标签和元数据分组
长期以来,LangSmith 一直支持监控图表,以展示您的 LLM 应用程序随时间推移的重要性能和反馈指标(请参阅任何项目详细信息页面中的监控部分)。然而,到目前为止,还无法比较包含不同标签或元数据的已记录追踪的指标。在 LLM 应用程序中,通常有许多旋钮可供您使用(模型参数、提示、分块策略、回溯窗口),每个旋钮都可能对您的应用程序产生巨大影响。
借助标签和元数据分组,LangSmith 用户现在可以使用不同的标识符标记其应用程序的不同版本,并使用新的监控功能并排查看它们的性能。
发送带有标签和元数据的追踪
LangSmith 现在支持在监控图表中按标签和元数据进行分组。以下是关于如何使用标签和元数据记录追踪的快速回顾。有关更多信息,请查看我们的文档。
LangChain
如果使用 LangChain,您可以在 invoke 中向任何 Runnable 发送带有标签和/或元数据的字典。相同的概念也适用于 TypeScript。
chain.invoke({"input": "What is the meaning of life?"}, {"metadata": {"my_key": "My Value"}}) # sending custom metadata
chain.invoke({"input": "Hello, World!"}, {"tags": ["shared-tags"]}) # sending custom tagsLangChain Python
LangSmith SDK / API
如果您不使用 LangChain,您可以选择使用 SDK 或 API 来记录带有自定义标签和/或元数据的追踪。
# Using the Python SDK
import openai
