关键链接
动机
检索增强生成 (RAG) 是 LLM 应用开发中最重要的概念之一。多种类型的文档可以传递到 LLM 的上下文窗口中,从而实现交互式聊天或问答助手。虽然迄今为止许多 RAG 应用都侧重于文本,但大量信息是以视觉内容形式传达的。例如,幻灯片通常用于从投资者演示到内部公司沟通等各种用例。随着像 GPT-4V 这样的多模态 LLM 的出现,现在可以对幻灯片中捕获的视觉内容进行 RAG。下面,我们展示了解决这个问题的两种不同方法。我们分享了一个用于评估幻灯片 RAG 的公共基准,并用它来突出这些方法之间的权衡。最后,我们提供了一个模板,用于快速创建幻灯片的多模态 RAG 应用。
设计
这项任务类似于文本文档上的 RAG 应用:根据用户问题检索相关的幻灯片,并将它们传递给多模态 LLM (GPT-4V) 以进行答案合成。至少有两种通用方法来解决这个问题。
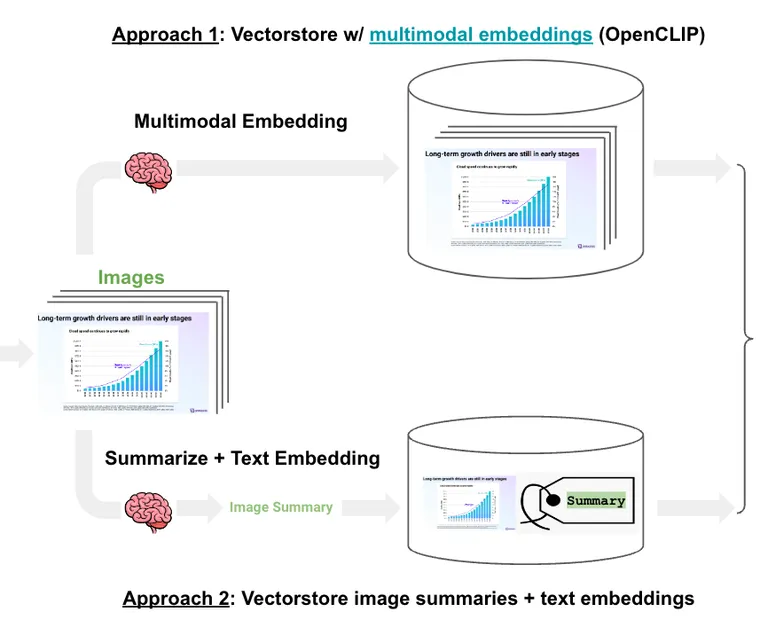
