关键链接
概述
随着上下文窗口扩展到 100 万 tokens,人们对长上下文 LLM 的兴趣正在激增。对于长上下文 LLM 检索,最受欢迎和被引用的基准之一是 Greg Kamradt 的 干草堆中的针:将一个事实(针)注入到上下文(干草堆)中(例如,Paul Graham 的 文章),并向 LLM 提出与此事实相关的问题。 这探索了跨上下文长度和文档位置的检索。
但是,这并不能完全反映许多 检索增强生成 (RAG) 应用程序;RAG 通常侧重于检索多个事实(来自索引),然后对它们进行推理。我们提出了一个新的基准来精确地测试这一点。在我们的 多重针 + 推理 基准测试中,我们展示了两个新的结果
- 当您要求 LLM 检索更多事实时,性能会下降
- 当 LLM 必须对检索到的事实进行推理时,性能会下降
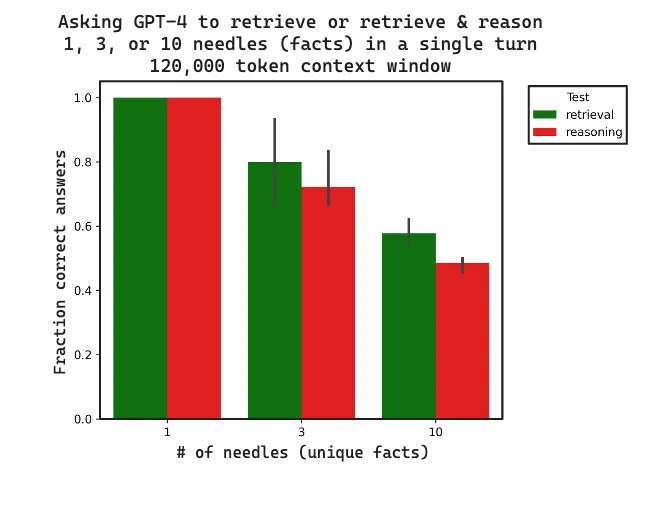
请参阅下面的图表,了解结果摘要:随着针数量的增加,检索性能会下降;并且对这些针进行推理比仅检索更差。
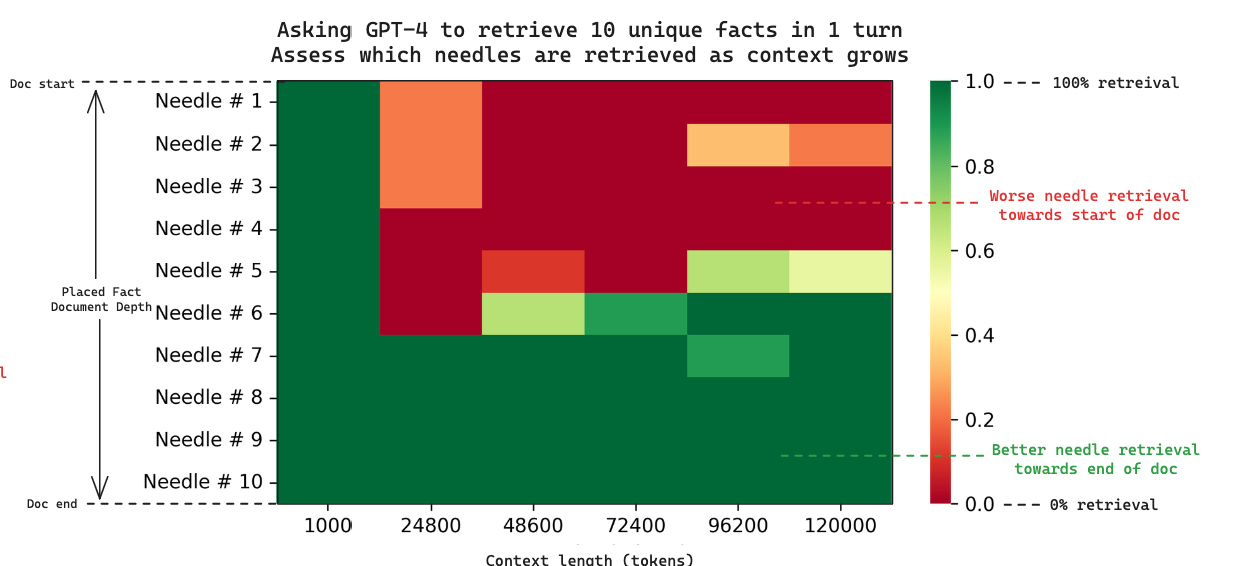
我们还展示了(类似于 之前的基准测试),随着传入的上下文越来越多,性能会下降。但是,我们还额外调查了不仅是整体性能,而且是当检索多个针时性能下降的 原因。查看下面结果的热图,我们可以看到,当检索多个针时,GPT-4 始终如一地检索末尾附近的针,而忽略了开头的针,这类似于 单针研究。
下面我们将介绍基准测试的使用方法,并讨论 GPT-4 的结果。
使用方法
要执行 多重针 + 推理 评估,用户只需要三件事:(1)一个需要多个针来回答的 问题,(2)一个从针中得出的 答案,以及(3)要插入到上下文中的 针列表。
我们扩展了 Greg Kamradt 的 LLMTest_NeedleInAHaystack 代码库,以支持多针评估和 LangSmith 作为评估器。使用 LangSmith 进行评估,我们 创建 了一个 LangSmith 评估集,其中包含项目 (1) 上述 问题 和 (2) 答案。
