
两周前,我们发布了 langchain-benchmarks 包,以及一个关于 LangChain 文档的 问答数据集。今天,我们发布了一个新的 提取数据集,用于衡量 LLM 从聊天记录中推断正确结构化信息的能力。
这个新数据集提供了一个实际环境,用于测试 LLM 应用程序开发中的常见挑战,例如分类非结构化文本、生成机器可读信息以及推理具有分散注意力的信息的多个任务。
在这篇文章的其余部分,我将介绍我们如何创建数据集,并分享一些初步的基准测试结果。我们希望您发现这对您自己的对话应用程序开发有用,并欢迎您的反馈!
数据集的动机
我们希望围绕一个真实世界的问题来设计数据集模式:从聊天机器人交互中收集结构化见解。
在夏季,我们优秀的实习生 Molly 帮助我们刷新了 Chat LangChain (repo),这是一个基于 LangChain Python 文档的检索增强生成 (RAG) 应用程序。它是一个“带有搜索引擎的 LLM”,因此您可以向它提出诸如“如何向代理添加记忆?”之类的问题,它会根据在文档中找到的任何内容告诉您答案。
这种 项目的真正考验始于部署后,当您开始观察它的使用方式并进一步改进它时。通常,用户不会提供明确的反馈,但他们的对话揭示了很多信息,虽然您可以尝试“将日志放入 LLM”来总结它,但您通常也可以从提取结构化内容以进行监控和分析中受益。这可以帮助驱动分析仪表板或微调数据收集管道,因为结构化值可以很容易地被传统软件使用。
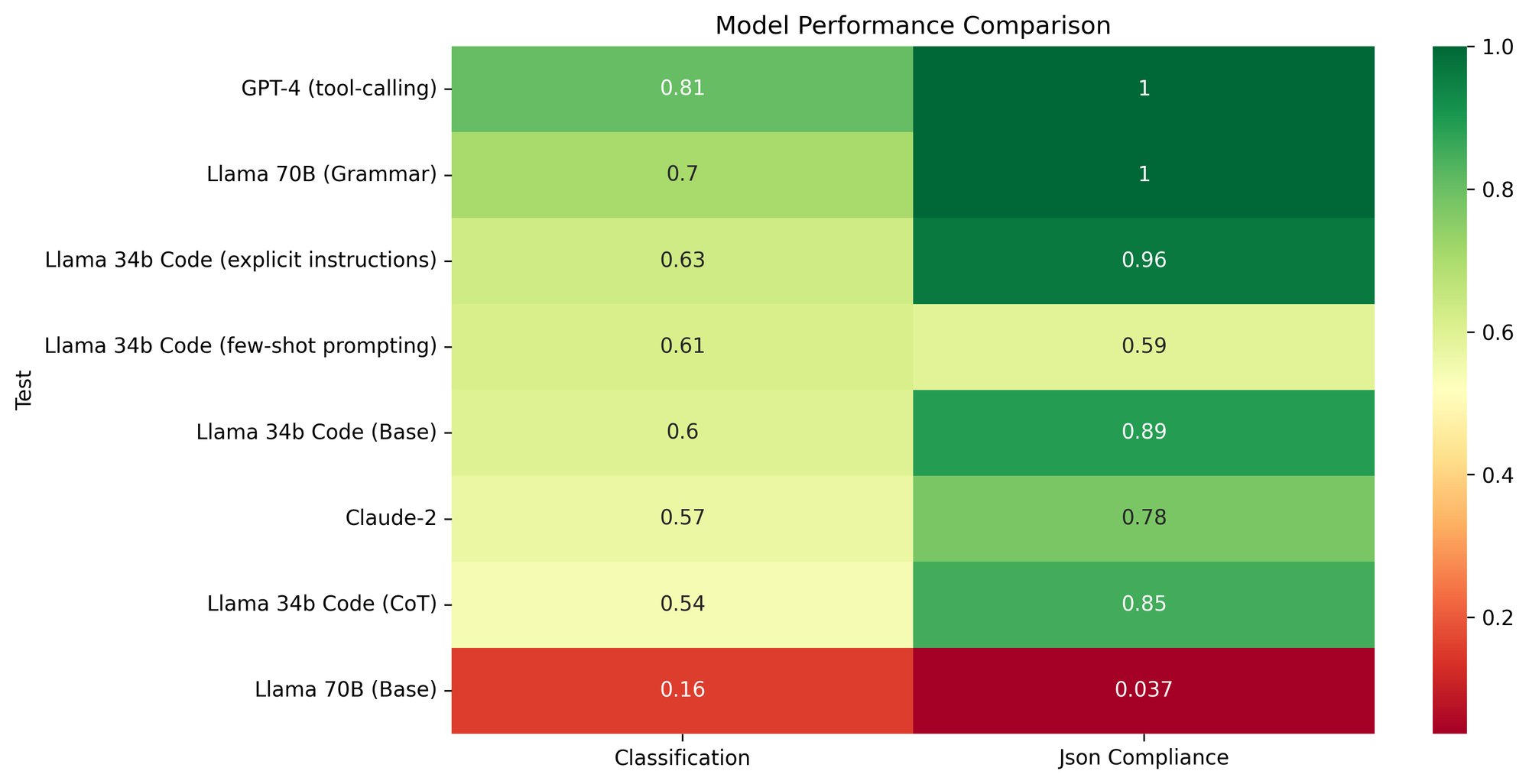
聊天提取数据集旨在测试当今的 LLM 如何能够从这类数据中提取和分类相关信息。在以下部分中,我将介绍我们如何创建数据集。如果您只想查看结果,请查看下面的摘要图表。您可以随意跳到实验部分以分析结果。
创建数据集
创建数据集的主要步骤是
- 确定用于表示结构化输出的数据模型。
- 用问答对播种。
- 使用 LLM 生成候选答案。
- 手动审查注释队列中的结果,并在必要时更新分类法。
LangChain 长期以来一直拥有 合成 数据集 生成 实用程序,可以帮助您引导一些初始数据,但最终版本应始终包含一定程度的人工审查,以确保适当的质量。这就是为什么我们向 LangSmith 添加了 数据注释队列,并将继续改进我们的工具,以帮助您构建数据飞轮。
一旦您拥有初始数据集,您就可以将标记数据用作种子生成模型中的少量示例,以提高提供给人类审查的数据质量。这可以帮助减少更新基本事实所需的工作量和更改。
提取模式
我们希望这项任务是可行的,同时仍然为当今许多常见模型提供挑战。我们使用 这个链接的 pydantic 模型 定义了模式。下面是一个提取值的示例
{
"GenerateTicket": {
"question": {
"toxicity": 0,
"sentiment": "Neutral",