(1) 多模态嵌入:将幻灯片提取为图像,使用多模态嵌入来嵌入每个图像,根据用户输入检索相关的幻灯片图像,并将这些图像传递给 GPT-4V 进行答案合成。我们之前发布了一个使用 Chroma 和 OpenCLIP 嵌入的 实践指南。
(2) 多向量检索器:将幻灯片提取为图像,使用 GPT-4V 总结每个图像,嵌入图像摘要并链接到原始图像,根据图像摘要和用户输入之间的相似性检索相关图像,最后将这些图像传递给 GPT-4V 进行答案合成。我们之前发布了一个使用 多向量检索器的 实践指南。
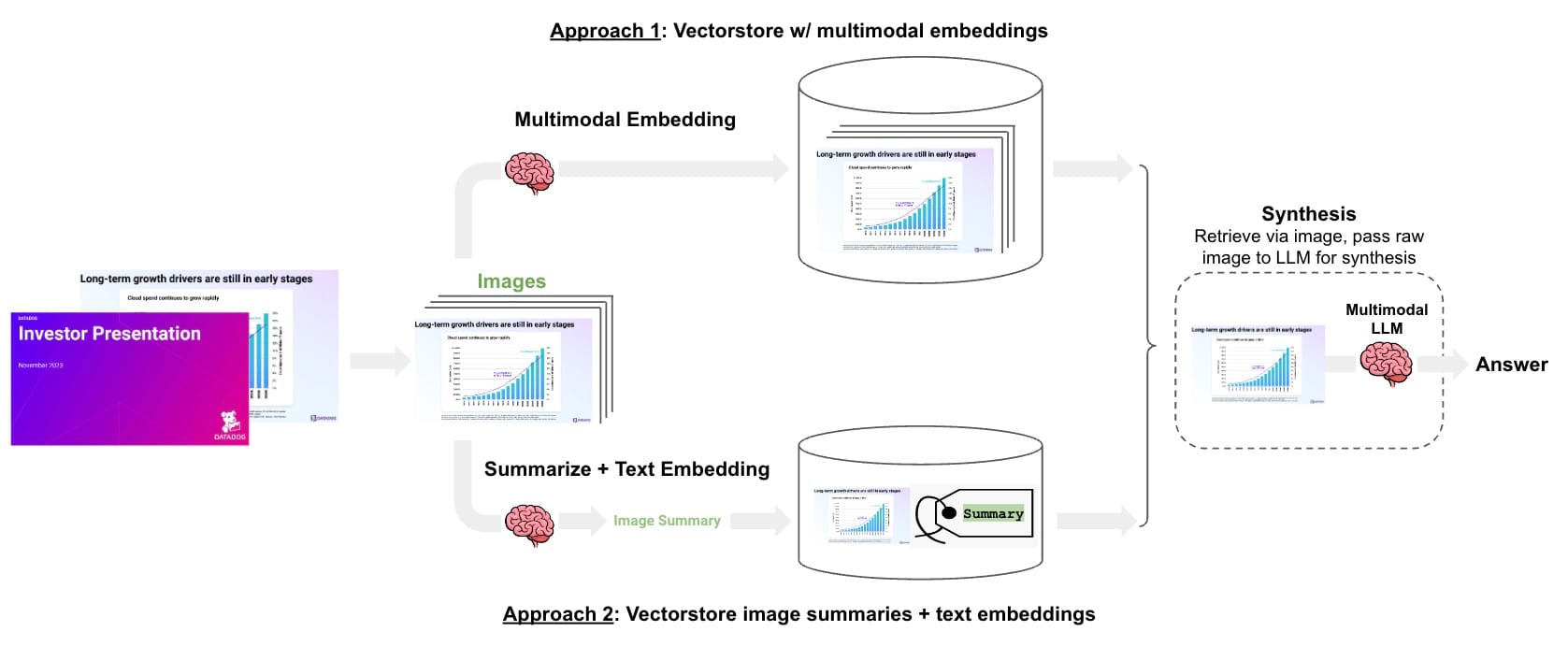
这两种方法之间的权衡很直接:多模态嵌入是一种更简单的设计,镜像了我们对基于文本的 RAG 应用所做的工作,但是选项有限,并且对于检索视觉上相似的图表或表格的能力存在一些疑问。相比之下,图像摘要使用成熟的文本嵌入模型,并且可以详细描述图表或图形。但是,这种设计存在更高的复杂性和图像摘要成本。
