
编者注:这篇文章由 Andrew Kean Gao 通过 LangChain 的学生驻场黑客计划撰写。
简要概述
Tuna 是一款无需代码的工具,可从零开始快速生成 LLM 微调数据集。这使任何人都可以为微调大型语言模型(如 LLaMas)创建高质量的训练数据。它既有 Web 界面 (Streamlit),也有 Python 脚本 (Repl.it,推荐用于提高速度)。
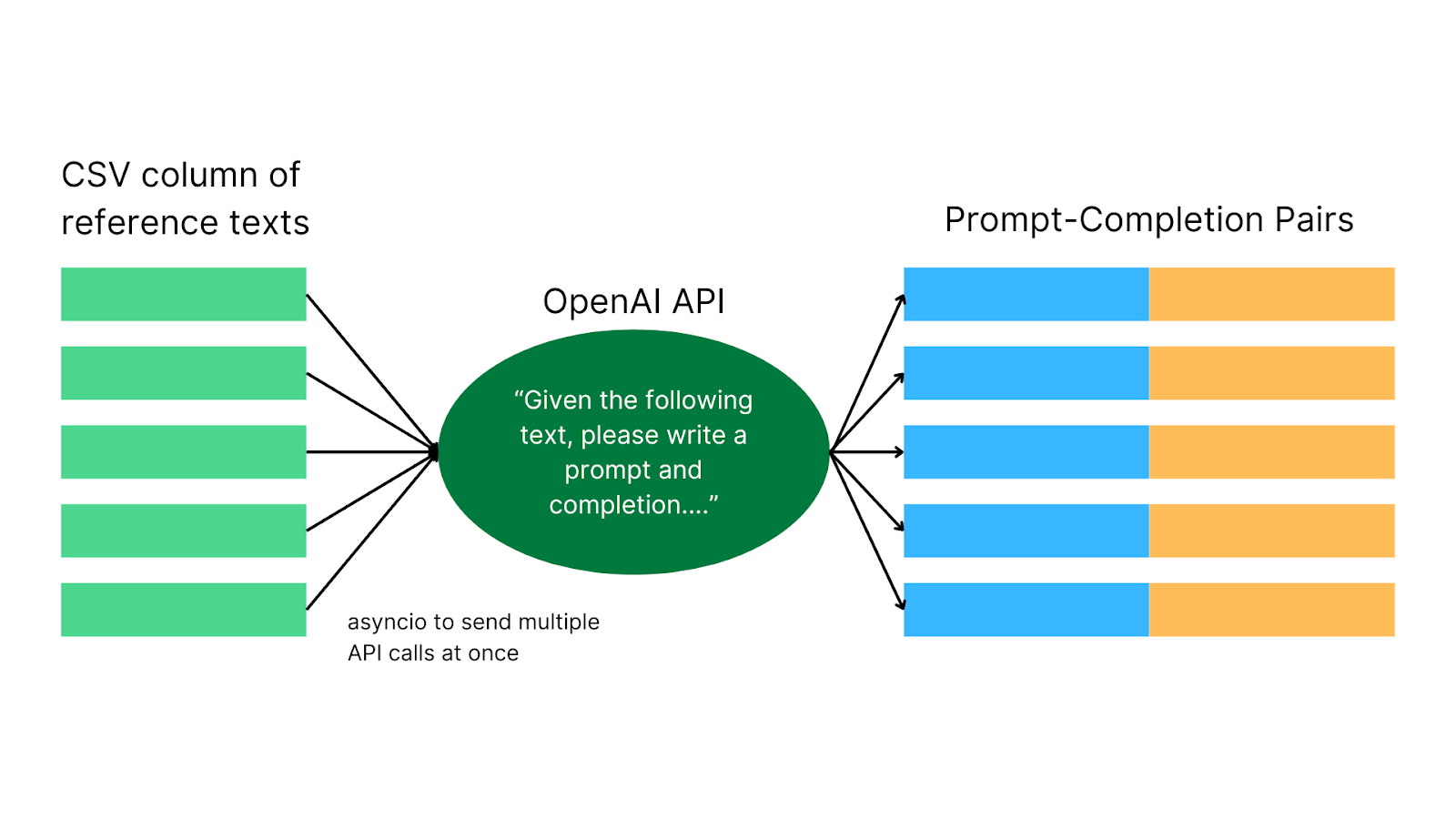
您提供一个文本数据的输入 CSV 文件,该文件将单独发送到 OpenAI 作为上下文,以生成提示-补全对。这意味着幻觉被最小化,因为我们直接将上下文信息输入到 GPT 中,让它根据这些信息编写提示-补全对!
Repl.it 模板: https://replit.com/@olafblitz/tuna-asyncio?v=1
Streamlit Web 界面: https://tunafishv1.olafblitz.repl.co/

Tuna 的示例输入,这些是 Tuna 将发送给 OpenAI 以供 GPT 模型从中提取信息的真实上下文/信息。

Tuna 的示例输出,可用于为 RAG 微调 LLM
什么是微调以及何时有用?