"is_off_topic": false,
"question_category": "Function Calling",
"programming_language": "unknown"
},
"response": {
"response_type": "provide guidance",
"confidence_level": 5,
"followup_actions": [
"Check with API provider for function calling support."
]
},
"issue_summary": "Function Calling Format Validation"
}
}提取输出示例
其中许多值在监控实际生产聊天机器人中可能很有用。我们以几种方式使模式具有挑战性,以使基准测试结果在区分模型容量和功能方面更有用。关于此模式的一些挑战包括
- 它包括几个相当长的 Enum 值。即使是 OpenAI 的函数调用/工具使用 API 在生成这些值时也可能不完美。
- 对象是嵌套的 - 如果 LLM 没有接受过代码训练,嵌套会使 LLM 更难保持连贯性。
- 每个嵌套组件中的值应仅从输入的相应部分(响应或问题)推断出来。
- 它在一个任务中结合了分类、摘要和结构化输出生成。
如果“注意力就是你所需要的一切”,通过分散模型的注意力,这个多任务目标对于 LLM 来说在单次生成中可能难以解决。
评估
此基准测试侧重于结构和分类,因此,我们不需要使用任何 LLM 即法官指标。相反,我们编写了自定义 LangSmith 评估器(请参阅 此处的代码定义)。以下是我们衡量的指标
- 结构验证
json_schema:正确为 1,不正确为 0。我们使用任务模式验证每个模型的已解析输出。
- 分类任务
question_category:对 25 个有效枚举值的分类准确率。off_topic_similarity:LLM 是否认为问题离题的二元分类准确率toxicity_similarity:用户问题的预测“毒性”水平的标准化差异。programming_language_similarity- 用户问题引用的预测编程语言的分类准确率。在大多数情况下,这是“未知”。confidence_level_similarity:响应的预测“置信度”与标记的置信度之间的标准化相似度。sentiment_similarity- 预测值和标签之间的标准化差异。情感评分标准为 0/1/2,分别代表负面/中性/正面。
- 总体差异
json_edit_distance:这是一个有点包罗万象的指标,它首先规范化预测的 json 和标签 json,然后计算两个序列化形式之间的 Damerau-Levenshtein 字符串距离。
实验
在制作此数据集时,我们想回答几个问题
- 最流行的闭源 LLM 相比如何?
