LLM 的几个关键用例涉及以结构化格式返回数据。提取是其中一个用例 - 我们最近通过更新的文档和一个专门的仓库强调了这一点。查询分析是另一个用例 - 我们最近也更新了我们关于此的文档。当以结构化格式返回信息时,字段可以是多种类型:字符串、布尔值、整数。最难正确处理的类型之一是高基数类别值(或枚举)。
“高基数类别值”是什么意思?“类别值”指的是必须是几个可能值之一的值 - 例如,它们不能是任意数字或字符串,它们必须在允许的集合中。 “高基数”的意思是有很多有效值。
为什么这很困难?这很困难,因为 LLM 本质上不知道字段可能有哪些可能的值。 因此,您需要向 LLM 提供有关可能值范围的信息。 如果您不这样做,它将编造值。 对于少量可能的类别值,这很容易 - 您只需将这些值放在提示中,并好好地要求 LLM 仅使用这些值。 但是,对于大量的值,它变得更加棘手。
随着可能值的数量增加,LLM 越来越难填写正确的值。 首先,如果可能值的数量足够高,那么它们可能不适合上下文。 其次,即使所有可能的值都可以适合上下文,将它们全部塞进去也会导致速度、成本以及 LLM 对所有上下文进行推理的能力出现问题。
最近我们花了很多时间思考查询分析,当我们改进此用例的文档时,我们明确添加了一个关于如何处理高基数类别值的页面。 在这篇博客中,我们想深入探讨我们试验过的几种方法,并为它们的表现提供具体的基准。
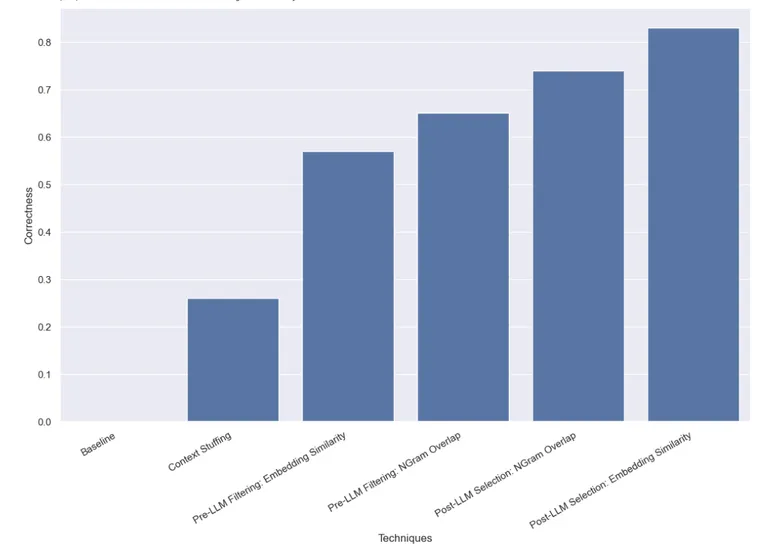
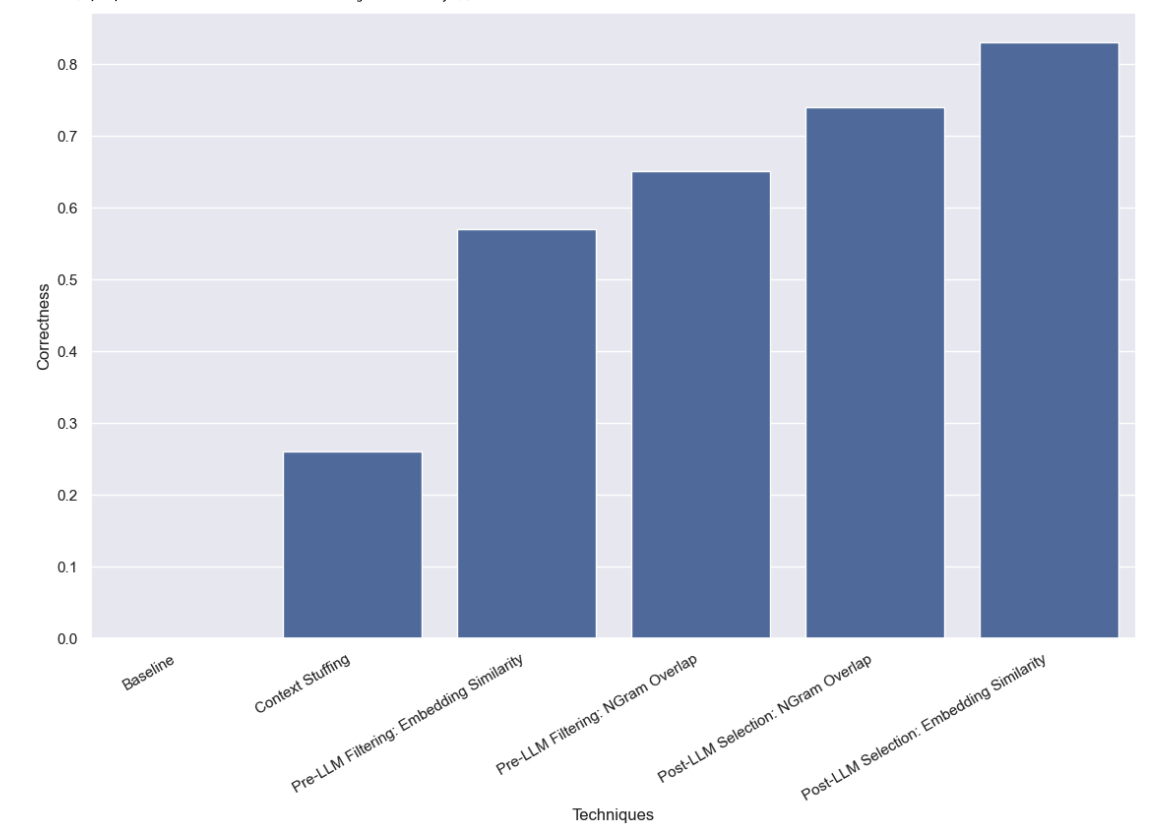
这是结果的预览,您也可以在 LangSmith 中查看。 请继续阅读以了解更多详情
数据集
您可以在此处查看数据集。
为了模拟这个问题,我们将想象这样一种情况:我们想按作者查找书籍。 作者字段是一个高基数类别变量 - 它可以取很多不同的值,但它们应该是特定的有效作者姓名。 为了测试这一点,我们创建了一个作者姓名和常用别名的数据集。 例如,Harry Chase 可能是 Harrison Chase 的别名。 我们希望智能系统能够处理这些类型的别名。 一旦我们有了这个姓名和别名列表,我们又生成了 10,000 个其他随机姓名。 请注意,10,000 甚至还不是真正的高基数 - 对于企业系统,这可能是数百万。
