
又一年使用 LLM 构建应用即将结束——而 2024 年并没有让人失望。每月有近 3 万用户注册 LangSmith,我们很幸运能站在行业前沿,了解正在发生的事情。
正如去年我们所做的那样,我们希望分享一些产品使用模式,这些模式展示了人工智能生态系统和构建 LLM 应用的实践是如何演变的。 随着人们在 LangSmith 中进行追踪、评估和迭代,我们看到了一些显著的变化。 这些变化包括开源模型采用率的急剧上升,以及从主要检索工作流程到具有多步骤、代理工作流程的 AI 代理应用程序的转变。
深入了解以下统计数据,准确了解开发人员正在构建、测试和优先考虑的内容。
基础设施使用情况
随着大型语言模型 (LLM) 席卷全球,每个人都在问魔镜:“哪个模型的使用率最高?” 让我们分析一下我们所看到的。
顶级 LLM 提供商
与去年的结果一样,OpenAI 仍然是 LangSmith 用户中最常用的 LLM 提供商——使用量是 Ollama 的 6 倍以上,Ollama 是第二受欢迎的提供商(按 LangSmith 组织使用量计算)。
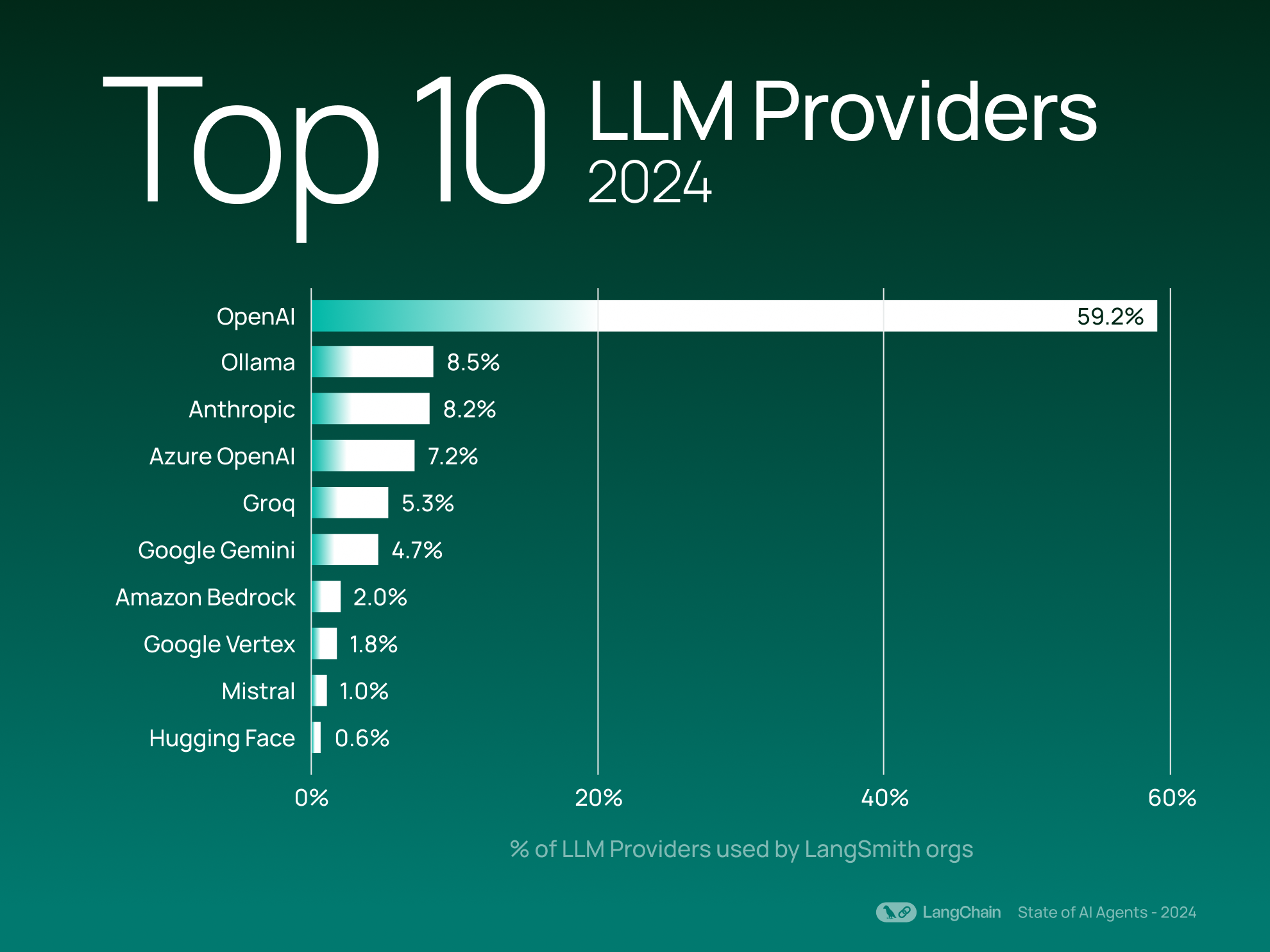
有趣的是,Ollama 和 Groq(两者都允许用户运行开源模型,前者侧重于本地执行,后者侧重于云部署)今年的势头加速,跻身前 5 名。 这表明人们对更灵活的部署选项和可定制的 AI 基础设施越来越感兴趣。

在提供开源模型的提供商方面,与去年相比,顶级提供商保持相对一致——Ollama、Mistral 和 Hugging Face 使开发人员可以轻松地在其平台上运行开源模型。 这些 OSS 提供商的集体使用量占前 20 名 LLM 提供商的 20%(按使用它们的组织数量计算)。
