
重要链接
如果说 2023 年是 LLM 的突破之年,那么 2024 年有望成为大量 LLM 驱动的应用程序投入生产的一年。从 Elastic AI 助手 到 CommandBar 的 Copilot 用户助手 - 越来越多的复杂应用程序正在交付生产并提供真正的业务价值。许多这些应用程序使用 LangSmith 来 测试 和 调试 他们的应用程序,今天我们宣布推出一套旨在帮助应用程序在生产部署后运行的新功能。
作为一名 AI 工程师,您的工作不会在应用程序发布到生产环境后就停止。一旦它投入生产,您就开始获得流经系统的真实用户数据,让您尝试回答各种问题。人们是如何使用它的?应用程序在哪里出错?哪里表现良好?我如何根据这些数据改进我的应用程序?我如何开始构建一个 数据飞轮?
为了尽可能轻松地解决这些问题,我们发布了一套围绕生产日志记录和自动化的新功能。生产监控 使您能够更轻松地手动探索和识别您的数据,而自动化 使您能够开始以自动化的方式处理这些数据。与所有 LangSmith 功能一样,无论您是否使用 LangChain,这些功能都有效。在本博客的其余部分,我们将介绍这些功能是什么。您还可以查看我们的 YouTube 播放列表 以获取视频演示。
筛选
我们已经改进了我们的基础设施,并在能够支持高级筛选器方面投入了大量资金。这些高级筛选器对于能够高效且彻底地检查您的数据至关重要。作为起点,我们支持基于以下内容的运行基本筛选:
