
编者按:这篇文章由 NeumAI 团队撰写,并从他们的博客交叉发布。对于许多构建者来说,高效地保持源数据相关且最新是一个挑战。对于那些基于像团队文档这样不断变化的数据源进行构建的团队来说,尤其令人痛苦(我们经常看到这种用例)。继我们昨天关于使摄取管道更具生产就绪性的博客之后,我们非常高兴强调这一点,因为它延续了这一思路。它在摄取管道上增加了调度和编排,其中一部分由 LangChain 文本分割器提供支持。
上周,我们发布了一篇关于使用数千个文档进行问答以及 Neum AI 如何帮助开发者构建大规模 AI 应用以支持该场景的博文。在这篇文章中,我们想更深入地探讨构建大规模 AI 应用的一个常见问题:如何以经济高效的方式保持上下文更新。
简介
首先让我们设置一些上下文(看看我们在这里做了什么 ;))。数据是构建 AI 应用最重要的部分。如果您用于训练模型的数据质量低下,那么您的模型性能将很差。如果您用于提示的数据质量低下,那么您的模型响应将不准确。关于数据为何重要的例子还有很多,但数据确实是提高我们 AI 模型准确性的基础部分。
具体来说,在这里,让我们深入探讨上下文。许多人都做过聊天机器人,其中将大量的提示传递给模型。对于几个原因,这可能会变得有问题。
- 您可能会达到上下文限制,具体取决于您使用的模型
- 您传递的令牌越多,您的操作成本就越高
因此,人们开始在提示中包含上下文,这些上下文是根据用户的查询获取的,以便仅将相关信息的子集传递给模型,使其能够准确执行。这也称为检索增强生成(RAG)。那些构建过这个的人都知道我在说什么,但如果您不了解,您可以查看 Pinecone 和 LangChain 的这两篇博文以获取更多信息。
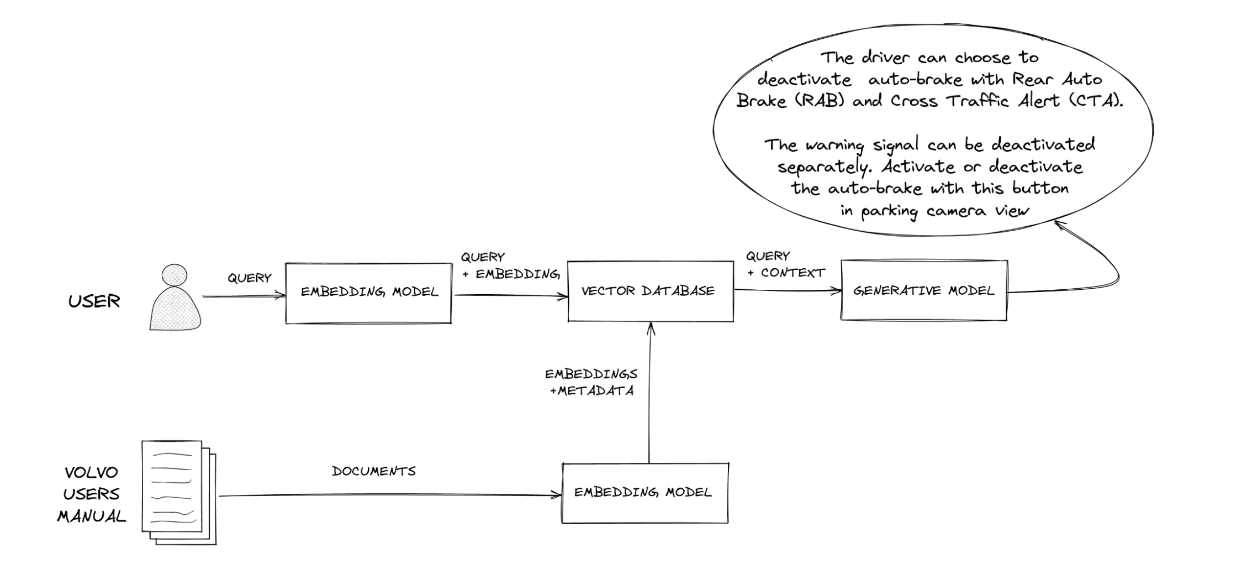
似乎没有太多人谈论的一个问题是此上下文的相关性如何。
相关且最新的上下文
想象一下,您正在创建一个基于不断变化的数据源(如餐厅的菜单或一些团队文档)的聊天机器人。您可以使用 之前的文章 中解释的一些库和工具轻松构建聊天机器人 - 例如 LangChain、Pinecone 等。我不会深入太多细节,但在高层次上,它大致是这样的
- 获取您的源数据
- 使用一些嵌入模型对其进行向量化处理(这至关重要,以便每当我们将上下文带入提示时,基于用户查询的“搜索”都是语义化和快速的)
- 将上下文带入您的模型(例如 GPT-4)的提示中并运行模型。
- 输出给用户
这提出了一个简单的问题。如果您的源数据发生变化怎么办?