from langsmith.run_helpers import traceable
@traceable(
run_type="llm"
name="My LLM Call",
tags=["tutorial"],
metadata={"githash": "e38f04c83"},
)
def call_openai(
messages: List[dict], model: str = "gpt-3.5-turbo", temperature: float = 0.0
) -> str:
return openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=temperature,
)Python SDK
// Using the TypeScript SDK
import { RunTree, RunTreeConfig } from "langsmith";
const parentRunConfig: RunTreeConfig = {
name: "My Chat Bot",
run_type: "chain",
inputs: {
text: "Summarize this morning's meetings.",
},
extra: {
metadata: {"githash": "e38f04c83"}
},
tags=["tutorial"]
};
const parentRun = new RunTree(parentRunConfig);
await parentRun.postRun();TypeScript SDK
# Using the REST API (in Python)
requests.post(
"https://api.smith.langchain.com/runs",
json={
"id": run_id,
"name": "My Run",
"run_type": "chain",
"inputs": {"text": "Foo"},
"start_time": datetime.datetime.utcnow().isoformat(),
"session_name": project_name,
"tags": ["langsmith", "rest", "my-example"],
"extra": {
"metadata": {"my_key": "My value"},
},
},
headers={"x-api-key": _LANGSMITH_API_KEY},
)REST API(在 Python 中)
案例研究:在 Chat LangChain 中测试不同的 LLM 提供商
Chat LangChain 是一个由 LLM 驱动的聊天机器人,旨在回答有关 LangChain Python 文档的问题。我们已使用 LangServe 将聊天机器人部署到生产环境,并启用了 LangSmith 追踪,以实现一流的可观察性。我们允许用户从四个 LLM 提供商(Claude 2.1、Fireworks 上托管的 Mixtral、Google Gemini Pro 和 OpenAI GPT 3.5 Turbo)中选择一个来驱动聊天体验,并使用 metadata 中的键 "llm" 发送模型类型。
假设我们有兴趣分析每个模型在重要指标方面的表现,例如延迟和首个令牌时间。
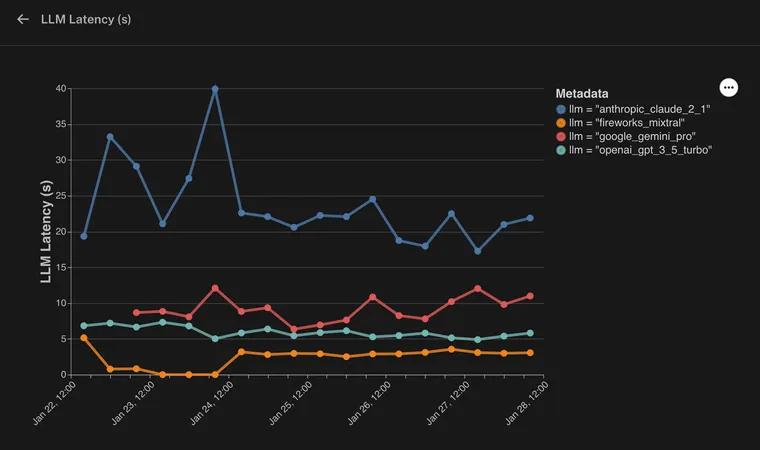