- 延迟: 可用于识别花费异常长时间的运行
- 错误: 可用于识别遇到突发错误的运行
- 反馈: 可用于识别用户认为特别好或特别差的运行
- 元数据/标签: 可用于根据其配置筛选到运行的子集
- 全文搜索: 可用于搜索关键字
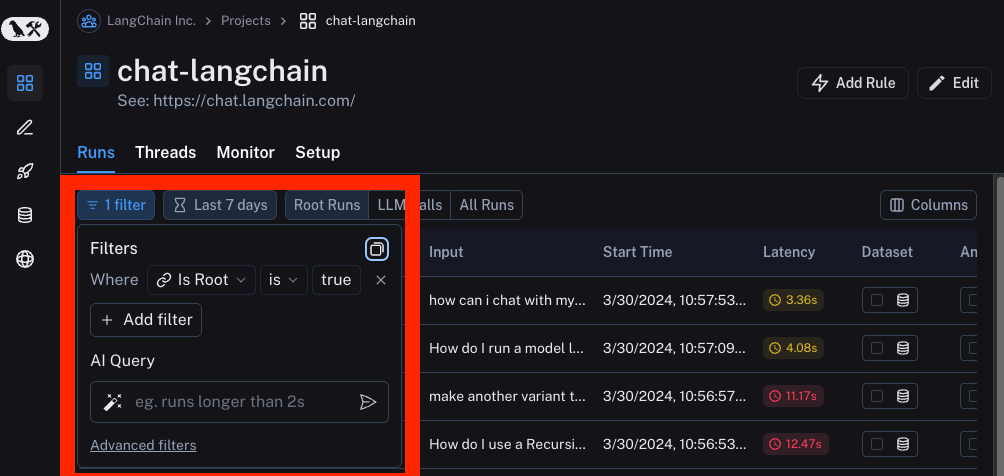
我们还添加了一些更高级的筛选形式。这些包括
按追踪属性:有时您可能希望根据追踪的根运行的属性来筛选运行。当使用链或代理时,这尤其常见,在链或代理中,有多个子运行构成更大的追踪。通常,您只收集对高级别追踪的反馈。您可能希望查找父追踪具有正面或负面反馈的特定类型的子运行。一个例子可能是筛选名称为 "ChatOpenAI" 的运行,其中追踪的根运行的 user_score 等于 0。
按树属性:与上述相反。您可能希望筛选具有特定类型子运行的追踪的根运行。这对于识别调用了特定工具的高级别追踪可能很有用,例如。
AI 查询:不知道如何在 UI 中构建您的追踪?用自然语言输入您想要搜索的内容,我们将使用 LLM 将其转换为我们的筛选语言!(是的,我们使用 LangSmith 监控这一点)
监控
筛选对于能够识别和查看单个数据点很有用。通常,您可能希望更鸟瞰地了解正在发生的事情。在 监控 选项卡中,您可以查看随时间变化的汇总统计信息。这些统计信息包括 LLM 特定指标,如延迟、首个令牌时间、成本、令牌、反馈等。
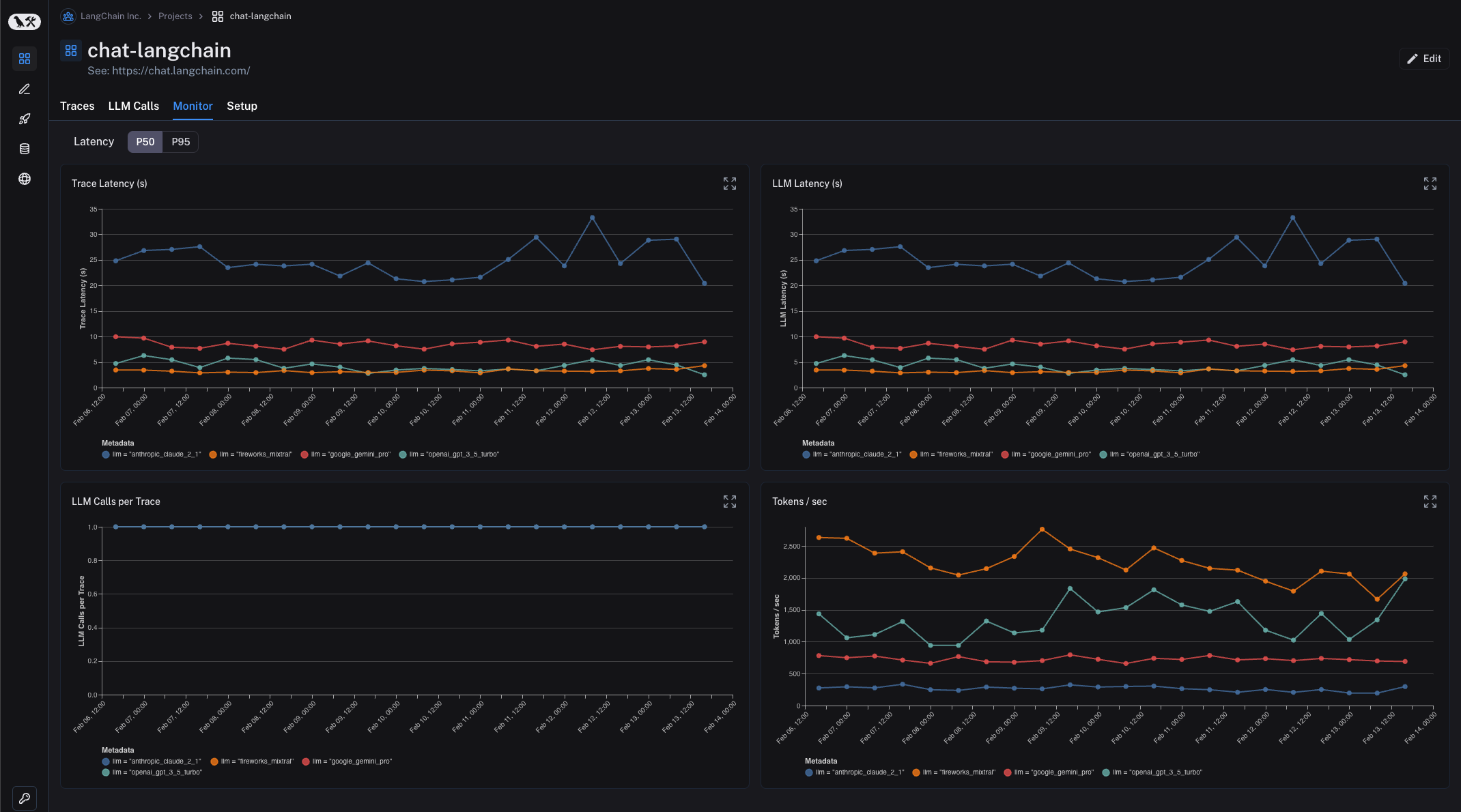
