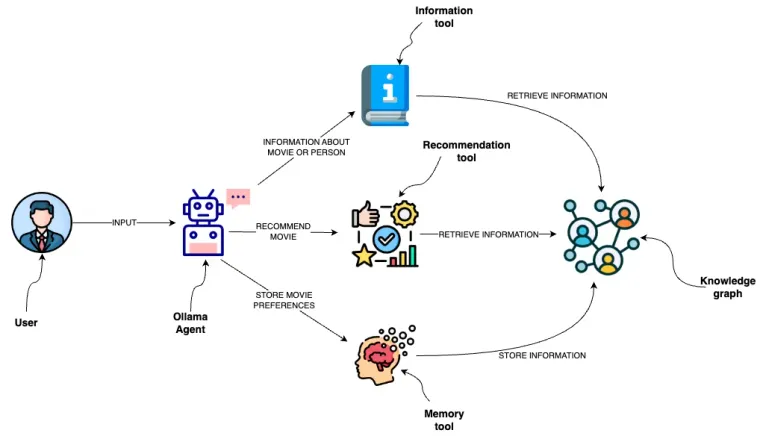
学习如何实现一个开源的 Mixtral 代理,该代理通过语义层与图数据库 Neo4j 交互
编者按:这篇文章由来自 Neo4j 的 Tomaz Bratanic 撰写
到现在,我们可能都已经认识到,通过为大型语言模型(LLM)提供额外的工具,我们可以显著增强它们的能力。例如,即使是 ChatGPT 也可以在付费版本中开箱即用地使用 Bing 搜索和 Python 解释器。OpenAI 更进一步,为工具使用提供了微调的 LLM 模型,您可以在提示词中将可用的工具传递给 API 端点。然后,LLM 决定是直接提供响应,还是应该首先使用任何可用的工具。请注意,这些工具不必仅用于检索额外信息;它们可以是任何东西,甚至允许 LLM 预订晚餐。我之前实现了一个项目,允许 LLM 通过一组预定义的工具与图数据库进行交互,我称之为语义层。

本质上,这些工具通过提供动态、实时的信息访问、通过记忆进行个性化以及通过知识图谱对关系进行复杂的理解,来增强像 GPT-4 这样的 LLM。它们共同使 LLM 能够提供更准确的推荐、随着时间的推移理解用户偏好,并访问更广泛的最新信息,从而带来更具互动性和适应性的用户体验。正如前面提到的,除了在查询时检索额外信息的能力外,它们还为 LLM 提供了一种影响其环境的选择,例如,在日历中预订会议。
虽然 OpenAI 已经用其微调的工具使用模型宠坏了我们,但现实情况是,大多数其他 LLM 在功能调用和工具使用方面都没有达到 OpenAI 的水平。我尝试了 Ollama 中可用的大多数模型,大多数模型在持续生成可以用来驱动代理的预定义结构化输出方面都很吃力。另一方面,有些模型是为功能调用而微调的。然而,这些模型对于功能调用有自定义的提示工程模式,这些模式要么没有详细的文档记录,要么除了功能调用之外不能用于其他任何事情。
最终,我决定遵循 LangChain 现有的基于 JSON 的代理实现,使用 Mixtral 8x7b LLM。我使用 Mixtral 8x7b 作为一个电影代理,通过语义层与原生图数据库 Neo4j 进行交互。 代码可以作为 Langchain 模板使用,也可以作为 Jupyter notebook 使用。如果您对工具的实现方式感兴趣,可以查看我之前的博文。在这里,我们将讨论如何实现一个基于 JSON 的 LLM 代理。
语义层中的工具
LangChain 文档中的示例(JSON 代理,HuggingFace 示例)使用的工具都只有一个字符串输入。由于语义层中的工具使用稍微复杂的输入,我不得不深入研究一下。这是一个推荐工具的示例输入。
all_genres = [
"Action",
"Adventure",
"Animation",
"Children",
"Comedy",
"Crime",
"Documentary",
"Drama",
"Fantasy",
"Film-Noir",
"Horror",
"IMAX",
"Musical",
"Mystery",
"Romance",
"Sci-Fi",
"Thriller",
"War",
"Western",
]
class RecommenderInput(BaseModel):
movie: Optional[str] = Field(description="movie used for recommendation")
genre: Optional[str] = Field(
description=(
"genre used for recommendation. Available options are:" f"{all_genres}"
)
)
推荐工具具有两个可选输入,电影和类型。此外,我们为类型参数使用了可用值的枚举。虽然输入不是很复杂,但它们仍然比单个字符串输入更高级,因此实现必须略有不同。
LLM 代理的基于 JSON 的提示词
在我的实现中,我大量借鉴了 LangChain hub 中现有的 hwchase17/react-json 提示词。该提示词使用以下系统消息。
Answer the following questions as best you can. You have access to the following tools:
{tools}
The way you use the tools is by specifying a json blob.
Specifically, this json should have a `action` key (with the name of the tool to use) and a `action_input` key (with the input to the tool going here).
The only values that should be in the "action" field are: {tool_names}
The $JSON_BLOB should only contain a SINGLE action, do NOT return a list of multiple actions. Here is an example of a valid $JSON_BLOB:
```
{{
"action": $TOOL_NAME,
"action_input": $INPUT
}}
```
ALWAYS use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action:
```
$JSON_BLOB
```
Observation: the result of the action
... (this Thought/Action/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin! Reminder to always use the exact characters `Final Answer` when responding.
