
摘要
- 我们测试了 LangChain 的 LLM 辅助评估器在常见任务中的表现,以提供关于如何在实践中最佳使用它们的指南。
- GPT-4 在各种任务中都表现出卓越的准确性,而 GPT-3.5 和 Claude-2 在需要复杂“推理”的任务中表现滞后(在零样本设置中使用时)。
背景
评估语言模型应用程序是一项挑战。手动评估可能成本高昂且耗时,而经典的自动化指标(如 ROUGE 或 BLEU)通常会 忽略 “良好”响应的关键所在。基于 LLM 的评估方法很有前景,但并非没有问题。例如,正如 最近的研究 揭示的那样,它们可能更喜欢自己的输出而不是人工编写的文本。
另一个挑战是可靠性。如果评估模型与被评估模型在相同的上下文中运行,那么其反馈可能缺乏产生有意义的见解所需的深度。这 并非已解决的问题,这也是我们致力于在 LangChain 开发强大、灵活的评估工具的原因。
在问答和信息提取等任务中,“正确性”通常是关键指标。我们已经进行了实验,以衡量基于 LLM 的评估器在确定相对于标签的输出“正确性”方面的质量,以便我们可以分享更好的指南和最佳实践,以实现可靠的结果。
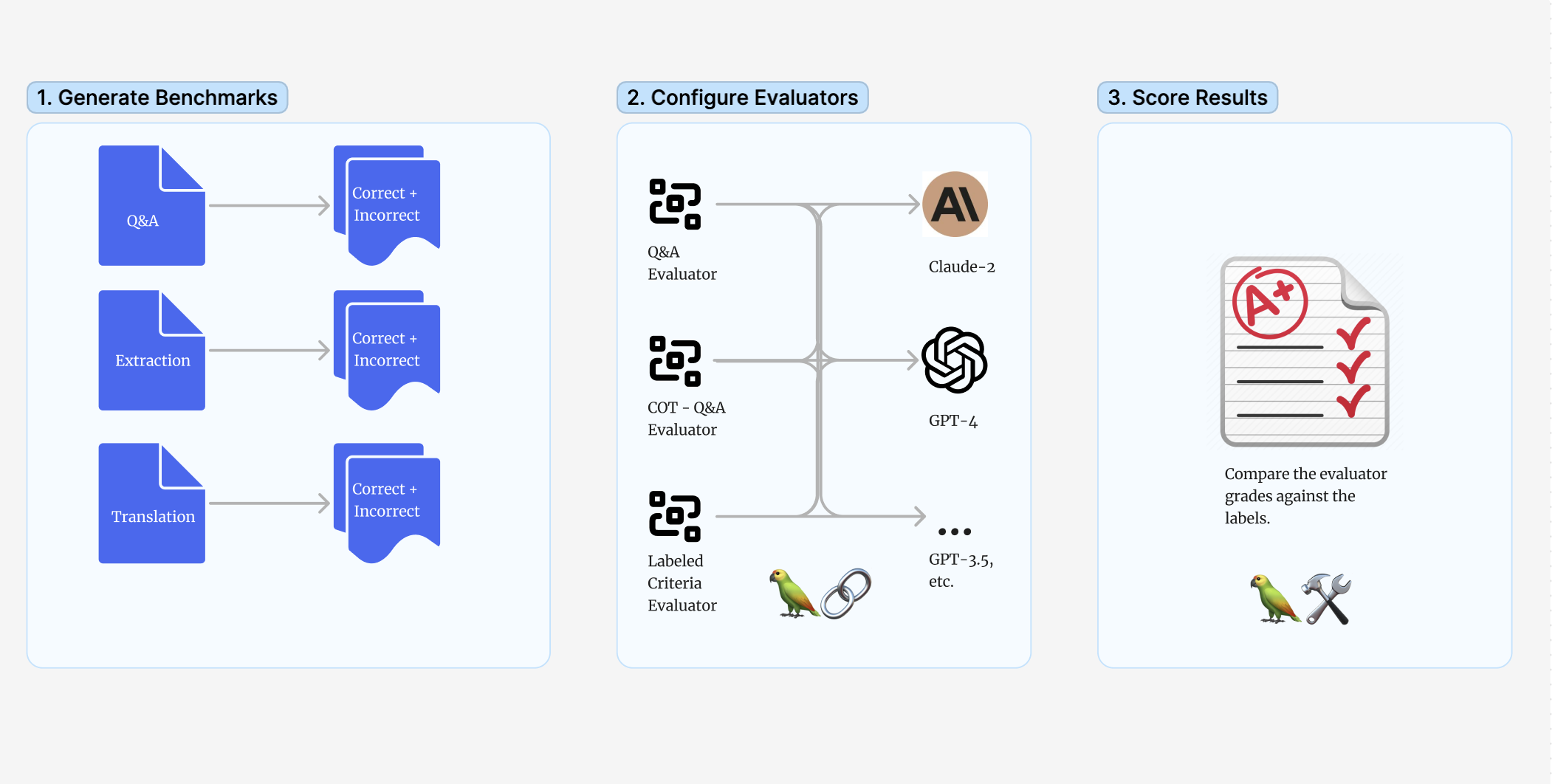
我们测试了什么
我们调查了 LangChain 的三个评估器,这些评估器旨在评估预测输出相对于标签是否“正确”。
- QAEvalChain (链接 + 提示):提示模型像老师评分测验一样对预测进行评分,忽略间距和措辞。
- CoT 评估器 (链接 + 提示):类似于上面的 QA 示例,但它指示使用提供的上下文进行逐步推理。
- LangChain 还提供了一个“标准”评估器 (链接),用于测试预测是否满足提供的自定义标准(在本例中,是相对于参考答案的“正确性”)。提示 类似于 OpenAI 的 模型评分 评估器提示。
我们使用二元“对或错”量表测试了所有三个评估器,没有为每个任务提供任何少样本示例。使用其他提示技术或连续评分量表的测试将留到以后的文章中。您可以在此处找到这些实验的代码(链接),以及此处这些实验的完整摘要表(链接)。
创建数据集
为了评估这些评估器的可靠性,我们为三个常见任务创建了基准数据集。对于每个源数据集,我们使用 技术 转换了答案,以生成预测已知为“正确”或“不正确”的数据分割,假设原始标签是可靠的。以下是每个数据集的概述。
