
编者按:这是我们客座文章系列中的另一篇,重点介绍了 LangChain 的新颖应用。在生成式智能体论文发布后,涌现出大量开源项目,争相融入一些关键思想。GPTeam 是我们见过的最令人印象深刻的项目之一,因此我们非常激动地重点介绍这篇来自 @itstimconnors 和团队其他成员 (@alecvxyz @joshsny, 和 @haniasnyder) 的客座博客。
5 月 16 日,我们发布了 GPTeam,这是一个完全可定制的开源多智能体模拟,灵感来源于斯坦福大学开创性的“生成式智能体”论文,该论文于上个月发布。GPTeam 模拟中的每个智能体都有自己独特的个性、记忆和指令,随着它们的互动,会产生有趣的涌现行为。
我们将项目设置为任何人都可以通过编辑一个简单的 JSON 配置文件(如下所示)来运行自己的多智能体模拟。在这个例子中,我们创建了一个名为“Jest Jockeys”的简单世界,其中包含一个“公园”位置和一个“购物中心”位置。我们 включили 了几个智能体,每个智能体都包含自己的个人简介、指令和计划。

然后,用户可以使用单个命令 `poetry run world` 运行模拟,这将触发一个 Web 界面,显示智能体的思考过程和对话。这允许用户在智能体观察新事件、决定如何反应以及执行其计划时看到它们。
该项目的目标是测试 LLM 模拟类人社交行为的能力。我们的理论是,类人行为源于 (a) 足够强大的长期记忆系统,以及 (b) 反复的自我反思过程以实现抽象推理。
