发者和企业寻求更有效的方式来利用大型语言模型 (LLM),LangChain 等集成工具正在为此铺平道路。在这篇文章中,我们将探讨 Epsilla 最近与 LangChain 的集成,以及它如何彻底改变问答领域。
LLM 驱动的问答管道中的检索增强生成 (RAG)
自 2022 年 10 月以来,ChatGPT 和其他大型语言模型 (LLM) 的采用和利用率大幅飙升。这些先进模型已成为人工智能领域的前沿领导者,在生成类人文本和理解细微查询方面提供了前所未有的能力。然而,尽管 ChatGPT 和类似的模型拥有强大的功能,但它们也存在固有的局限性。最重大的挑战之一是它们无法整合上次训练截止日期之后的更新知识,导致它们不了解此后发生的事件或发展。此外,虽然它们拥有广泛的通用知识,但它们无法访问专有或私有公司数据,而这些数据对于寻求定制见解或决策的企业而言通常至关重要。这就是检索增强生成 (RAG) 作为变革者介入的地方。RAG 通过动态检索外部来源的相关信息来弥合知识差距,确保生成的响应不仅真实而且是最新的。向量数据库通过实现高效和语义化的信息检索,在 RAG 机制中发挥着不可或缺的作用。这些数据库将信息存储为向量,使 RAG 能够根据输入查询的语义相似性快速准确地获取最相关的文档或数据点,从而提高 LLM 生成响应的准确性和相关性。
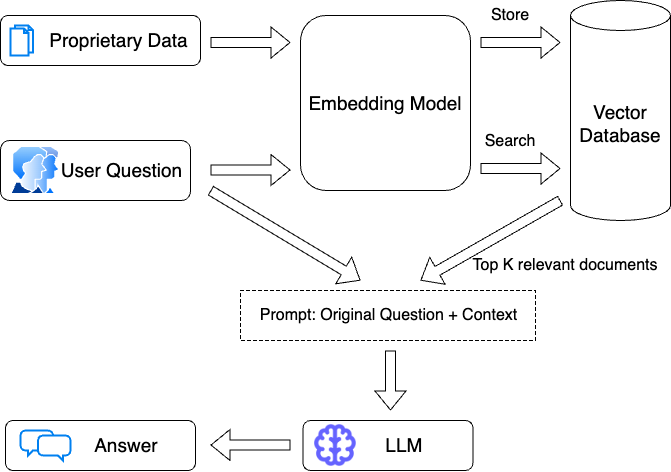
使用 LangChain 和 Epsilla 实现问答管道
LangChain 在 LLM 生态系统组件之上提供统一的接口和抽象层,简化了构建生成式 AI 应用程序的过程。借助 LangChain,开发人员可以避免样板代码,专注于交付价值。
通过 Epsilla 与 LangChain 的集成,现在 AI 应用程序开发人员可以轻松利用 Epsilla 提供的卓越性能(基准测试),同时构建 AI 应用程序中的知识检索组件。
以下是使用 LangChain 和 Epsilla 实现问答管道的分步指南。
步骤 1. 安装 LangChain 和 Epsilla
pip install langchain
pip install openai
pip install tiktoken
pip install pyepsilladocker pull epsilla/vectordb
docker run --pull=always -d -p 8888:8888 epsilla/vectordb步骤 2. 提供您的 OpenAI 密钥
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"步骤 3. 准备知识和嵌入模型
from langchain.embeddings import OpenAIEmbeddings
from langchain.document_loaders import WebBaseLoader
from langchain.text_splitter import CharacterTextSplitter
loader = WebBaseLoader("https://raw.githubusercontent.com/hwchase17/chat-your-data/master/state_of_the_union.txt")
documents = loader.load()
documents = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0).split_documents(documents)
embeddings = OpenAIEmbeddings()
步骤 4. 向量化知识文档
from langchain.vectorstores import Epsilla
from pyepsilla import vectordb
client = vectordb.Client()
vector_store = Epsilla.from_documents(
documents,
embeddings,
client,
db_path="/tmp/mypath",
db_name="MyDB",
collection_name="MyCollection"
)步骤 5. 创建 RetrievalQA 链,用于对上传的知识进行问答
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=vector_store.as_retriever())
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
这是回复
结论
Epsilla 与 LangChain 的集成标志着问答系统领域向前迈进了一大步。通过利用 LLM 和向量数据库的优势,这种集成有望提供更丰富、更准确和更具上下文意识的答案。随着人工智能继续重塑我们的世界,LangChain 等工具以及像 Epsilla 这样强大的向量数据库将处于这场变革的最前沿。
对于那些渴望深入了解的人,LangChain 的源代码以及与 Epsilla 的实现细节可在 Google Colab 上找到。