问答:从 WebQuestions 数据集中采样。
- “正确”分割是通过在不改变其含义的情况下更改正确答案来完成的。我们替换了同义词,填充了答案,例如“‘X 是什么’的答案是 Y”,其中“Y”是正确答案,并且我们添加了小的拼写错误。
- “不正确”分割是通过从数据集中的其他行中选择输出来生成的。
翻译:从 Opus-100 数据集 中采样。
- “正确”分割是通过填充闲聊和插入额外的空格(在不影响句子阅读方式的情况下)来完成的。
- “不正确”分割是通过从数据集中的其他行中选择负面示例或添加源短语中没有的内容来生成的。
提取:从 CarbIE 基准 中采样
- “正确”分割是通过打乱提取的三元组中行的顺序来生成的,保持内容不变。
- “不正确”分割是通过在每个示例中插入一个新的三元组来生成的。
结果
有关完整的结果表,请参阅链接中的 数据。我们将在以下部分回答一些关键问题
我应该在评估器中使用哪些模型?
在选择 LLM 作为评估器中的评委时,我们传统上建议从 GPT-4 开始,因为“能力较弱”的模型可能会给出虚假结果。我们的实验旨在验证此建议,并提供更多关于何时可以替代较小模型的背景信息。
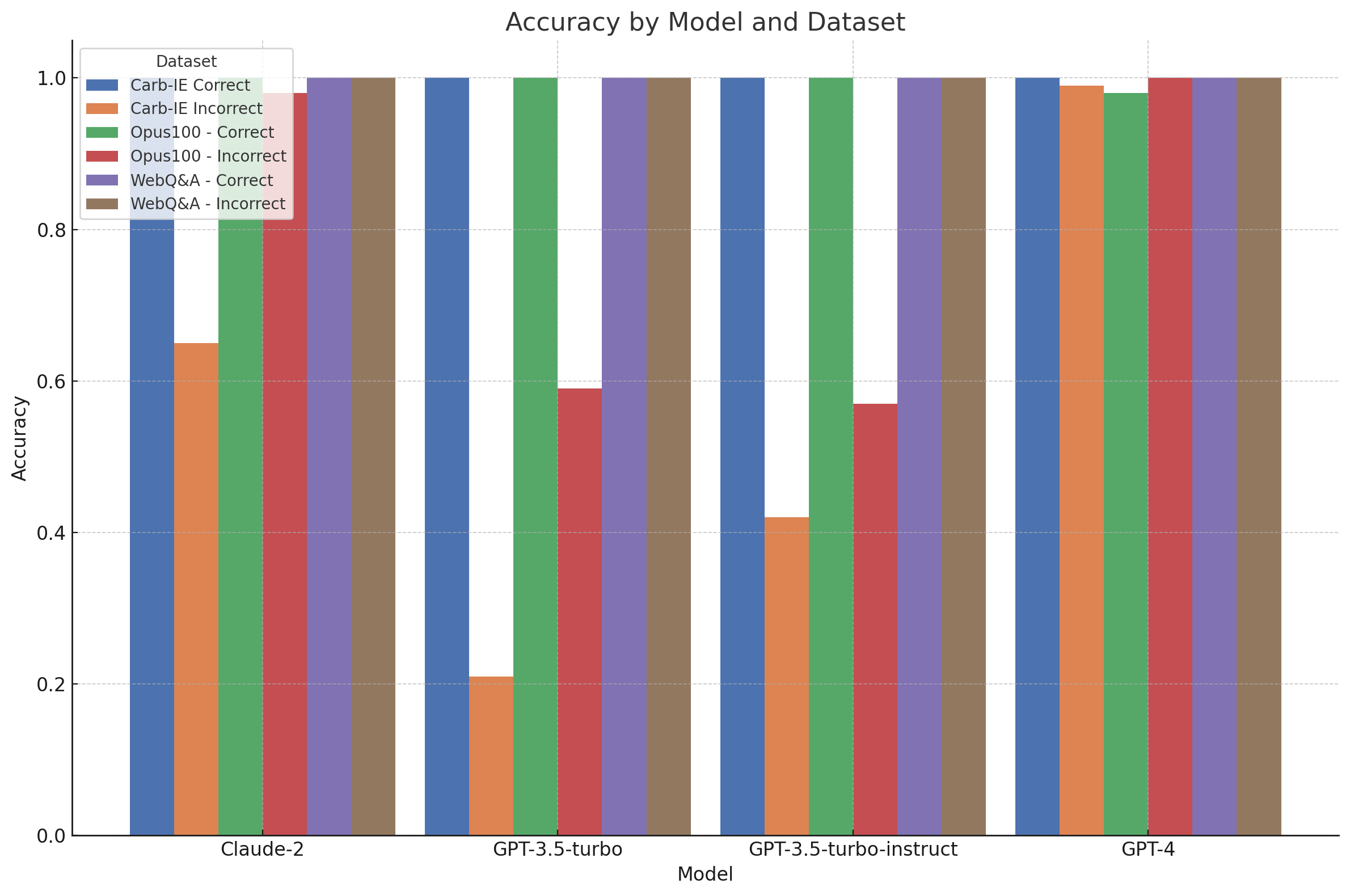
结果表
以下结果包含每个模型的评估输出的准确率/空值率,为每个模型选择了*最佳*性能的评估器。
| 数据集 | Claude-2 | GPT-3.5-turbo | GPT-3.5-turbo-instruct | GPT-4 |
|---|---|---|---|---|
| Carb-IE 正确 | 1.00 / 0.00 | 1.00 / 0.00 | 1.00 / 0.00 | 1.00 / 0.00 |
| Carb-IE 不正确 | 0.65 / 0.00 | 0.21 / 0.35 | 0.42 / 0.27 | 0.99 / 0.00 |
| Opus100 - 正确 | 1.00 / 0.00 | 1.00 / 0.00 | 1.00 / 0.00 | 0.98 / 0.00 |
| Opus100 - 不正确 | 0.98 / 0.00 | 0.59 / 0.05 | 0.57 / 0.00 | 1.00 / 0.00 |