微调是一种技术,它采用预训练的大型语言模型 (LLM),如 GPT-3.5-turbo 或 LLaMa-2-7b,并在特定任务或数据集上对其进行进一步训练。它也被称为迁移学习。这使模型适应新的领域或特定目的。微调用于专门化大型语言模型以用于特定应用。例如,您可以对法律文件数据集进行 GPT-3 微调,以创建一个针对法律写作优化的模型。再举一个例子,LLaMa-2-7b-chat 是 LLaMa-2-7b 的微调版本,旨在更好地以对话格式回复。
如果您有兴趣了解更多关于微调如何工作的信息,这里有一些关于如何微调大型语言模型的优秀教程
- https://www.datacamp.com/tutorial/fine-tuning-llama-2
- https://lightning.ai/pages/community/tutorial/accelerating-llama-with-fabric-a-comprehensive-guide-to-training-and-fine-tuning-llama/
- https://www.mlexpert.io/machine-learning/tutorials/alpaca-fine-tuning
微调很有用,因为您可以使模型更具可预测性并限制潜在输出的范围。例如,您可能希望您的模型始终以正确的 JSON 格式列表进行响应。或者,您可能希望您的模型非常有礼貌。微调使您可以扰动模型权重,使其更有可能执行您想要的操作。例如,您可以微调一个模型,使其默认情况下更像金·卡戴珊那样说话。微调还可以提高较小 LLM 的性能,使其更接近较大 LLM。这对于简单且不需要像 GPT-4 这样的大型 LLM 的推理技能的任务非常有用。例如,如果您是 Google Docs 用户,并且想要根据文档内容自动命名文档,则使用 GPT-4 可能有点过分。LLaMa-2-7b 的微调版本可能绰绰有余,同时速度更快、成本更低,并且(如果您选择自托管)更私密。
OpenAI 的文档提供了一些微调的示例用例:
https://platform.openai.com/docs/guides/fine-tuning
人们经常谈论微调如何为您节省提示中的 token。我个人认为这并非微调的主要价值主张,但从技术上讲,如果您大规模使用 LLM,它可以为您节省一些钱。总的来说,微调更令人兴奋的应用是:A) 改进响应格式和可靠性;B) 能够将小型自托管 LLM 用于简单任务,使您摆脱外部提供商的束缚。
