
编者注: 这篇文章由 HumanSignal 的常驻数据科学家 Jimmy Whitaker 撰写。 HumanSignal。 Label Studio 是一个开源数据标注平台,在为微调大型语言模型 (LLM) 标注数据时,它为 LangChain 提供了灵活性。它还支持准备自定义训练数据,以及通过人工反馈收集和评估响应,这是持续评估和维护专家系统的关键部分。
简介
当将大型语言模型 (LLM) 应用于现实世界时,质量是一个关键问题。LLM,尤其是基础模型,是在大量数据语料库上训练的,这赋予了它们对世界的普遍“理解”,令人叹为观止。但是,伴随着这种广泛的覆盖范围,LLM 也继承了互联网级别的偏见,这种偏见几乎不可能完全理解,更不用说控制了。这种普遍存在的偏见构成了一个挑战,因为它并非总是与我们独特应用领域的期望和要求相符。因此,一刀切的 LLM 通常达不到为特定应用提供高质量响应的期望。
这并不是说关注数据量对于在通用聊天机器人方面取得惊人成果毫无作用。但是,尽管这些 LLM 数据丰富,但它们在现实世界中的应用仍有改进空间。质量,而不是数量,成为了关键问题。对于商业应用,上下文感知、数据隐私以及控制这些应用的能力至关重要。构建于 LLM 之上的 LLM 和应用需要持续微调,以适应特定领域并将模型与我们的精确需求对齐。持续可靠地执行此操作的能力正变得对垂直领域的特定 LLM 应用至关重要。
此外,我们必须不断调整和改进我们的模型和应用。这种持续的调整确保了我们的语言模型在我们的领域内以最佳方式运行,并且不会传播我们宁愿抛弃的偏见。
这些挑战需要组织和评估数据,以进行特定于应用的调整和评估模型质量。这些需求将我们带到了今天的明星——Label Studio。
Label Studio:您的 LLM 调优器
Label Studio 在改进大型语言模型及其周围应用的持续过程中发挥着不可或缺的作用。它是一个捕获和注释用户与我们应用的交互的平台。这种能力对于理解我们模型的性能和查明需要调整的领域至关重要。
在这篇博文中,我们将探讨如何将 Label Studio 用作持续改进的工具,特别是在构建问答 (QA) 系统时,该系统经过训练,可以使用来自 Label Studio 的 GitHub 文档 的领域特定知识来回答有关 Label Studio 本身的问题。
但是,重要的是要注意,我们关于 QA 的对话只是一个起点。Label Studio 的功能远远超出了简单的 QA 场景。它可以对响应中的情感进行分类、对 LLM 提供的答案进行评分、提取特定实体,甚至可以处理音频和视觉数据。虽然我们在此处的重点是 QA 系统,以演示调整 LLM 应用的综合方法,但潜在的应用是无限的。
