三周前,OpenAI 举办了一场备受期待的开发者日活动。他们发布了大量新功能。对我来说,其中最有趣的两个是 Assistants API 和 GPTs。在我看来,这两者代表了相同的押注——押注于特定的、类代理的、封闭的“认知架构”。它们吸引了不同的最终用户,但都表明了 OpenAI 推动应用程序朝着这种特定认知架构发展的雄心。在 LangChain,我们相信一个由 LLM 驱动的类代理系统能够真正改变世界。然而,我们认为实现这一目标的途径是让公司能够控制他们的认知架构。今天,您可以使用像 OpenGPTs 这样的项目来实现这一点——OpenGPTs 是 Assistants API(和 GPTs)的开放、可编辑和可配置的版本。
GPTs 和 Assistants API
在这两者中,GPTs 可能是互联网上讨论更多的一个。它们提供了一种(很大程度上)无需代码的方式来创建您自己的“GPT”。这些 GPT 可以通过自定义指令、自定义知识和自定义函数进行定制。这些 GPT 似乎是对应用商店的第二次尝试,是对插件的跟进(插件 - 用 Sam Altman 自己的话来说 - 没有找到产品市场契合度)。
Assistants API 是这个想法更以开发者为中心的版本。Assistants API 是一个有状态的 API,允许存储之前的消息、上传文件、访问内置工具(代码解释器),并且可以用于控制其他工具(通过函数调用,开发者在其中指定要调用的函数,然后可以在客户端执行该函数)。
认知架构
从底层来看,这两者都代表了一种类似的“认知架构”。在这里,我使用认知架构来描述 LLM 应用程序的编排。我第一次听到这个术语是由 Flo Crivello(Lindy 的创建者,一家自主代理初创公司)使用的,我认为这是一个非常棒的术语。
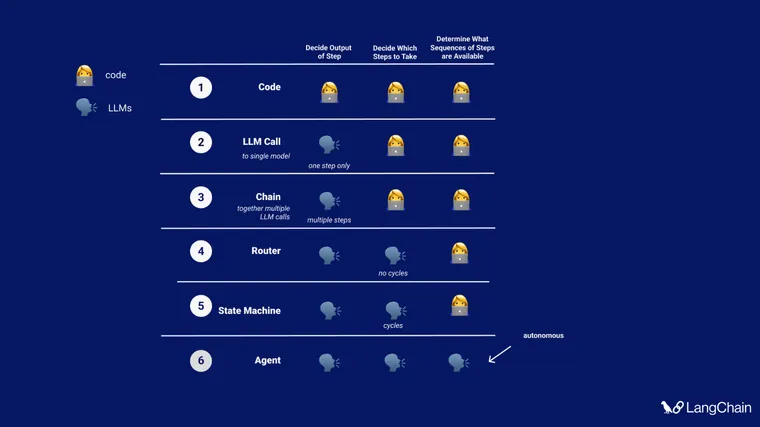
在 LangChain,我们已经思考认知架构一段时间了。在最近的 TedAI 演讲(视频尚未发布)中,我谈到了我们看到开发者构建的不同级别的认知架构。这些包括
- 单次 LLM 调用,仅确定应用程序的输出
- LLM 调用链,仍然仅确定应用程序的输出
- 使用 LLM 作为路由器,以选择要使用的操作(工具、检索器、提示)