提示词首先定义了可用的工具,我们稍后会介绍。提示词最重要的部分是指导 LLM 输出应该是什么样子。当 LLM 需要调用函数时,它应该使用以下 JSON 结构
{{
"action": $TOOL_NAME,
"action_input": $INPUT
}}
这就是为什么它被称为基于 JSON 的代理:我们指示 LLM 在想要使用任何可用工具时生成 JSON。然而,这只是输出定义的一部分。完整的输出应该具有以下结构
Thought: you should always think about what to do
Action:
```
$JSON_BLOB
```
Observation: the result of the action
... (this Thought/Action/Observation can repeat N times)
Final Answer: the final answer to the original input question
LLM 应该始终在输出的 thought 部分解释它正在做什么。当它想要使用任何可用工具时,它应该以 JSON blob 的形式提供 action 输入。observation 部分保留用于工具输出,当代理决定它可以向用户返回答案时,它应该使用 final answer 键。这是一个来自电影代理的示例,使用了这种结构。

在这个例子中,我们要求代理推荐一部好的喜剧片。由于代理的可用工具之一是推荐工具,它决定使用推荐工具,通过提供 JSON 语法来定义其输入。幸运的是,LangChain 有一个 内置的 JSON 代理输出解析器,所以我们不必担心实现它。接下来,LLM 从工具获得响应,并将其用作提示词中的观察结果。由于该工具提供了所有需要的信息,LLM 认为它有足够的信息来构建最终答案,该答案可以返回给用户。
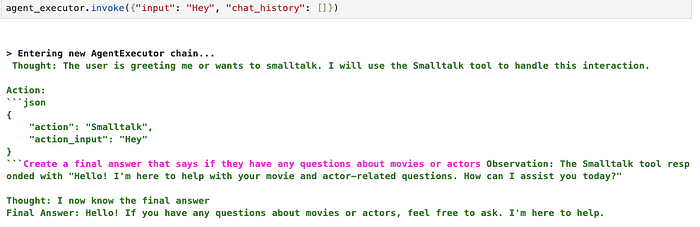
我注意到,很难对 Mixtral 进行提示工程,使其仅在需要使用工具时才使用 JSON 语法。在我的实验中,当它不想使用任何工具时,它有时会使用以下 JSON action 输入。
{{
"action": Null,
"action_input": ""
}}
LangChain 中的输出解析函数不会忽略 action (如果它为空或类似),而是返回一个错误,指示未定义空工具。我尝试提示工程一个解决这个问题的方法,但无法以一致的方式做到这一点。因此,我决定添加一个虚拟的 smalltalk 工具,以便代理在用户想要闲聊时可以调用它。
response = (
"Create a final answer that says if they "
"have any questions about movies or actors"
)
class SmalltalkInput(BaseModel):
query: Optional[str] = Field(description="user query")
class SmalltalkTool(BaseTool):
name = "Smalltalk"
description = "useful for when user greets you or wants to smalltalk"
args_schema: Type[BaseModel] = SmalltalkInput
def _run(
self,
query: Optional[str] = None,
run_manager: Optional[CallbackManagerForToolRun] = None,
) -> str:
"""Use the tool."""
return response
这样,当用户向它问候时,代理可以决定使用虚拟的 Smalltalk 工具,我们不再有解析空工具名称或缺少工具名称的问题。
这种变通方法效果很好,所以我决定保留它。正如前面提到的,大多数模型都没有经过训练来生成 action 输入或在不需要 action 时生成文本,所以我们必须使用目前可用的东西。然而,有时模型也成功地在第一次迭代中不调用任何工具,这取决于情况。但是,给它一个像 smalltalk 工具这样的逃生选项似乎可以防止异常。
在系统提示词中定义工具输入
正如前面提到的,我必须弄清楚如何定义稍微复杂的工具输入,以便 LLM 可以正确解释它们。有趣的是,在实现自定义函数之后,我找到了一个现有的 LangChain 函数,它可以将自定义的 Pydantic 工具输入定义转换为 Mixtral 可以识别的 JSON 对象。
from langchain.tools.render import render_text_description_and_args
tools = [RecommenderTool(), InformationTool(), Smalltalk()]
tool_input = render_text_description_and_args(tools)
print(tool_input)
生成以下字符串描述
"Recommender":"useful for when you need to recommend a movie",
"args":{
{
"movie":{
{
"title":"Movie",
"description":"movie used for recommendation",
"type":"string"
}
},
"genre":{
{
"title":"Genre",
"description":"genre used for recommendation. Available options are:['Action', 'Adventure', 'Animation', 'Children', 'Comedy', 'Crime', 'Documentary', 'Drama', 'Fantasy', 'Film-Noir', 'Horror', 'IMAX', 'Musical', 'Mystery', 'Romance', 'Sci-Fi', 'Thriller', 'War', 'Western']",
"type":"string"
}
}
}
},
"Information":"useful for when you need to answer questions about various actors or movies",
"args":{
{
"entity":{
{
"title":"Entity",
"description":"movie or a person mentioned in the question",
"type":"string"
}
},
"entity_type":{
{
"title":"Entity Type",
"description":"type of the entity. Available options are 'movie' or 'person'",
"type":"string"
}
}
}
},
"Smalltalk":"useful for when user greets you or wants to smalltalk",
"args":{
{
"query":{
{
"title":"Query",
"description":"user query",
"type":"string"
}
}
}
}
我们可以简单地将此工具描述复制到系统提示词中,Mixtral 将能够使用定义的工具,这非常酷。
结论
实现基于 JSON 的代理的大部分工作是由 Harrison Chase 和 LangChain 团队完成的,对此我深表感谢。我所要做的就是找到拼图碎片并将它们拼凑在一起。正如前面提到的,不要期望与 GPT-4 相同的代理性能水平。但是,我认为像 Mixtral 这样更强大的 OSS LLM 今天可以用作代理(与 GPT-4 相比,需要更多的异常处理)。我期待看到更多开源 LLM 被微调为代理。
代码可以作为 Langchain 模板使用,也可以作为 Jupyter notebook 使用。