我们在此处可以看到,我们已按 llm 元数据键对监控图表进行了分组。通过分析图表,我们可以识别模型之间的任何变化或差异,并就我们的应用程序做出数据驱动的决策。
LLM 延迟
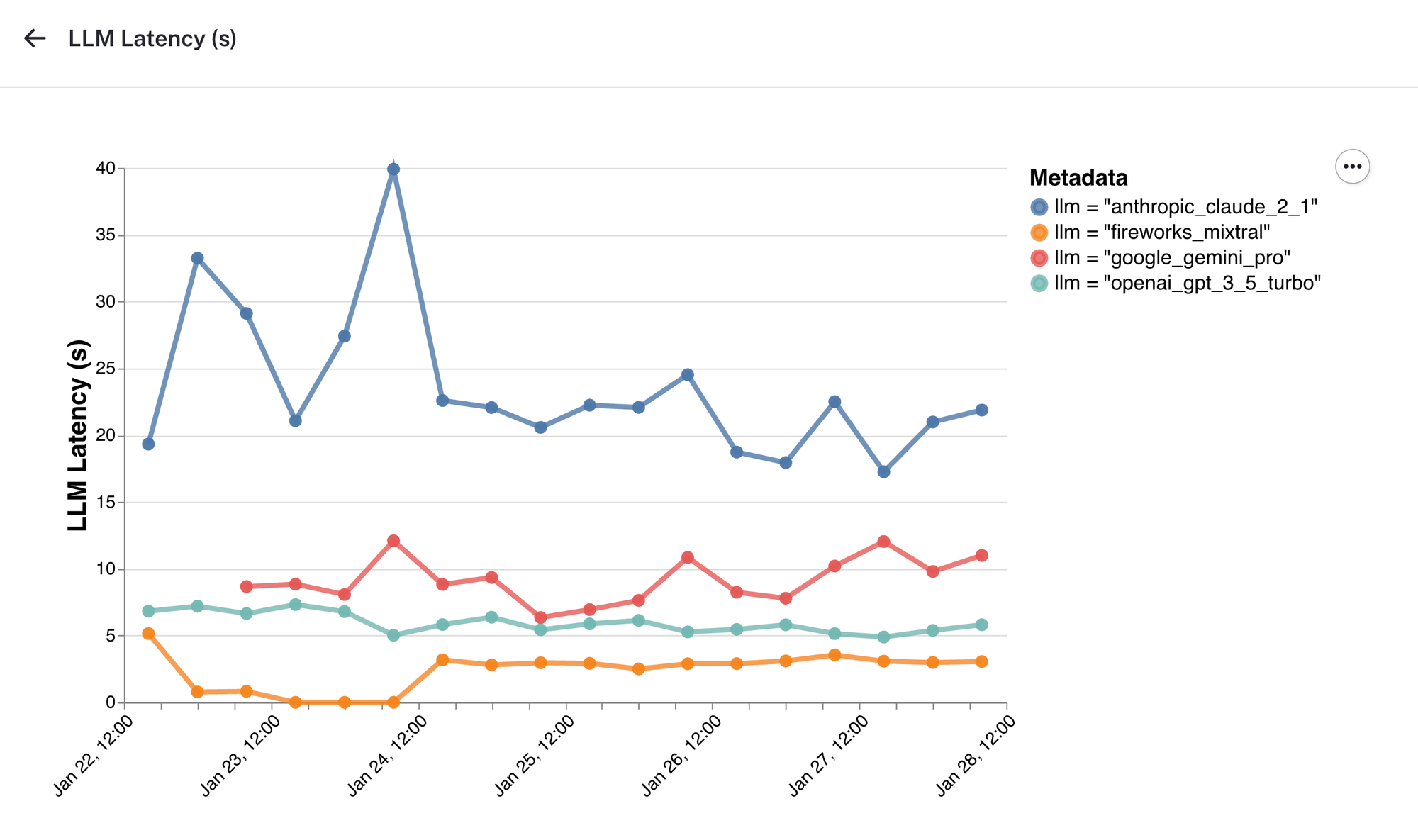
在这里,我们看到由 Fireworks 上的 Mixtral 驱动的响应比其他提供商完成得更快得多。
首个令牌时间
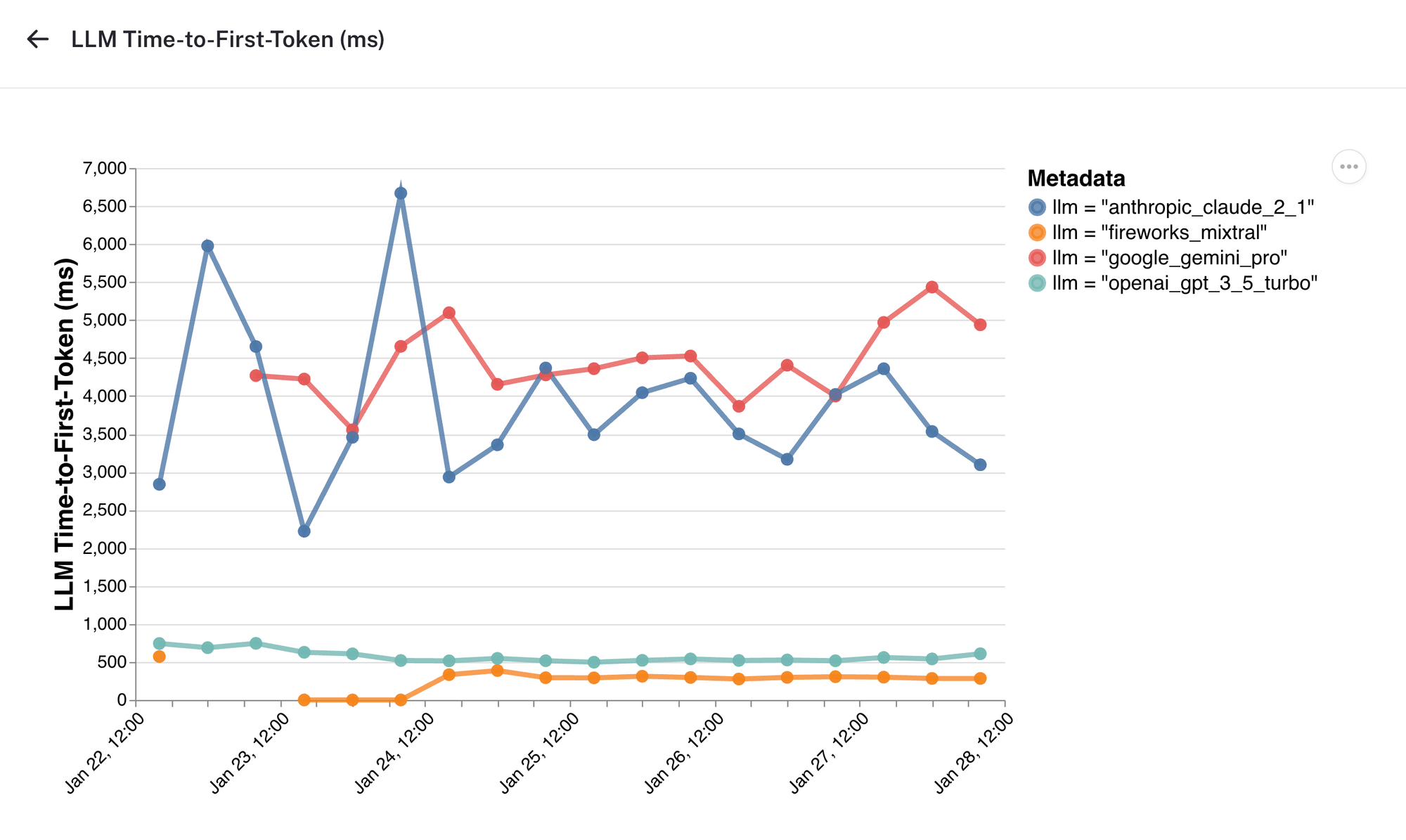
此图表显示了不同 LLM 提供商的首个令牌时间随时间的变化。有趣的是,虽然 Google Gemini 提供的整体完成时间比 Claude 2.1 更快,但首个令牌时间的趋势却更慢。
反馈
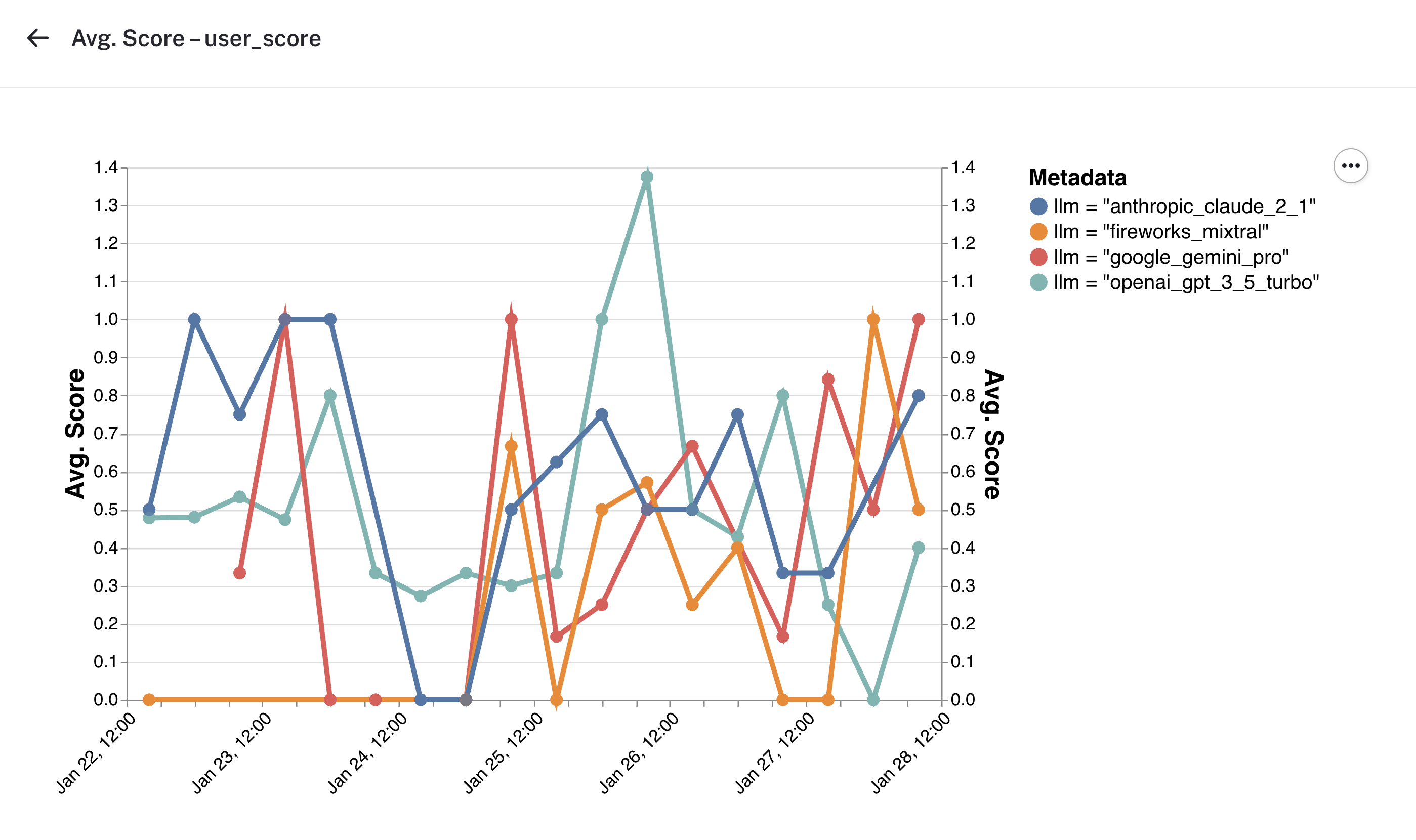
监控部分还显示了随时间推移的不同标准反馈图表。虽然在此期间我们的反馈数据存在噪声,但您可以想象,看到不同模型提供商的聊天机器人响应中用户满意度的明显趋势将有助于评估模型延迟与响应质量之间的权衡。
其他用例
在这里,我们向您展示了如何在 LangSmith 中使用元数据和标记将您的数据分组为不同的类别(每个模型类型一个类别),然后并排分析每个类别的性能指标。这种范例可以轻松应用于其他用例
- 使用修订进行 A/B 测试:假设您正在应用程序中推出不同的功能修订或版本,并希望并排测试它们。通过在元数据中发送
revision标识符并在图表中按此修订进行分组,您可以清楚地看到每个版本相对于彼此的性能。 - 增强用户体验:通过在元数据中使用
user_id或conversation_id对数据进行分组,您可以深入了解不同用户体验应用程序的方式,并识别任何特定于用户的问题或趋势。
这些示例仅仅是 LangSmith 新分组功能可能实现的冰山一角。