
编者按: 这篇文章是与 Ragas 团队合作撰写的。在 LangChain,我们经常思考和讨论的一个问题是,行业将如何发展以识别超越传统 ML Ops 指标的新监控和评估指标。Ragas 是一个令人兴奋的新框架,可以帮助开发人员以新的方式评估 QA 流水线。这篇文章展示了 LangSmith 和 Ragas 如何成为希望构建可靠 LLM 应用程序的团队的强大组合。
评估对团队的重要性是区分匆忙推出垃圾产品的人和认真构建该领域产品的人的主要区别。
这篇 HackerNews 评论 强调了在将应用程序从酷炫演示转变为可用于生产的产品时,拥有强大的评估策略的重要性。在构建 LLM 应用程序时尤其如此,因为为其提供支持的模型具有固有的随机性。您可以通过一些简短的训练并在一些示例上进行验证,轻松构建出令人印象深刻的 LLM 应用程序,但要使其更健壮,您必须在与生产分布匹配的测试数据集上对其进行测试。这是一个演进的过程,也是您将在应用程序的整个生命周期中进行的事情,但让我们看看 Ragas 和 LangSmith 如何在此处为您提供帮助。
本文将专门讨论 QA 系统(或 RAG 系统)。每个 QA 流水线都有 2 个组件
- 检索器 - 检索回答查询所需的最相关信息
- 生成器 - 使用检索到的信息生成答案。
在评估 QA 流水线时,您必须分别和一起评估这两个组件,以获得总体评分以及各个评分,从而确定您想要改进的方面。例如,使用更好的分块策略或嵌入模型可以改进检索器,而使用不同的模型或提示可以改变生成步骤。您可能想要衡量生成步骤中出现幻觉的倾向或检索步骤的召回率。
但是,您可以使用哪些指标和数据集来衡量和基准测试这些组件? 有许多用于评估 QA 系统的传统指标和基准,例如 ROUGE 和 BLUE,但它们与 人类判断的相关性较差。此外,您的流水线在标准基准(如 Beir)上的性能与生产数据之间的相关性可能会因两者之间的分布偏移而异。此外,构建这样的黄金测试集是一项昂贵且耗时的任务。
利用 LLM 进行评估
利用强大的 LLM 进行无参考评估是一种新兴的解决方案,它已显示出巨大的希望。它们比传统指标更能与人类判断相关联,并且还需要更少的人工注释。诸如 G-Eval 之类的论文已经对此进行了实验,并给出了有希望的结果,但也存在一些缺点。
LLM 偏爱输出自己的输出,当要求在不同输出之间进行比较时,这些输出的相对位置更为重要。当要求在给定范围内进行评分时,LLM 也可能对某个值存在偏差,并且它们也偏爱更长的响应。有关更多信息,请参阅 大型语言模型不是公平的评估器 论文。Ragas 旨在解决使用 LLM 评估 QA 流水线的这些局限性,同时还提供可操作的指标,使用尽可能少的注释数据,更便宜且更快。
介绍 Ragas
Ragas 是一个框架,可帮助您跨这些不同方面评估 QA 流水线。它为您提供了一些指标来评估 QA 系统的不同方面,即
- 用于评估检索的指标:提供
context_relevancy和context_recall,为您提供检索系统性能的度量。 - 用于评估生成的指标:提供
faithfulness,用于衡量幻觉,以及answer_relevancy,用于衡量答案与问题的相关程度。
这 4 个方面的调和平均值为您提供 ragas 分数,这是衡量 QA 系统在所有重要方面性能的单一指标。

大多数测量不需要任何标记数据,这使得用户更容易运行它,而无需担心首先构建人工注释的测试数据集。为了运行 ragas,您只需要几个问题,如果您使用 context_recall,则需要一个参考答案。(冷启动测试数据集的选项也在路线图中)
现在让我们看看 Ragas 的实际应用,并通过评估使用 Langchain 构建的 QA 链来尝试一下。
评估 QA 链
我们将基于 NYC 维基百科页面构建一个 QA 链,并在其之上运行我们的评估。这是一个非常标准的 QA 链,但请随时查看 文档。
from langchain.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
# load the Wikipedia page and create index
loader = WebBaseLoader("https://en.wikipedia.org/wiki/New_York_City")
index = VectorstoreIndexCreator().from_loaders([loader])
# create the QA chain
llm = ChatOpenAI()
qa_chain = RetrievalQA.from_chain_type(
llm, retriever=index.vectorstore.as_retriever(), return_source_documents=True
)
# testing it out
question = "How did New York City get its name?"
