[编者注]: 这是 第二篇 希望是众多客座文章中的第二篇。我们旨在突出基于 LangChain 构建的创新应用。如果您有兴趣与我们合作撰写此类文章,请联系 harrison@langchain.dev。
作者: Parth Asawa (pgasawa@), Ayushi Batwara (ayushi.batwara@), Jason Ding (jasonding@), Arvind Rajaraman (arvind.rajaraman@) [@berkeley.edu]
问题
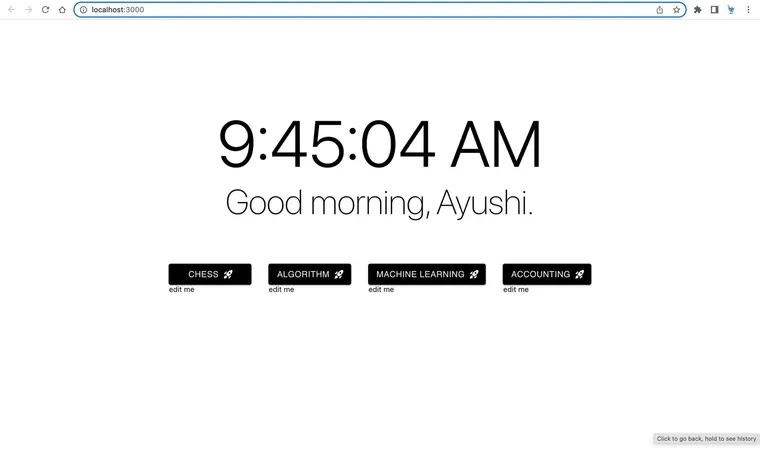
你的浏览器是否曾经像这样?

可能你曾有过这样的经历:在不同的窗口中打开了无数个标签页。为什么?因为我们从不只同时处理一件事情。作为学生,你可能会为不同的课程、不同的项目、活动等打开标签页;作为开发者,你可能会有不同的项目、计划标签页等等。你懂的。
你可能尝试过一种解决方案,那就是——标签页分组

但是这些标签页分组能实现什么呢?它们是否消除了它们试图消除的混乱?否。 相反,我们最终打开越来越多的标签页,希望有一天我们会用到某个早已遗忘的标签页中的某一段话。打开的标签页越多,上下文切换就越困难;这一切都只是混乱。
知识也会过时——很难不断跟踪所有标签页中的信息,而且在大多数情况下,我们会忘记它。没有知识中心化的概念。
使命
鉴于人们在当前浏览体验中面临的普遍问题,这种体验已经很长时间没有看到任何根本性的创新或变化,我们着手用 Origin 来颠覆它。
我们都是加州大学伯克利分校的学生,目前正在通过管理、创业和技术 (M.E.T.) 项目攻读 EECS 和工商管理双学位。
这个项目是我们在斯坦福大学年度黑客马拉松 TreeHacks 上用 36 小时构建出来的一个想法。
Origin 是一款应用程序,它可以获取你现有的浏览器历史记录,并将其组织成具有上下文感知的工作区,并自动生成摘要,然后提供特定于工作区的语义搜索、推荐系统和聊天机器人。
我们获取你的浏览历史记录,创建嵌入,并自动运行聚类算法来学习工作区。我们启用语义搜索,以便在工作区内轻松查找不同的 URL,这样你就永远不必害怕关闭标签页;然后,我们抓取网站以创建摘要,并为每个工作区使用高度特定的聊天机器人。这实现了知识中心化、轻松访问现有知识以及知识持久性——即使你关闭标签页,知识也会在那里。
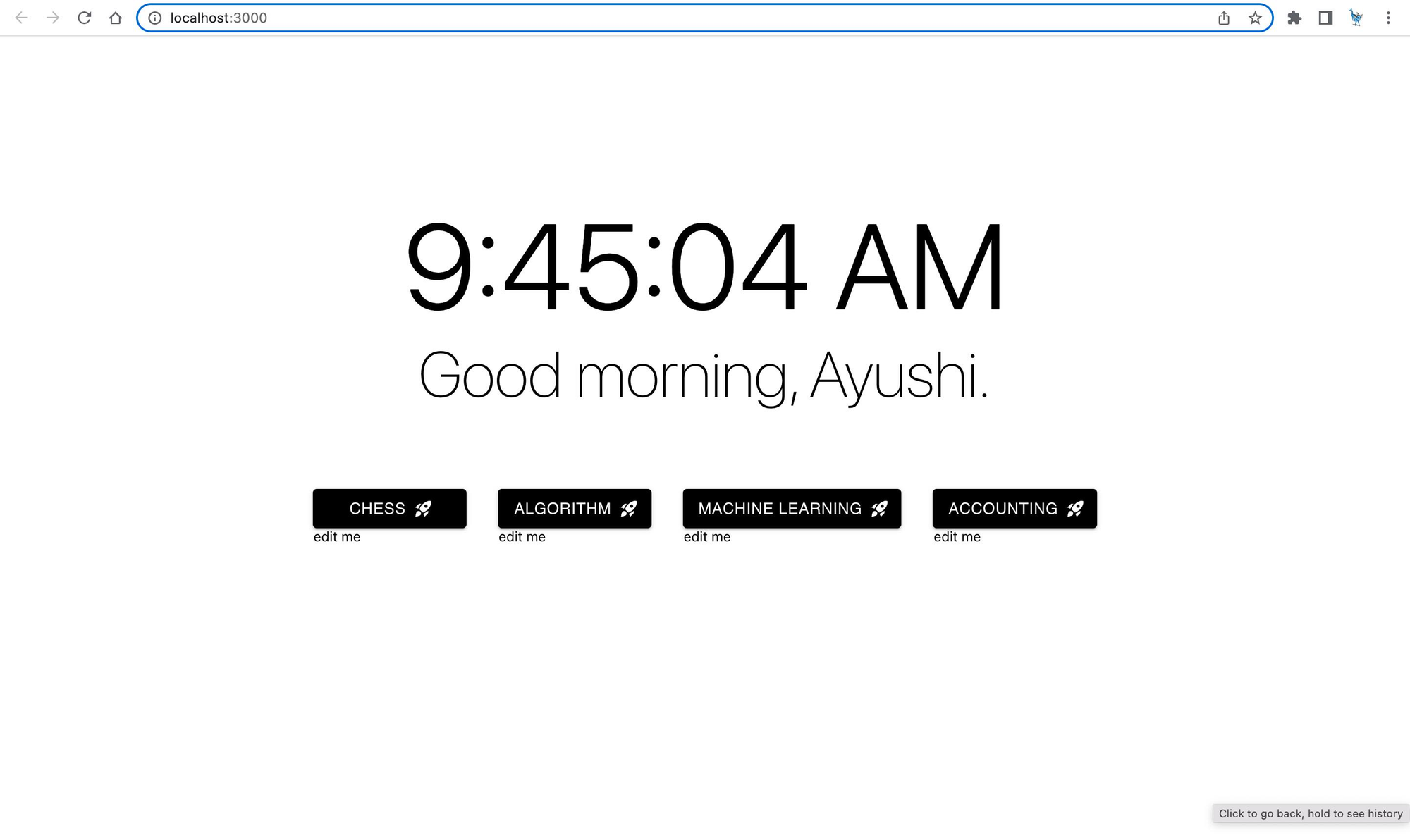
一个带有学习工作区的 V0 示例着陆页
技术深入
在这篇博文中,我们将主要关注 LangChain 如何融入我们的项目。顺便说一句,我们依赖一些传统的机器学习和统计技术,如 K-Means、协同过滤、现成的 HF 嵌入等,以整合诸如聚类、语义搜索、推荐系统等其他功能。
我们将 LangChain 融入到 MVP 浏览器体验的两个关键方面,这两个方面在你启动工作区时发生。
摘要
第一个是摘要。我们想要一种有效的方式来提醒用户他们在工作区中停留在哪里。使用 BeautifulSoup,我们开发了一个网络抓取工具来解析最近访问过的网站。从这些信息中,我们想要一种生成有效摘要的方法,并依赖 LangChain 的“map_reduce”摘要链,以使用 OpenAI 嵌入有效地总结大量文本。

