
TLDR: 我们很高兴地宣布一个新的 LangChain 模板,用于帮助研究,其灵感主要来源于 GPT Researcher 团队,并与之合作开发。我们对此感到兴奋,因为这是我们见过的性能最佳、运行时间最长、通用的、非聊天“认知架构”之一。
重要链接
聊天的缺点
到目前为止,大多数 LLM 应用程序都是基于聊天的。这并不令人惊讶 - ChatGPT 是 用户增长速度最快的消费者应用程序,而聊天是一种合理的 UX(允许来回互动,是一种自然的媒介)。然而,作为一种 UX,聊天也有一些缺点,并且常常会使创建高性能应用程序变得更加困难。
延迟预期
主要的缺点是聊天带来的延迟预期。当您使用聊天应用程序时,作为用户,您对该应用程序的延迟有一定的期望。具体来说,您期望快速响应。这就是为什么流式传输在 LLM 应用程序中是一项非常重要的功能 - 它给人一种快速响应的错觉并显示进度。
这些延迟预期意味着很难在后台做太多的工作 - 您做的工作越多,生成响应所需的时间就越长。这有点问题 - LLM 应用程序的主要问题是 它们的准确性/性能,而提高准确性/性能的主要方法是花费更多时间将流程分解为各个步骤,运行更多检查等等。然而,所有这些额外的步骤都会大大增加延迟。
我们经常与试图平衡这两个考虑因素的团队交谈,这两个因素有时可能是矛盾的。在使用聊天 UX 时,对于复杂的推理任务,很难在预期的时间内获得高度准确和有用的响应。
输出格式
聊天非常适合消息。但对于不太适合放在消息中的内容来说,就没那么好了 - 比如长篇论文或代码文件,或多个文件。在使用聊天 UX 时,将结果显示为消息通常会使它们更难审查或使用。
人机环路
LLM 并非(尚未)高度准确,因此大多数应用程序都大量采用人机环路。这是有道理的 - 只在小范围内使用 LLM,然后让人类检查/验证其输出并要求跟进。
然而,这里需要权衡。如果人类需要过多地参与到环路中,那么实际上并没有节省他们的时间!但是你也不能完全将人类从环路中移除 - 再次强调,LLM 还不够可靠。
关键在于找到一些 UX,在这些 UX 中,您可以要求 LLM 完成大量工作,但其结果仍然不被期望是完美的输出。
非聊天项目
我们对许多不使用聊天作为主要媒介的项目感到兴奋。以下重点介绍一些:
这个项目有一个小的聊天组件(询问澄清问题),之后自主运行并生成代码文件。这在关键点有人工参与。
- 澄清问题:早期收集需求
- 在最后,当您可以检查代码时