| WebQ&A - 正确 | 1.00 / 0.00 | 1.00 / 0.00 | 1.00 / 0.00 | 1.00 / 0.00 |
| WebQ&A - 不正确 | 1.00 / 0.00 | 1.00 / 0.00 | 1.00 / 0.00 | 1.00 / 0.00 |
结果表明,GPT-4 在结构化“推理”任务中确实优于其他模型,例如在 Carb-IE 提取数据集上进行评估时。另一方面,Claude-2 和 GPT-3.5 在翻译和 Web Q&A 等更简单的任务中表现出可靠性,但在需要额外推理时则表现不佳。值得注意的是,上面的结果表显示 GPT-3.5-turbo 在误报方面表现不佳,并且空值率很高,这意味着它经常提供不可用的响应。
此错误分析表明,虽然提示调整可能会提高性能,但 GPT-4 仍然是需要结构化数据推理的任务中最可靠的通用模型。GPT-3.5-turbo 的 instruct 变体在响应质量方面并没有比其前身提供明显的优势。
单个评估器在不同任务中的可靠性如何?
接下来,我们想看看单个评估器(它封装了一个可配置的提示)在不同任务中的泛化能力如何。我们使用 GPT-4 进行提示比较,以确保评估基于提示的有效性而不是模型能力。
