简介
LangChain 的主要用例之一是将 LLM 连接到用户数据,从而允许用户构建个性化的 LLM 应用程序。 其中关键部分是检索 - 根据用户查询获取相关文档。
今天,我们很高兴地宣布 Vectara 集成到 LangChain 中,以帮助简化检索。 在这篇博文中,我们将深入探讨检索如此重要的原因,以及如何使用 Vectara 的 LangChain 集成来构建可扩展的 LLM 驱动的应用程序。
什么是 Vectara?
Vectara 是一个 GenAI 对话式搜索平台,通过“Grounded Generation”(可信赖生成),提供易于使用的“为您的自有数据打造 ChatGPT”体验。
开发者可以使用 Vectara 的 API,它基于神经搜索核心,能够实现查询与相关文档之间的高度精确匹配,从而构建 GenAI 对话式搜索应用程序,例如我们的 AskNews 示例应用程序。
使用 Vectara 简化了 LLM 应用程序开发:搜索平台承担了大量与用户数据交互的繁重工作,让开发者可以专注于其产品特有的应用程序逻辑。

LangChain 的可信赖生成
LLM 是非常强大的模型,但它们存在数据时效性和幻觉问题。 例如,正如这篇关于 LLM 幻觉的博文中所提到的,如果您向 ChatGPT 询问硅谷银行,它将根据其训练的 2022 年之前的数据提供响应,并且对该银行最近的倒闭一无所知。
“Grounded Generation”(可信赖生成)是解决此问题的一种通用方法,也是 LangChain 提供的可用主要用例之一。
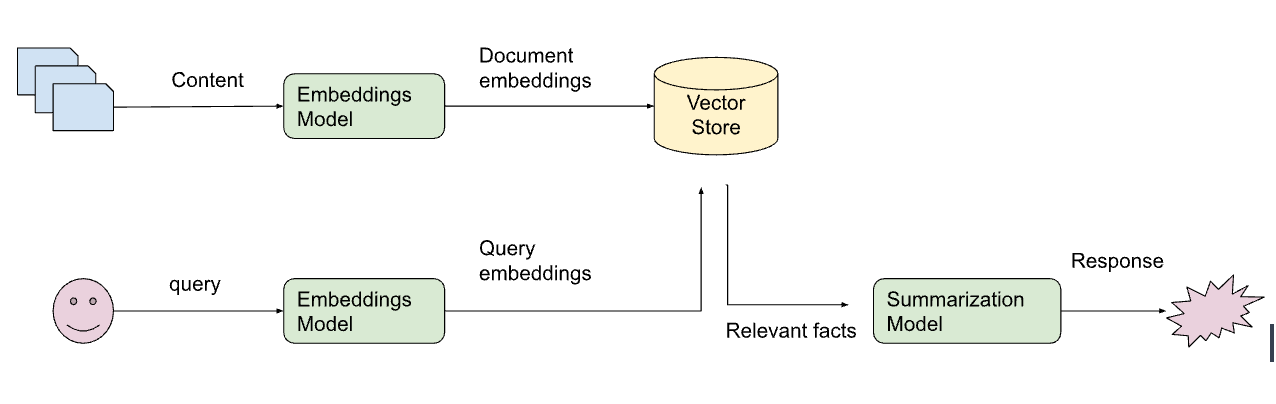
让我们看一个来自 LangChain 代码库的使用检索增强生成进行问答的简单示例。
from langchain.document_loaders import TextLoader
from langcain.embeddings import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.text_splitters import CharacterTextSplitter
from langchain.vectorstores import FAISS
raw_docs = TextLoader(‘state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(raw_docs)
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(docs, embeddings)
qa = RetrievalQA.from_llm(llm=OpenAI(), retriever=vectorstore.as_retriever())首先,我们获取文档文本(在本例中为 2022 年国情咨文的文字记录),并使用 langchain.text_splitter.CharacterTextSplitter 将文本拆分为小块(每块 1000 个字符)。
然后,我们使用 OpenAIEmbeddings 获取每个块的嵌入向量,并将它们存储在像 FAISS 这样的向量数据库中。
最后,我们构建一个 RetrievalQA(检索问答)链。
我们得到的答案是:
“普京误判了形势,以为当他入侵乌克兰时,世界会屈服。”
非常酷!
使用 Vectara 的 LangChain 问答
让我们运行相同的程序,但这次使用 Vectara 作为向量数据库。 这样做将利用 Vectara 的“Grounded Generation”(可信赖生成)。
首先,我们设置一个 Vectara 帐户并创建一个语料库。 在为该语料库创建 API 密钥后,我们可以将所需的参数设置为环境变量
export VECTARA_CUSTOMER_ID=<your-customer-id>
export VECTARA_CORPUS_ID=<the-corpus-id>
export VECTARA_API_KEY=<...API-KEY…>Vectara 提供其自身针对精确检索优化的嵌入向量,因此我们实际上不必使用(或付费购买)额外的嵌入模型。 相反,我们只需使用 Vectara.from_documents() 将文档上传到 Vectara 针对此语料库的索引中,并将其用作链中的检索器
from langchain.vectorstores import Vectara
loader = TextLoader(“state_of_the_union.txt”)
documents = loader.load()
vectara = Vectara.from_documents(documents)
qa = RetrievalQA.from_llm(llm=OpenAI(), retriever=vectara.as_retriever())
print(qa({“query”: “According to the document, what did Vladimir Putin miscalculate?”}))Vectara 获取源文档并以优化的方式自动对其进行分块并创建嵌入向量,因此我们甚至不必使用 TextSplitter(并决定块大小),也不需要调用(或付费购买)OpenAIEmbeddings。 由于 Vectara 具有其自己的内部向量存储,因此我们不需要使用 FAISS 或任何其他商业向量数据库。
最后,我们以与之前相同的方式构建 RetrievalQA(检索问答)链,并且再次得到响应
“普京误判了形势,以为当他入侵乌克兰时,世界会屈服。”
总结
我们很高兴 Vectara 完全集成到 LangChain 中,这使得已经喜爱 LangChain 的开发人员可以更轻松地使用 Grounded Generation(可信赖生成)构建 LLM 驱动的应用程序。
非常感谢 Vectara 团队(Ofer、 Amr 和许多其他人)的支持和贡献。
如果您想亲身体验 Vectara + LangChain 的优势,可以在这里注册一个免费的 Vectara 帐户。