TLDR; 今天我们发布了 OpenGPTs 中的两个“人机回路”功能,中断和授权,均由 LangGraph 提供支持。
我们最近发布了 LangGraph,一个帮助开发者构建多角色、多步骤、有状态的 LLM 应用程序的库。这句话包含了很多词,让我们逐一分解。
多角色

一个专家团队可以共同构建一些他们任何一个人都无法单独构建的东西。LLM 应用程序也是如此:LLM(擅长答案生成和任务规划)与搜索引擎(最擅长查找当前事实)配对时会更加强大。我们已经看到人们通过新颖的方式结合这两个(以及其他)构建块,构建了一些令人惊叹的应用程序,例如 perplexity 或 arc search。
正如人类团队比一个人单独工作需要更多的协调一样,具有多个角色的应用程序也需要一个协调层来
- 定义涉及的角色(图中的节点)以及他们如何相互移交工作(图中的边)
- 在适当的时间安排每个角色的执行,如果需要并行执行,并获得确定性的结果
多步骤
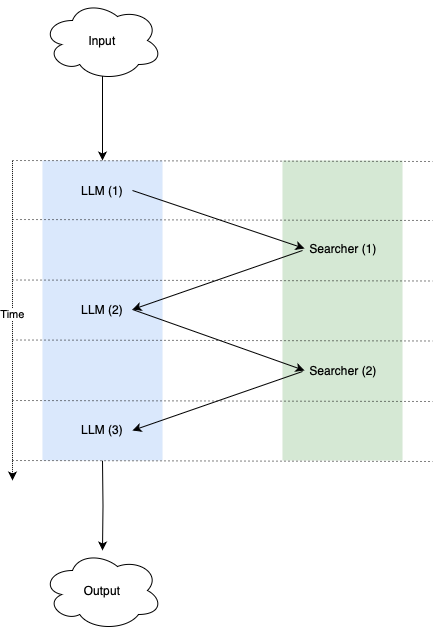
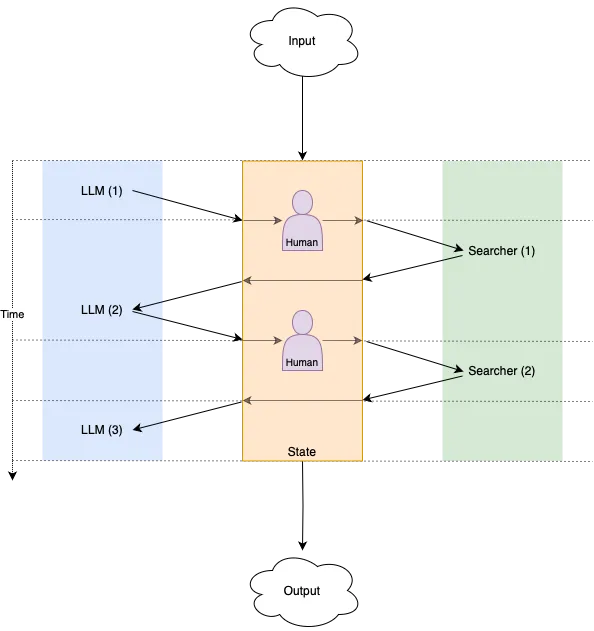
当每个角色将工作移交给另一个角色时(例如,LLM 提示向搜索工具请求关于查询的结果),我们需要理解多个角色之间来回交互的意义——它以什么顺序发生,每个角色被调用多少次等等。为了做到这一点,我们可以将角色之间的交互建模为跨多个离散步骤发生,当一个角色将工作移交给另一个角色时,这会导致安排计算的下一步,依此类推,直到没有更多的角色将工作移交给其他角色,并且我们已经达到了最终结果。
有状态
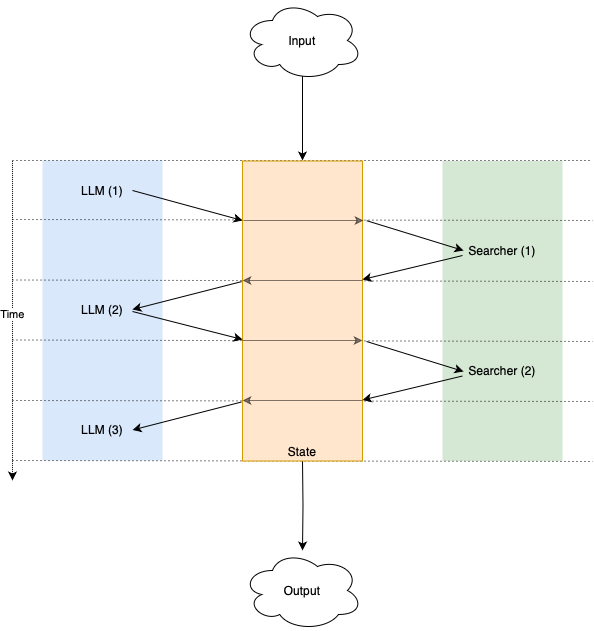
跨步骤的通信意味着状态的更新,否则当您第二次调用 LLM 角色时,您将获得与第一次相同的结果。事实证明,将这种状态从每个角色中提取出来非常有用,以便所有角色协同工作以更新单个中心状态。通过单个中心状态,我们还可以轻松地在每次计算期间或之后对其进行快照和存储。
人机回路
单个共享状态使过程更容易观察、中断和修改。这对于复杂的 LLM 应用程序非常重要,在这些应用程序中,一定程度的人工监督/批准/编辑可能是玩具和在现实世界中有用的部署之间的区别。我们正在 OpenGPTs 中引入对两种形式的人机回路的支持,由 LangGraph 提供支持——中断和授权。
中断