这里更高级的功能之一是您可以按元数据属性对运行进行分组。这意味着您向表示特定配置的运行添加元数据标签。一个具体的例子是 ChatLangChain,我们在其中在五个不同的 LLM 提供商之间轮换。我们插入一个元数据键来跟踪我们选择了哪个 LLM。在 LangSmith 中,您随后可以按此元数据键对监控仪表板进行分组。这使我们能够轻松地比较所有相同的统计数据(延迟、反馈等)在五个不同的模型提供商之间。
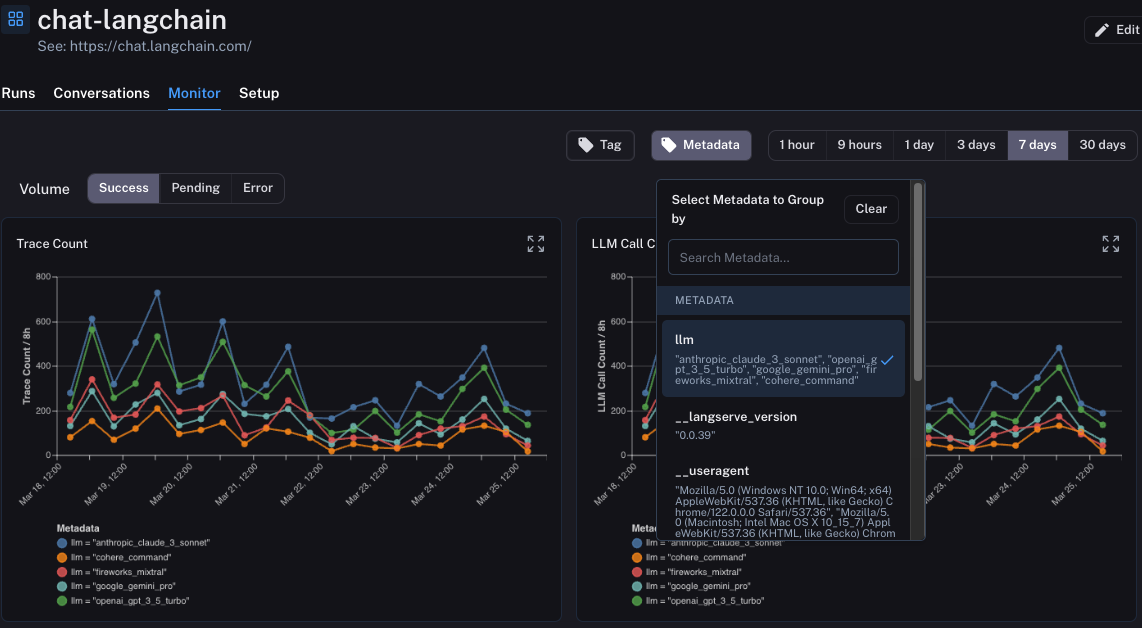
这些图表的另一个非常有用的功能是它们都是交互式的。这意味着您可以单击图表中的任何特定点,这将自动将您带到 运行 页面,并自动筛选为仅显示您刚刚单击的时间段内的数据点。
线程
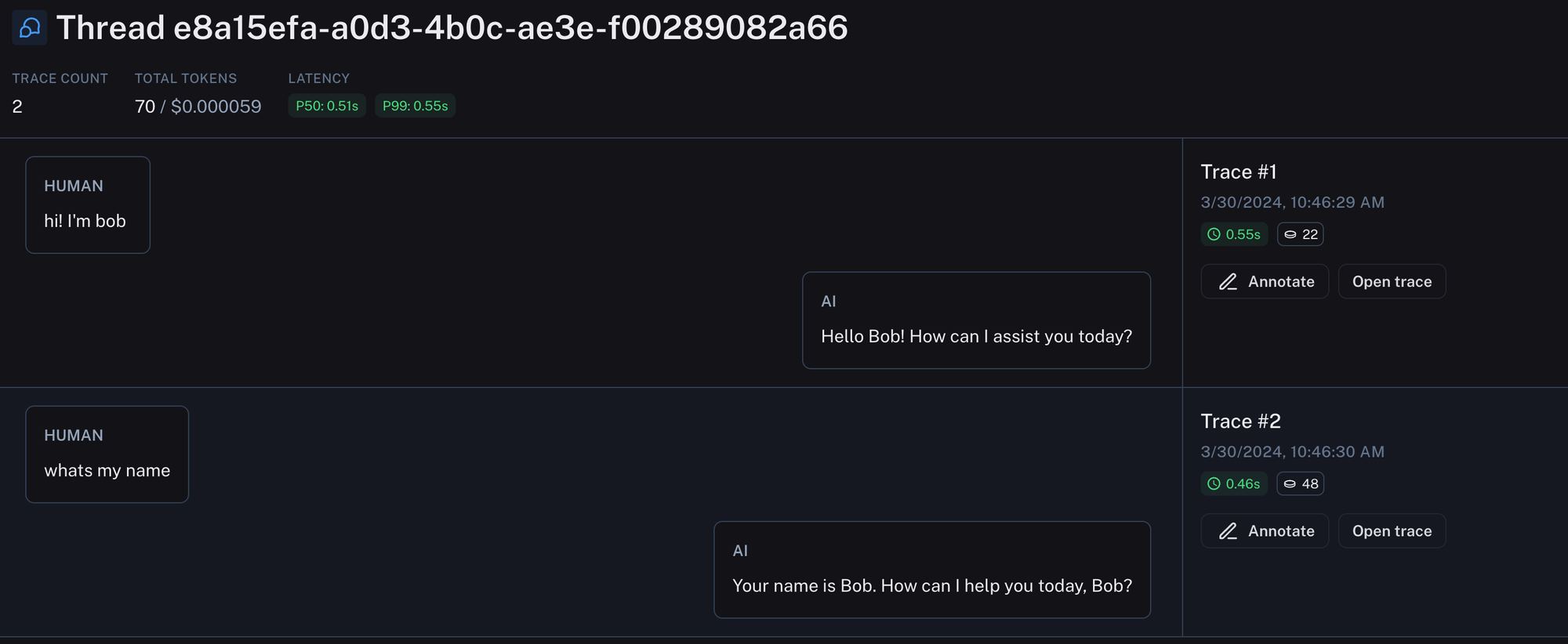
LLM 应用程序的主要 UX 仍然是聊天。在聊天应用程序中,人类消息和 AI 响应之间存在来回交互。每个 AI 响应都是一个追踪(并且可以包含许多子运行)。通过 线程,我们现在引入了一种在单个视图中查看整个对话来回交互的方式。这可以通过为每个追踪附加一个特殊的元数据键以及该对话的唯一标识符来完成。这使得调试对话变得更加容易,因为您可以在一个位置看到整个线程。
自动化
之前的特性都使手动检查数据点变得容易。通过 自动化,您现在可以以自动方式对感兴趣的数据点执行操作。