例如,让我们使用 这个 案例研究,其中针是披萨配料的组合。我们创建一个新的 LangSmith 评估集(此处)名为 multi-needle-eval-pizza-3,其中包含我们的 问题 和 答案
question:
What are the secret ingredients needed to build the perfect pizza?
answer:
The secret ingredients needed to build the perfect pizza are figs, prosciutto, and goat cheese.LangSmith 的问题、答案对 multi-needle-eval-pizza-3 评估集
一旦我们创建了数据集,我们使用以下几个标志
document_depth_percent_min- 第一根针的深度。其余的针大致以相等的间隔插入在第一根针之后。multi_needle- 运行多针评估的标志needles- 要注入到上下文中的完整针列表evaluator- 选择langsmitheval_set- 选择我们创建的评估集multi-needle-eval-pizza-3context_lengths_num_intervals- 要测试的上下文长度的数量间隔context_lengths_min(和 max)- 要测试的上下文长度范围
我们可以运行此命令来执行评估
python main.py --evaluator langsmith --context_lengths_num_intervals 6 --document_depth_percent_min 5 --document_depth_percent_intervals 1 --provider openai --model_name "gpt-4-0125-preview" --multi_needle True --eval_set multi-needle-eval-pizza-3 --needles '[ " Figs are one of the secret ingredients needed to build the perfect pizza. ", " Prosciutto is one of the secret ingredients needed to build the perfect pizza. ", " Goat cheese is one of the secret ingredients needed to build the perfect pizza. "]' --context_lengths_min 1000 --context_lengths_max 120000 使用 LangSmith 运行多针评估的命令
这将启动以下工作流程。它会将针插入到干草堆中,提示 LLM 使用插入针的上下文生成对 问题 的响应,并评估生成是否正确检索了针,使用基本事实 答案 和已记录的已插入针。
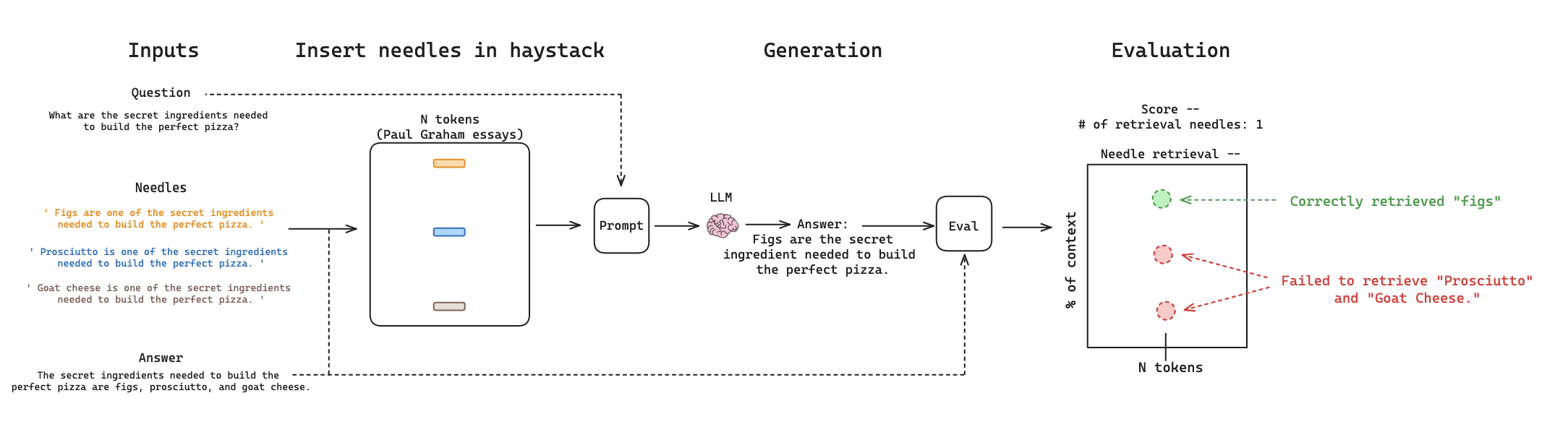
多重针 + 推理 评估的工作流程Multi-Needle + Reasoning evaluationGPT-4 检索结果
为了测试 GPT-4 的多针检索,我们构建了三个 LangSmith 评估集
multi-needle-eval-pizza-1此处 - 插入单根针multi-needle-eval-pizza-3此处 - 插入三根针multi-needle-eval-pizza-10此处 - 插入十根针
