评估模型输出是 LLM 应用程序开发中最重要的挑战之一。但是,对于许多任务(例如,聊天或写作),人类偏好很难编码在一组规则中。相反,对多个候选 LLM 答案进行成对评估可能是教导 LLM 人类偏好的更有效方法。
下面,我们将解释什么是成对评估,为什么您可能需要它,并提供一个示例演练,说明如何在您的 LLM 应用程序开发工作流程中使用 LangSmith 最新的成对评估器。
成对评估的起源
成对评估已开始在关于测试和基准测试 LLM 模型性能的对话中发挥重要作用。例如,来自人类反馈的强化学习(即 RLHF)在 LLM 对齐中采用了成对评估的概念。人类训练员会看到同一输入的成对 LLM 响应,并选择哪个更符合某些标准(例如,帮助性、信息性或安全性)。
最受欢迎的 LLM 基准测试之一,Chatbot Arena,也采用了这个想法:它为给定的用户提示呈现两个匿名的 LLM 生成结果,并允许用户选择更好的一个。虽然 Chatbot Arena 依赖于人类反馈进行成对评估,但也可以使用 LLM-as-a-judge 来 预测人类偏好 并自动化此成对评估过程。
尽管成对评估在公共基准测试和 LLM 对齐中很受欢迎,但许多用户可能不知道如何使用自定义成对评估来改进他们的 LLM 应用程序。考虑到这一限制,我们在 LangSmith 中添加了成对评估作为一项新功能。
LangSmith 中的成对评估器
LangSmith 的成对评估允许用户 (1) 使用任何期望的标准定义自定义的 LLM-as-judge 成对评估器,以及 (2) 使用此评估器比较两个 LLM 生成结果。 当您单击“数据集和测试”选项卡时,您将看到一个新的子标题“成对实验”,而不是选择要比较的运行。
这与比较视图有何不同?
您可能会问的一个问题是“这与比较视图有何不同?”
如果您错过了,几周前我们发布了改进的比较视图,用于 回归测试。这允许您比较两个运行并识别回归。成对评估在目标上是相似的,但在实现上却截然不同。
在之前的比较视图中,您将单独评估每个运行,然后比较分数。例如,您将给每个运行一个 1-10 分的等级(独立地),然后查找一个运行比另一个运行获得更高等级的情况。