最终生成的代码可以很容易地被用户修改,因此它更像是一个初稿,而不是其他任何东西。输出是 Python 文件 - 比在聊天中输出自然得多。没有人期望文件是自动生成的 - 如果我要让同事编写一些代码,我不会期望他们不断地给我发消息报告进度!我会期望他们离开一段时间,做一些工作,然后我会查看 - 这正是这里的 UX。
这个机器人一直在巡逻我们的 GitHub 仓库并响应问题。用户不是通过聊天与它互动,而是通过 GitHub 问题。对 GitHub 问题的响应时间预期远高于聊天,这为 DosuBot 提供了充足的时间来完成它的工作。它的输出也不被期望是完美的工件 - 它们只是对用户的回复。用户很大程度上参与到环路中,可以根据自己的意愿接受并实施它们。
我们之前讨论过这个项目(并且将在下一节中更多地讨论它,因为“研究助手”很大程度上基于它)。这个项目编写完整的研究报告。它保存生成的文件 - 正如我们会保存研究报告一样(我们不会在聊天中互相发送研究报告)!它需要一段时间才能运行 - 但这完全没问题。如果我要求同事为我写一份研究报告,我不会期望得到任何接近即时响应的结果。它的输出可以很容易地被检查和修改,并用作初稿 - 不期望得到完整的输出。
所有这些项目都打破了基于聊天的 UX 趋势。它们承担了越来越大的工作量 - 而不是回答一个您可以在研究报告中使用的单个问题,它们为您编写研究报告!最终的响应通常最好不是作为聊天消息,而是作为其他一些文件,并且这些文件可以很容易地被修改,因此仍然存在人机环路组件。
这些项目令人兴奋不仅仅是因为它们不使用聊天。它们令人兴奋是因为它们是我们看到的一些最有用的应用程序,而这可能正是因为它们不使用聊天。
研究助手
几周前,我们推出了 LangChain 模板 - 一系列参考架构,是开始使用 GenAI 应用程序的最快方式。其中大多数都围绕聊天展开。然而,我们看到的一些最有趣和最有用的应用程序(包括上面的那些)并没有使用聊天作为主要界面。
我们希望开始添加非基于聊天的模板。我们过去曾与 GPT-Researcher 团队 密切合作,并认为他们有一个很棒的用例。因此,我们与他们合作在 LangChain 模板中添加了一个“研究助手”模板,使其可以轻松地在 LangChain 生态系统中开始使用此模板。注意:他们最近也发布了一个重要的新版本 - 查看一下。
这个应用程序在底层做了什么?“认知架构”可以分解为几个步骤:
- 用户输入要撰写的问题/主题
- 生成一堆子问题
- 对于每个子问题:研究该子问题并获取相关文档,然后针对该子问题总结这些文档
- 获取每个子问题的摘要,并将它们组合成最终报告。
- 输出最终报告
这些部分中的每一部分都是模块化的,使其非常适合 LangChain 生态系统
- 替换用于生成子问题的提示和/或 LLM
- 替换用于获取相关文档的检索器
- 替换用于生成最终报告的提示和/或 LLM
默认情况下,该模板使用 OpenAI 作为 LLM,并使用 Tavily 作为搜索引擎。Tavily 是 GPT-Researcher 团队创建的搜索引擎,并针对 AI 工作负载进行了优化。具体来说,Tavily API 针对 RAG 进行了优化。他们优化了获取最真实和相关的信息,以插入任何 RAG 管道中,从而最大限度地提高 LLM 的推理和输出。这使得搜索网络变得容易上手。但是,它可以很容易地修改为指向我们的 Arxiv Retriever 或我们的 PubMed Retriever,并快速转变为这些站点的研究助手。它也可以同样容易地指向包含您相关信息的向量数据库。
这种架构在底层做了很多工作。将此集成到 LangChain 生态系统的另一个巨大好处是,您可以通过 LangSmith 为此架构获得一流的可观察性。使用 LangSmith,您可以查看所有许多步骤,并检查每个步骤的输入和输出。
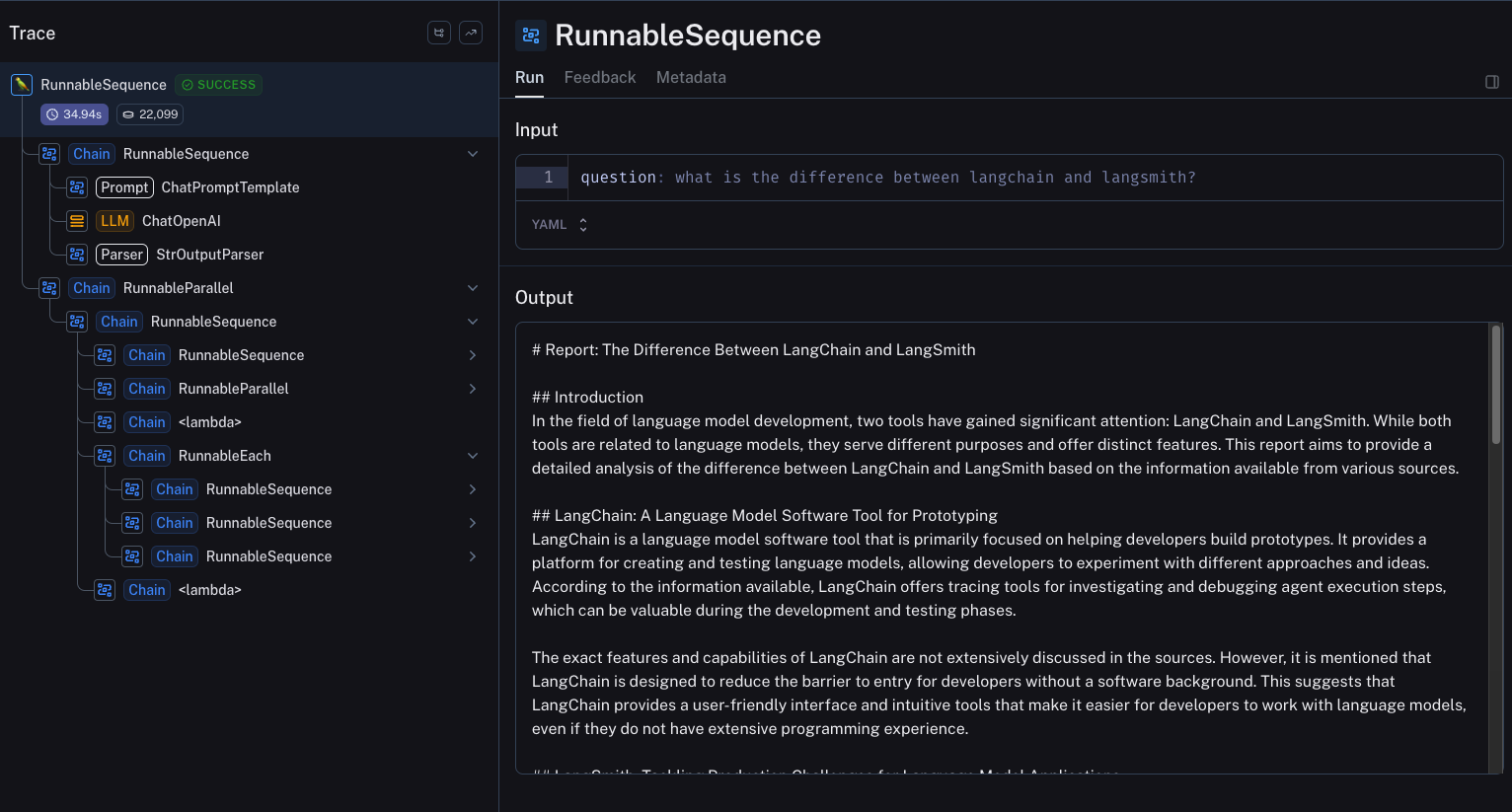
您可以在 此处 探索此示例跟踪。
结论
虽然到目前为止 GenAI 领域一直由具有聊天 UX 的应用程序主导,但我们看好最有效的自主系统是运行时间较长的系统。GPT-Researcher 的创建者 Assaf Elovic 也是如此认为。
随着 AI 的改进,自动化也会随着时间的推移而增长,用户行为只会越来越要求产品提供更多自动化。随着自动化的增长,用户期望将会改变,从即时响应/反馈更多地转向获得高质量结果的能力。
因此,有空间和需求开发更复杂的 AI 应用程序,这些应用程序可能需要更长的时间才能完成,但旨在最大限度地提高 RAG 和内容生成的质量。这也与在后台运行以完成复杂任务的自主代理框架有关。
GPT-Researcher 是这方面的一个完美例子,我们很高兴与他们合作,将这个“研究助手”模板变为现实。请在此处 试用 并告诉我们您的想法!