result = qa_chain({"query": question})
result["result"]
# output
# 'New York City got its name in 1664 when it was renamed after the Duke of York, who later became King James II of England. The city was originally called New Amsterdam by Dutch colonists and was renamed New York when it came under British control.'为了将 Ragas 与 LangChain 一起使用,首先从 ragas.metrics 导入您要使用的所有指标。接下来导入 RagasEvaluatorChain,它是一个 langchain 链包装器,用于将 ragas 指标转换为 langchain EvaluationChain。
from ragas.metrics import faithfulness, answer_relevancy, context_relevancy, context_recall
from ragas.langchain import RagasEvaluatorChain
# make eval chains
eval_chains = {
m.name: RagasEvaluatorChain(metric=m)
for m in [faithfulness, answer_relevancy, context_relevancy, context_recall]
}创建评估器链后,您可以通过 __call__() 方法使用 QA 链的输出来调用该链,以运行评估
# evaluate
for name, eval_chain in eval_chains.items():
score_name = f"{name}_score"
print(f"{score_name}: {eval_chain(result)[score_name]}")
# output
# faithfulness_score: 1.0
# answer_relevancy_score: 0.9193459596511587
# context_relevancy_score: 0.07480974380786602
# context_recall_score: 0.9193459596511587Ragas 在底层使用 LLM 进行评估,但以不同的方式利用它们来获得我们关心的测量结果,同时克服它们存在的偏差。让我们深入了解它们在底层的工作原理,以了解其工作方式。
底层原理
可选,不是遵循后续步骤的必需步骤,但有助于理解 ragas 的内部工作原理。
所有指标都在此处记录,但在本节中,让我们尝试了解每个 Ragas 指标的确切工作原理。