我们评估了 GPT4(128k token 上下文长度)在小(1000 token)和大(120,000 token)上下文长度的单轮中检索 1、3 或 10 根针的能力。运行的所有命令都 在此。带有 LangSmith 跟踪公共链接的所有生成结果都 在此。这是我们结果的摘要图
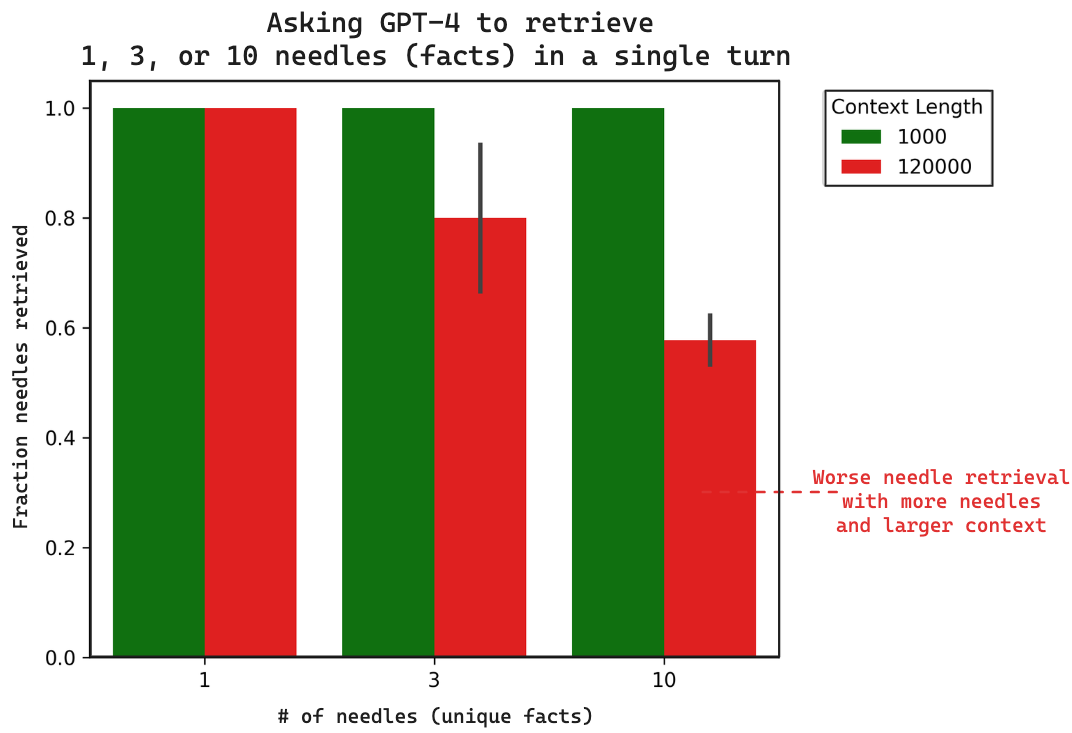
有明显的观察结果
- 当针的数量从 1 增加到 10 时,性能会下降
- 当上下文从 1000 tokens 增加到 120,000 tokens 时,性能会下降
为了探索和验证这些结果,我们可以深入研究 LangSmith 跟踪:此处 是一个 LangSmith 跟踪,我们在其中插入了 10 根针。这是 GPT-4 生成的内容
The secret ingredients needed to build the perfect pizza include espresso-soaked dates, gorgonzola dolce, candied walnuts, and pear slices.10 根针、24,800 token 上下文的副本 1 的 GPT-4 生成
只有 四种 秘制配料 在生成的内容中。根据 跟踪,我们验证了所有 10 根针都在上下文中,并且我们 记录 了插入的针顺序
* Figs
* Prosciutto
* Smoked applewood bacon
* Lemon
* Goat cheese
* Truffle honey
* Pear slices
* Espresso-soaked dates
* Gorgonzola dolce
* Candied walnuts 上下文中放置的 10 根针的顺序
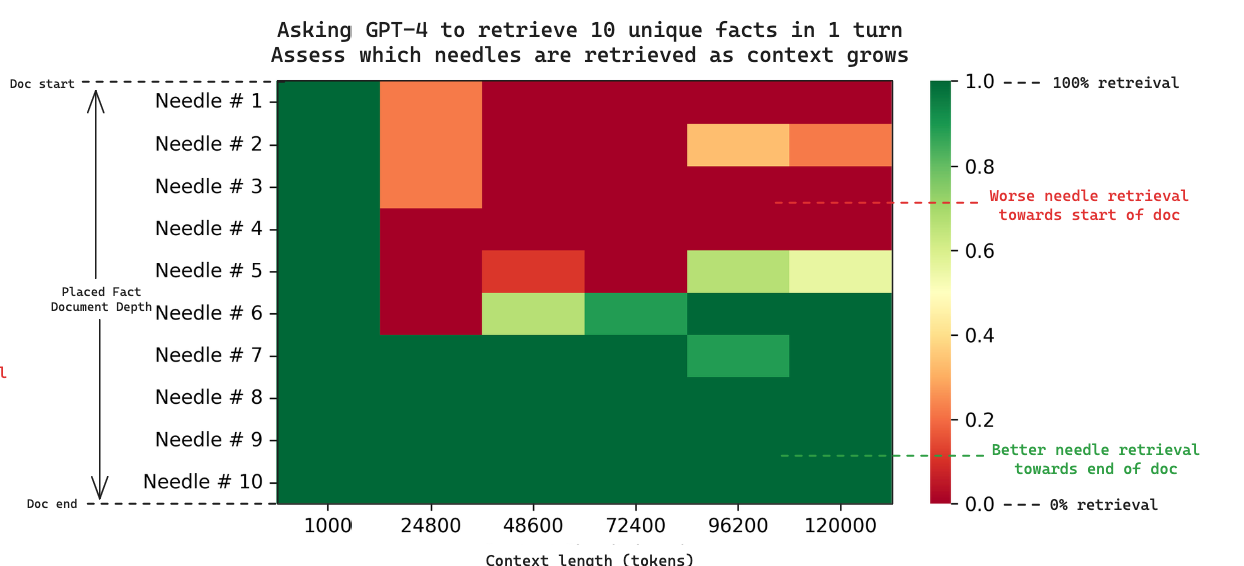
由此我们可以确认,生成内容中的四种 秘制配料 是放置在我们上下文中的 最后四根 针。这引发了一个关于 检索失败地点 的有趣观点。Greg 的 单针 分析表明,当针放置在文档开头附近时,GPT-4 检索会失败。