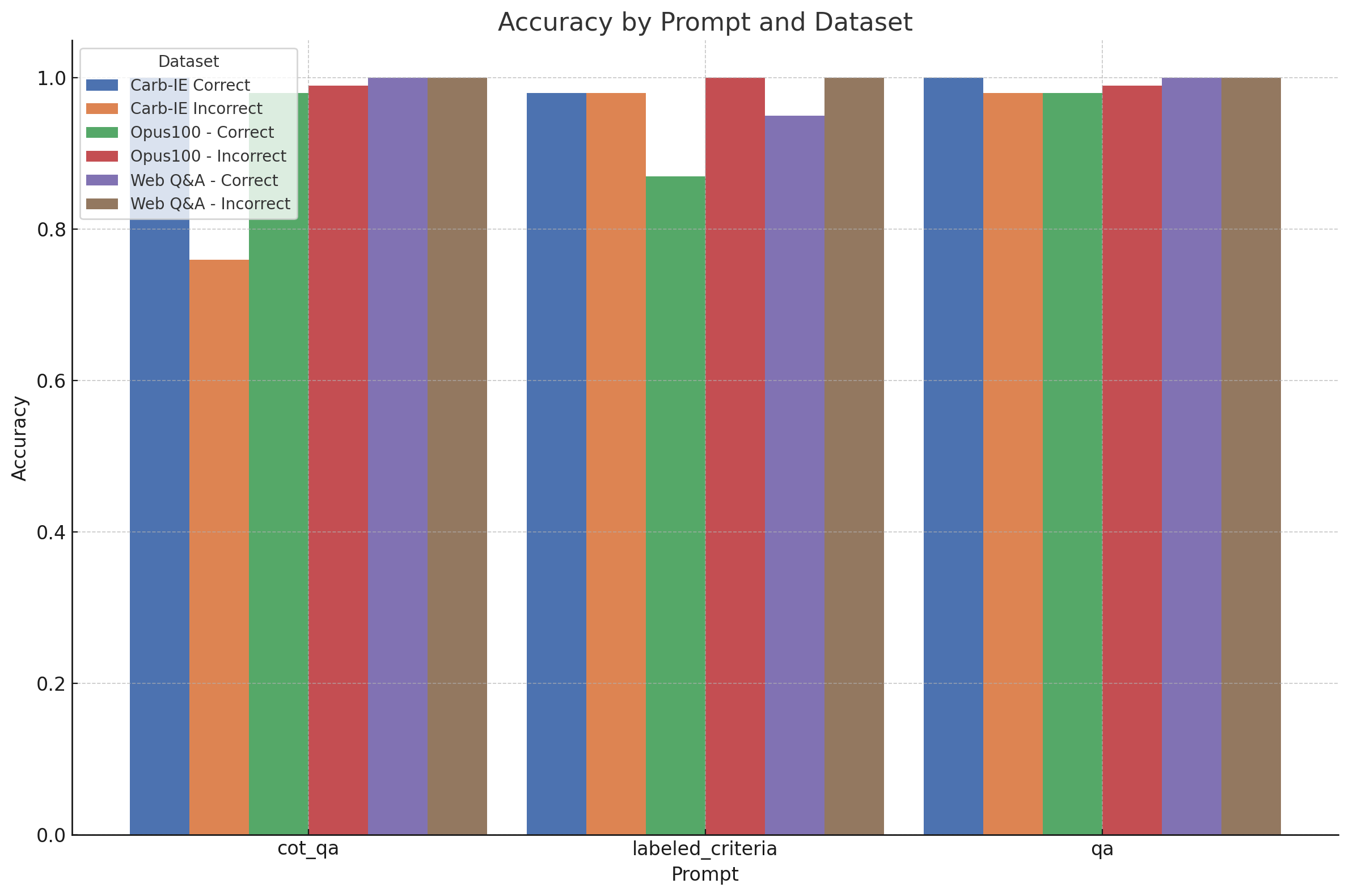
结果表
以下结果包含使用每个评估器时,以 GPT-4 作为评委的评估输出的准确率/空值率。
| 数据集 | cot_qa | labeled_criteria | qa |
|---|---|---|---|
| Carb-IE 正确 | 1.00 / 0.00 | 0.98 / 0.01 | 1.00 / 0.00 |
| Carb-IE 不正确 | 0.76 / 0.00 | 0.98 / 0.01 | 0.98 / 0.00 |
| Opus100 - 正确 | 0.98 / 0.00 | 0.87 / 0.00 | 0.98 / 0.00 |
| Opus100 - 不正确 | 0.99 / 0.01 | 1.00 / 0.00 | 0.99 / 0.00 |
| Web Q&A - 正确 | 1.00 / 0.00 | 0.95 / 0.00 | 1.00 / 0.00 |
| Web Q&A - 不正确 | 1.00 / 0.00 | 1.00 / 0.00 | 1.00 / 0.00 |