顶级检索器/向量存储
执行检索对于许多 GenAI 工作流程仍然至关重要。 前 3 名向量存储与去年保持不变,Chroma 和 FAISS 是最受欢迎的选择。 今年,Milvus、MongoDB 和 Elastic 的向量数据库也进入了前 10 名。

使用 LangChain 产品构建
随着开发人员在使用生成式人工智能方面获得了更多经验,他们也在构建更动态的应用程序。 从工作流程日益复杂到 AI 代理的兴起,我们看到了一些指向不断发展的创新生态系统的趋势。

可观测性不仅限于 LangChain 应用程序
虽然 langchain(我们的开源框架)是许多人 LLM 应用程序开发之旅的核心,但今年 LangSmith 追踪的 15.7% 来自非 langchain 框架。 这反映了一个更广泛的趋势,即无论您使用什么框架来构建 LLM 应用程序,都需要可观测性——并且 LangSmith 支持互操作性。
Python 仍然占主导地位,而 JavaScript 的使用量正在增长
调试、测试和监控在我们的 Python 开发人员心中肯定占有特殊的地位,84.7% 的使用量来自 Python SDK。 但人们对 JavaScript 的兴趣显着且不断增长,因为开发人员追求以 Web 为先的应用程序——JavaScript SDK 占今年 LangSmith 使用量的 15.3%,与去年相比增长了 3 倍。
AI 代理正在获得关注
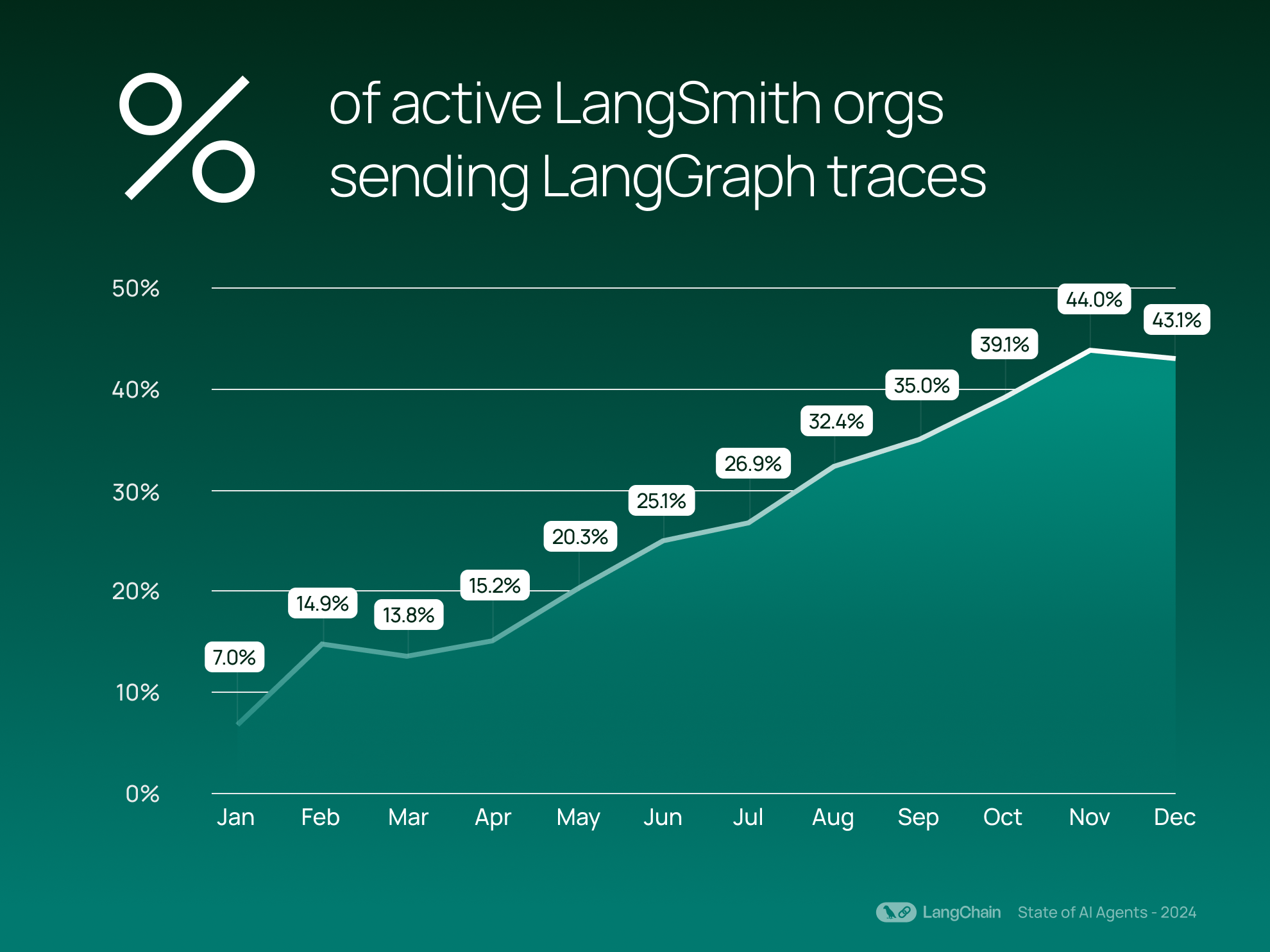