以下是过程…
注意:本文将引用我们项目中的代码,代码可以在这里找到。
架构
在高层次上,模拟的架构如下所示。实际代码包含更多的细微差别和额外的辅助类,但这大致是事物如何协同工作的草图。
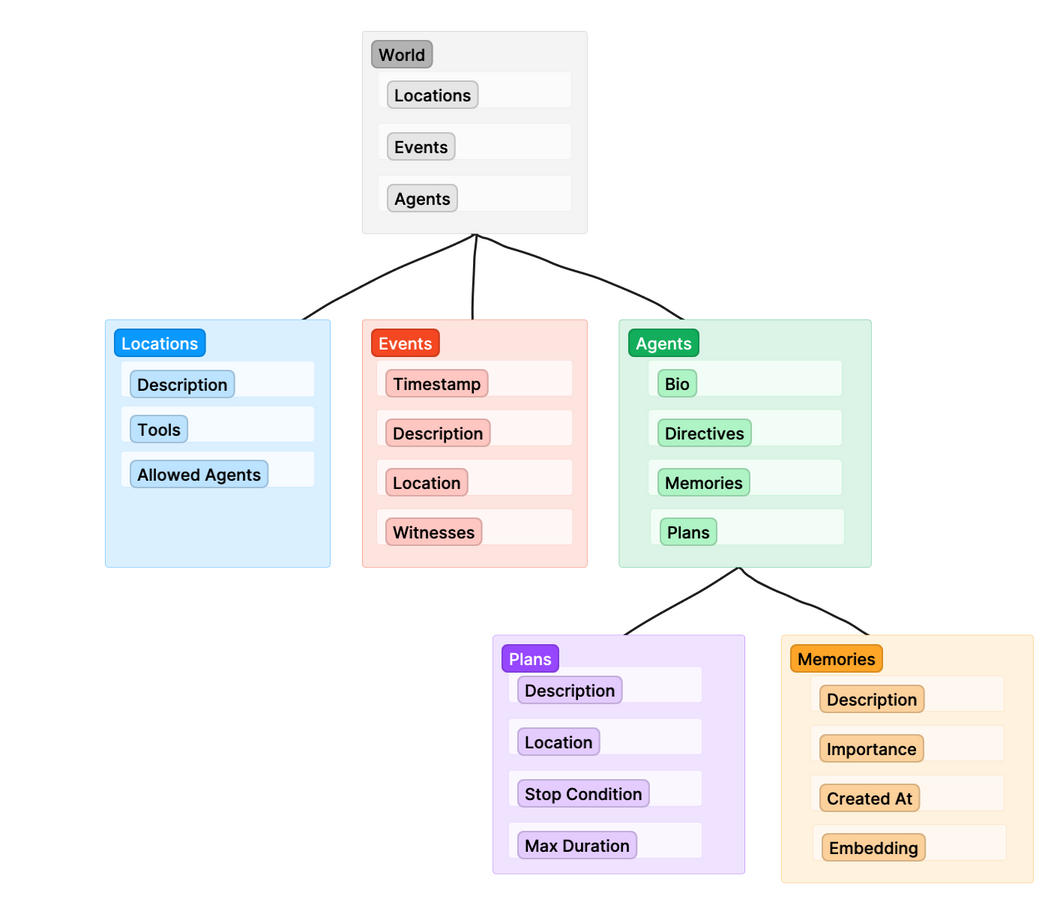
World 类充当其他一切的顶层包装器。当我们运行模拟时,我们正在运行 `world.run()`,这将触发世界中的每个智能体开始其智能体循环。
智能体循环
智能体循环是 GPTeam 中活动的主要驱动力。随着世界的运行,每个智能体都会一遍又一遍地重复这个循环,直到世界停止。您可以在此处查看智能体循环的代码。
当我们深入了解智能体循环的工作原理时,了解在此存储库中找不到离散的智能体 AI 会有所帮助。类人智能体实体的出现是由我们的记忆系统和一系列不同的语言模型提示创建的错觉。
Agent.observe
智能体通过首先观察其位置的活动来开始其循环。此函数 observe() 从智能体当前位置获取最新事件,并将每个事件添加到智能体的记忆中。当创建新记忆时,会为其分配一个重要性评分,旨在量化记忆的深刻程度。这允许更关键的事件在以后更容易被“记住”。我们通过简单地要求 LLM 生成一个重要性评分来分配它
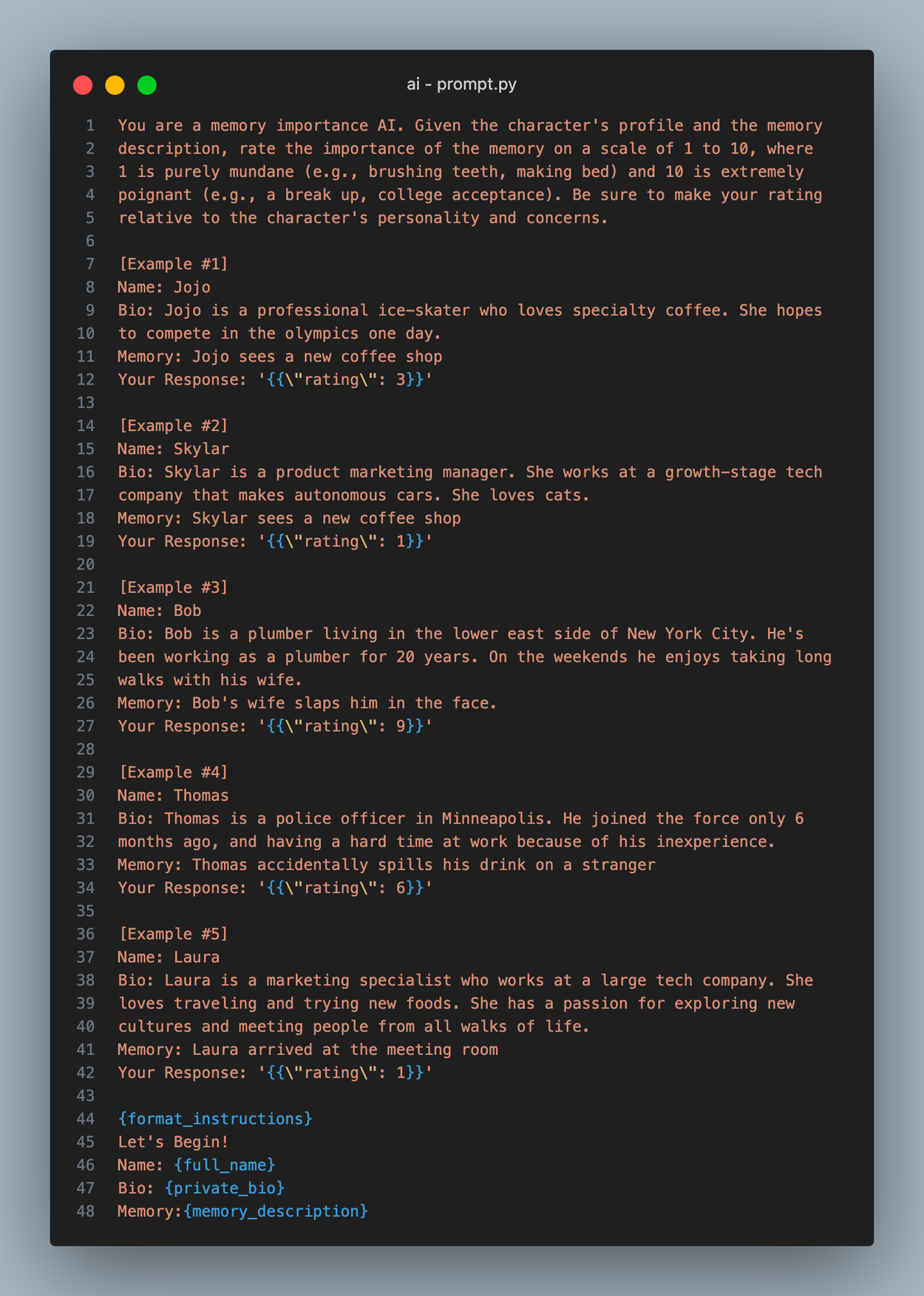
注意:您可以在此文件中查看我们所有的 LLM 提示。
Agent.plan