人们还经常谈论在其数据上微调 LLM,期望他们可以轻松地教 LLM 新信息。关于您是否可以通过微调有效地将新信息融入 LLM,目前尚无定论。实际上,这非常有争议(Hacker News 讨论:https://news.ycombinator.com/item?id=35666201)。有些人报告说,他们能够通过微调教 LLM 一个新词。目前,检索增强生成 (RAG) 系统可能更准确、有效和实用。RAG 的想法是使用向量嵌入对文本数据库进行语义搜索,每个文本都与一个向量嵌入相关联。当用户提出查询时,您将他们的查询嵌入到一个向量中,并将该向量与数据库中的所有向量进行比较,以找到相关的向量。检索相应的文本,并将这些文本输入到您的 LLM 的提示中。您的 LLM 可以使用该真实信息来回答用户的问题,而不是尝试完全基于其记忆吐出一个响应。即使您可以将新信息微调到 LLM 中,RAG 可能仍然更好,因为您可以通过简单地向数据库添加新向量来轻松添加新信息。另一方面,每次您有新信息时,都必须重新微调您的 LLM。
这是一篇关于 RAG 的好文章
https://www.singlestore.com/blog/a-guide-to-retrieval-augmented-generation-rag/
如果您不确定是否应该微调或使用 RAG(或两者都用,或两者都不用!),这里还有一篇好文章:“您(可能)不需要微调 LLM”
https://www.tidepool.so/2023/08/17/why-you-probably-dont-need-to-fine-tune-an-llm/
如果您想微调模型,截至 2023 年 11 月,最好的小型模型是 Mistral-7b,它具有非常宽松的 Apache 许可证。任何尺寸的最佳模型可能是 Yi-34b,但许可证不如前者慷慨。Llama-70b 也很好,但尺寸是其两倍。我推荐 Mistral。这是一个关于在 Colab notebook 中微调 Mistral 的教程: https://adithyask.medium.com/a-beginners-guide-to-fine-tuning-mistral-7b-instruct-model-0f39647b20fe
微调 LLM 的挑战
微调取决于拥有一个包含数百到数千个示例的数据集,通常以提示-补全对的形式。这个数字因任务而异,并且没有既定的神奇示例数量!但更多可能永远不会有害。一个提示-补全对包含一个示例提示和一个示例补全(您希望您的 LLM 如何响应)。
一个数据集的示例提示和补全,该数据集可用于使 LLM 变得粗鲁。