自动化由三个要点组成:筛选器、采样率和操作。筛选器确定您要对其执行操作的数据点子集。我们在上面讨论了筛选器,我们可以重用相同的 UI 组件来创建自动化。在构建所需的筛选器后,您可以单击 添加规则 按钮来创建自动化。
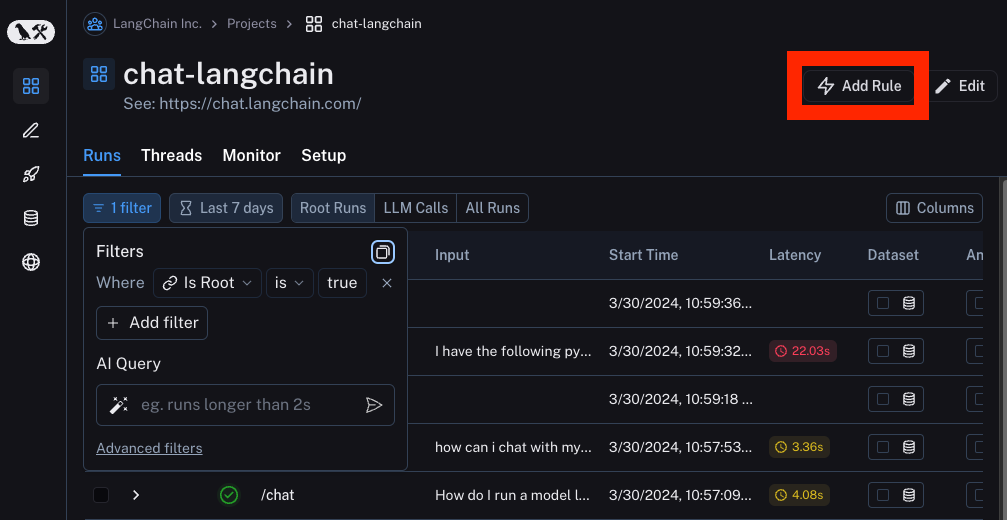
采样率是接下来要设置的内容。这是一个介于 0 和 1 之间的比率,表示您要对其执行操作的满足筛选器的数据点的分数。
您可以从三个操作中选择:添加到数据集、添加到注释队列 和 在线评估。
添加到数据集
添加到数据集 操作完全按照名称所示执行操作:它自动将所有选定的运行添加到数据集。运行的输入成为数据点的输入,输出成为输出,并且任何元数据或反馈也会被复制过来。
这可以用于自动构建数据集,您可以将其用于测试、少样本示例或微调。这里的一个典型工作流程包括筛选收到正面反馈的数据点,并将它们移动到数据集中。
添加到注释队列
添加到注释队列 操作也是不言自明的。它将所有选定的数据点移动到注释队列中。注释队列是一种用户友好的方式,可以轻松检查数据点。您可以从这个队列中留下反馈、注释或手动添加到数据集。
一个常见的工作流程是将任何具有负面反馈的数据点发送到注释队列。这允许审阅者检查所有数据点,并可选择使用正确答案对其进行注释,并将其移动到数据集。
在线评估
在线评估是我们正在添加的全新功能,也是我们非常兴奋的功能。虽然人类可能难以查看大量数据点,但对于语言模型来说,这非常容易!