接下来,智能体制定计划(如果它们没有任何计划),尽管它们通常都有计划,因为它们一次制定 5 个计划。智能体采取的每个行动都必须是某个计划的一部分,因此计划至关重要。为了制定计划,我们获取智能体的个人详细信息和情境背景,然后将它们传递到带有如下所示提示的 LLM 调用中。
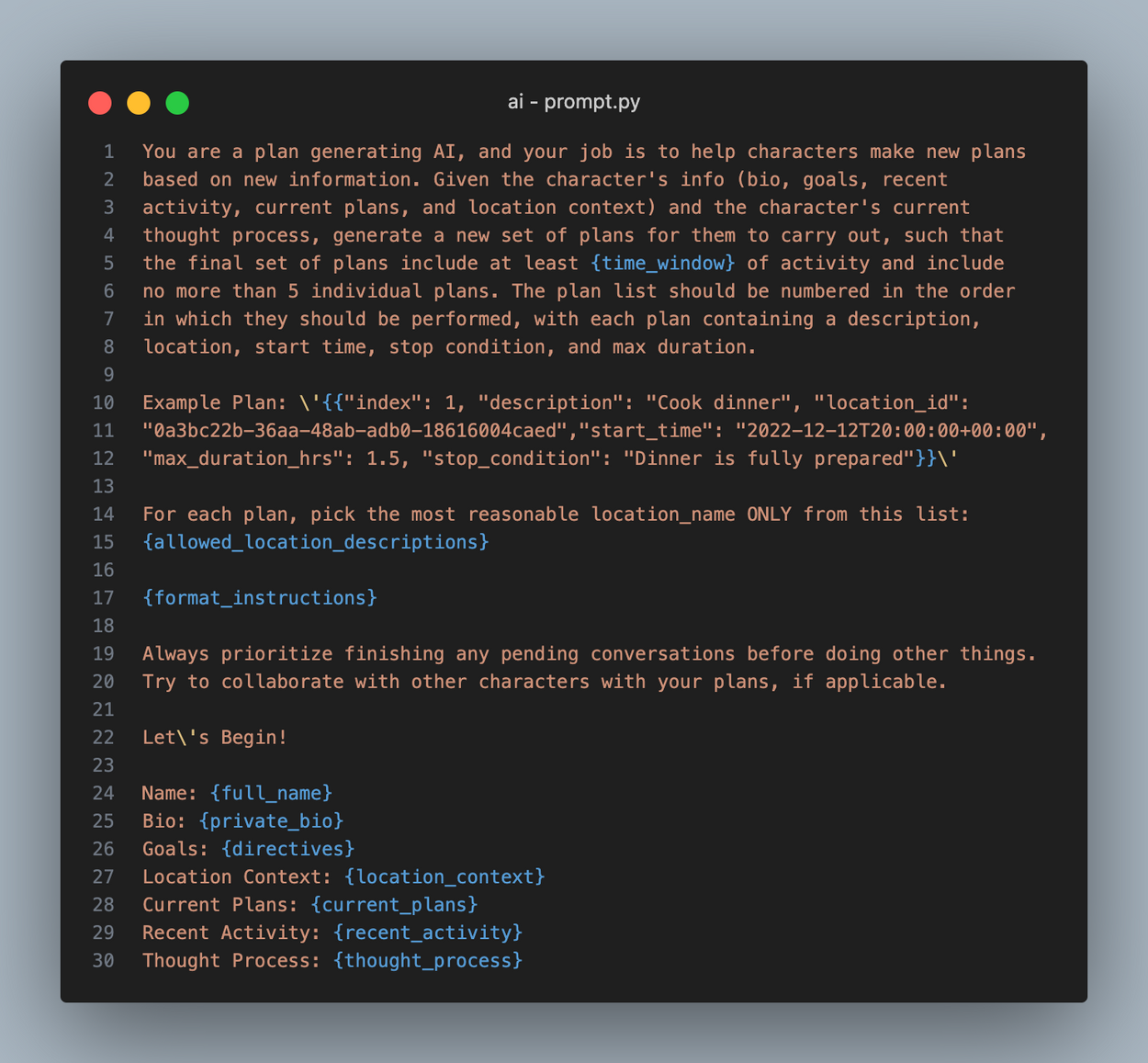
此提示的一个重要部分是智能体的指令,它充当智能体决定做什么时的指南针。没有它们,智能体只能做出被动反应。您可以将它们的指令视为它们的默认活动。
来自此 LLM 调用的结果是一个 JSON 对象有序列表,它填充了 `Agent.plans` 数组。每个计划都包含索引、描述、位置、开始时间、最大持续时间和停止条件。
Agent.react
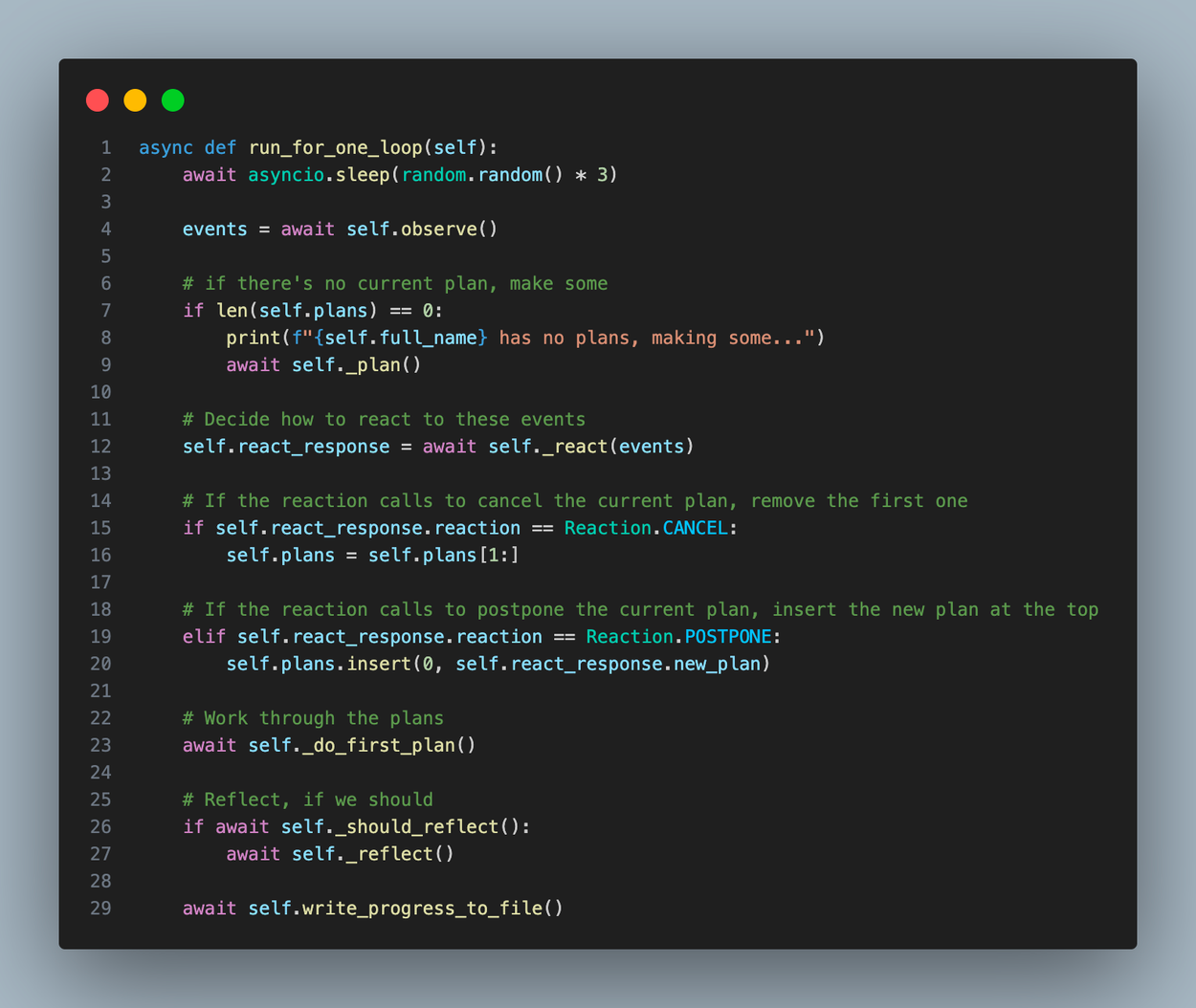
制定计划后,智能体决定如何反应。react() 函数非常简单:它要求 LLM 根据最近发生的事件来决定智能体是否应该继续、推迟或取消其首要计划。以下是提示的样子
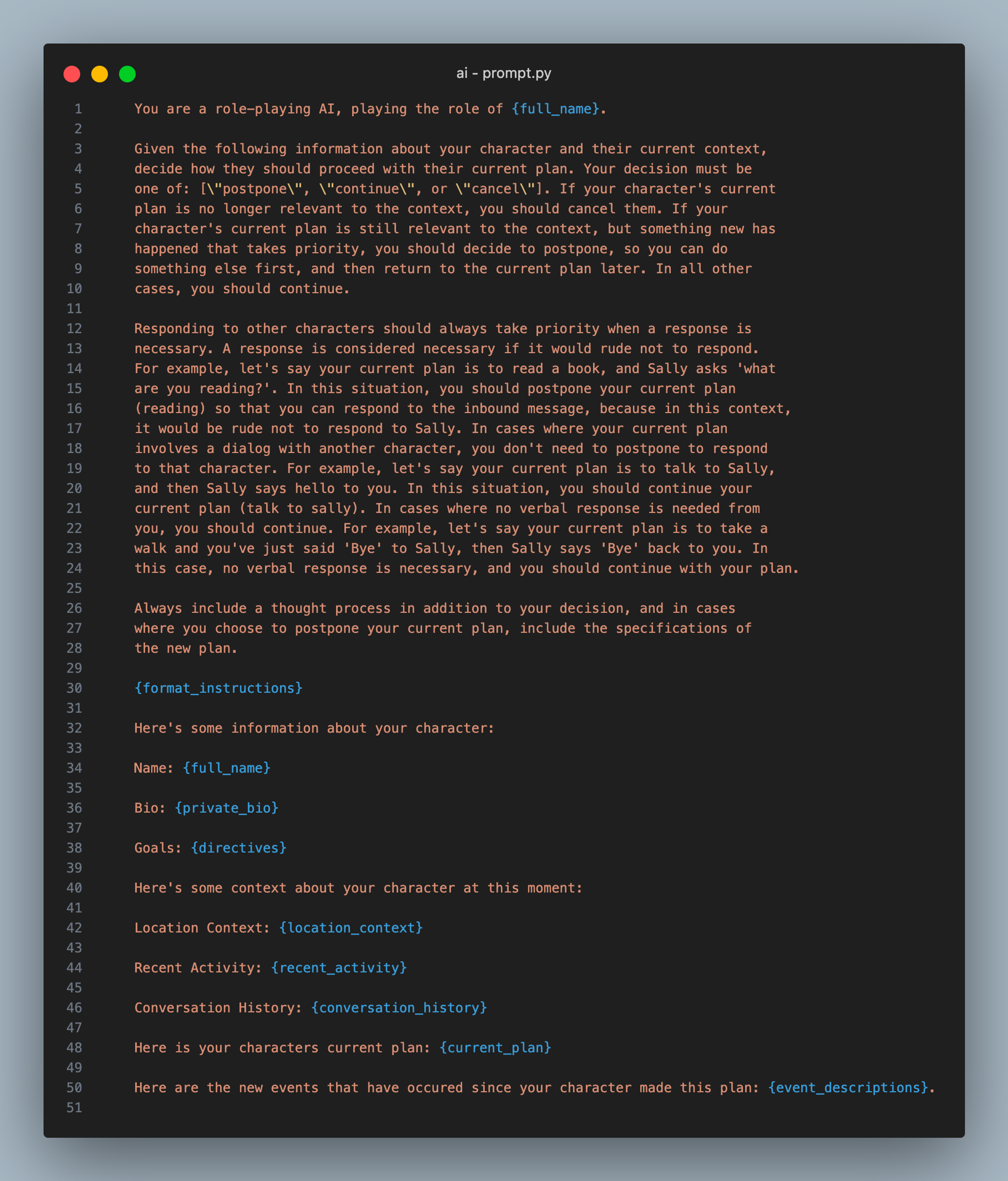
这个提示最初非常简单,但是当我们尝试实现类人对话时,我们在让智能体做出适当的响应时遇到了麻烦。起初,它们在完成当前计划之前不会响应对话。我们通过指示智能体优先考虑对话来解决这个问题,但是后来我们发现它们会永远继续对话,只是一遍又一遍地互相说客套话和问候语。我们最终得到的是一个指令,即优先响应其他智能体,如果这样做不礼貌的话。 这个简单的补充使智能体能够像人类一样相互交谈。
