今天,我们很高兴地宣布在 LangGraph 中迈向长期记忆支持的第一步,该支持在 Python 和 JavaScript 中均可使用。 长期记忆使您能够在对话之间存储和回忆信息,以便您的代理可以从反馈中学习并适应用户偏好。 此功能是 OSS 库的一部分,默认情况下为所有 LangGraph Cloud 和 Studio 用户启用。
关于记忆
今天大多数 AI 应用程序都是金鱼;它们会忘记对话之间的所有内容。 这不仅效率低下,而且从根本上限制了 AI 可以做什么。
在 LangChain 的过去一年中,我们一直与客户合作将记忆构建到他们的代理中。 通过这种经验,我们意识到了一些重要的事情:对于 AI 记忆而言,没有通用的完美解决方案。 每个应用程序的最佳记忆仍然包含非常特定于应用程序的逻辑。 从广义上讲,今天大多数“代理记忆”产品都过于高级。 他们试图创建一个无法满足许多生产用户需求的通用产品。
这种洞察力就是我们为什么将初始记忆支持构建到 LangGraph 中作为简单的文档存储的原因。 高级抽象可以很容易地构建在之上(正如我们将在下面展示的那样),但其下是一个简单、可靠、持久的记忆层,它内置于所有 LangGraph 应用程序中。
跨线程记忆
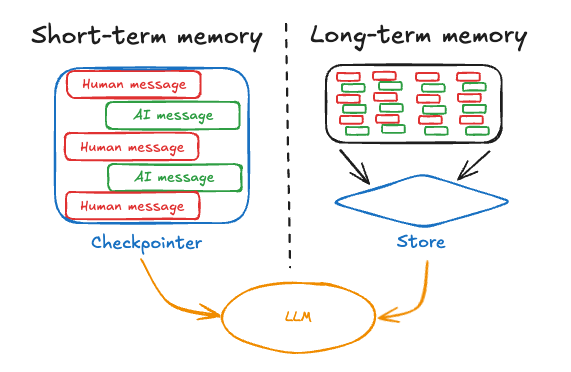
LangGraph 一直擅长使用 检查点管理单个对话线程内部的状态。 这种“短期记忆”使您可以在单个对话中维护上下文。
今天,我们正在跨 多个线程扩展该功能,使您的代理能够轻松记住跨多个对话的信息,所有这些都集成在 LangGraph 框架中。
在其核心,跨线程记忆“仅仅”是一个持久的文档存储,可让您放置、获取和搜索您已保存的记忆。 这些基本原语启用
- 跨线程持久性:跨不同的对话会话存储和回忆信息。
- 灵活的命名空间:使用自定义命名空间组织记忆,可以轻松管理不同用户、组织或上下文的数据。
- JSON 文档存储:将记忆保存为 JSON 文档,以便于操作和检索。
- 基于内容的过滤:跨命名空间搜索基于内容的记忆。
为了更深入地理解这些概念,我们准备了一组文档,以提供框架和关于如何入门的指导
实际应用
为了帮助您开始在应用程序中实现长期记忆,我们准备了一个新的 LangGraph 模板
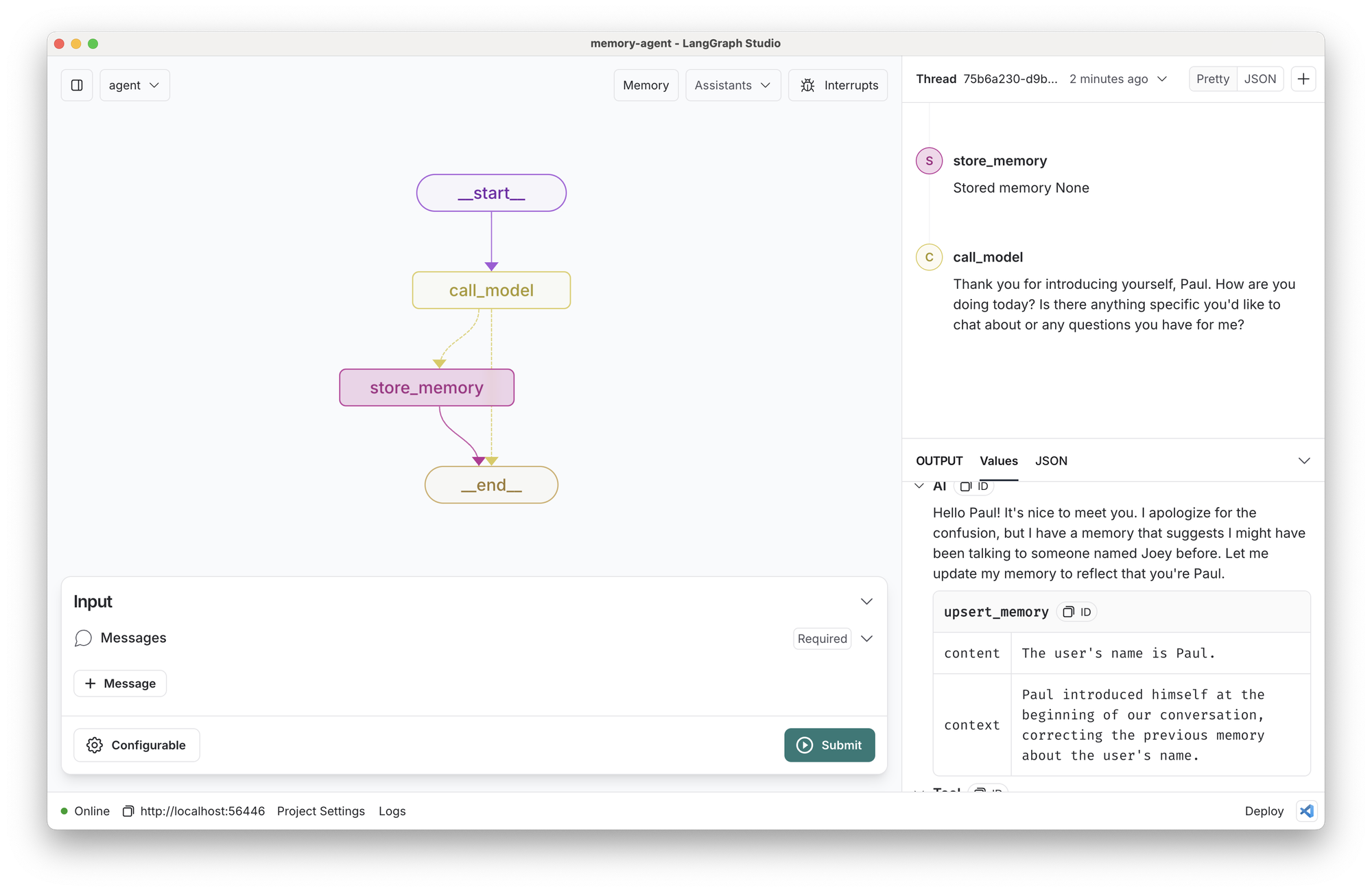
此 LangGraph 模板展示了一个聊天机器人代理,它可以管理自己的记忆。 此模板的关键资源是
- 一个 端到端教程视频,介绍了实现过程
- Python 中的 LangGraph 记忆代理
- JavaScript 中的 LangGraph.js 记忆代理
这些资源演示了一种在 LangGraph 中利用长期记忆的方法,弥合了概念和实现之间的差距。
我们鼓励您探索这些材料,并尝试将长期记忆融入您的 LangGraph 项目中。 与往常一样,我们欢迎您的反馈,并期待看到您如何在您的应用程序中应用这些新功能。