让我们考虑一下 QA 流程:当用户与聊天机器人交互时,我们可以捕获提出的问题和返回的答案。然后,将这些数据发送到 Label Studio,在那里可以对其进行检查和注释,以评估响应是否合适。通过回答问题和应用注释的过程,我们可以有效地衡量我们系统的质量,并且我们应该能够使用这些数据来持续增强我们的 QA 系统。
在我们进一步进行之前,值得强调两个关键点
- 上下文理解: 基础模型,尤其是在初始阶段,可能无法完全掌握例如 GitHub 存储库的完整上下文。这意味着 QA 机器人始终存在产生不相关或无意义响应的潜在风险。这突出了持续审查和验证机器人答案的重要性。
- 动态数据源: 正当您认为自己已达到良好的质量水平时,请记住数据源(如 GitHub 存储库)是活生生的实体。它们会演变、变化,有时,这可能会导致机器人出错。因此,始终需要定期监督。
最终,我们对 QA 系统的目标是作为 LLM 应用持续增强的蓝图。我们希望有一个系统,使我们能够战略性地驾驭反馈和适应的持续循环,同时允许我们融入人类的理解。这种持续的反馈循环是我们创建有价值的 AI 解决方案的方式。
付诸行动
为了演示这一点,让我们构建一个简单的 LLM 驱动的 QA 系统,以回答有关 Label Studio 的问题。您可以在 GitHub 上查看 完整示例 ,了解更多详细信息。

步骤 1:构建一个简单的 QA 系统
在本示例中,我们将使用 LangChain、ChromaDB 和 OpenAI 来构建我们的 QA 系统。尽管由于 OpenAI 的集成简化,我们在此示例中选择使用 OpenAI,但根据您的偏好,将其替换为其他 LLM 是可行的。
您可以在 此处 阅读更多关于我们与 LangChain 集成的信息。
以下是我们方法的一个简要概述。

Github 作为我们的数据集: 首先,我们需要一个数据集来为我们的 QA 系统构建文档数据库。由于我们正在构建一个 QA 系统来回答有关 Label Studio 的问题,我们可以使用 Label Studio Github 存储库中的文档 markdown 文件作为我们的来源。LangChain 使这变得容易,只需几行代码即可完成。
from langchain.document_loaders.git import GitLoader
from git import Repo
repo_path = "./data/label-studio-repo"
repo = Repo.clone_from("https://github.com/HumanSignal/label-studio",
to_path=repo_path)
branch = repo.head.reference
loader = GitLoader(repo_path=repo_path,