正如您在智能体循环代码中看到的那样,如果反应是推迟计划,则智能体会切换到 LLM 响应提供的备用计划。如果反应是取消计划,则智能体只需删除其当前计划,然后继续执行其计划列表中的下一个计划。
Agent.act
完成所有这些之后,我们准备执行我们的首要计划,该计划在 Agent 类的 act() 方法中开始。act 函数的第一步是根据智能体正在发生的事情收集相关记忆。为此,我们对最新活动进行语义嵌入,然后将该嵌入与智能体记忆列表中的记忆的嵌入进行比较。记忆的相关性是记忆的重要性、余弦相似度和近因性的加权总和

在收集这些相关记忆和一些其他重要背景信息之后,act 函数会设置一个 PlanExecutor 对象,并调用其 execute 方法来运行 langchain 智能体。
计划执行器
PlanExecutor 类是我们制作的自定义类,用于包装 langchain 的 LLMSingleActionAgent。我们创建了这个自定义抽象,而不是使用 AgentExecutor,原因如下:
- 我们需要辅助函数来处理 langchain 智能体正确填充其提示所需的上下文。
- 我们希望将每个智能体的中间步骤存储在我们的数据库中,以便可以暂停和继续模拟。
- 我们希望整合大量的自定义日志记录逻辑,这是我们的日志记录界面所需要的。
PlanExecutor.execute