- 现成的开源 LLM 相对于闭源模型表现如何?
- 简单的提示策略在提高提取性能方面有多有效?
- 如果我们控制 LLM 语法以输出有效记录,这对各个分类指标有多重要?
我们评估了以下 LLM
gpt-4-1106-preview:最近的长上下文、精馏版本的 GPT-4。claude-2- 来自 Anthropic 的 LLM。llama-v2-34b-code-instruct- Code Llama 2 的 34b 参数变体,在指令数据集上进行了微调。llama-v2-chat-70b- Llama 2 的 70b 参数变体,针对聊天进行了微调。yi-34b-200k-capybara- 来自 Nous Research 的 34b 参数模型。
实验 1:GPT 与 Claude
我们首先比较了闭源 LLM Claude-2 和 GPT-4。对于 GPT-4,我们使用了它的工具调用 API,您可以为其提供 JSON 模式以进行填充。由于 Anthropic 尚未发布类似的工具调用 API,我们测试了两种不同的指定模式的方式:
- 直接作为 Json 模式。
- 作为 XSD (XML 模式)
您可以在 链接测试 中并排查看各个预测。您还可以查看下面的摘要图表和表格
GPT-4 和 Claude 的比较
| 测试 | confidence_level_similarity | json_edit_distance | json_schema | off_topic_similarity | programming_language_similarity | question_category | sentiment_similarity | toxicity_similarity |
|---|---|---|---|---|---|---|---|---|
| claude-2-xsd-to-xml-5689 | 0.97 | 0.39 | 0.52 | 0.00 | 0.52 | 0.37 | 0.91 | 1.0 |
| claude-2-json-schema-to-xml-5689 | 0.97 | 0.37 | 0.78 | 0.00 | 0.44 | 0.48 | 0.93 | 1.0 |
| gpt-4-1106-preview-5689 | 0.94 | 0.28 | 1.00 | 0.89 | 0.59 | 0.56 | 1.00 | 0.0 |
正如预期的那样,GPT-4 在几乎所有指标上都表现更好,并且我们无法让 Claude 一次性完美输出所需的模式。有趣的是,使用 JSON 模式提示的 Claude 模型比使用 XSD(XML 模式)中提供的相同信息提示的模型略好,这表明至少在这种情况下,模式的一致格式并不那么重要。
很容易看到一些常见的模式问题;例如,在 此运行 和 此运行 中,模型为后续操作输出项目符号列表,而不是正确标记的元素,这被解析为字符串而不是列表。下面是此示例图像

虽然我们可以根据具体情况修复这些解析错误,但不可预测性会阻碍整体开发体验。将一个提取链适应另一项任务需要更多的开销,因为解析器和其他行为不太一致。相对于 GPT,XML 语法还增加了 Claude 的总体 token 使用量。虽然“token”不具有直接可比性,但冗长的语法可能会导致更慢的响应时间和更高的成本。
实验 2:开源模型
接下来,我们想对流行的现成开源模型进行基准测试,并首先比较三个模型中的相同基本提示
llama-v2-34b-code-instruct- Code Llama 2 的 34b 参数变体,在指令数据集上进行了微调。llama-v2-chat-70b- Llama 2 的 70b 参数变体,针对聊天进行了微调。yi-34b-200k-capybara- 来自 Nous Research 的 34b 参数模型。
查看 链接比较 以在 LangSmith 中查看输出,或参考下面的汇总指标
比较基线 OSS 模型
| 测试 | confidence_level_similarity | json_edit_distance | json_schema | off_topic_similarity | programming_language_similarity | question_category | sentiment_similarity | toxicity_similarity |
|---|---|---|---|---|---|---|---|---|
| yi-34b-200k-capybara-5d76-v1 | -0.30 | 0.16 | 0.37 | 0.41 | 0.15 | 0.15 | 0.28 | 0.41 |
| llama-v2-70b-chat-28a7-v1 | 0.30 | 0.43 | 0.04 | 0.30 | 0.15 | 0.04 | 0.30 | 0.00 |
| llama-v2-34b-code-instruct-bcce-v1 | 0.93 | 0.41 | 0.89 | 0.89 | 0.44 | 0.07 | 0.59 | 1.00 |
尽管 Llama 2 的 70B 变体模型尺寸更大,但由于其预训练和 SFT 语料库中包含的代码量较少,因此无法可靠地输出 JSON。Yi-34b 在这方面更可靠,但它仍然只有 37% 的时间匹配所需的模式。它在最难的分类任务 question_category 分类中也表现更好。