可能是餐厅不再提供菜单中的某项商品。内部文档或维基刚刚更新了一些新内容。
我们的聊天机器人会以高精度响应吗?
很可能不会。除非您有一种方法为您的 AI 模型提供最新的上下文,否则它可能不会知道意大利辣香肠披萨已不再可用,或者团队新成员入职的文档已更改。它将以之前存储在向量存储中的任何上下文(甚至没有任何上下文!)进行响应。
进入 Neum
使用 Neum,我们会自动同步您的源数据和您的向量存储。这意味着每当 AI 应用程序想要查询向量数据库以进行语义搜索或将上下文带入 AI 模型时,信息将始终是最新的。重要的是要注意,您的模型质量还取决于您如何向量化数据。在 Neum,我们利用不同的 LangChain 工具根据用例对源数据进行分区。
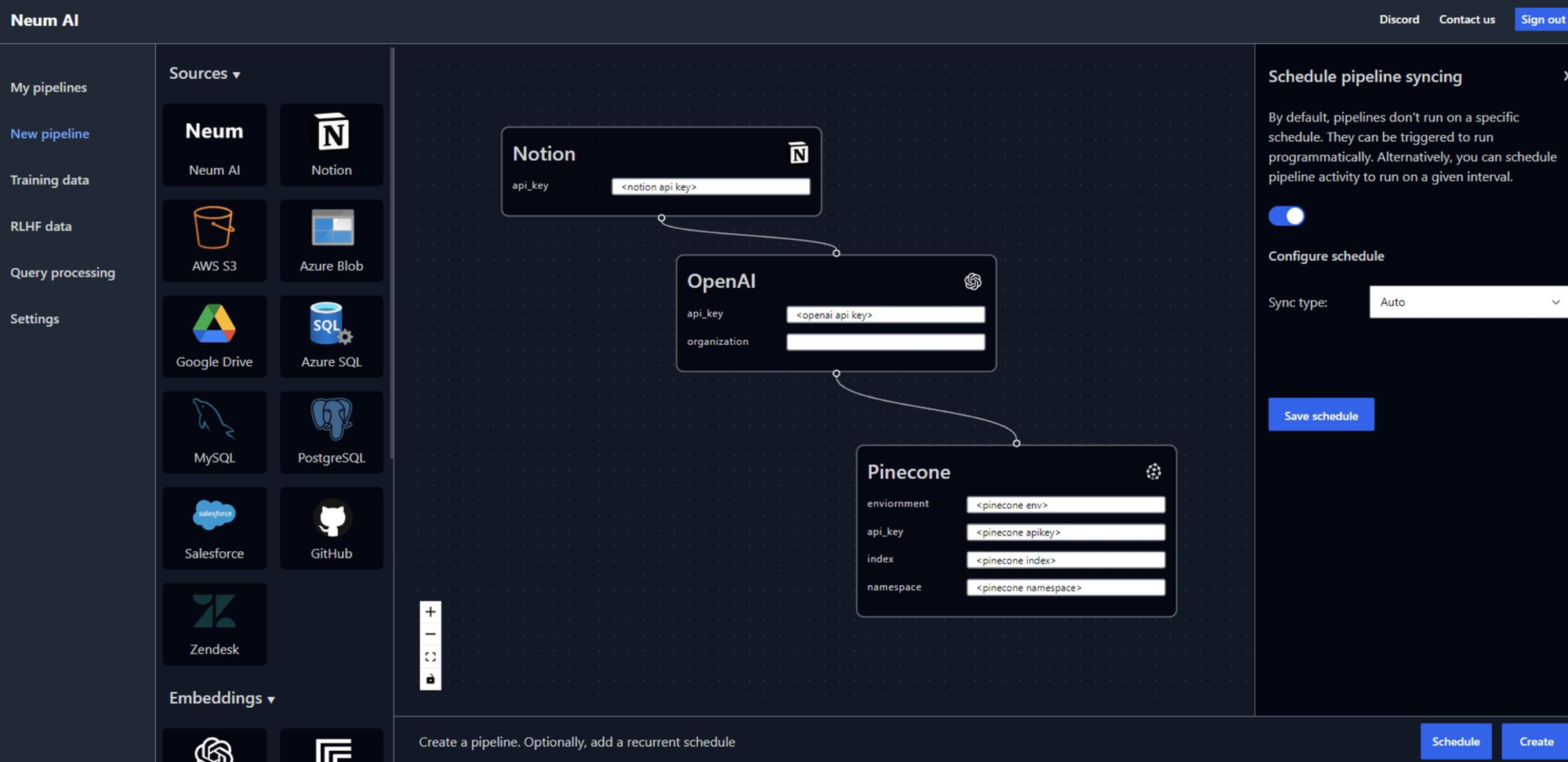
这些是为 LLM 数据构建此同步所需的首要事项。
- 设置同步源所需的基础设施
- 设置您的调度程序或实时管道以更新数据
- 处理在任何给定点出现问题时的错误
- 最重要的是,高效地向量化以降低成本
现在,让我们简要谈谈成本。
OpenAI 嵌入定价模型目前为每 1k 个令牌 0.0001 美元。这看起来可能不多,但大规模来说,大致相当于每 TB 数据 1 万美元。如果您的源数据不大,您可以通过不断地向量化并将数据存储在向量存储中来解决问题。
但是,如果您有大量文档怎么办?如果您在数据库中有数百万甚至数百万行怎么办?始终向量化所有内容不仅效率低下,而且成本非常高昂!