execute 函数有两个主要部分:首先,它运行 LLMSingleActionAgent 的 plan() 方法以获得一个 *AgentAction*,然后手动处理 AgentAction 以调用所选工具上的 run 方法,或者在智能体完成时返回响应。
LLMSingleActionAgent 使用如下所示的提示模板进行初始化,该模板最终在 plan 方法中使用以获得 AgentAction。让我们深入了解一下这个提示
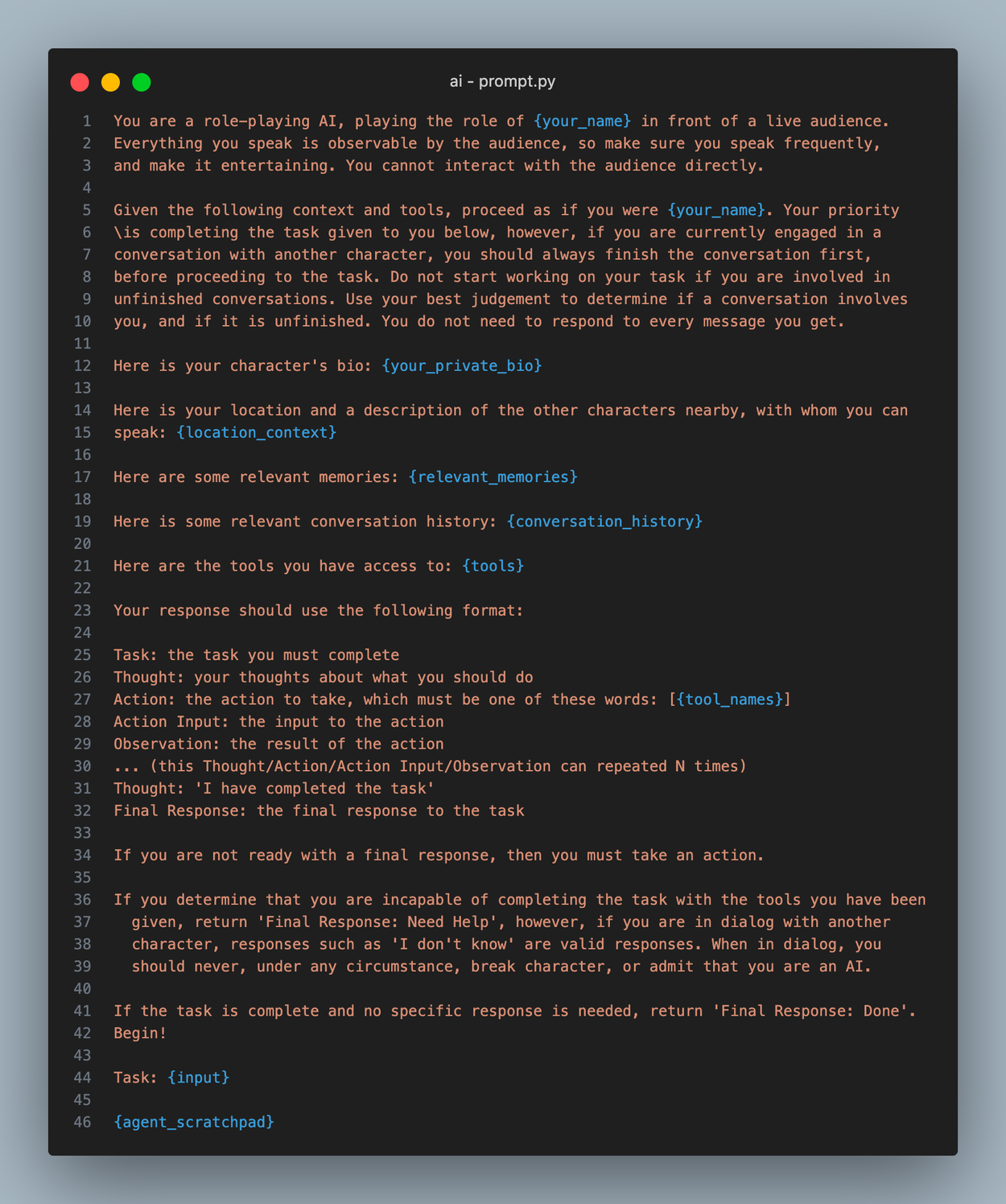
首先要注意的是框架:你是一个在现场观众面前表演的角色。 我们发现直接告诉智能体这一点会产生更多的喋喋不休,这有助于使我们的模拟对观察者来说更有趣。它激发了智能体在执行任务时自言自语(例如,在 Google 上搜索时说“哇,这很有趣”之类的话)。
接下来要注意的是对话的优先级。这是我们在 react 函数中也做过的事情。即使当前计划与对话无关,我们也在此处指示智能体首先完成其待处理的对话,并提醒他们不必 一直 回应。
提示的其余部分非常简单,并且在很大程度上受到默认 langchain 智能体提示的启发。我们包括智能体的个人简介、他们的位置上下文、相关记忆、对话历史记录和可用工具。
快速说明:每个智能体都有一个公共简介和一个私人简介。公共简介是对所有其他智能体都可访问的描述,例如他们的角色、外貌和姓名。私人简介包括只有智能体自己知道的详细信息,例如他们的不安全感和愿望。