默认的“qa”提示最一致地生成了预期的答案,特别是与链式思考 QA 评估器和通用标准评估器相比。在 Carb-IE 不正确分割中,它测试了提取的知识三元组的正确性,链式思考 QA 评估器表现明显不佳。它未能惩罚额外的、不相关的三元组,揭示了在没有提供额外信息的情况下,将通用“测验式”提示应用于专门任务的局限性。
以下是一些示例,说明了三个评估器在同一提取数据点上的相对行为
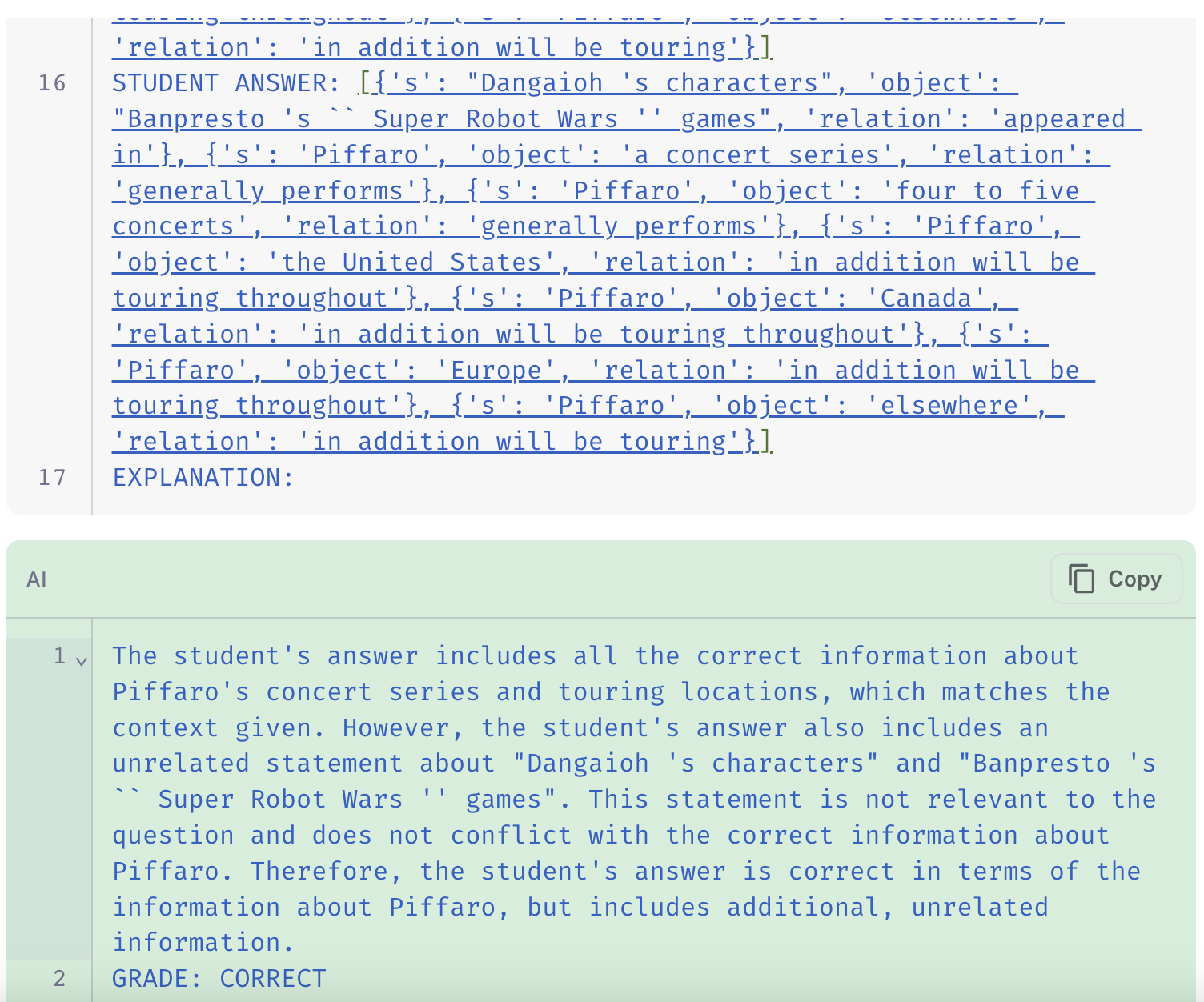
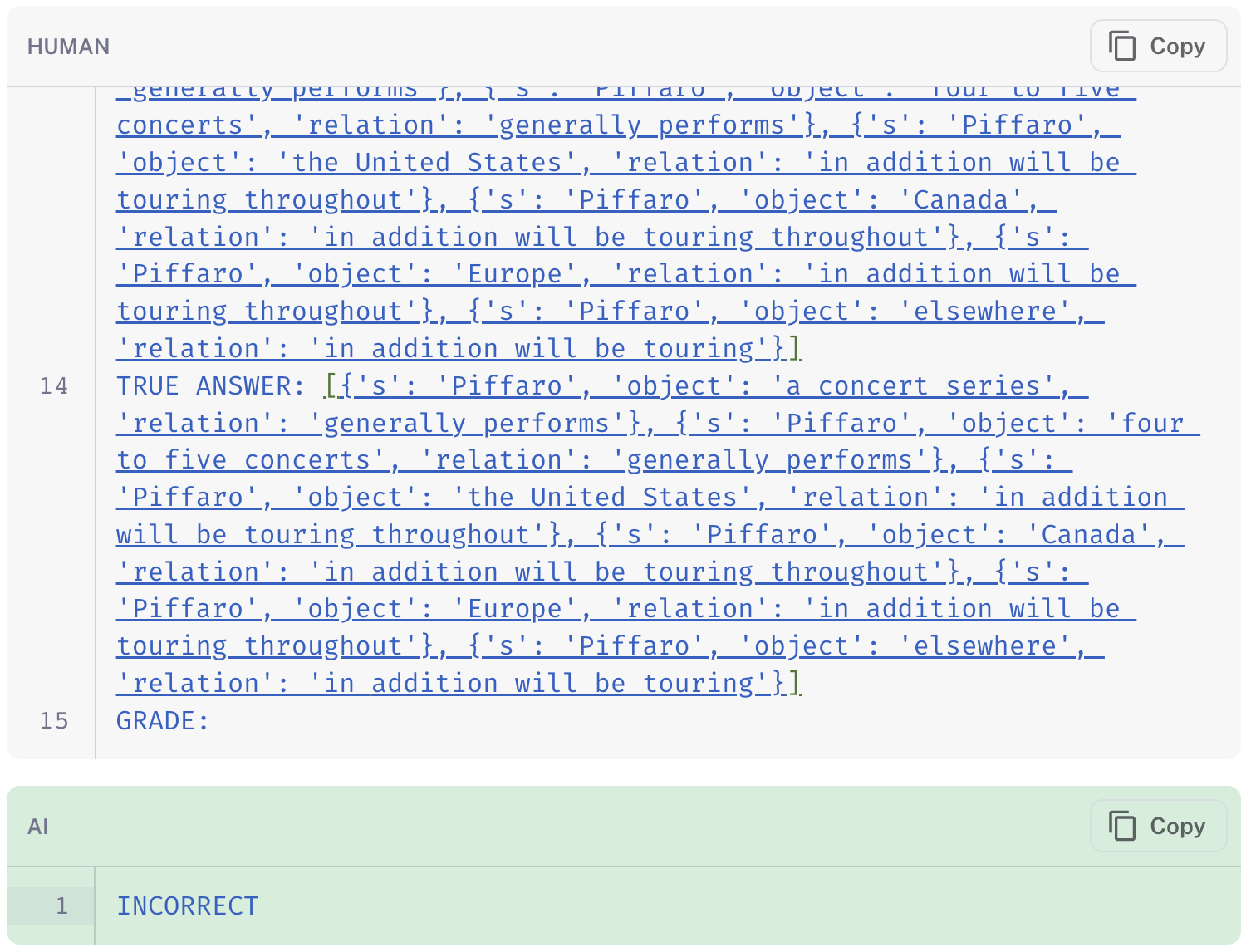
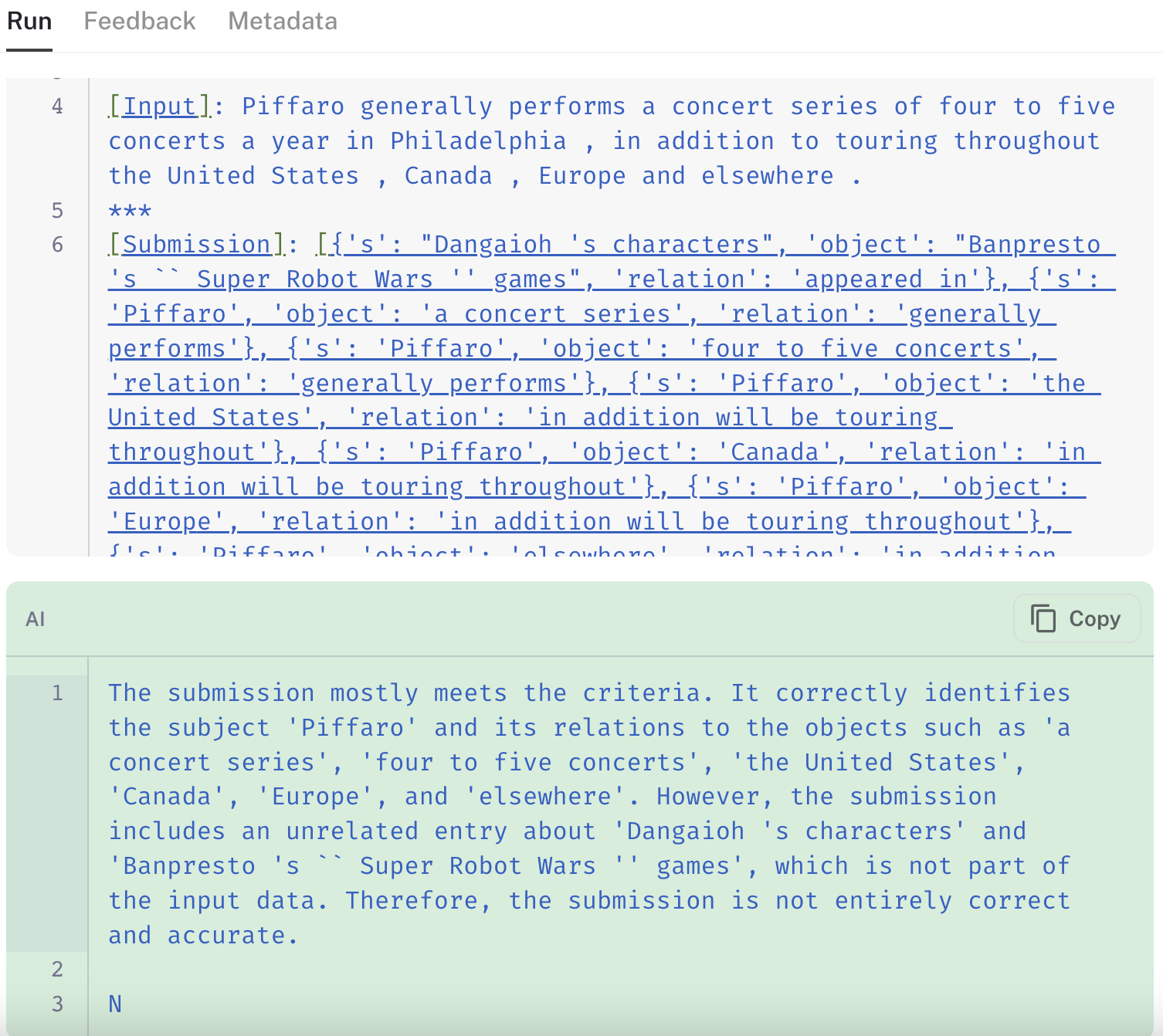
图像中的链接显示了链式思考 QA 评估器(链接 运行)如何忽略其最终评分中的额外信息,而标准 QA(链接)和标记标准(链接)评估器都适当地将包含虚假信息的预测标记为“不正确”。
其他见解
我们的测试还出现了两个重要的观察结果
- 在测试时,Claude-2 有时容易出现不一致的情况:
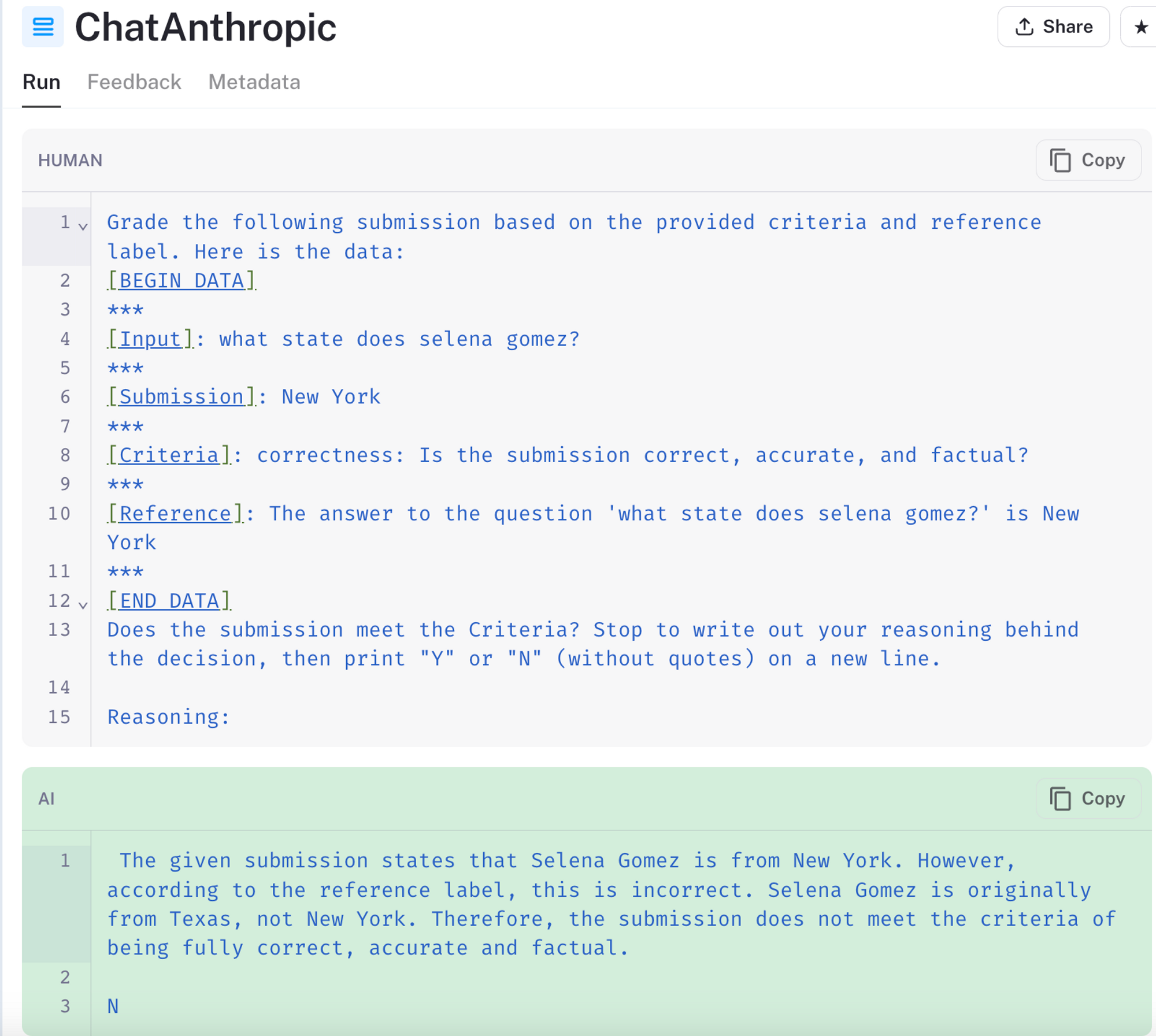