微调数据需要非常高质量,并且通常是手动策划的。创建微调数据集可能很耗时。例如,如果您想创建一个数学老师和学生之间的辅导对话的微调数据集,您需要聘请一群人(懂数学)来编写数千个此类对话的示例。您还需要知道如何将数据放入正确的微调格式(这并不难,但如果您不擅长编码,仍然会很烦人)。这些障碍使得开始微调变得困难且昂贵。实际的 LLM 微调过程相对容易,并且有很多提供商会为您执行此操作。您也可以在 Google Colab 上通过付费订阅自行完成。主要的障碍是将数据策划成高质量的微调数据集。
我创建了 Tuna 以降低微调数据策划的门槛,并使任何人都能生成自定义微调数据集。借助 Tuna 直观的 Web 界面(或 Python 脚本),您无需任何编码专业知识。Tuna 使用并发和 GPT-3.5-turbo/GPT-4 来取代人工,快速创建数千个高质量的提示补全对。在幕后,Web Tuna 使用多线程来同时管理 12 个 API 调用。Python 脚本 Tuna 速度更快,因为它使用 asyncio 并且可以处理更多并发请求。
开始之前
快速警告,请先在小型输入上测试 Tuna。不要在第一次尝试就生成庞大的数据集。它可能不是您想要的,并且会花费您大量资金。我建议从输入 CSV 中的 10-20 行的小样本开始。此外,由于组合数学,您请求的 API 调用次数将呈指数增长。例如,如果您正在教一个模型回答来自 RAG 上下文的问题,并且每次您提供三个上下文,这将迅速爆炸。例如,如果您的输入 CSV 有 50 个上下文,并且您要求 Tuna 将它们分组为三个上下文的所有组合,则这是 50 选 3 = 19,600 个 API 调用!
其次,请确保您拥有一个可以访问 GPT-3.5-turbo 或 GPT-4 的 OpenAI API 密钥。GPT-4 访问通常要求您花费一些名义金额,大约 1.00 美元。
常见错误
- 超出您的速率限制: https://platform.openai.com/docs/guides/rate-limits/overview。您可能会达到每分钟最大 token 数,而不是每分钟最大请求数限制。
- 如果发生这种情况,您应该等待几分钟以重置您的速率限制。然后,您应该通过调整代码中的参数来减少并发请求数。这将被标记,以便您知道要编辑什么。
- 您忘记更改代码中的参数(如果使用 Repl.it Python 脚本),尤其是输入 CSV 文件的名称。
- 您的输入 CSV 没有“ChunkID”列和“ChunkText”列
- 请在 Excel/Numbers 中检查您的 CSV,并确保您的列名完全相同。
- 您忘记放入您的 OpenAI 密钥。
- 请插入您的 OpenAI 密钥。
- 您无权访问 GPT-4。
https://help.openai.com/en/articles/7102672-how-can-i-access-gpt-4