评估
为了评估这些方法,我们选择了一个来自 Datadog 的最新盈利演示,作为一个包含视觉和定性元素的真实幻灯片。我们为此幻灯片创建了一个小型公共 LangChain 基准,包含 10 个问题:您可以在此处和此处查看有关在此基准上进行评估的文档。
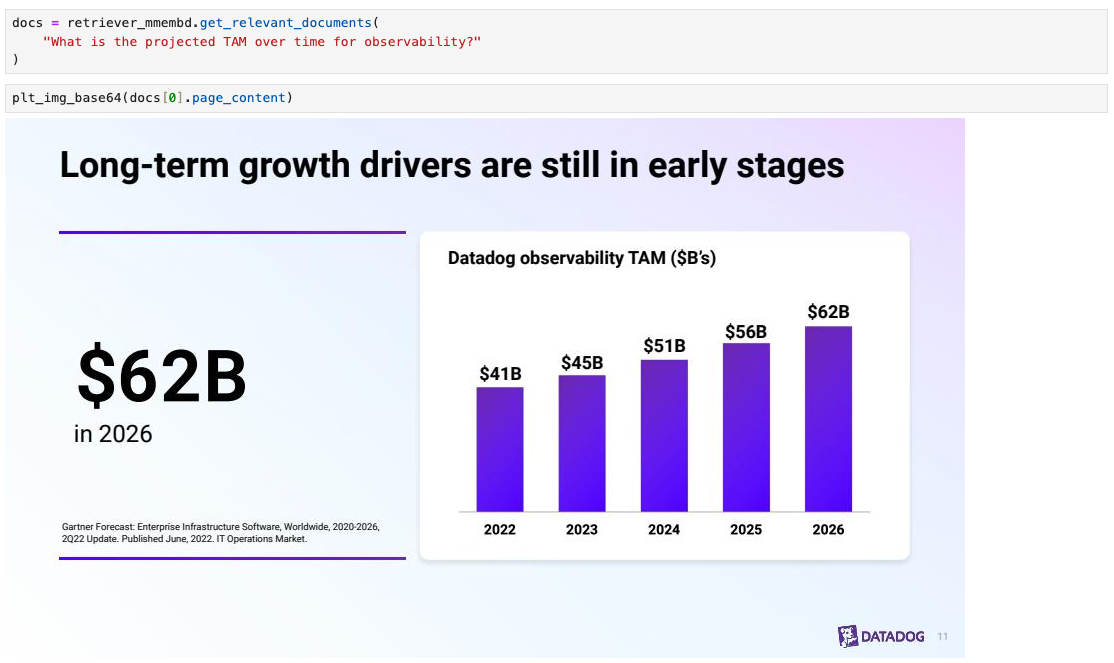
作为健全性检查,我们可以看到可以根据幻灯片内容的自然语言描述来检索幻灯片(下面,请参阅此处的代码)。
我们基准中的问答对基于幻灯片的视觉内容。我们使用 LangSmith 评估了上述两种 RAG 方法,并与使用文本提取的 RAG (Top K RAG (仅文本)) 进行了比较。
方法 | 得分 (CoT 准确率) |
Top k RAG (仅文本) | 20% |
多模态嵌入 | 60% |
多向量检索器(带图像摘要) | 90% |