在 Neum,我们开发了技术来帮助检测差异,并且只向量化必要的信息,从而以高效且节省成本的方式保持上下文最新。
眼见为实
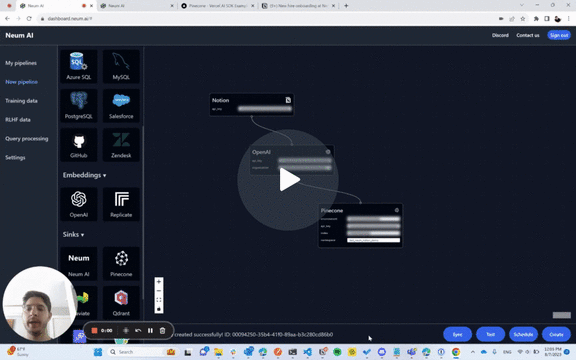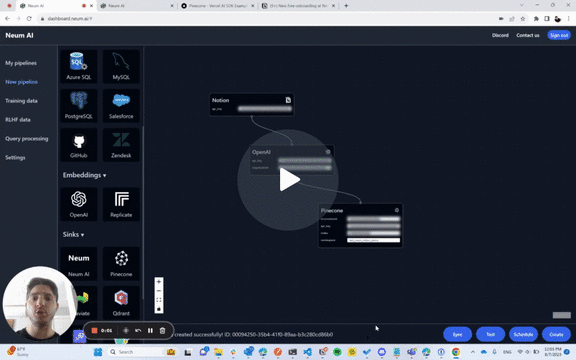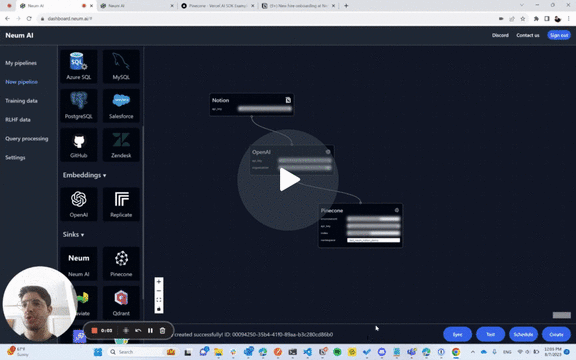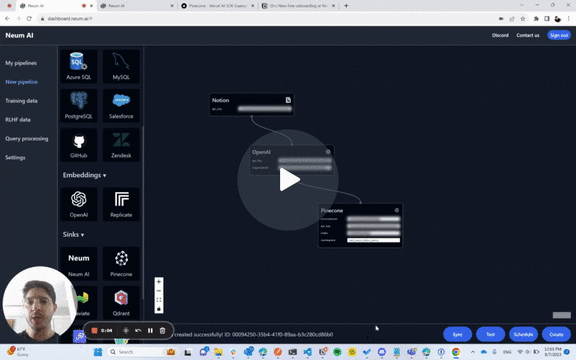
为了证明这一点,我们为我们的 Notion 工作区创建了一个示例聊天机器人,该聊天机器人会随着 Notion 内容的更新而自动更新。它允许用户提问,并在内部发生更改时获得最新的响应。该示例使用 Vercel 作为前端,Pinecone 作为向量存储构建。在内部,Neum 利用 LangChain 的文本分割器工具。
在幕后,Neum 不仅确保提取、嵌入更新并将其加载到 Pinecone 中,而且还确保我们仅更新需要更新的数据。如果 Notion 工作区的某个部分没有更改,我们不会重新嵌入它。如果某个部分已更改,则会重新嵌入它。这种方法通过提供最新的数据来提供更好的用户体验,并通过仅在需要时使用资源来提高成本效益。
观看下面的 2 分钟视频,深入了解其工作原理!
如果您对这些主题感兴趣,可以联系 founders@tryneum.com!