随着公司越来越认真地将 AI 代理融入各个行业,我们可控代理框架 LangGraph 的采用率也在上升。 自 2024 年 3 月发布以来,LangGraph 的势头稳步增长——43% 的 LangSmith 组织现在发送 LangGraph 追踪。 这些追踪代表了超越基本 LLM 交互的复杂、协调的任务。
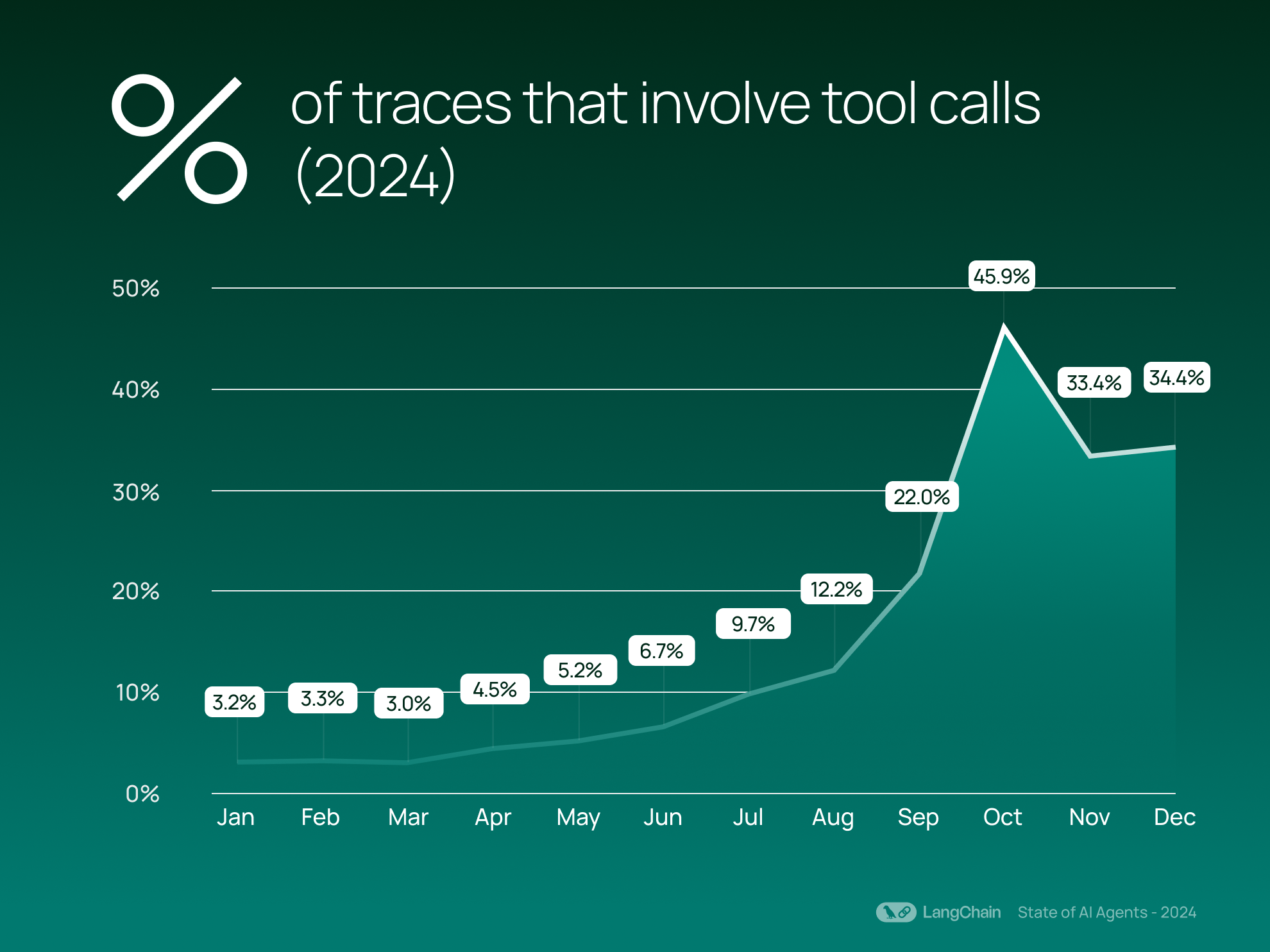
这种增长与代理行为的兴起相符:我们看到平均现在 21.9% 的追踪涉及工具调用,高于 2023 年的平均 0.5%。 工具调用允许模型自主调用函数或外部资源,标志着更具代理性的行为,模型可以决定何时采取行动。 增加工具调用的使用可以增强代理与外部系统交互并执行诸如写入数据库等任务的能力。
性能和优化
在开发应用程序(尤其是利用 LLM 资源的应用程序)时,平衡速度和复杂性是一个关键挑战。 下面,我们将探讨组织如何与其应用程序交互,以使其需求的复杂性与高效的性能相匹配。
复杂性正在增长,但任务正在得到有效处理
每个追踪的平均步骤数在过去一年中增加了一倍多,从 2023 年的平均 2.8 步上升到 2024 年的 7.7 步。 我们将步骤定义为追踪中的不同操作,例如调用 LLM、检索器或工具。 步骤的增加表明组织正在利用更复杂和多方面的工作流程。 用户不是进行简单的问答交互,而是在构建将多个任务链接在一起的系统,例如检索信息、处理信息和生成可操作的结果。

相比之下,每个追踪的平均 LLM 调用次数增长较为温和——从 平均 1.1 次 LLM 调用增加到 1.4 次。 这说明开发人员正在设计系统,以更少的 LLM 调用实现更多目标,在保持功能的同时控制昂贵的 LLM 请求。
LLM 测试与评估