branch=branch,
file_filter=lambda f: f.endswith('.md'))
data = loader.load()文档的 LLM 嵌入: 每个文档都由一个嵌入表示,这是一个高维向量,捕获了从我们的 LLM 检索的文档内容。这些嵌入使我们能够辨别哪些文档彼此相似。当用户提交问题时,我们可以为其生成嵌入并检索相关文档。
向量数据库存储: 在本例中,我们使用向量数据库 ChromaDB 来保存我们的文档嵌入。这允许与我们的嵌入进行有效的文档比较,并能够在需要时扩展我们的系统。
以下 Python 代码展示了我们如何结合特征提取和向量数据库来创建我们的 QA 系统。
from langchain.text_splitter import MarkdownTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
text_splitter = MarkdownTextSplitter(chunk_size = 500, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
vectorstore = Chroma.from_documents(documents=all_splits,
embedding=OpenAIEmbeddings())
现在我们有了嵌入方法和导入了文档的向量存储,我们就可以开始回答问题了。我们的系统提示指示模型仅依赖其收到的文档来回答问题,从而降低了产生幻觉响应的可能性。
步骤 2:捕获用户互动
聊天界面对于理解和学习主题非常有用。我们创建了一个简单的 Gradio 应用程序,使与 QA 系统的交互更加容易。
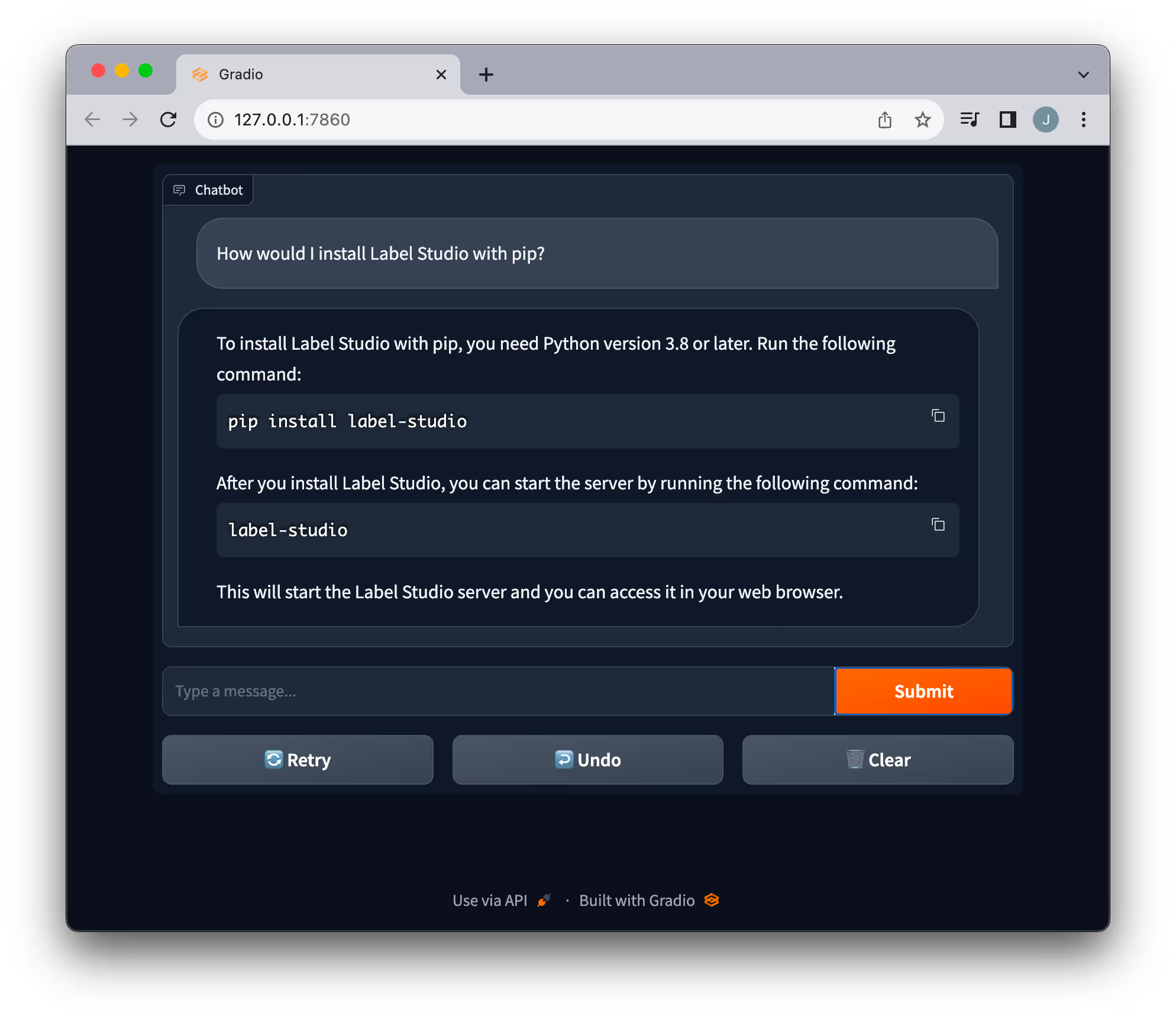
我们的目标不仅仅是解决用户查询;通过检查答案的质量和相关性来掌握系统的有效性至关重要。因此,我们在 LangChain 中实施了 Label Studio 回调,以捕获提出的问题和系统的响应。
class LabelStudioCallbackHandler(BaseCallbackHandler):
def __init__(self, api_key, url, project_id):
self.ls_client = ls.Client(url=url, api_key=api_key)
self.ls_project = self.ls_client.get_project(project_id)
self.prompts = {}
def on_llm_start(self, serialized, prompts, **kwargs):
