编者按:以下是 Dosu 首席执行官 Devin Stein 的客座博客文章,Dosu。Dosu 是一位工程团队成员,帮助您开发、维护和支持软件。
众所周知,构建生产级 LLM 产品非常困难。可靠性是任何产品成功的关键,但是当您的产品以一系列概率函数为基础时,确保可靠性绝非易事。
在 Dosu,我们不断迭代我们的产品。对于我们所做的每一项更改,我们都需要了解它对最终用户的影响。评估驱动开发 (EDD) 使我们能够充满信心地交付产品。在过去的几个月中,LangSmith 使我们能够扩展 EDD,使我们能够轻松监控和搜索 Dosu 的活动。
什么是 Dosu?
如果您在 LangChain GitHub 存储库上花费过任何时间,您可能已经见过 Dosu,一位 AI 队友,帮助开发、维护和支持软件项目。
Dosu 诞生于我担任开源软件维护者的经历,这是一个有益但众所周知非常耗时的角色。随着我的 OSS 项目越来越受欢迎,我发现自己花费更多的时间在提供支持而不是开发新功能上。
对于维护者来说,这种责任经常 导致倦怠,并促使一些人 宣布 issue 破产,这个过程包括简单地关闭所有未解决的 issue 和 PR。OSS 社区也因此受到影响,因为人们经常等待数天、数周甚至数月才能得到维护者的回复。
这种现象并非开源独有。在行业内,高达 85% 的开发人员时间 花费在非编码任务上,例如回答临时问题、分类 issue 和处理管理事务。
Dosu 将这些任务从开发人员的工作中解放出来,让他们可以做自己喜欢的事情:保持流畅、编码和交付出色的功能。与此同时,Dosu 也是 OSS 社区的资源,每当社区成员遇到意外问题或有只有代码才能回答的新颖问题时,Dosu 都会立即提供反馈。
早期
Dosu 于 2023 年 6 月下旬推出。那时,我们的量很小,足以让我们检查每一个响应。每天,仅凭 grep 和 print 语句,我们就仔细梳理日志,以找出需要改进的领域。
这项工作非常辛苦,但对于设计和开发 Dosu 的架构非常重要。它帮助我们的团队深入了解人们如何尝试使用 Dosu,它擅长处理哪些类型的请求,以及哪些类型的请求它有所欠缺。
一旦我们知道我们需要改进什么,问题是如何改进它。与传统的代码更新不同,更改 LLM 逻辑并非易事。很难知道一个小小的更改会对整体性能产生什么影响。很多时候,我们看到对提示的细微调整在一个领域产生了更好的结果,但在另一个领域却导致了倒退。
我们需要一种衡量我们更改影响的方法。对于每一次更改,我们都希望确保我们正在
- 在表现良好的领域保持性能
- 在表现不佳的领域提高性能
正是在这些早期,我们转向评估驱动开发来衡量我们的进步。
评估驱动开发