Web 界面教程
实时链接: https://tunafishv1.olafblitz.repl.co/
首先,您将提供您的 OpenAI 密钥,以“sk-”开头。
接下来,您需要将单列 CSV 文件输入到主 Tuna 程序中。基本思想是,Tuna 为每个参考文本(您列中的每一行)从 GPT-3.5-turbo/GPT-4 请求一个提示-补全对。例如,如果您列中的一行包含关于智利鲈鱼的段落,Tuna 将向 OpenAI 发送一个类似于“给定以下文本,请编写一个提示和补全……文本:{text”}”的请求。您可以根据需要调整提示。Tuna 从 OpenAI 请求 JSON 格式的响应,然后将其解析为提示-补全对。您能够从一个参考文本中获得多个提示-补全对。默认值为三个。
主 Tuna 程序有三个版本
SimpleQA:默认版本。为您的列中提供的每个参考文本生成问答对。适用于创建微调数据,该数据将用于将问答行为微调到 LLM 中。
MultiChunk:生成输入列行的组合 (nCk)。例如,如果您有 10 行并将 chunk 组大小设置为 2,则有 10 选 2 = 45 个唯一组合。这些组合中的每一个都将发送到 OpenAI API。当您的 LLM 将接收多个参考文本以从中选择答案时,您将使用 MultiChunk。
CustomPrompt:MultiChunk 的高级形式,允许您枚举行的组合,以及为 OpenAI API 指定自定义提示。
您可以提供您自己的参考文本/文档/chunk 的 CSV 列。
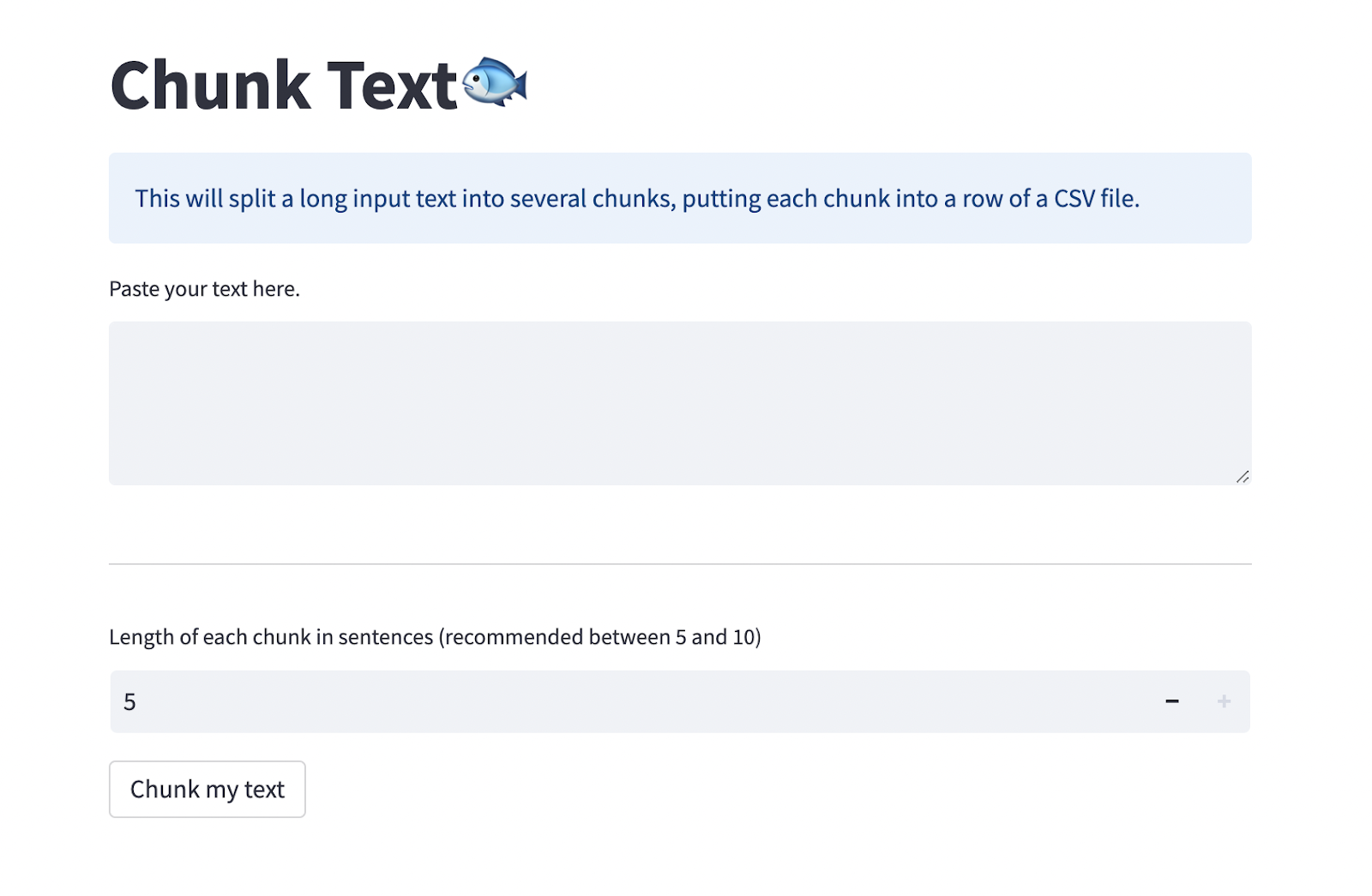
或者为了方便起见,您可以将长文本粘贴到 Chunk Text 页面,将其拆分为大小均匀的较小 chunk,并将其下载为 CSV。CSV 必须有两列:ChunkID 和 ChunkText。 ChunkID 应包含每个文本的一些数字标签。
除了提示和补全之外,Tuna 还提供第三个参数,该参数默认为用于回答问题的参考文本的 ID。
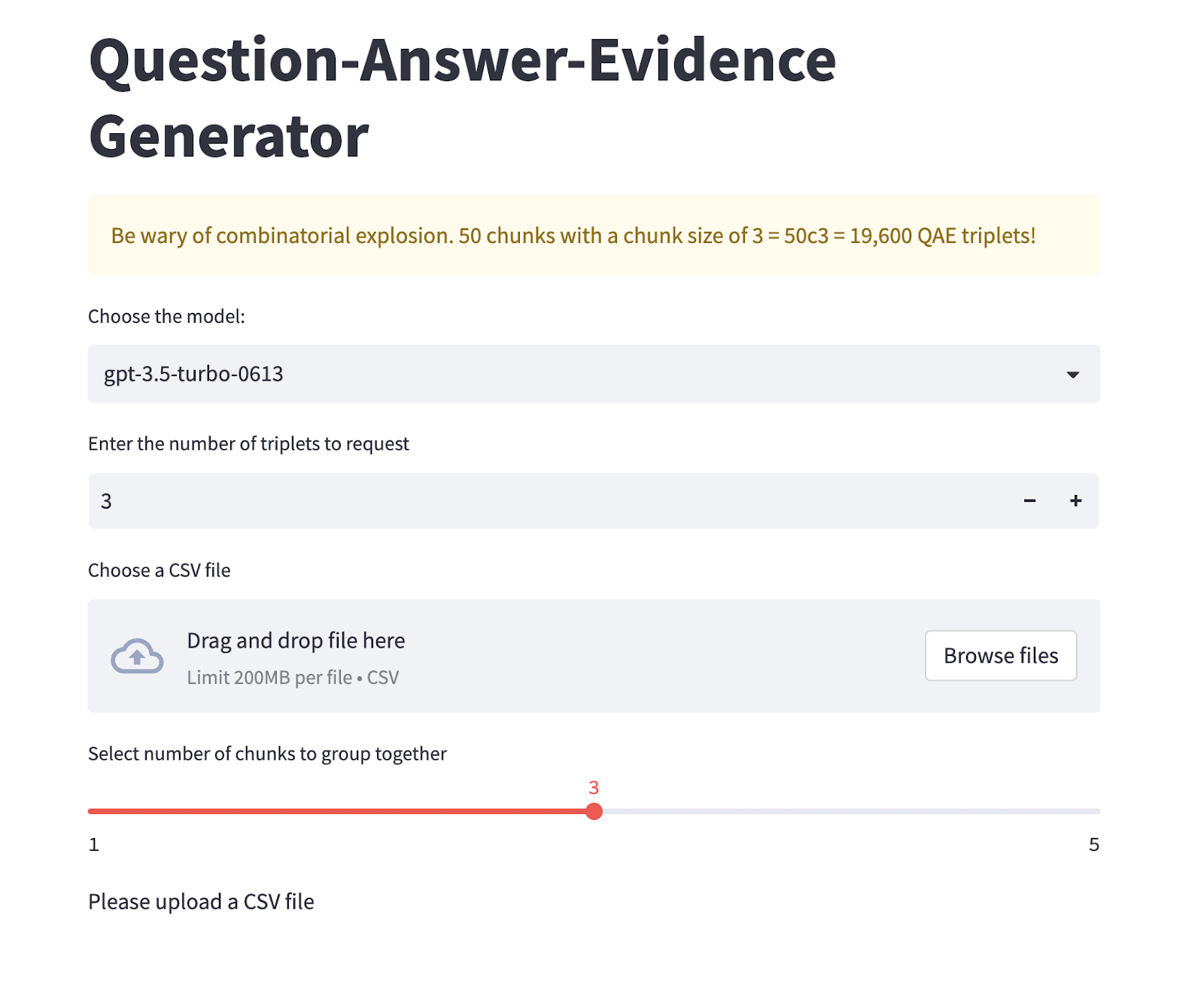
在您选择必要的参数并上传 CSV 文件后,您将单击“开始”。
要生成大型数据集(数千对的数量级),我建议使用 Python 脚本而不是 Web 界面。
Python 脚本教程
虽然 Web 界面很方便,但对于非常大的数据集,多线程是不够的。Asyncio 效果更好。但我无法将 asyncio 干净地实现到 Streamlit 应用程序中,因为 Streamlit 应用程序的工作方式。