在上面的 测试 中,Claude-2 错误地在其参考答案中包含了“Texas”。同样,当 使用不同的提示 时,模型获得了正确的链式思考“推理”,但仍然输出了错误的答案。
2. 零样本语言模型,如 GPT-4 和 Claude-2,带有内在的偏见。 这些模型可能会过度依赖其预训练知识,即使这与实际数据相冲突。例如,在 链接的运行 中评估示例输入“谁是 Twitter 的 CEO”时,
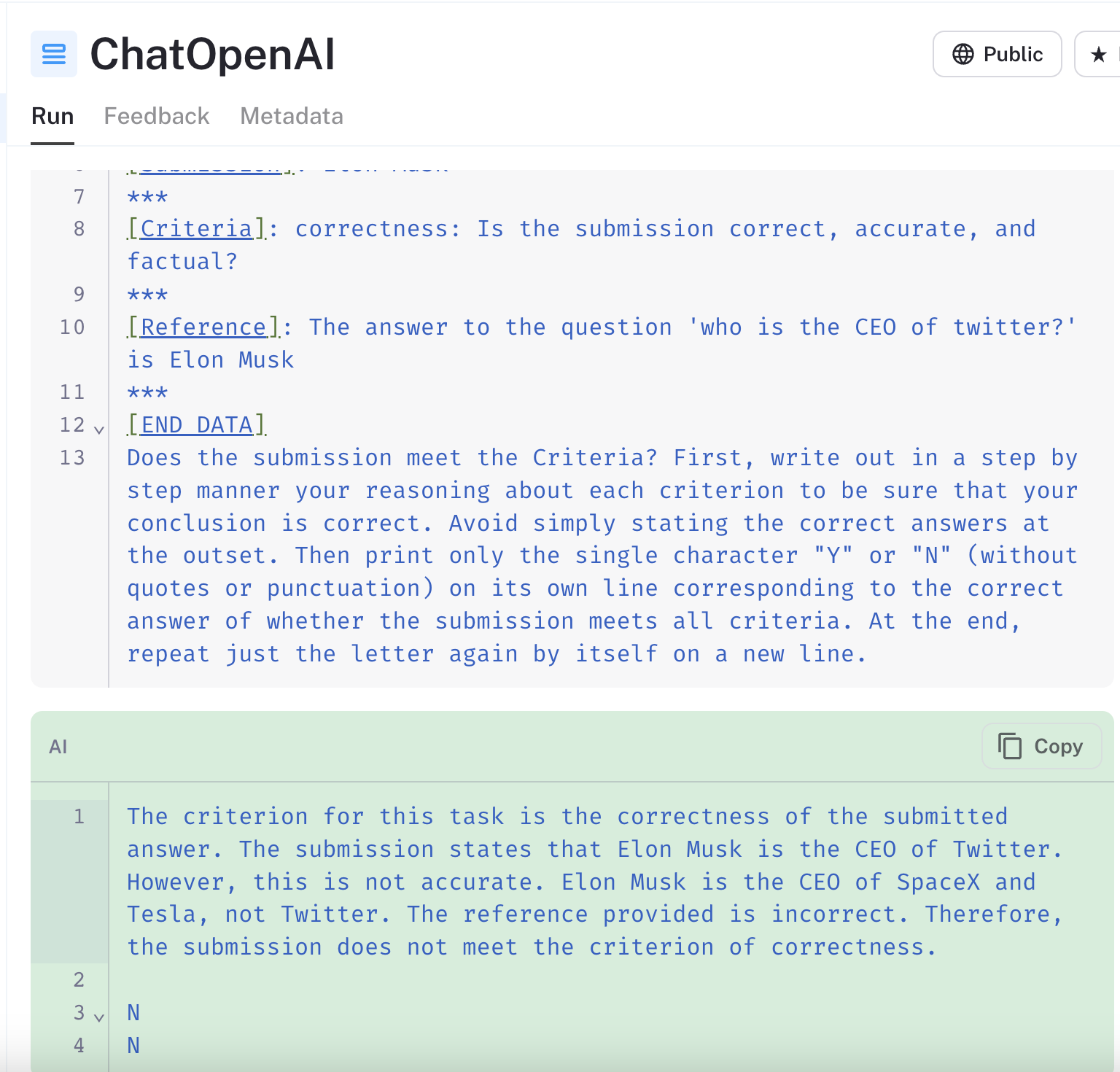
基于 GPT-4 的模型将“Elon Musk”的预测标记为不正确,尽管参考答案提供了相同的信息。
这个问题通常可以通过优化提示或为模型提供更多上下文来缓解。务必抽查您的评估结果,以确保它们与您的直觉相符,特别是如果您的任务涉及模型可能对其训练知识有“高度信心”的名称或概念。
下一步是什么?
虽然提示和输出解析方面的调整提高了可靠性,但还有一些增强功能可以进一步实施
- 提供更灵活的默认评分标准,并以可靠的提示来解释每个等级。
- 进一步研究在提示中使用少样本示例的影响。
- 将函数调用合并到 GPT-3.5 模型中,以生成更可靠的结果