- Faithfulness(忠实度):衡量生成的答案在提供的上下文中的事实准确性。这分 2 个步骤完成。首先,给定一个问题和生成的答案,Ragas 使用 LLM 来找出生成的答案所做的陈述。这给出了我们需要检查其有效性的陈述列表。在步骤 2 中,给定陈述列表和返回的上下文,Ragas 使用 LLM 来检查所提供的陈述是否受上下文支持。对正确的陈述数量进行求和,然后除以生成的答案中的陈述总数,以获得给定示例的分数。
- Answer Relevancy(答案相关性):衡量答案与问题的相关性和切题程度。对于给定的生成答案,Ragas 使用 LLM 找出生成的答案可能回答的可能问题,并计算与实际问题的相似度。
- Context Relevancy(上下文相关性):衡量检索到的上下文中的信噪比。给定一个问题,Ragas 调用 LLM 以找出回答问题所需的检索上下文中的句子。所需句子与上下文中句子总数之间的比率为您提供分数
- Context Recall(上下文召回率):衡量检索器检索回答问题所需的所有必要信息的能力。Ragas 通过使用提供的 ground_truth 答案并使用 LLM 检查答案中的每个陈述是否可以在检索到的上下文中找到来计算此值。如果找不到,则意味着检索器无法检索到支持该陈述所需的信息。
了解每个 Ragas 指标的工作原理,您可以了解评估是如何执行的,从而使这些指标可重现且更易于理解。可视化 Ragas 结果的一种简单方法是使用 LangSmith 的 traces 和 LangSmith 的评估功能。现在让我们更深入地了解一下
使用 LangSmith 可视化评估
虽然 Ragas 为您提供了一些有见地的指标,但它并不能帮助您在生产中持续评估 QA 流水线的过程中。但这正是 LangSmith 的用武之地。
LangSmith 是一个平台,可帮助调试、测试、评估和监控在任何 LLM 框架上构建的链和代理。LangSmith 提供以下优势
- 一个用于创建和存储测试数据集并运行评估的平台。
- 一个用于可视化和深入研究评估结果的平台。使 Ragas 指标可解释和可重现。
- 如果您的应用程序也使用 LangSmith 进行监控,则可以从生产日志中持续添加测试示例的功能。
借助 RagasEvaluatorChain,您还可以使用 Ragas 指标来运行 LangSmith 评估。要了解有关 LangSmith 评估的更多信息,请查看 快速入门。
让我们从您需要在 LangSmith 内部创建数据集以存储测试示例的需求开始。我们将从一个小型数据集开始,其中包含 5 个问题和这些问题的答案(仅用于 context_recall 指标)。
# test dataset
eval_questions = [
"What is the population of New York City as of 2020?",
"Which borough of New York City has the highest population?",