创建此数据集后,我们会提出诸如“哈利·蔡斯关于外星人的书有哪些?”之类的问题。 我们的查询分析系统应该将此解析为结构化格式,其中包含两个字段:主题和作者。 在这种情况下,预期结果将是 {“topic”:’ “aliens”, “author”: “Harrison Chase”}。 我们希望我们的系统能够识别出没有名为 Harry Chase 的作者,但 Harrison Chase 可能是用户想要表达的意思。
通过这种设置,我们可以针对我们创建的别名数据集运行此练习,看看它们是否正确映射到真实姓名。 我们还将跟踪延迟和成本。 这种类型的查询分析系统通常用于搜索,这意味着我们会合理地关注这两个因素。 因此,我们也限制所有方法仅进行一次 LLM 调用。 我们可能会在以后的文章中对进行多次 LLM 调用的方法进行基准测试。
下面,我们介绍几种不同的方法以及它们的表现。
您可以在LangSmith 中的完整结果中查看,以及在此处查看重现结果的代码。
基线
首先,我们对仅要求 LLM 进行查询分析而不告知其有效名称可能是什么的基线进行了基准测试。 正如预期的那样,这没有得到一个正确的响应。 这是通过构造实现的 - 我们正在对一个数据集进行基准测试,该数据集明确要求按作者的别名查找作者。
上下文填充
在这种方法中,我们将所有 10,000 个合法的作者姓名填充到提示中,并要求 LLM 进行查询分析,同时记住这些是合法的作者姓名。 一些模型(如 GPT-3.5)甚至根本无法运行此操作(由于上下文窗口限制)。 对于其他具有较长上下文窗口的模型,它们很难准确地选择正确的姓名。 GPT-4 仅在 26% 的示例中选择了正确的姓名。 它会犯的最大错误是提取姓名而不进行更正。 这种方法也相当缓慢且成本高昂,平均运行时间为 5 秒,总成本为 $8.44。
LLM 前过滤
我们进行基准测试的下一种方法是过滤传递给 LLM 的可能值列表。 这样做的好处是将可能名称的子集传递给 LLM,这意味着它需要考虑的名称会少得多,有望使其能够更快、更便宜、更准确地进行查询分析。 这确实增加了一个单独的潜在故障模式 - 如果初始过滤是错误的怎么办?
按嵌入相似度过滤
对于初始过滤,我们使用了基于嵌入的方法,并选择了与查询最相似的 10 个姓名。 请注意,这里我们将整个查询与姓名进行比较 - 这不是一个很好的比较!