第一种模式,中断,是最简单的控制形式——用户正在查看应用程序生成的流式输出,并在他认为合适时手动中断它。状态保存在用户按下中断按钮之前的最后一个完整步骤。从那里,用户可以选择
- 从该点继续,计算将继续进行,就像没有被中断一样,或者
- 向应用程序发送新的输入(例如,聊天机器人中的新消息),这将取消任何待处理的未来步骤,并开始处理新的输入,或者
- 什么都不做,也不会运行任何其他操作。
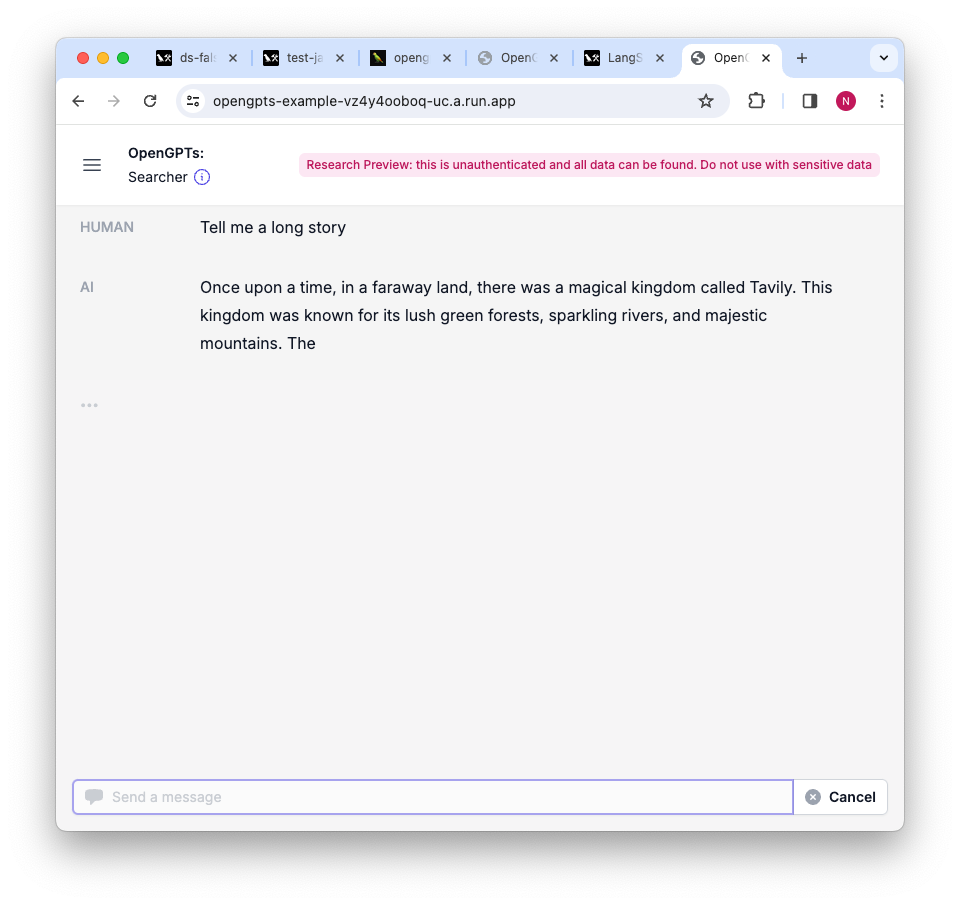
授权
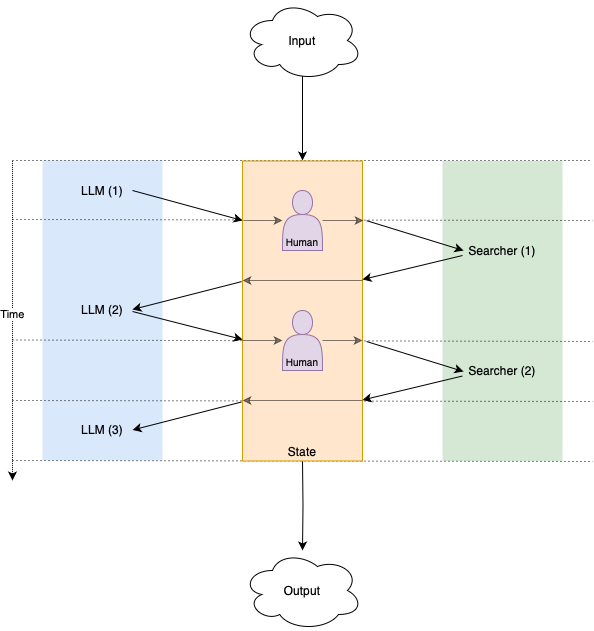
第二种控制模式是授权,用户提前定义他们希望应用程序在每次即将调用特定角色时将控制权移交给他们。在 OpenGPTs 中,我们为工具确认实现了这种模式——当此模式开启时,在调用任何工具之前,应用程序将暂停并请求确认,此时用户可以再次
- 恢复计算,接受工具调用
- 发送新消息以引导机器人朝不同的方向发展,在这种情况下,工具将不会被调用
- 或者,什么都不做。

在哪里找到它
您可以点击这里演示 OpenGPTs,点击这里 fork 它。
您可以在这里找到一个示例笔记本,用于构建您自己的带有“人机回路”控制的 LangGraph 应用程序。