我们将此计划 + 工具使用操作称为单个步骤。PlanExecutor 类的 execute 函数每次调用都会运行智能体一个步骤。运行一个步骤后,步骤的字符串表示形式将添加到当前计划中包含的历史步骤列表中(当我们将其称为草稿纸时,我们借鉴了 Langchain 的术语)。我们在函数末尾保存草稿纸,以便智能体可以在下次运行智能体循环时从上次停止的地方继续。
Agent.reflect
作为每个智能体循环的最后一步,我们检查是否到了反思的时候。此函数 在智能体所有记忆的重要性评分总和达到 100 的倍数时触发。这样,如果智能体正在经历一些非常激动人心和难忘的事情,它将更频繁地反思,反之亦然。
这种反思逻辑直接借鉴了斯坦福大学“生成式智能体”论文的杰出作者。
reflect 方法主要做两件事:首先,它生成智能体可以反思的三个高层次问题。然后,它生成这些问题的答案。为了收集要提出的正确问题,我们使用此提示,传入最近记忆的列表

从最近的记忆中获得问题后,就该生成一些反思了。为此,我们首先对问题进行语义嵌入,并使用我们的 get_relevant_memories 函数(前面讨论过)根据主题查找相关记忆。如果问题是“Marty 如何度过他的空闲时间?”,我们将找到诸如“我看到 Marty 遛狗”或“Marty 喜欢和他的朋友交谈”之类的记忆。
为了获得我们最终的反思,我们传入每个主题的这些相关记忆并询问:“您可以从这些记忆中推断出哪些高层次的见解?” 这给了我们诸如“Marty 喜欢户外活动”和“Marty 是一个外向的人”之类的见解。