"What is the economic significance of New York City?",
"How did New York City get its name?",
"What is the significance of the Statue of Liberty in New York City?",
]
eval_answers = [
"8,804,000", # incorrect answer
"Queens", # incorrect answer
"New York City's economic significance is vast, as it serves as the global financial capital, housing Wall Street and major financial institutions. Its diverse economy spans technology, media, healthcare, education, and more, making it resilient to economic fluctuations. NYC is a hub for international business, attracting global companies, and boasts a large, skilled labor force. Its real estate market, tourism, cultural industries, and educational institutions further fuel its economic prowess. The city's transportation network and global influence amplify its impact on the world stage, solidifying its status as a vital economic player and cultural epicenter.",
"New York City got its name when it came under British control in 1664. King Charles II of England granted the lands to his brother, the Duke of York, who named the city New York in his own honor.",
'The Statue of Liberty in New York City holds great significance as a symbol of the United States and its ideals of liberty and peace. It greeted millions of immigrants who arrived in the U.S. by ship in the late 19th and early 20th centuries, representing hope and freedom for those seeking a better life. It has since become an iconic landmark and a global symbol of cultural diversity and freedom.',
]
examples = [{"query": q, "ground_truths": [eval_answers[i]]}
for i, q in enumerate(eval_questions)]# dataset creation
from langsmith import Client
from langsmith.utils import LangSmithError
client = Client()
dataset_name = "NYC test"
try:
# check if dataset exists
dataset = client.read_dataset(dataset_name=dataset_name)
print("using existing dataset: ", dataset.name)
except LangSmithError:
# if not create a new one with the generated query examples
dataset = client.create_dataset(
dataset_name=dataset_name, description="NYC test dataset"
)
for q in eval_questions:
client.create_example(
inputs={"query": q},
dataset_id=dataset.id,
)
print("Created a new dataset: ", dataset.name)如果您转到 LangSmith 仪表板并检查数据集部分,您应该能够看到我们刚刚创建的数据集。
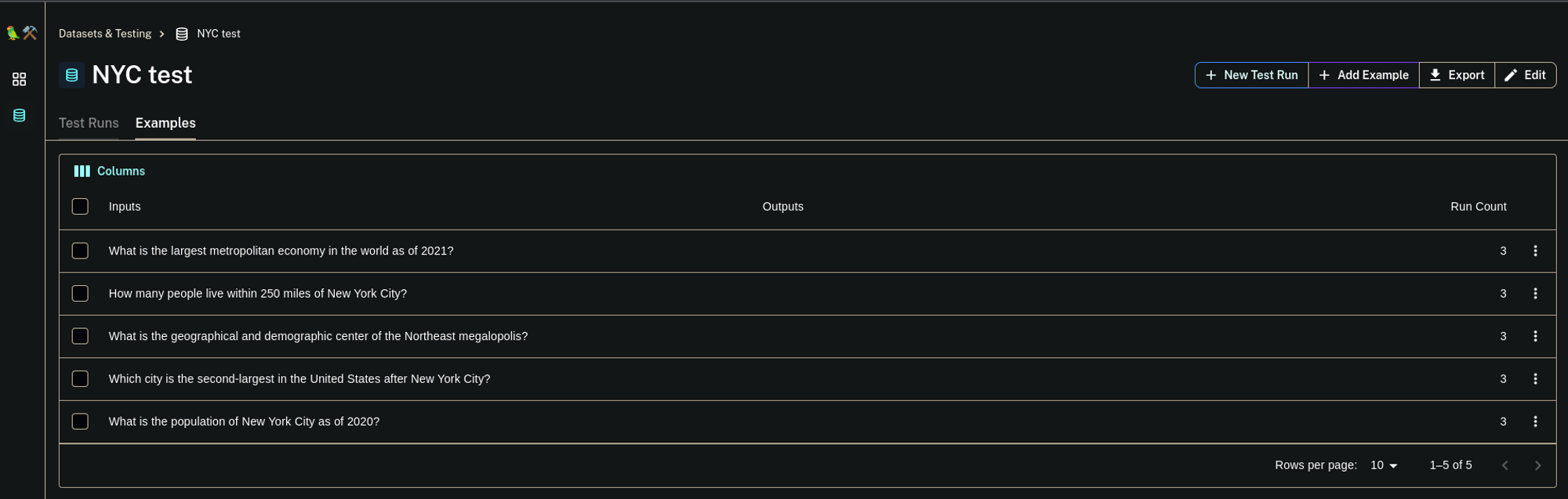
要运行评估,您必须从 LangSmith SDK 调用 run_on_dataset() 函数。但在那之前,您必须创建一个链工厂,该工厂每次调用时都会返回一个新的 QA 链。这样做是为了在评估单个示例时不会重用 QA 链中的任何状态。如果使用检查上下文的指标,请确保 QA 链返回上下文。
# factory function that return a new qa chain
def create_qa_chain(return_context=True):
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=index.vectorstore.as_retriever(),