- 状态机 - 使用 LLM 在步骤之间路由,在某种循环中,但允许的转换选项仍然在代码中枚举
- 代理 - 移除大量脚手架,以便转换选项完全由 LLM 确定
代理
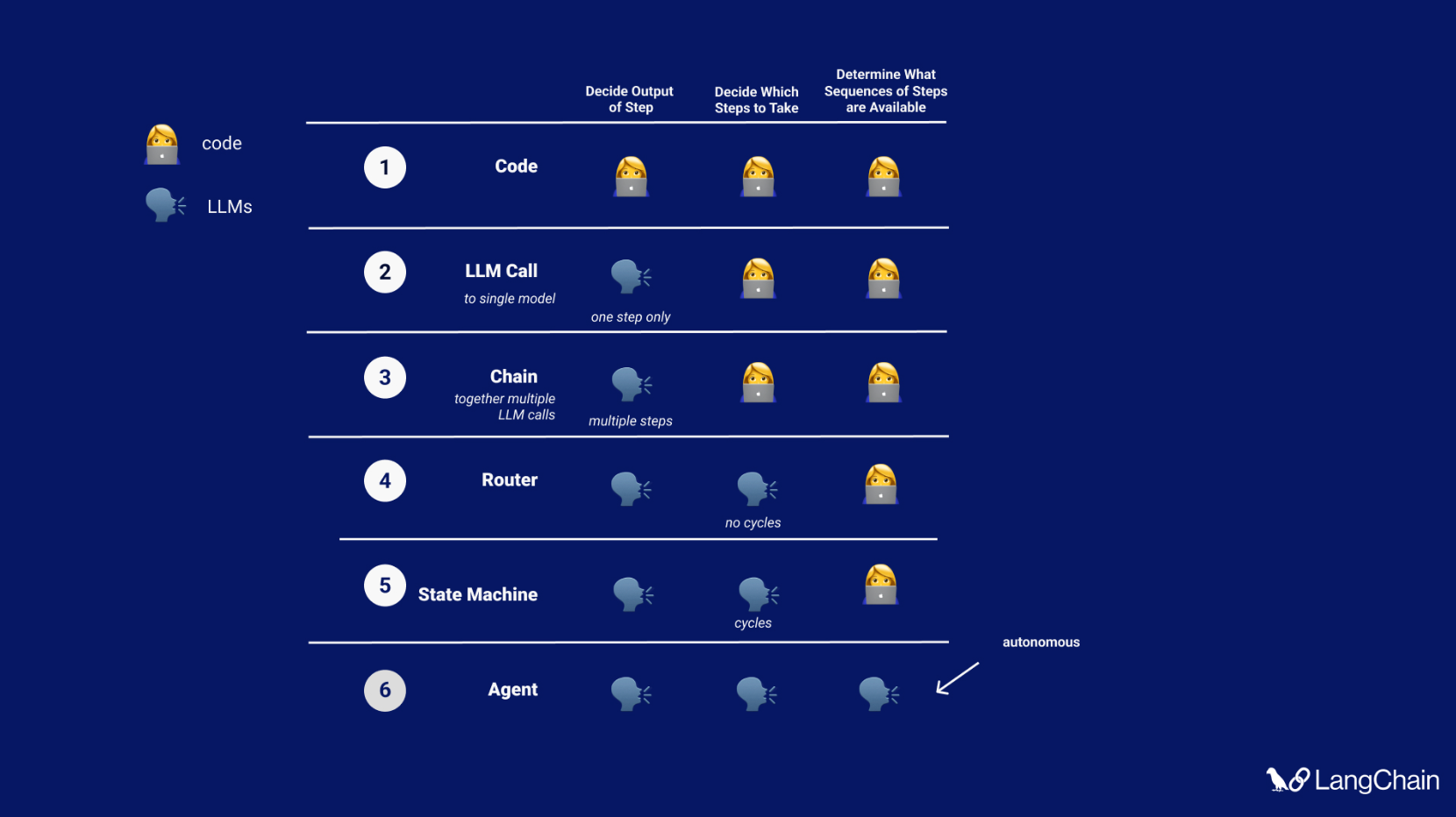
Assistants API 和 GPTs 都是上述“代理”认知架构的示例。Sam Altman 甚至在宣布它们时使用了完全相同的术语(“代理”)。尽管代理可能是一个过载的术语,用于描述各种不同的应用程序,但 OpenAI 对该术语的使用在很大程度上与我们的理解一致:仅使用 LLM 来定义转换选项。
这种应用程序在实践中是什么样的?这最好被认为是一个循环。给定用户输入,将进入此循环。然后调用 LLM,产生对用户的响应或要采取的操作。如果确定需要响应,则将其传递给用户,并且该周期结束。如果确定需要操作,则执行该操作,并进行观察(操作结果)。该操作和相应的观察结果被添加回提示符(我们称之为“代理草稿纸”),并且循环重置,即再次调用 LLM(使用更新的代理草稿纸)。
在高层次上,这就是 GPTs 正在做的事情。当他们调用您给他们的工具(或内置工具,如检索或代码解释器)时,您可以在屏幕上看到一个旋转的小部件。这表示正在执行的操作,GPT 正在等待观察结果。在某个时候,它只是用文本响应 - 没有要采取的操作 - 并且循环结束。
Assistants API 也是如此。唯一的区别是 API 不会为您调用工具 - 除非它是内置工具,如检索或代码解释器。相反,它会响应某种类型的消息,告诉您应该调用哪些工具(以及这些工具的输入应该是什么),然后等待您在客户端调用工具并将结果传回。
这种“代理”认知架构在过去一年半中一直在发展。AI21 Labs 在一年半前发布了他们的 MRKL 论文。ReAct 提示策略(一年多前发布)是一种特殊的提示策略,可以实现这种类型的架构。我们大约在一年前将 ReAct 纳入 LangChain,并迅速扩展到更通用的零样本提示策略。AutoGPT 大约在九个月前突然出现,使用了相同的认知架构,但赋予它更多工具、更持久的记忆,以及通常更大的任务来完成。
OpenAI 正在进行的押注