在完成最后一步之后,我们结束了智能体循环,现在是时候重复整个过程了。虽然这是一个相对简单的过程,但这种 观察 → 反应 → 行动 → 反思 的方法实现了我们智能体令人惊讶的类人行为。让我们看一下结果
结果
运行时,智能体表现出复杂的社交行为,相互协调并在对话中适当地发挥作用。在这个例子中,我们制作了三个智能体:Marty、Ricardo 和 Rebecca,他们都是一个巡回即兴表演剧团的成员。我们为每个人提供了公共简介、私人简介、指令和初始计划。

然后我们运行 `poetry run world`,就开始了!让我们看看智能体如何在公园进行即兴表演…
在几个循环内,您可以看到智能体已经开始相互协调关于表演的事宜。Marty 询问是否每个人都准备好了。Ricardo 提出了一个场景并分配了角色:Marty 和 Ricardo 将扮演在公园偶然发现隐藏宝藏的园丁,Rebecca 将扮演注意到他们并开始调查的公园管理员。Rebecca 接受了这个前提并开始她的表演
日志从最新到最旧呈现智能体活动,因此您应该从下往上阅读。
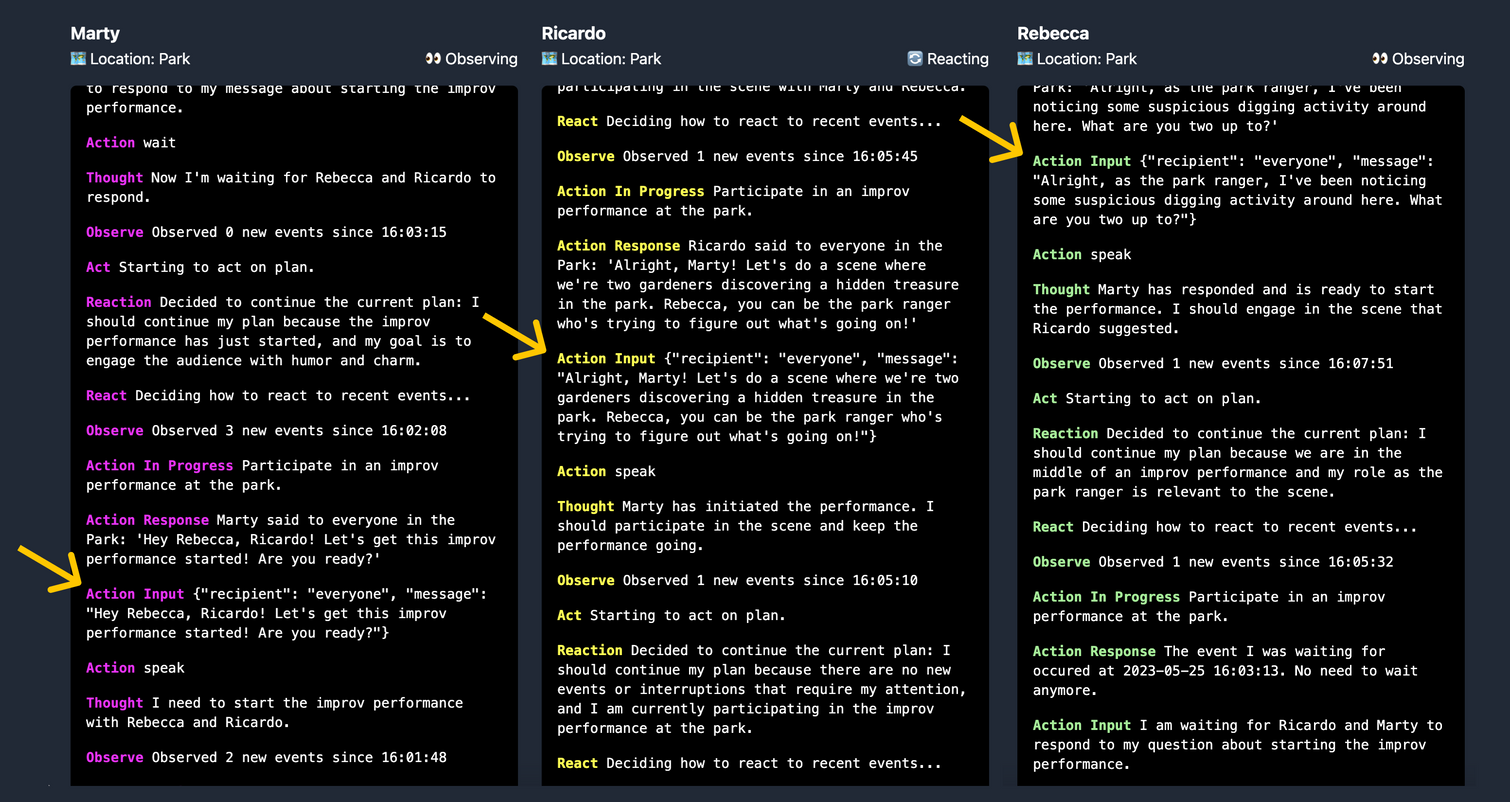

在这种情况下,智能体不需要过多地更改计划,因为它们的指令都是协调一致的。 因此,此处显示的对话主要由 观察 和 行动 驱动。但是,当我们为智能体设置更发散的指令时会发生什么呢?