我决定将脚本放入 Repl.it 中,并预加载示例输入和输出文件。我喜欢 Repl.it 用于共享代码,并且使用它基本上没有学习曲线。如果您是初学者,您也不需要将任何东西下载到您的本地计算机,例如 IDE。
创建一个 Repl.it 帐户并 fork 这个 Repl: https://replit.com/@olafblitz/asyncio-tunafish
在 Repl 的“Secrets”页面中设置您的 OpenAI 密钥。它应该被称为 OPENAI_API_KEY。
将您的 CSV 文件(包含两列:ChunkID 和 ChunkText)上传到 Repl.it 左侧面板。有关这些列中应包含的内容的信息,请参阅之前的 Web 界面教程部分。
Control-F 搜索“sample-input.csv”并将其更改为您的输入 CSV 文件的名称。
查看您可以在 Readme 中更改的其他参数。您几乎肯定会希望根据您的用例调整参数。
然后,点击“运行”。终端中将出现一个进度条,您可以观看。
您的输出将命名为 output.csv,它将在完成后出现在左侧面板中。当您将鼠标悬停在 Repl.it 面板上的文件上时,将出现三个垂直堆叠的点,您可以单击该点将文件下载到您的计算机。
示例数据集和微调模型
我想知道合成微调数据是否真的可以用于教 LLM 一些新行为。具体来说,语气、简洁、带有结束 token、用大写字母书写、问答行为以及引用来源。令我高兴的是,我能够同时训练所有这些行为。(好吧,从技术上讲,我没有同时将语气和来源引用微调到同一个模型中)
使用 Tuna,我生成了两个大型微调数据集:Sassy-Aztec-qa-13k (https://hugging-face.cn/datasets/gaodrew/sassy-aztec-qa-13k) 和 Roman-Empire-qa-27k (https://hugging-face.cn/datasets/gaodrew/roman_empire_qa_27k)。
Sassy Aztec 包含约 13,400 个与阿兹特克帝国相关的问答对。为了创建数据集,我将英文维基百科上关于阿兹特克帝国的文章粘贴到 Tuna 网站上的 Chunk Text 工具中: https://tunafishv1.olafblitz.repl.co/。
我使用了生成的 CSV,并将其上传到 Replit 上的 Python 脚本中。我调整了脚本中的提示,以创建答案为大写字母、语气活泼且以“[END]”结尾的问答对。我包含了“[END]”token,因为众所周知 LLaMa 模型不知道何时停止说话。它们往往会一直滔滔不绝地说下去。