LangSmith 提供了比较视图,我们可以在其中并排查看每个实验的结果。此处是一个公共页面,可以在其中详细比较评估运行。下图显示了运行比较视图。
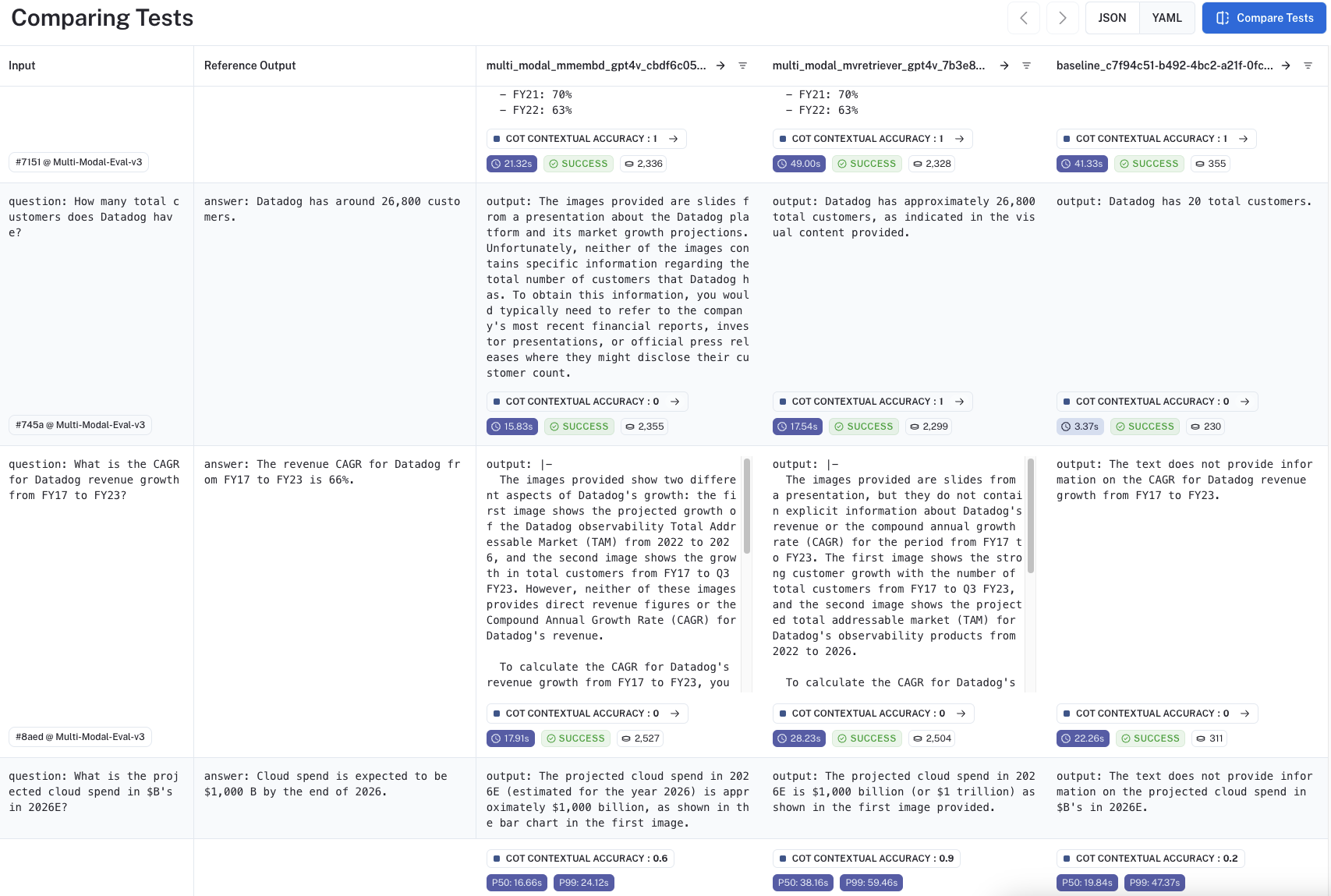
使用上述比较分析,我们可以比较每个问题检索到的内容。这些幻灯片深入探讨了评估集中的每个问答对以及相关的 LangSmith 跟踪。
见解
- 多模态方法远远超过仅文本 RAG 的性能。我们看到多模态方法(60% 和 90%)比仅加载文本的 RAG(20%)有了显着改进,这是一个预期的结果,因为保留视觉上下文对于推理幻灯片内容至关重要。
- GPT-4V 在从图像中提取结构化数据方面非常强大。例如,请参阅此跟踪。问题询问客户数量,这只能从包含各种视觉内容的幻灯片中检索。GPT-4V 能够从幻灯片中正确提取此信息
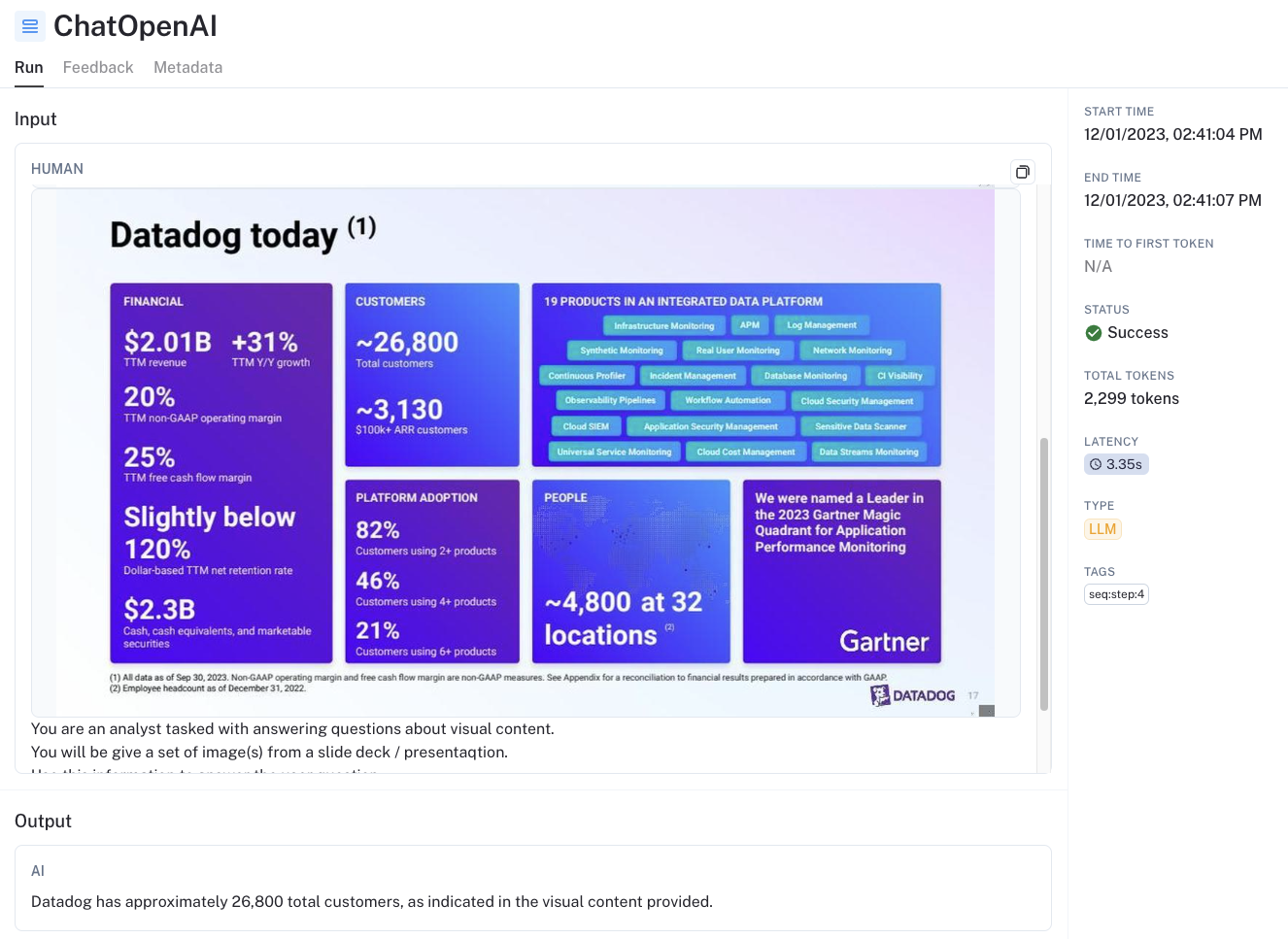