34B Code Llama 2 能够输出有效的 JSON,并且在其他指标方面做得不错,因此我们将使用它作为以下提示实验的基线。
实验 3:提示模式合规性
在三个开源模型基线中,34B Code Llama 2 变体表现最佳。因此,我们选择它来回答“简单的提示技术在使模型可靠地输出结构化 JSON 方面效果如何”这个问题(提示:效果不太好)。您可以使用 此笔记本 重新运行实验。
在基线实验中,最常见的失败模式是幻觉无效的 Enum 值(例如,参见 此运行),以及简单事物(如问题情感)的分类性能不佳。
我们测试了三种提示策略,以查看它们如何影响总体性能
- 添加额外的特定于任务的说明:模式已经对每个值都有描述,但我们想看看是否添加额外的说明,例如,仔细从列表中选择有效的 Enum 值,会有所帮助。我们已经在几个 playground 示例中测试过这种方法,并看到它有时会有所帮助。
- 思维链:要求模型在生成最终输出之前逐步思考模式结构。
- 少量示例:除了明确的说明和模式外,我们还为模型手工制作了预期的输入-输出对以供遵循。有时 LLM(像人一样)通过查看几个示例而不是从说明中学习效果更好。
以下是结果
比较 OSS 模型的提示策略
| 测试 | 提示 | confidence_level_similarity | json_edit_distance | json_schema | off_topic_similarity | programming_language_similarity | question_category | sentiment_similarity | toxicity_similarity |
|---|---|---|---|---|---|---|---|---|---|
| llama-v2-34b-code-instruct-bcce-v1 | 基线 | 0.93 | 0.41 | 0.89 | 0.89 | 0.44 | 0.07 | 0.59 | 1.00 |
| llama-v2-34b-code-instruct-e20e-v1 | 说明 | 0.95 | 0.38 | 0.96 | 0.89 | 0.63 | 0.11 | 0.54 | 1.00 |
| llama-v2-34b-code-instruct-34b8-v2 | 少量示例 | 0.89 | 0.38 | 0.59 | 0.85 | 0.33 | 0.07 | 0.85 | 0.96 |
| llama-v2-34b-code-instruct-d3a3-v2 | CoT | 0.97 | 0.42 | 0.85 | 0.85 | 0.44 | 0.04 | 0.57 | 0.81 |
没有任何提示策略在所讨论的指标上表现出有意义的改进。少量示例技术甚至降低了模型在 JSON 模式测试中的性能(参见:示例)。这可能是因为我们增加了提示中的内容量,这些内容分散了对原始模式的注意力。明确说明似乎确实提高了编程语言分类的性能,因为模型被指示关注问题。然而,贡献很小,对于情感分类指标,模型仍然会受到响应情感的干扰。
实验 4:结构化解码
由于没有任何提示技术可以显着提高模型输出的结构,我们想测试其他方法来可靠地生成符合模式的 JSON。具体来说,我们想应用结构化解码技术,例如 logit 偏差 / 基于约束的 采样。有关引导文本生成的调查,请查看 Lilian Weng 的 优秀文章。
在此实验中,我们使用 Llama.cpp 的基于语法的 解码机制 测试 Llama 70B,以保证有效的 JSON 模式。请参阅与基线的比较 此处 和下表。
比较基线与基于语法的解码
| 测试 | 解码 | confidence_level_similarity | json_edit_distance | json_schema | off_topic_similarity | programming_language_similarity | question_category | sentiment_similarity | toxicity_similarity |
|---|---|---|---|---|---|---|---|---|---|
| llama-v2-70b-chat-28a7-v1 | 基线 | 0.30 | 0.43 | 0.04 | 0.30 | 0.15 | 0.04 | 0.3 | 0.0 |
| llama-gguf-1f95-v2 | 结构化 | 0.93 | 0.44 | 1.00 | 0.89 | 0.37 | 0.26 | 1.0 | 1.0 |
最显着(也是预期的)改进是 json_schema 正确性从几乎从不正确变为 100% 有效。这意味着其他值也可以可靠地解析,从而减少了这些字段中的 0。由于基本 Llama 70B 聊天模型也比我们之前的 34B 模型实验更大、更强大,因此我们也可以看到情感相似性和问题类别方面的改进。然而,这些指标的绝对性能仍然很低。基于语法的解码使输出结构得到保证,但仅凭它不足以保证值本身的质量。
完整结果
有关上述实验的完整结果,请查看 LangSmith 测试链接。您还可以按照 此笔记本,针对您自己的模型运行任何这些基准测试。