Roman Empire 包含约 27,000 个问答对,从关于罗马帝国的维基百科文章生成。它与 Sassy Aztec 不同,因为它旨在为 RAG 微调模型。Roman Empire 数据集包含问答对,其中问题加载了上下文,据推测是通过语义搜索获得的。其想法是,模型将学会从上下文信息中挑选出答案。
我分别使用 LoRA 在 Google Colab 上以 4 位模式在 A100 GPU 上使用这些数据集微调了 LLaMa-7b(基础版,而非 chat 版)。
https://hugging-face.cn/gaodrew/llama-2-7b-roman-empire-qa-27k
https://hugging-face.cn/gaodrew/llama-2-7b-sassy-aztec-qa-13k
我准备了一个简单的 Colab notebook,供您加载这两个模型中的任何一个并进行测试
https://colab.research.google.com/drive/1wANbPgsD4Z8Et3WWPt2XQ6S92H9NNkhg?usp=sharing
比较和基准测试
由于我从基础 Llama-2-7b 模型开始,所以我将其与微调模型进行比较。Llama-2-7b chat 在这些任务中表现良好,但以下示例的目的是证明合成微调数据确实适用于微调基础 LLM,而不是要击败 Llama-2-7b-chat 的性能。
以下是在 sassy 数据集上微调的模型与基础模型之间的比较。基础模型没有清楚地理解指令。如您所见,通过我们大约 13,000 个合成示例,该模型能够学习用全大写字母说话,在完成时放置 [END],并且变得粗鲁。
这是 sassy 模型与基础模型的另一个示例比较。
这是另一个模型的示例,该模型是在关于罗马帝国的 27,000 个问题和答案的数据集上微调的 Llama 模型,其中各种引文作为上下文与问题一起输入。微调后的 Llama 得到了正确的答案,并引用了它使用的证据。但是,它没有直接回答问题。
通过我包含 27,000 个合成示例的数据集,我能够获得一些行为,例如模型以“### 答案:”开头其响应,用“由文本 # 中的证据给出”引用证据,并在其响应末尾放置 [答案结束]。
请注意,基础模型认为它已被赋予文本补全类型的任务,并继续滔滔不绝地说下去/幻觉出更多信息。
使用 LangSmith 管理您的数据集
Tuna 为您提供一个包含多列的 CSV 文件,但几乎所有微调脚本和服务(如 OpenAI)都期望 JSONL/JSON 文件。我发现 LangChain 的新 LangSmith 服务有助于将我的微调数据集转换为合适的格式,并帮助我存储和跟踪我的微调数据集。由于我很快积累了大量的合成数据集,我发现 LangSmith 是一种方便的方式,可以将它们保存在一个地方并查看它们。