return_source_documents=return_context,
)
return qa_chain现在让我们配置并运行评估。您可以使用 RunEvalConfig 来配置评估,其中包含您要针对其运行的指标/评估器链以及返回结果的 prediction_key。现在调用 run_on_dataset 和 LangSmith 以使用我们上传的数据集,并针对来自工厂的链运行它,并使用我们提供的 custom_evaluators 进行评估并上传结果。
from langchain.smith import RunEvalConfig, run_on_dataset
evaluation_config = RunEvalConfig(
custom_evaluators=[eval_chains.values()],
prediction_key="result",
)
result = run_on_dataset(
client,
dataset_name,
create_qa_chain,
evaluation=evaluation_config,
input_mapper=lambda x: x,
)
# output
# View the evaluation results for project '2023-08-24-03-36-45-RetrievalQA' at:
# https://smith.langchain.com/projects/p/9fb78371-150e-49cc-a927-b1247fdb9e8d?eval=true打开结果,您将看到类似这样的内容
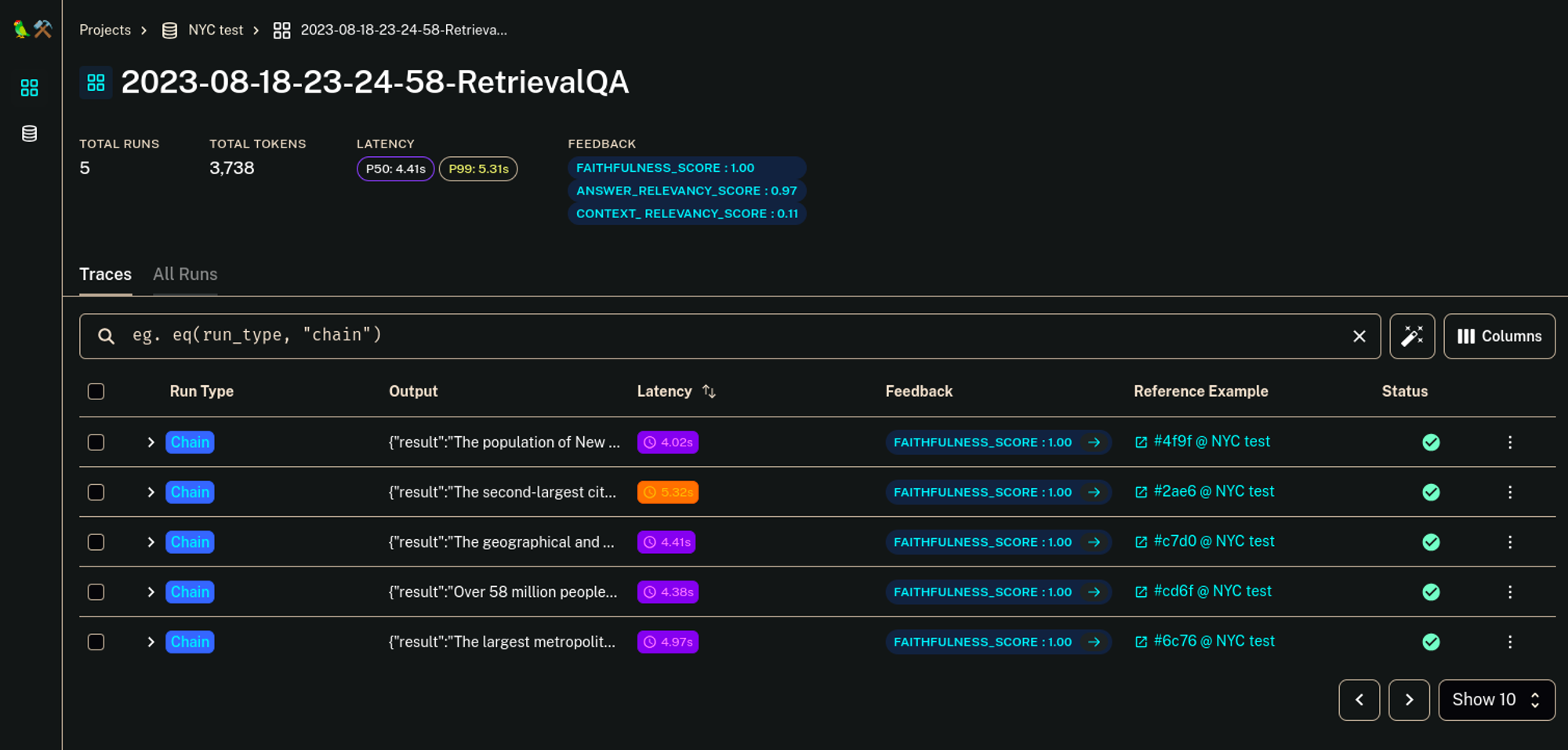
这显示了训练数据集中每个示例的输出,并且“反馈”列显示了评估结果。现在,如果您想更深入地了解分数的原因以及如何改进它们,请单击任何单个示例并打开“反馈”选项卡。
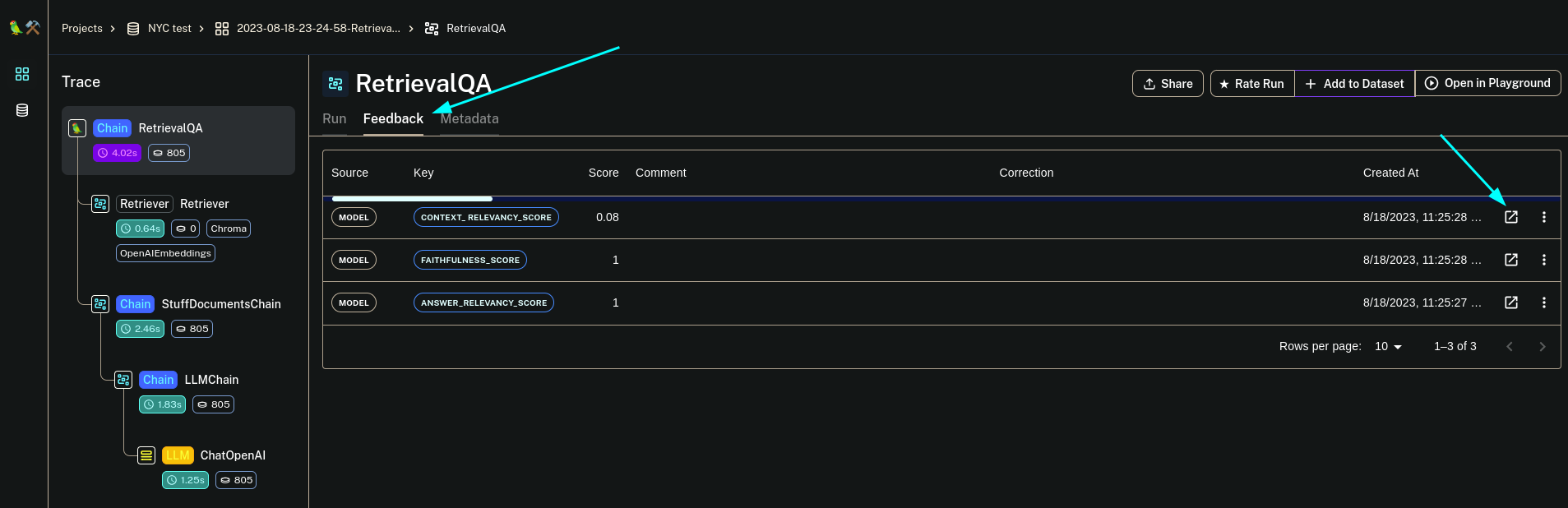
这将向您显示每个分数,如果您打开弹出图标,它将指向 RagasEvaluatorChain 的评估运行。
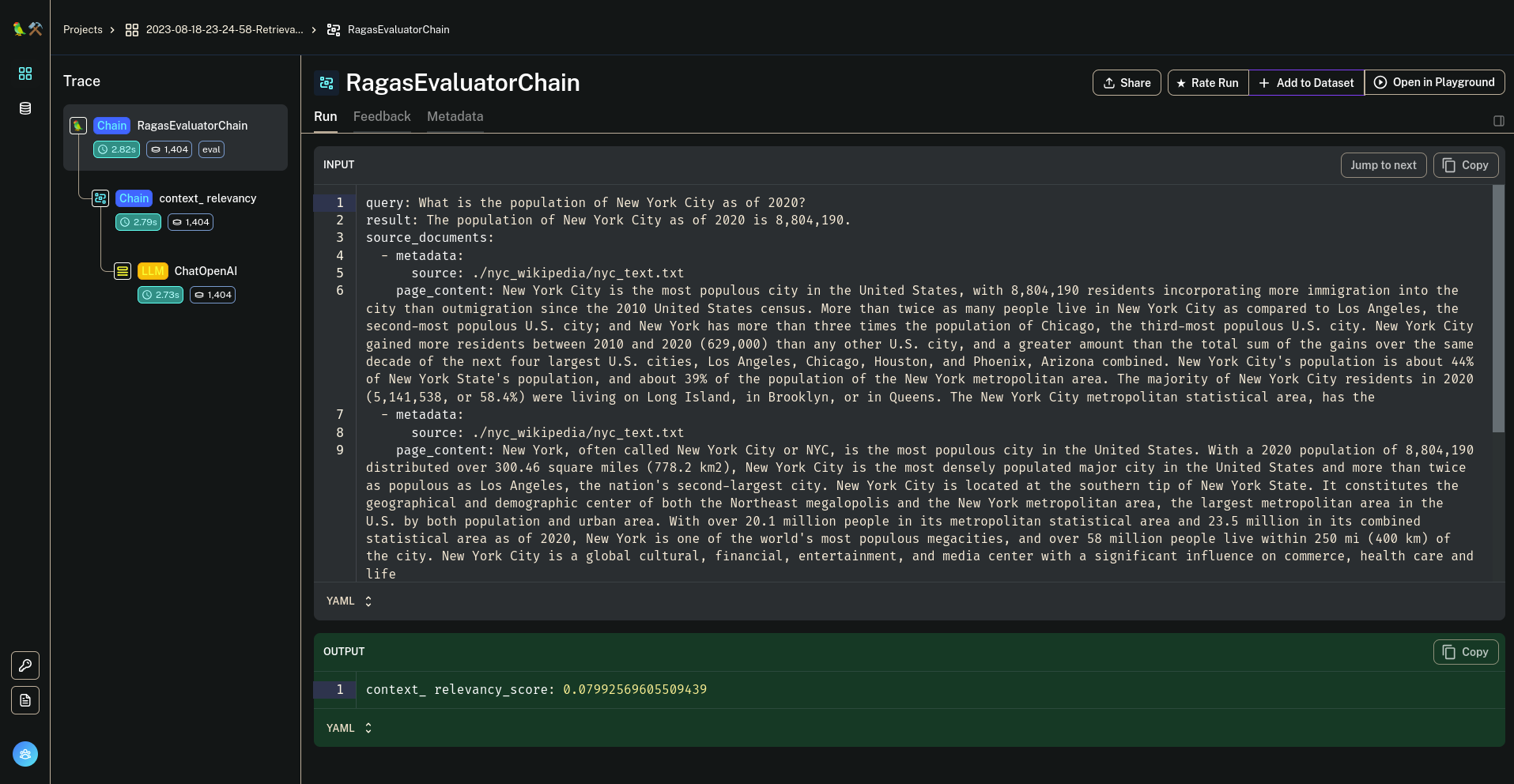
您可以分析每个结果以查看其原因,这将为您提供有关如何改进它的想法。
现在,如果您的 QA 流水线也使用 LangSmith 进行日志记录、跟踪和监控,您可以利用 add-to-dataset 功能来设置持续评估流水线,该流水线不断将有趣的数据点(基于人类反馈或其他间接方法)添加到测试中,以使测试数据集保持最新,并具有更广泛覆盖面的更全面的数据集。
结论
Ragas 通过解决传统指标的局限性并利用大型语言模型来增强 QA 系统评估。LangSmith 提供了一个用于运行评估和可视化结果的平台。
通过使用 Ragas 和 LangSmith,您可以确保您的 QA 系统稳健可靠,并为实际应用做好准备,从而使开发过程更加高效和可靠。