我非常有兴趣看到 OpenAI 如何如此 heavily 倾向于代理,因为根据所有说法,这种认知架构对于严肃的应用程序来说还不够可靠。他们比任何人都更有优势来使其工作——毕竟他们控制着底层模型。但这仍然是一个赌注。他们押注随着时间的推移,困扰代理的问题将会消失。
我们看到的大多数真正有用的“自主代理”在两个关键方面有所不同。
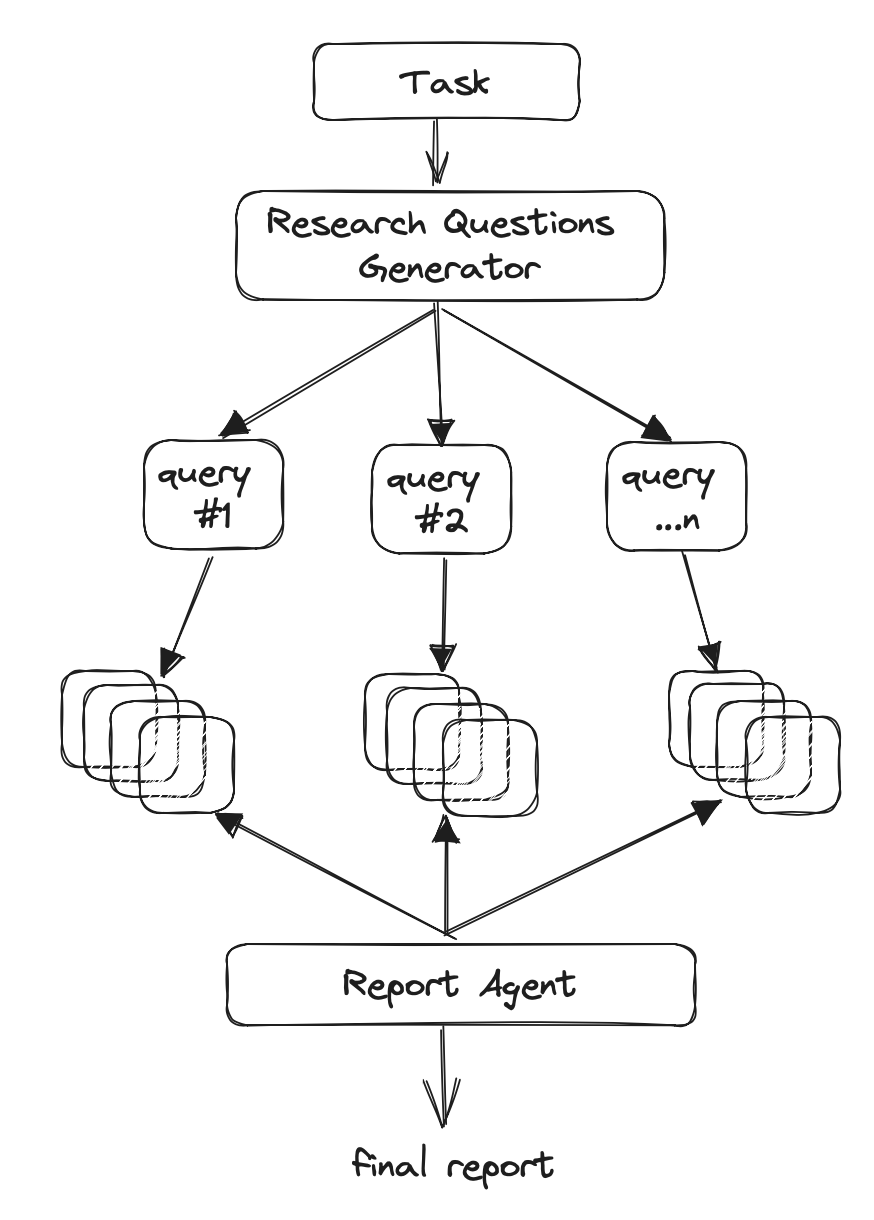
首先,许多实际上不是这种“代理”认知架构,而是更像是精心设计和复杂的链条,或者更类似于“状态机”。这方面的两个很好的公开例子是 GPT-Researcher 和 Sweep.dev。
我们曾多次撰写关于 GPT-Researcher 的文章 多次 次,并于上周与他们合作发布了一个 LangChain 模板。它们是少数几个能够产生有价值结果的复杂 LLM 驱动应用程序之一,但它们的认知架构更像是一个复杂的链条。如果我们看一下下面的图表,我们可以看到它在一个方向上流动。它执行了许多复杂的步骤,但以定义的方式:它首先生成子问题,然后获取每个子问题的链接,然后总结每个链接,然后将摘要组合成一份研究报告。
Sweep.dev 是另一个很好的例子。他们在夏天写了一篇 博客,描述了他们的认知架构,包括一个非常棒的图表。

显然存在明确定义的转换和步骤。首先,进行搜索。然后生成计划。然后执行计划。然后有一个验证步骤:如果通过,则创建一个 PR,Sweep 完成。如果失败,则制定一个新的计划。这是一个非常清晰的状态机,其中不同状态之间存在明确定义的转换。
我们合作的许多其他构建者和团队都有复杂的链条/状态机为其应用程序提供动力。
对于使用更类似于这种代理架构的应用程序,它们与 GPTs 的另一个不同之处在于:如何向代理提供上下文。
我正在与 Flo Crivello 聊天讨论认知架构,他提出了一个观点,即代理架构中的一个区别是如何向代理提供上下文。请记住,我们描述大多数有趣的 LLM 应用程序的方式是“上下文感知的推理应用程序”。
代理拉取上下文是什么意思?这意味着代理决定它需要什么上下文,然后请求它。这通常通过工具发生。作为一个具体的例子,一个旨在与 SQL 数据库交互的代理可能需要知道 SQL 数据库中存在哪些表。因此,我们可以给它一个返回数据库中表列表的工具,它可以开始时调用该工具。