评估驱动开发 (EDD) 就像测试驱动开发一样,为我们提供了针对其进行开发的最终目标。评估 — 或“evals” — 是我们理解更新和新功能的基准。EDD 帮助我们了解我们对 Dosu 的核心逻辑、模型或提示所做的任何更改的影响。
通过 EDD,我们有了一个完善的改进 Dosu 的流程
- 使用少量初始评估创建新行为
- 向用户发布新行为
- 监控生产环境中的结果并识别失败模式
- 为离线评估中的每个失败模式添加示例
- 迭代更新后的评估以提高性能
- 重新发布并重复
当 Dosu 刚开始时,这种开发工作流程对我们来说效果很好,但随着我们的使用量增长,跟上 Dosu 的活动变得困难。
在大规模情况下保持高品质标准
今天,Dosu 已安装在数千个存储库中,并且在一天中的所有时间生成响应。我们构建了数十个子模块来智能地处理不同类型的场景,并且随着模型和该领域的研究不断发展,我们不断迭代我们的问题解决方法。
虽然 Dosu 的增长令人兴奋,但也带来了挑战。Dosu 活动的增加使得几乎不可能监控响应并识别生产环境中的失败模式,这对于我们的 EDD 工作流程至关重要。
我们决定是时候升级我们的 LLM 监控堆栈了。我们寻找一种工具,它不仅可以帮助我们监控 Dosu 的活动,而且足够灵活以适应我们现有的工作流程。我们的一些标准包括
- 提示必须存在于 Git 中 — 本着 EDD 的精神,我们将提示视为代码。对提示的任何更改都必须按照与代码更改相同的标准进行处理。
- 代码级追踪 — Dosu 不仅仅是一系列 LLM 请求。我们希望在单个追踪中跟踪 LLM 请求之间的元数据。
- 易于导出数据 — 我们有现有的评估数据集和工具,我们希望保留它们。
- 可自定义和可扩展 - LLM 领域正在快速发展。没有构建 LLM 应用程序的标准方法。我们希望控制跟踪哪些元数据,并能够定制工具以满足我们的需求。
我们探索了 LLM 监控和评估领域,试图找到一种满足我们要求的产品。在与 LangChain 团队(我们的早期合作伙伴之一)通话后,我们很高兴听到 LangSmith 似乎满足所有条件。
通过 SDK 实施 LangSmith
LangSmith 最让我们兴奋的不是其时尚的 UI 或广泛的功能集,而是它的 SDK。LangSmith SDK 为我们提供了我们正在寻找的精细控制和可定制性。
为了试用 LangSmith,我们只需将 @traceable 装饰器添加到我们的一些 LLM 相关函数中。我们只花了数分钟进行检测,并且在将这些更改推送到生产环境后,我们立即看到追踪信息涌入 LangSmith UI。

@traceable 装饰器一个出乎意料的绝妙功能是它可以将函数和 LLM 调用追踪发送到 LangSmith。这使我们可以在 LangSmith UI 中的单个追踪中查看原始函数输入、渲染的提示模板和 LLM 输出。