聊天机器人
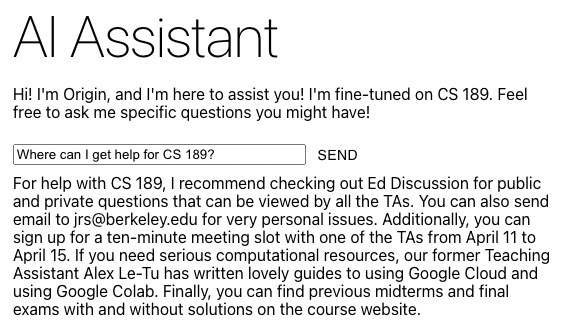
第二个是“与你的浏览器聊天”的能力。用户拥有分散在数百个标签页中的知识,但他们很少重新访问并花费时间来解析这些知识。但是,如果用户想要一种与他们的知识互动的简单方式,那是不存在的。然而,一个可以访问这些浏览器中所有信息的聊天机器人是存在的。使用相同的网络抓取工具,我们遵循 LangChain 的 Chat Your Data 示例设置的模型,并将文本分解成更小的块,然后将其嵌入并存储在向量存储中。然后,这个向量存储在服务时被用作 ChatVectorDBChain 的一部分,以便基于 OpenAI 模型为我们的聊天机器人提供上下文,并根据用户的工作区上下文生成高度特定的响应。
结论和未来方向
尽管进行了所有这些有趣的探索,但仍有很多事情需要考虑,这些事情在现实世界中是无法扩展的。例如,标准 GPT-3 模型的计算成本很高,而且在我们使用它们的方式中可能无法持续。我们认为,找出优化 LLM 使用成本的方法,对于任何将 LLM 集成到其产品中的公司来说,都将是一个有趣的挑战。
如果超越黑客马拉松项目,将其视为真正的产品,我们可能会从头开始重新设计,并专注于使一些关键技术特性和流程正确,以便在尝试添加一些更花哨的功能之前,它实际上提供了一个基准价值水平。以摘要工具为例,虽然这在当时很酷,但如果没有更多的选择性过滤和工程,实际上很难提取出对用户有用的工作区摘要。我们很高兴现在花一些时间思考这些更具挑战性的工程和设计问题——LangChain 绝对是一个会被使用的工具!
感谢阅读!请通过 LinkedIn/Twitter/Email (@berkeley.edu) 联系我们——我们很乐意收到你的来信!