相反,当上下文被推送到语言模型时,它被编码到应用程序的逻辑中,即应该获取特定的上下文片段并将其推送到提示符中。在上面的 SQL 代理示例中,这将对应于提前自动获取 SQL 表并将它们插入到提示符中。
大多数使用代理架构的应用程序都有大量的推送上下文。作为一个例子,LangChain 中的 SQL 和 Pandas 代理将表模式作为系统消息的一部分。作为另一个例子,Rubrics 团队为 Cal.com 构建的代理在 提示符中推送了大量的用户信息。
这种上下文的推送与拉取再次为开发者提供了更多控制。它允许我们强制执行在 LLM 决定做什么时哪些上下文是相关的。具体来说,知道哪些上下文最相关,如何获取该上下文,以及如何提供它,这些小的决策可以对质量和性能产生很大的影响。
GPTs——以及在某种程度上,Assistant API——在很大程度上为应用程序提供了不受约束的代理架构,这种架构更多地依赖于根据需要拉取上下文。这对于快速入门或简单任务来说可能很棒,但对于更复杂的用例,没有什么可以替代控制适合手头问题的认知架构。
开放与封闭
除了认知架构的选择之外,Assistants API 和 GPTs 的另一个显着属性是认知架构本身是封闭的。我们不知道底层发生了什么。我们不知道确切的算法。我们不知道为了管理聊天历史的上下文做了什么。我们不知道为了检索做了什么。
现在我们可以对这两者进行猜测。但是,随着他们添加越来越多的东西,并且它变得越来越复杂,它将变得越来越像一个黑匣子。
我敢打赌,随着时间的推移,这将成为比模型本身更大的讨论话题。一年前,大多数新功能(而且我敢打赌,内部的大部分重点)都放在了更好的模型上。现在,核心模型改进与弄清楚如何以代理方式最好地连接它们之间似乎是 50/50 的比例。作为这种重要性的更多证据,Karpathy 的 Twitter 动态(所有 AGI 事物的权威阅读清单)越来越倾向于将 LLM 视为操作系统。就在过去的这个周末,他发布了一个关于此的 精彩视频。
我完全期望这种趋势会继续下去,并且 OpenAI(以及其他实验室)会在模型周围的平台和工具上投入更多,而不仅仅是模型本身。通往 AGI 的道路不仅仅在于更好的模型——还在于将它们连接到周围环境。随着这些实验室的重点转移,我期望——并且希望——围绕开放与封闭的讨论不仅发生在模型上,也发生在认知架构上。