- 检索正确的图像是核心挑战。正如幻灯片中指出并在上面提到的那样,如果检索到正确的图像,那么 GPT-4V 通常能够正确回答问题。但是,图像检索是核心挑战。我们发现图像摘要确实比多模态嵌入显着提高了检索效果,但预先计算摘要的复杂性和成本更高。核心需求是能够区分视觉上相似的幻灯片的多模态嵌入。OpenCLIP 有各种不同的模型值得尝试;它们可以轻松配置,如此处所示。
部署
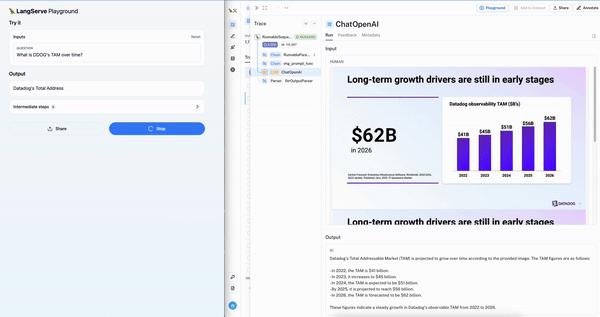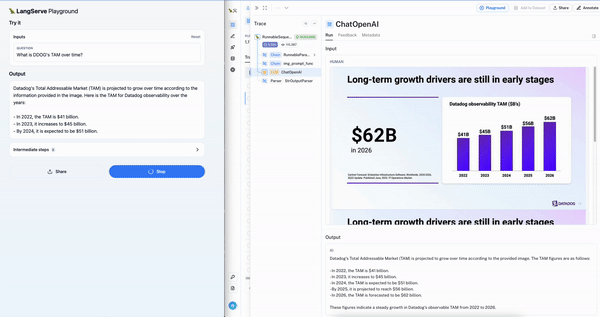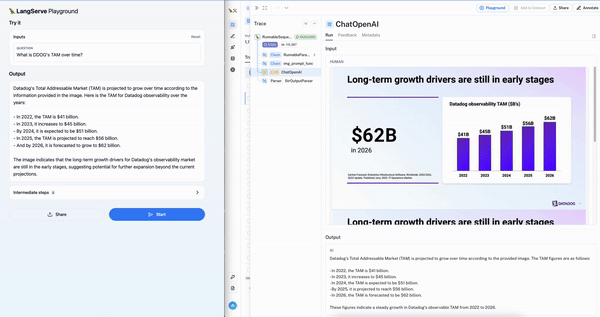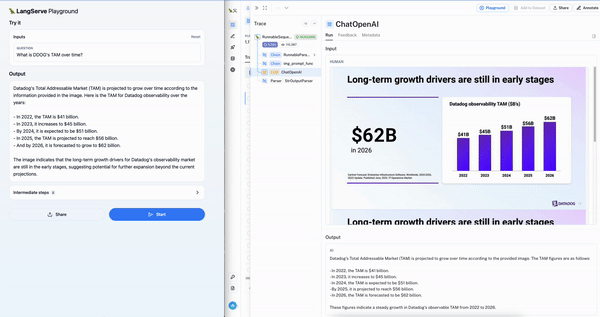
为了简化此用例的多模态 RAG 应用程序的测试,我们发布了一个使用 Chroma 和 OpenCLIP 多模态嵌入的模板。这使得入门极其容易:只需上传演示文稿并按照 README 操作(只需两个命令即可构建向量数据库并运行 Playground)。下面我们可以看到 Datadog 盈利演示上的交互式聊天 Playground(左)以及显示正确幻灯片检索的 LangSmith 跟踪(右)。
结论
多模态 LLM 有潜力解锁幻灯片中的视觉内容,用于 RAG 应用程序。我们为 Datadog 的投资者演示幻灯片构建了一个公共基准评估集,其中包含问答对 (此处)。我们在此基准上测试了使用两种方法的多模态 RAG。我们发现这两种方法都超过了仅文本 RAG 的性能。我们确定了多模态 RAG 方法之间的权衡:每个幻灯片的文本摘要可以提高检索效果,但代价是需要预先生成每个幻灯片的摘要。多模态模型可能具有更高的性能上限,但当前的选择有些有限,并且在我们的测试中,性能不如文本摘要。为了帮助测试和部署多模态 RAG 应用程序,我们还发布了一个模板。