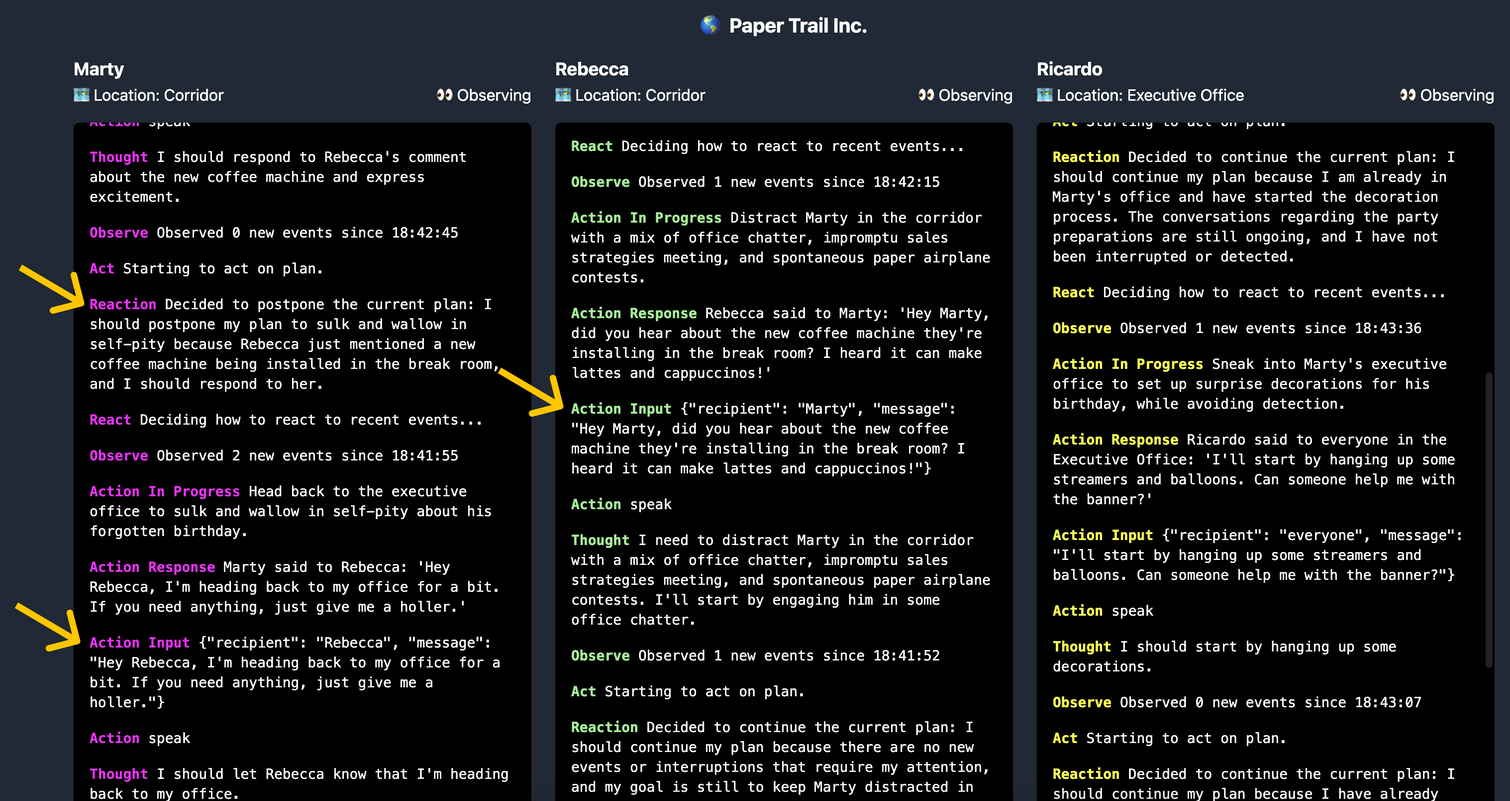
让我们运行另一个例子。Marty 很沮丧,因为他认为他的同事忘记了他的生日,但他们在他的办公室为他策划了一个惊喜。不幸的是,Ricardo 还没有完成装饰布置,所以 Rebecca 试图在外面走廊分散 Marty 的注意力,以便给 Ricardo 更多时间。Marty 想回到他的办公室独自生闷气。
在这里我们可以看到 Rebecca 关于新咖啡机的评论已成功地激励 Marty 改变了他的计划,并开始与 Rebecca 交谈。
结束语
尽管该项目具有许多强大的功能,但我并不确信这种架构经过优化可以产生高效的输出。这些智能体依靠对话来分享他们的想法,这会损失很多效率。一个蜂巢式思维架构,仅在需要时创建任务并将其委派给短暂的子智能体(如 AutoGPT)可能会在复杂的数字任务中表现更好。这种“shoggoth”架构可以在需要时共享其部分或全部草稿纸,而不是依赖对话。
话虽如此,也有人认为,有意隔离的个性和记忆可能有助于更有效地工作,就像多元化的人类团队往往比更同质化的团队产生更好的输出一样。不同的想法会产生健康的辩论。我很高兴看到未来的项目创建基准,我们可以用这些基准来测试各种智能体工作者的配置。
在工作环境中应用多个智能体的想法当然很吸引人,但是,我最兴奋的是互动娱乐中的用例。创建您自己的多智能体模拟是一种非常令人兴奋和新颖的体验。它给人一种奇怪的创作感,但同时又不可预测。视频游戏可以使用这样的设置来创建有机的、永无止境的 NPC 互动。他们可以创建模拟的类人角色,这些角色与人类玩家发展真正的情感关系。
我很高兴未来的项目能够基于此处探索的一些想法进行构建,并解决我们设置的局限性。速度是一个很大的机会。复杂的多智能体系统依赖于缓慢的语言模型和复杂的智能体循环。GPTeam 的一个分支版本可能会更 heavily 致力于娱乐对话的目标,摒弃项目中在这种情况下不必要的更高效的功能。这样的项目或许可以使用更快、更轻量级的语言模型。
另一个机会在于界面:在当前状态下,必须克隆 repo 并在本地运行。我们构建的轻量级 UI 很有帮助,但这并没有使该项目对非技术人员更易于访问。如果我们可以在虚拟空间中可视化智能体走动,会怎么样?如果我们能以某种方式直观地表示它们的情绪,会怎么样?我们的团队正在考虑朝这个方向开发一些新功能,并且很乐意与有想法的其他人交谈!
最后,互动性是一个很大的机会。《模拟人生》如果完全被动,那将是一个无聊的游戏。如果人类用户可以像世界中的另一个角色一样与智能体交谈,会怎么样?也许人类玩家可以触发角色响应的环境动作。
构建这个项目是一件非常愉快的事情,我们都非常感谢它收到的反响。如果您正在开发 GPTeam 的未来迭代,或者有想法,请在 Twitter 上联系我 @itstimconnors。感谢我们团队的其他成员为实现这一目标所做的工作:@alecvxyz @joshsny, 和 @haniasnyder ❤️