认知架构能让你的啤酒更好喝吗?
Jeff Bezos 有一句名言,说要 只做能让你的啤酒更好喝的事情。这指的是早期的工业革命,当时啤酒厂也在自己发电。啤酒厂酿造好啤酒的能力实际上并不取决于他们的电力有多么与众不同——因此,那些外包发电并更多关注酿造的啤酒厂跃升到了优势地位。
认知架构也是如此吗?控制你的认知架构真的能让你的啤酒更好喝吗?目前,我强烈认为答案是肯定的,原因有两个。首先:让复杂的代理真正发挥作用非常困难。如果你的应用程序依赖于代理工作,并且让代理工作具有挑战性,那么几乎根据定义,如果你能做得好,你就会比你的竞争对手更有优势。第二个原因是,我们经常看到 GenAI 应用程序的价值与认知架构的性能密切相关。许多当前的公司都在销售用于编码的代理,用于客户支持的代理。在这些情况下,认知架构就是产品。
最后一个原因也是我很难相信公司愿意锁定在由一家公司控制的认知架构中的原因。我认为这与云甚至 LLM 的锁定不同。在这些情况下,您正在使用云资源和 LLM 来构建或驱动特定的应用程序。但是,如果认知架构越来越接近成为一个完整的应用程序本身——您就不太可能希望将其锁定。
LangChain 如何适应
在 LangChain,我们相信一个由 LLM 驱动的类代理系统能够真正改变世界。然而,我们认为实现这一目标的途径是让公司能够控制他们的认知架构。
这需要大量的工程工作。我们正在构建工具来帮助解决这个问题。借助 LCEL,我们有一种灵活的方式可以将链条组合在一起。借助 LangChain,我们拥有 超过 600 个集成,可以完全灵活地选择您使用的模型/向量存储/数据库。借助 LangSmith,我们明确地专注于提供尽可能最佳的调试体验(因为这是大多数团队所在的地方),但我们也添加了管理工具(回归测试、监控、数据注释、提示中心),以帮助您在投入生产时管理这些系统。
我们最近还发布了 OpenGPTs。这是尝试重现与 Assistants API 以及 GPTs 相同的体验(我们对 GPTs 的实现只是 Assistants API 之上的一个简单 UI)。它是开源的,目前可配置为四个不同的模型提供商,并且可以轻松修改所使用的确切检索方法。
这仅仅是开始。