我们发现,使用这种方法,GPT-3.5 成功地获得了 57% 的正确示例。 这也比以前的方法更快、更便宜,平均运行时间为 0.76 秒,总成本为 $.002。
按 NGram 相似度过滤
我们使用的第二种过滤方法是将 TF-IDF 向量化器拟合到所有有效名称的 3-gram 字符序列,并使用向量化的有效名称和向量化的用户输入之间的余弦相似度来选择前 10 个最相关的有效名称添加到模型提示中。 请注意,这里我们将整个查询与姓名进行比较 - 这不是一个很好的比较!
我们发现,使用这种方法,GPT-3.5 成功地获得了 65% 的正确示例。 这也比以前的方法更快、更便宜,平均运行时间为 0.57 秒,总成本为 $.002。
LLM 后选择
我们进行基准测试的最后一种方法涉及首先使用 LLM 进行查询分析,然后在事后尝试纠正任何错误。 我们首先对用户输入运行查询分析,并且没有在提示中放入任何关于有效作者姓名可能是什么的信息。 这与我们最初运行的基线相同。 然后,我们运行了一个步骤,该步骤获取作者字段中的姓名并找到最相似的有效姓名。
按嵌入相似度选择
首先,我们通过使用嵌入来完成此相似性检查。
我们发现,使用这种方法,GPT-3.5 成功地获得了 83% 的正确示例。 这也比以前的方法更快、更便宜,平均运行时间为 0.66 秒,总成本为 $.001。
按 NGram 相似度选择
最后,我们尝试使用我们的 3-gram 向量化器进行此相似性检查。
我们发现,使用这种方法,GPT-3.5 成功地获得了 74% 的正确示例。 这也比以前的方法更快、更便宜,平均运行时间为 0.48 秒,总成本为 $.001。
结论
我们对各种使用高基数类别进行查询分析的方法进行了基准测试。 我们将自己限制为仅允许进行一次 LLM 调用,这阻止了我们使用链接或代理技术。 这样做是为了模拟实际的延迟约束。 我们发现,使用通过嵌入相似度进行的 LLM 后选择效果最佳。
还有其他方法可以进行基准测试。 特别是,有很多方法可以考虑查找最相似的类别值(在 LLM 调用之前或之后)。 此数据集中使用的类别也不像许多企业系统必须处理的类别那样具有高基数。 此数据集有约 1 万个值,许多真实世界的数据集有数百万个。 在更高基数的数据上进行基准测试,并增加数据量将是值得的。