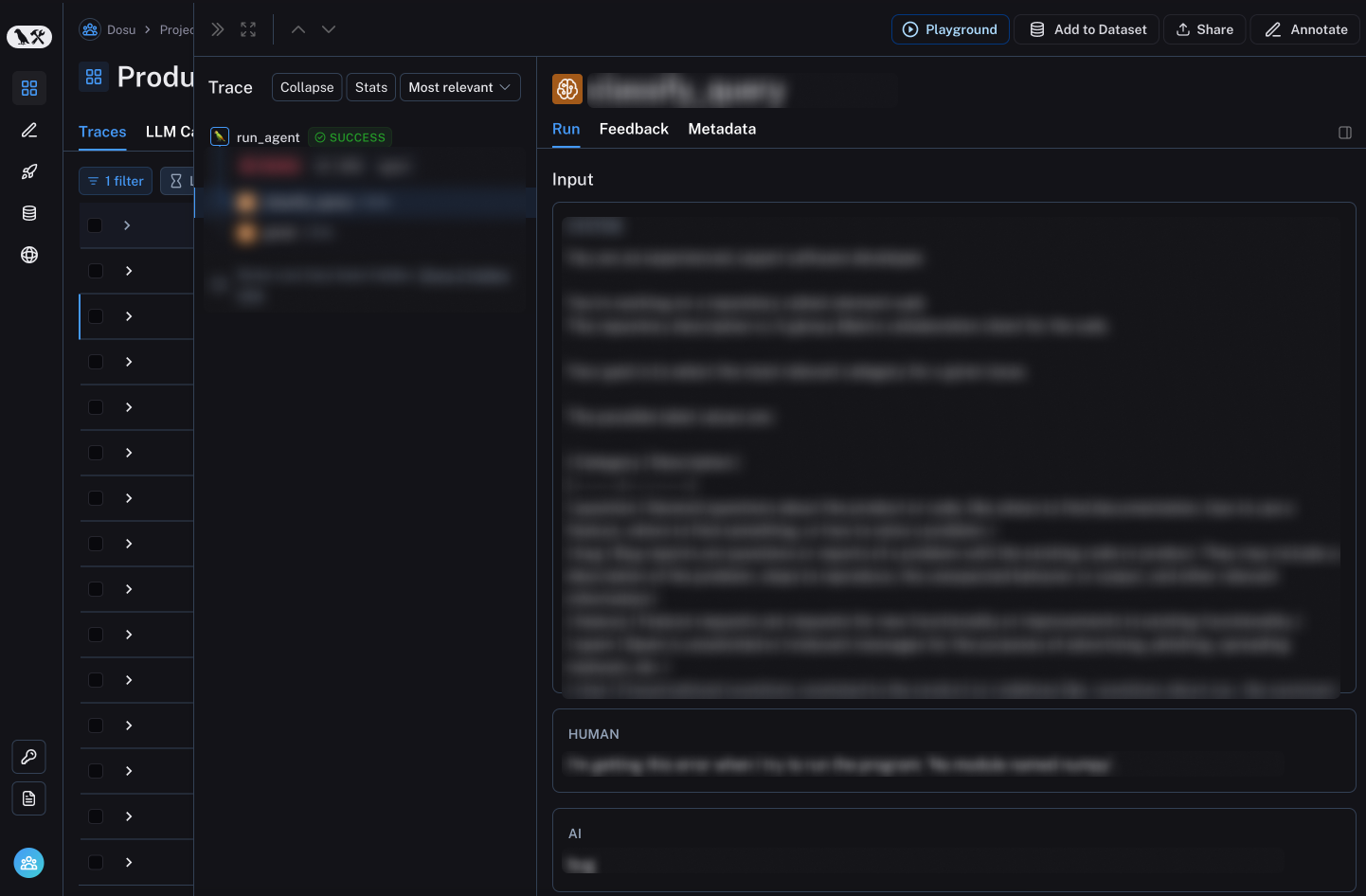
开箱即用,LangSmith 让我们能够了解 Dosu 的所有活动。下一步是利用 LangSmith 来识别失败模式并将其集成到我们的 EDD 工作流程中。
查找失败
Dosu 收到来自用户的无数请求 — 从关于代码库的简单问题,到从升级到新库版本产生的错误追踪,到询问功能的状态。Dosu 可能的输入越多,意味着可能的失败模式就越多。
当尝试识别失败模式或 Dosu 处理不好的请求时,我们有多种信号可以寻找,例如
- 显式反馈:ChatGPT 普及的经典点赞/踩踏反馈。
- 用户情绪:当用户在 GitHub issue 上与 Dosu 互动时,他们的回复通常会显示 Dosu 是否有帮助
- 内部错误:LLM 可能因多种原因而失败。输入或输出是否太大?生成的响应是否与所需的模式不匹配?
- 响应时间:在 Dosu,我们优先考虑质量而不是速度;但是,了解响应速度慢的原因很重要。有些请求需要快速响应,而另一些请求则需要较慢但更精确的响应。
LangSmith 的高级搜索功能使识别异常行为变得容易。我们可以使用一系列标准执行搜索,包括:显式用户反馈、最近的错误事件、响应时间延迟或负面情绪。LangSmith 还允许我们将其他元数据附加到每个追踪,以进一步扩展其搜索功能。
我们已经识别出许多意想不到的失败模式。例如,我们发现当用户共享数千行日志或 OpenAI 嵌入的原始浮点值时,响应速度非常慢的模式。
我们团队最喜欢的失败之一发生在 Dosu 被要求标记拉取请求时。Dosu 没有标记拉取请求,而是决定告诉用户它很高兴今晚去听音乐会。关于 Dosu 是否是 Swiftie,目前还没有定论。

一旦我们找到失败模式,EDD 工作流程与以前相同。
- 我们在 LangSmith 中搜索更多示例
- 将它们添加到我们的评估数据集
- 针对评估进行迭代
- 推送 Dosu 的新版本,然后重复。
自动化评估数据集收集
Dosu 的评估驱动开发的未来是光明的。我们的团队正在进一步定制 LangSmith,以允许我们从生产流量中自动构建评估数据集。我们希望 Dosu 的工程师可以尽可能简单地根据对话主题、用户细分、请求类别等来管理数据集。
Dosu 与 LangChain 的合作有一个有趣的飞轮效应。LangSmith 帮助我们更快地迭代以提高 Dosu 的性能。Dosu 的改进直接转化为减轻 LangChain 团队的维护和支持负担,使他们能够花费更多时间为 LangSmith 交付功能,这反过来又加快了 Dosu 的开发速度。这个过程就这样继续下去!
PS:Dosu 正在招聘!请通过 jobs*@dosu.dev* 联系