组织正在做些什么来测试其 LLM 应用程序,以防止不准确或低质量的 LLM 生成的响应? 虽然保持 LLM 应用程序的高质量绝非易事,但我们看到组织正在使用 LangSmith 的评估功能来自动化测试并生成用户反馈循环,从而创建更强大、更可靠的应用程序。
LLM 作为裁判:评估重要事项
LLM 作为裁判评估器将评分规则捕获到 LLM 提示中,并使用 LLM 来评分输出是否符合特定标准。 我们看到开发人员最常测试以下特性:相关性、正确性、完全匹配和帮助性
这些突显了大多数开发人员都在对响应质量进行粗略检查,以确保 AI 生成的输出不会完全偏离目标。

通过人工反馈迭代
人工反馈是人们构建 LLM 应用程序的迭代循环的关键部分。 LangSmith 加快了收集和整合关于追踪和运行(即跨度)的人工反馈的过程——以便用户可以创建丰富的改进和优化数据集。 在过去一年中,注释运行次数增长了 18 倍,与 LangSmith 使用量的增长呈线性增长。
每次运行的反馈量也略有增加,从每次运行 2.28 个反馈条目增加到 2.59 个反馈条目。 尽管如此,每次运行的反馈仍然相对稀疏。 用户可能优先考虑审查运行的速度而不是提供全面的反馈,或者只评论需要关注的最关键或有问题的运行。
结论
在 2024 年,开发人员倾向于使用多步骤代理来应对复杂性,通过更少的 LLM 调用来提高效率,并使用反馈和评估方法在其应用程序中添加质量检查。 随着更多 LLM 应用程序的创建,我们很高兴看到人们如何深入研究更智能的工作流程、更好的性能和更强的可靠性。
在此处了解更多关于 LangSmith 如何为您的 LLM 应用程序开发带来更高的可见性并随着时间的推移提高性能——从调试瓶颈到评估响应质量再到监控回归。