self.prompts[str(kwargs["parent_run_id"] or kwargs["run_id"])] = prompts
def on_llm_end(self, response, **kwargs):
run_id = str(kwargs["parent_run_id"] or kwargs["run_id"])
prompts = self.prompts[run_id]
tasks = []
for prompt, generation in zip(prompts, response.generations):
tasks.append({'prompt': prompt, 'response': generation[0].text})
self.ls_project.import_tasks(tasks)
self.prompts.pop(run_id)此回调记录查询和答案,并直接将其插入 Label Studio。这为检查、注释和评估响应提供了一个直观的界面。
步骤 3:注释 QA 应用的性能
一旦我们的数据进入 Label Studio,我们就拥有了理解和使用我们的人工专业知识改进数据所需的所有工具。有很多方法可以改进您的数据,例如共识收集、应用过滤器,甚至 使用其他 LLM 来评估您的数据。
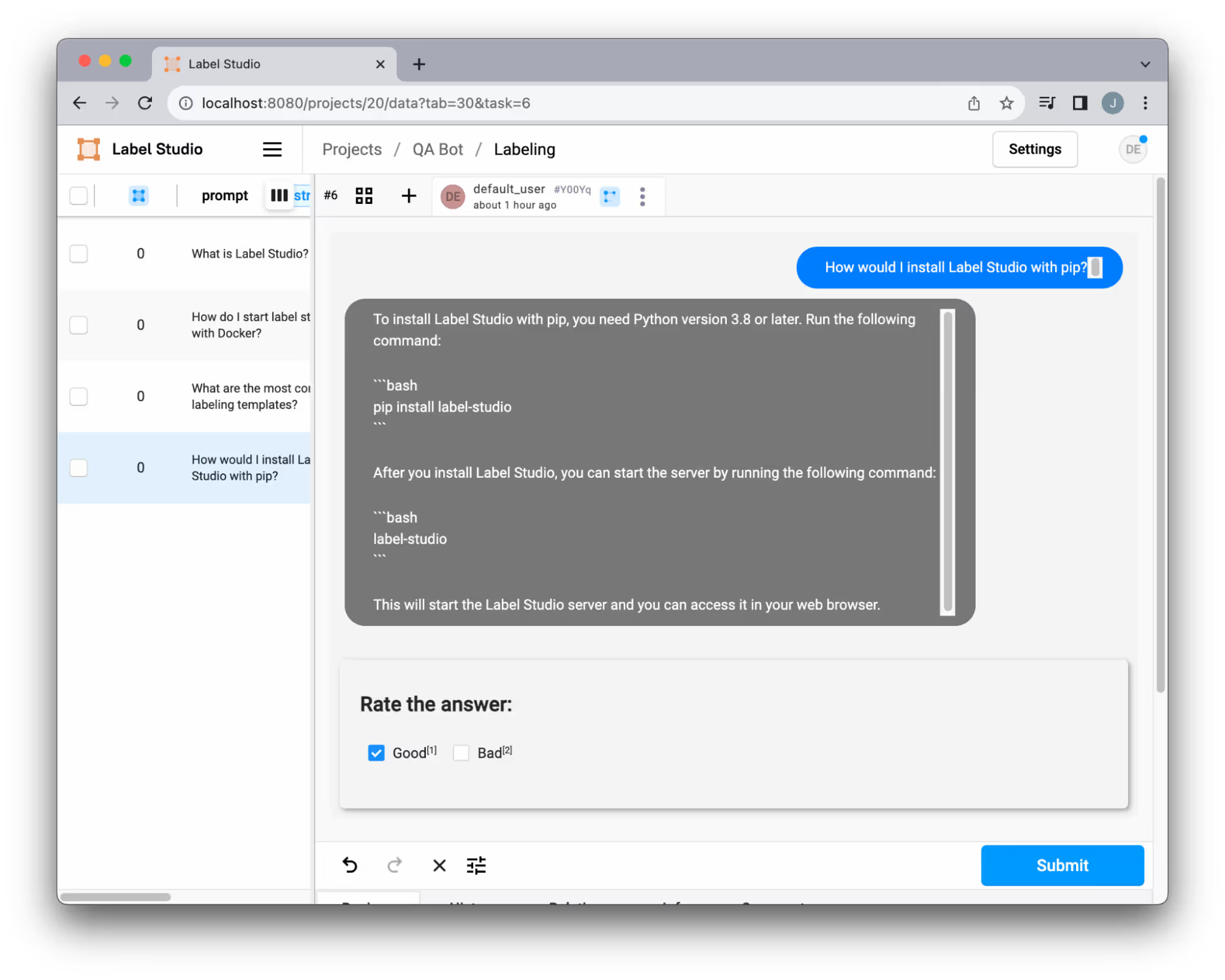
我们的 QA 系统使用 自定义模板 来查看聊天互动。根据我们的独特需求定制这些模板的灵活性确保了标注体验与我们的需求完美契合。无论是添加新类别、允许响应编辑还是整合其他自定义项,该系统都提供了广泛的适应性。了解更多关于如何 个性化模板 的信息。
步骤 4:评估质量
当我们积累了回答的问题和随附的注释时,我们可以开始衡量我们系统的质量。这种反馈循环使我们深入了解我们的 LLM 应用的性能以及需要调整的地方。
例如,我们可能想知道我们系统的总体准确性。我们可以使用数据集中标记为“良好”的示例数量,使用简单的公式

我们可以通过在标注界面中过滤“良好”结果来计算准确率,或者我们可以导出数据集以进行更强大的分析,从而简单地查看这些数字。
我们可以在 UI 中以 CSV 格式导出我们的数据。一旦我们有了数据集,我们就可以对我们的 QA 系统执行任何类型的数据分析,例如计算不相关问题的百分比、域外响应等等。
许多指标和仪表板都是 企业版 Label Studio 的内置功能,以支持更强大的标注工作流程,如下所示。
步骤 5:改进系统
这种迭代方法的妙处在于其自我改进的性质。当用户与系统互动时,我们会积累宝贵的反馈。通过将积极评价的(“良好”)响应集成到我们的文档数据库中,我们增强了系统的上下文理解。有关此代码段的更多详细信息,请参阅 GitHub 上的 完整示例。