因为我们记录了每根针的放置位置,所以我们也可以探索这一点:下面的热图显示了 10 根针检索与上下文长度的关系。每列都是一个单独的实验,当我们要求 GPT-4 在上下文中检索 10 根针时。
随着上下文长度的增加,我们也看到文档开头的检索失败。在多针情况下,这种效应似乎比单针情况(对于 GPT-4,大约从 73k tokens 开始)更早开始(大约从 25k tokens 开始)。
GPT-4 检索与推理
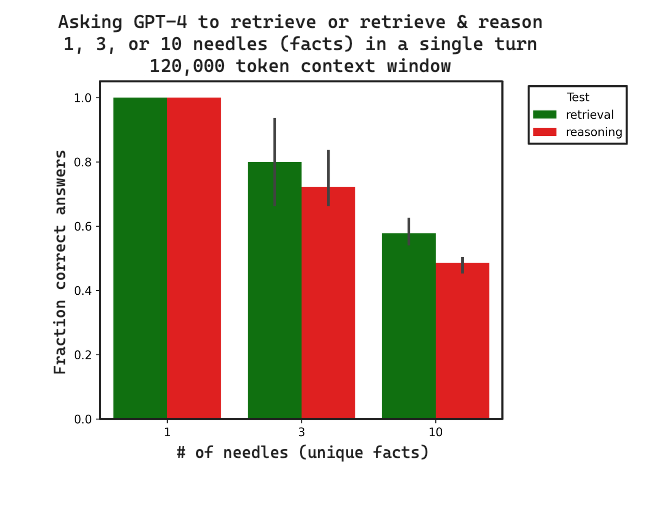
RAG 通常侧重于检索多个事实(来自文档的索引语料库),然后对它们进行推理。为了测试这一点,我们构建了 3 个数据集,通过要求提供所有秘制配料的 首字母,在上述数据集的基础上进行构建。这需要检索配料并对它们进行推理以回答问题。
multi-needle-eval-pizza-reasoning-1- 此处multi-needle-eval-pizza-reasoning-3- 此处multi-needle-eval-pizza-reasoning-10- 此处
请注意,这是一种极其简单的推理形式。对于未来的基准测试,我们希望包含不同级别的推理。
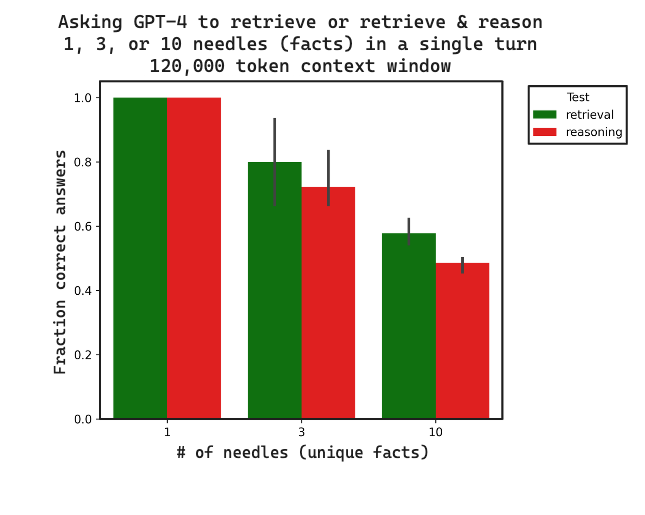
我们比较了检索和 检索 + 推理 之间 3 个副本的正确答案比例。带有跟踪的所有数据都 在此。随着上下文长度的增加,检索和推理的性能都会下降,推理落后于检索。这表明检索可能会设置推理性能的上限,正如预期的那样。
结论
长上下文 LLM 的出现非常有前景。为了使用它们代替或与外部检索系统一起使用,至关重要的是要了解它们的局限性。多重针 + 推理 基准测试可以表征长上下文检索相对于使用传统 RAG 方法的性能。
我们可以得出一些一般性见解,但还需要进一步测试