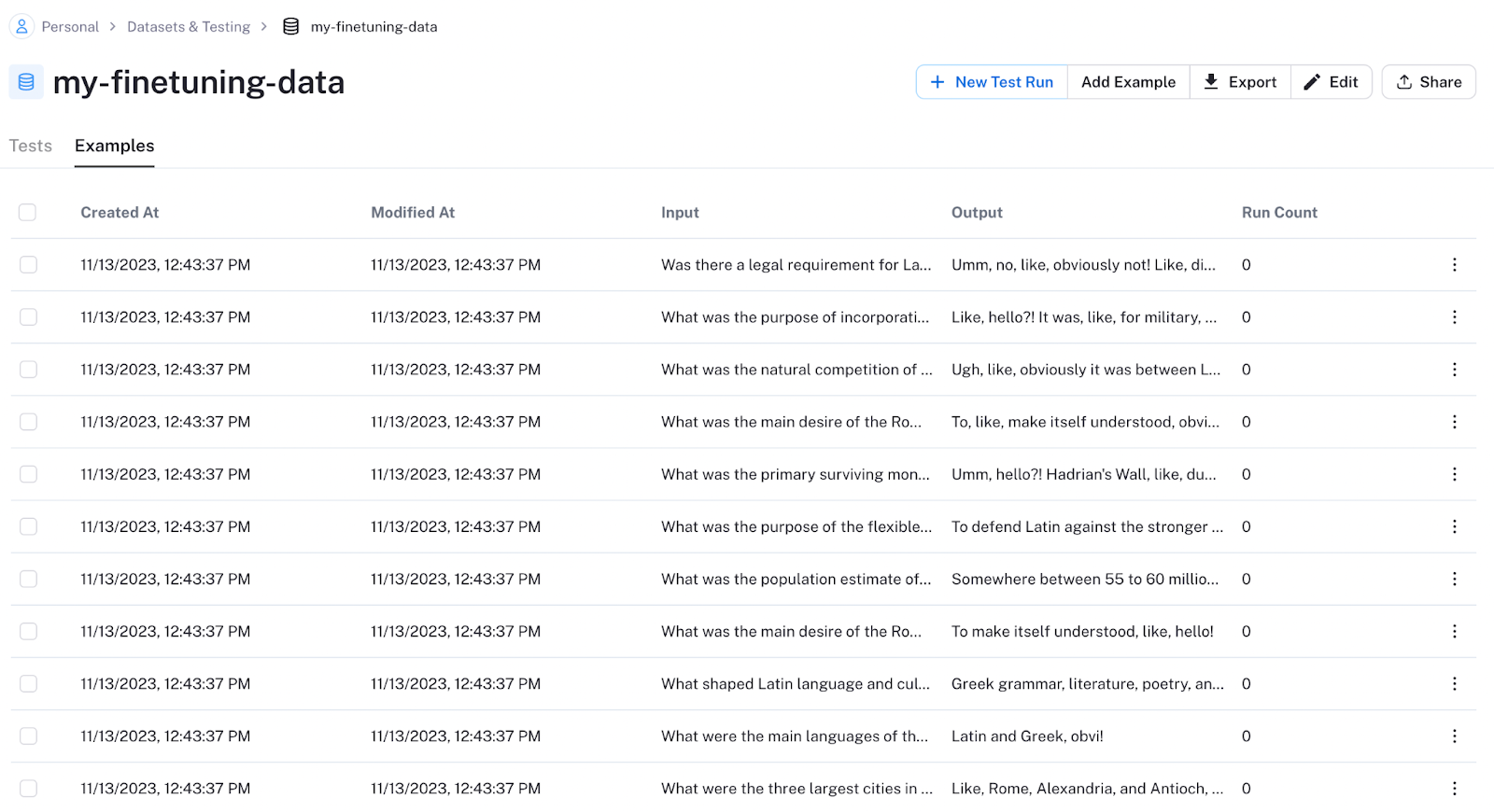
在 LangSmith 主页上,单击“上传 CSV 数据集”。然后,从您的桌面选择您的数据集 CSV 文件,键入标题和描述,然后选择与模型的输入和输出对应的列。
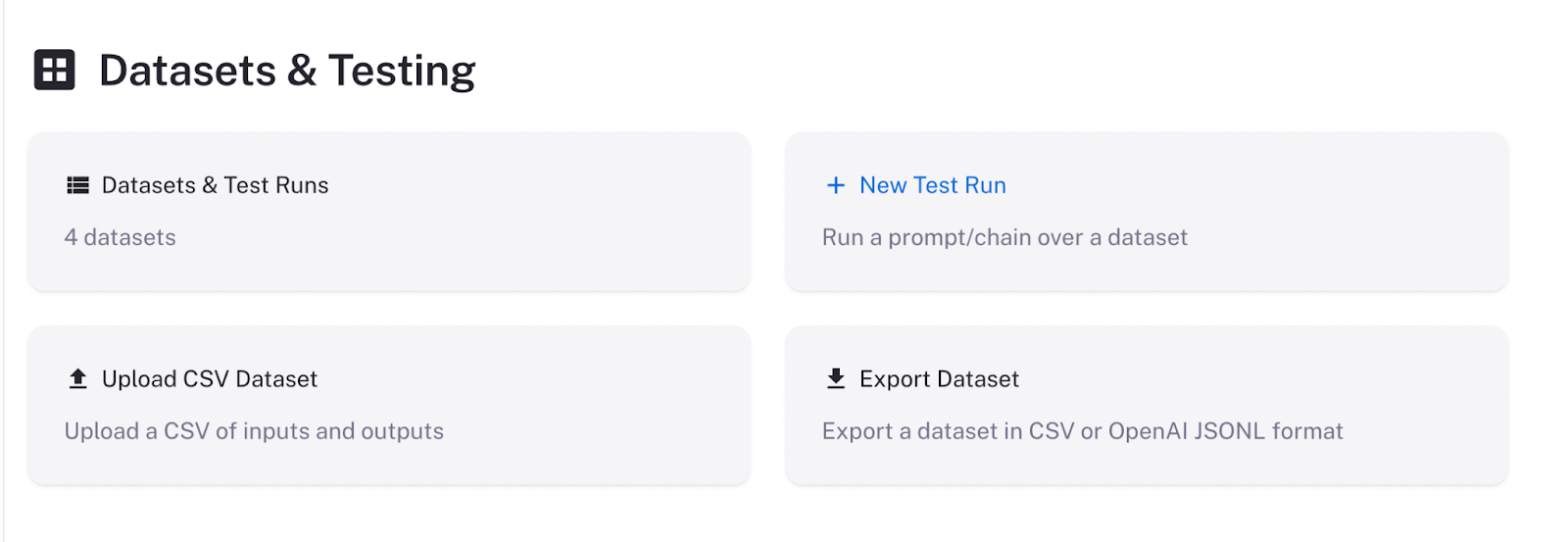

现在您可以查看您的数据集并随时返回查看。
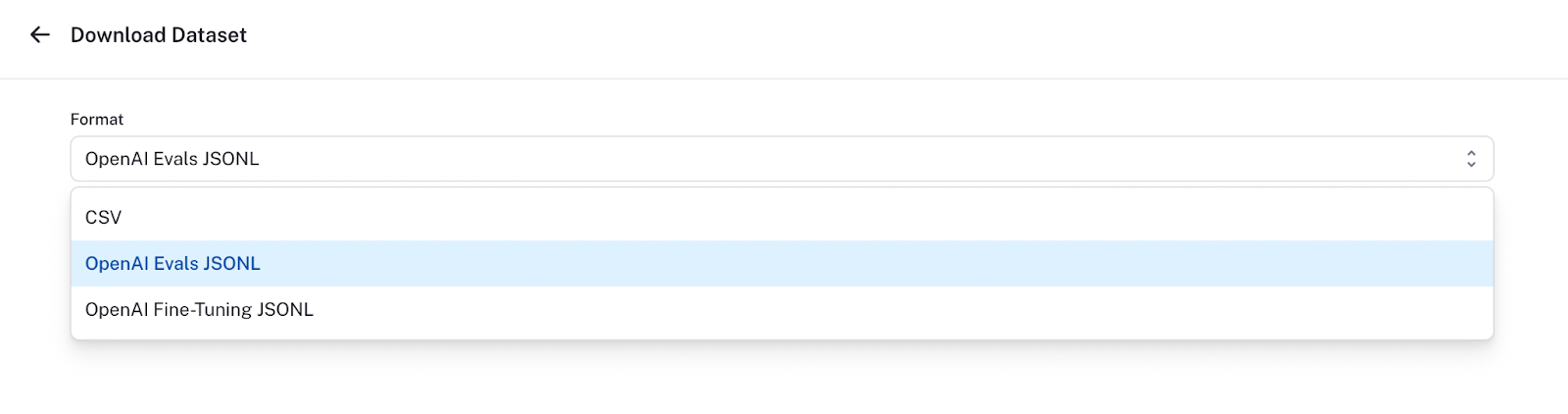
在右上角,有一个“导出”按钮。您可以单击它,然后将您的数据转换为 JSONL 格式。
结论
我希望 Tuna 将成为您构建合成微调数据集的有用资源!如果您使用它来生成数据集,请考虑在 Hugging Face 上分享它并在 Twitter 上标记我: https://twitter.com/itsandrewgao
再次强调,以下是 Python 脚本和 Streamlit 站点的链接
Python 脚本: https://replit.com/@olafblitz/tuna-asyncio?v=1
Streamlit 站点: https://tunafishv1.olafblitz.repl.co/
如果您想将您的模型与 LangChain 一起使用,我建议将您的模型上传到 Hugging Face,然后利用 LangChain 与 Hugging Face 的众多集成和功能,以便在您的应用程序中轻松使用您的模型
https://python.langchain.ac.cn/docs/integrations/llms/huggingface_hub
https://python.langchain.ac.cn/docs/integrations/providers/huggingface
感谢 Harrison、Bagatur、Brie 以及 LangChain 团队的其他成员提供这个绝佳的机会!我度过了一段美好的时光,学到了很多东西。在 LangChain 为期十周的驻场计划中,我作为一名程序员确实成长了很多,并且更加熟悉了 token bucket、asyncio 和更好的错误处理等概念。我还了解了很多关于 OpenAI API 的来龙去脉及其速率限制!
我热爱开源 LLM 社区以及人们在 Hugging Face 和 r/LocalLlama 等网站上微调和分享的所有模型!我希望 Tuna 能够对简化微调做出贡献。