# Extract "good" examples and convert them to Documents
good_examples = extract_good_examples_from_jsonl(json_path)
docs = [Document(page_content=str(example), metadata={"source": json_path}) for example in good_examples]
# Add documents to the vector store and persist
vectorstore.add_documents(docs)
vectorstore.persist()
这种方法可能有利于实现我们系统的即时改进,但这可能会变得繁琐。但是,随着我们的数据集变得越来越大,我们可以采用其他调整技术,例如微调 LLM 或嵌入生成器。每次用户互动以及每个问题和答案都成为有价值的数据集。它更清晰地描绘了潜在的系统差距和一般用户痛点。最终,这种用户驱动的反馈循环增强了我们的应用程序,使其越来越符合我们的领域,并不断提高其响应质量。
适用于任何 QA 系统的生成式 AI 工作流程
归根结底,我们有一个生成式 AI 工作流程,可以用于调整任何 QA 系统。它展示了将 LangChain 和 Label Studio 等尖端技术与 OpenAI 的 LLM 相结合的力量,从而形成了一个强大的解决方案,可以驯服偏见并提高语言模型的质量。
当我们拥抱这种工作流程时,我们为创建更细致、特定于领域的应用程序打开了大门,这些应用程序不仅可以准确地回答用户问题,而且可以以与我们独特领域的价值观和需求紧密结合的方式进行回答。因此,持续改进我们的 LLM 应用不仅是一个目标,而且是我们致力于进行的持续过程——这要归功于创新工具和对质量的坚定奉献。
结论
在一个大型语言模型 (LLM) 改变了 AI 驱动应用格局的时代,确保其质量和相关性从未如此重要。 我们讨论的迭代方法 展示了微调这些模型以满足特定应用需求的重要性,尤其是在克服固有偏见和确保领域特定准确性方面。数量与质量的这种动态是使 AI 在现实世界场景中真正具有影响力的最前沿。通过将 Label Studio 与 LangChain 和 LLM 结合使用,我们铺平了一条有希望的前进道路。通过持续的人工反馈、迭代改进和领域特定的校准,我们可以确保我们的 AI 系统强大、精确、可靠,并符合用户期望。
加入 Label Studio 社区!
开源是为了构建社区、分享知识和共同创新。Label Studio 邀请您成为这场运动的一份子。 为项目做贡献、向社区学习,并利用集体智慧的力量。让我们共同微调 AI 的未来,使技术更具包容性和适应性。