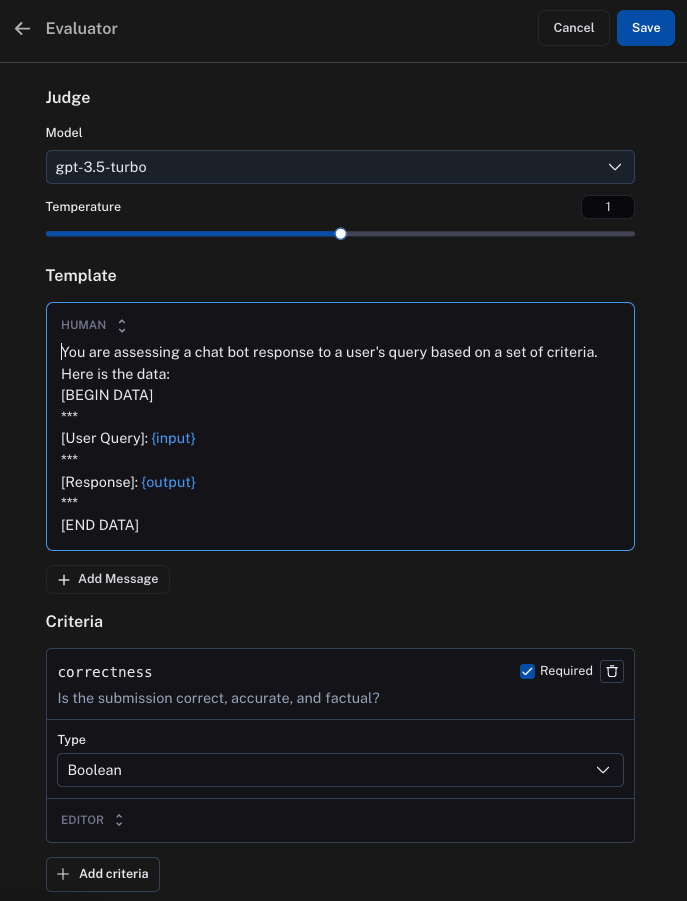
在线评估 的基本思想是将每个运行发送到 LLM,以根据某些标准对其进行评估。此标准可以是“粗鲁”(检查 LLM 的响应是否粗鲁)或完全不同的内容,如“主题”(将用户输入分类为各种主题)。标准是完全可配置的。
用例:优化
我们还添加了一个示例用例,展示如何将所有这些功能组合到一个相对高级的用例中。我们整理的用例展示了如何创建一个应用程序,该应用程序可以随着时间的推移学习如何以您喜欢的风格发推文。它使用了一些技术来实现这一点
- 将所有追踪记录到 LangSmith
- 将所有反馈记录到 LangSmith,与特定追踪相关联
- 对于所有具有正面反馈的追踪,移动到数据集
- 对于所有具有负面反馈的追踪,移动到注释队列
- 在应用程序中使用上述数据集作为少样本示例
您可以在 此处 查看详细的演示。
结论
将 LLM 应用程序发布到生产环境只是第一步。有了它,您就可以开始获得真实的用户互动和反馈。捕获这些信息然后利用它至关重要。您越容易做到这一点,您的应用程序就能越快地改进。借助这些“生产日志记录和自动化”功能,我们正在使您尽可能轻松地做到这一点。