成对评估同时查看结果。这允许您定义一个明确比较两个结果的评估器。然后,您将获得该对的分数。它不是单独为每个运行评分。
何时可能使用成对评估?
为了激发此功能,此视频 展示了一个与内容生成相关的常见用例。在此示例中,我们希望 LLM 生成引人入胜的推文来总结学术论文。我们构建了一个包含 10 篇不同论文的数据集作为示例 (此处) 并从 4 个不同的 LLM 生成了摘要。
由于没有我们希望 LLM 生成的单一“真实”论文摘要,因此我们使用了 标准评估器,并使用 此 评估提示,根据 5 个标准(例如,表情符号的使用、引人入胜的标题等)将摘要推文从 1(最差)到 5(最佳)进行评分。
我们在数据集中捕获了此 summary_engagement_score,如下所示。
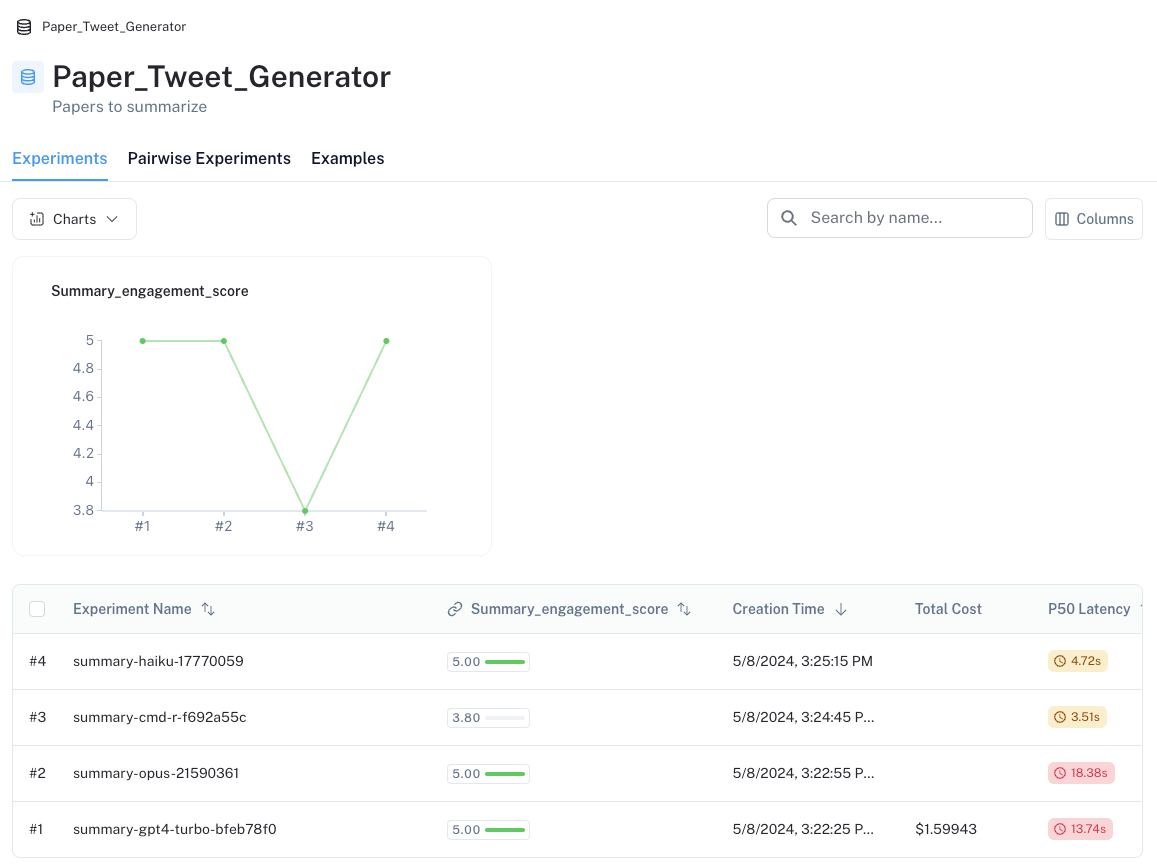
但是,这立即突出了一个问题:4 个 LLM 中的 3 个在我们的 summary_engagement_score 上都获得了满分,它们之间没有区别。孤立地看,可能很难定义一个区分各种 LLM 的标准评估器。但是,成对评估提供了一种替代方法来应对这一挑战。
使用自定义成对评估
如 视频(文档 此处)所示,我们在 LangSmith SDK 中使用自定义成对评估器,并在 LangSmith UI 中可视化成对评估的结果。为了将这些应用于上面提到的问题,我们首先定义一个 成对评估提示,该提示编码了我们关心的标准(例如,根据标题、项目符号等,两个推文摘要中哪个更引人入胜)。然后,我们只需对已在我们的数据集上运行的任何两个实验运行我们的自定义评估器 evaluate_pairwise(请参阅 此处 使用的完整代码)。
from langsmith.evaluation import evaluate_comparative
evaluate_comparative(
["summary-cmd-r-f692a55c", "summary-opus-21590361"],
evaluators=[evaluate_pairwise],
)
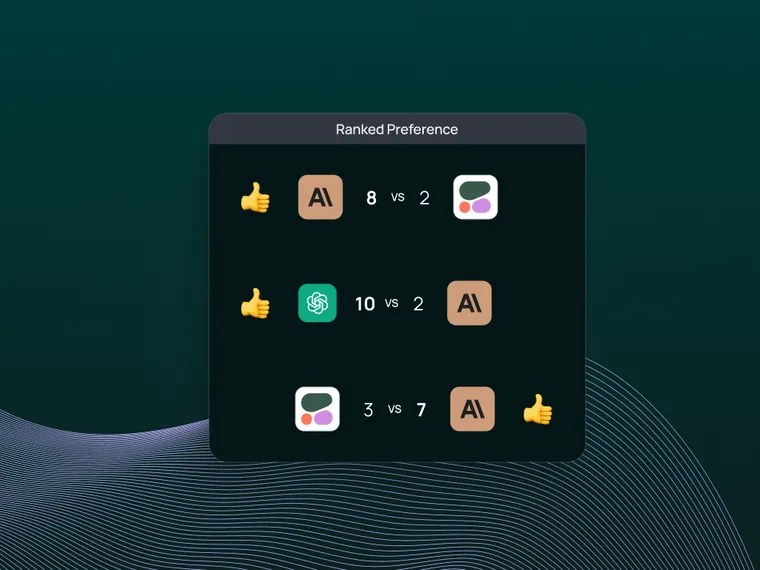
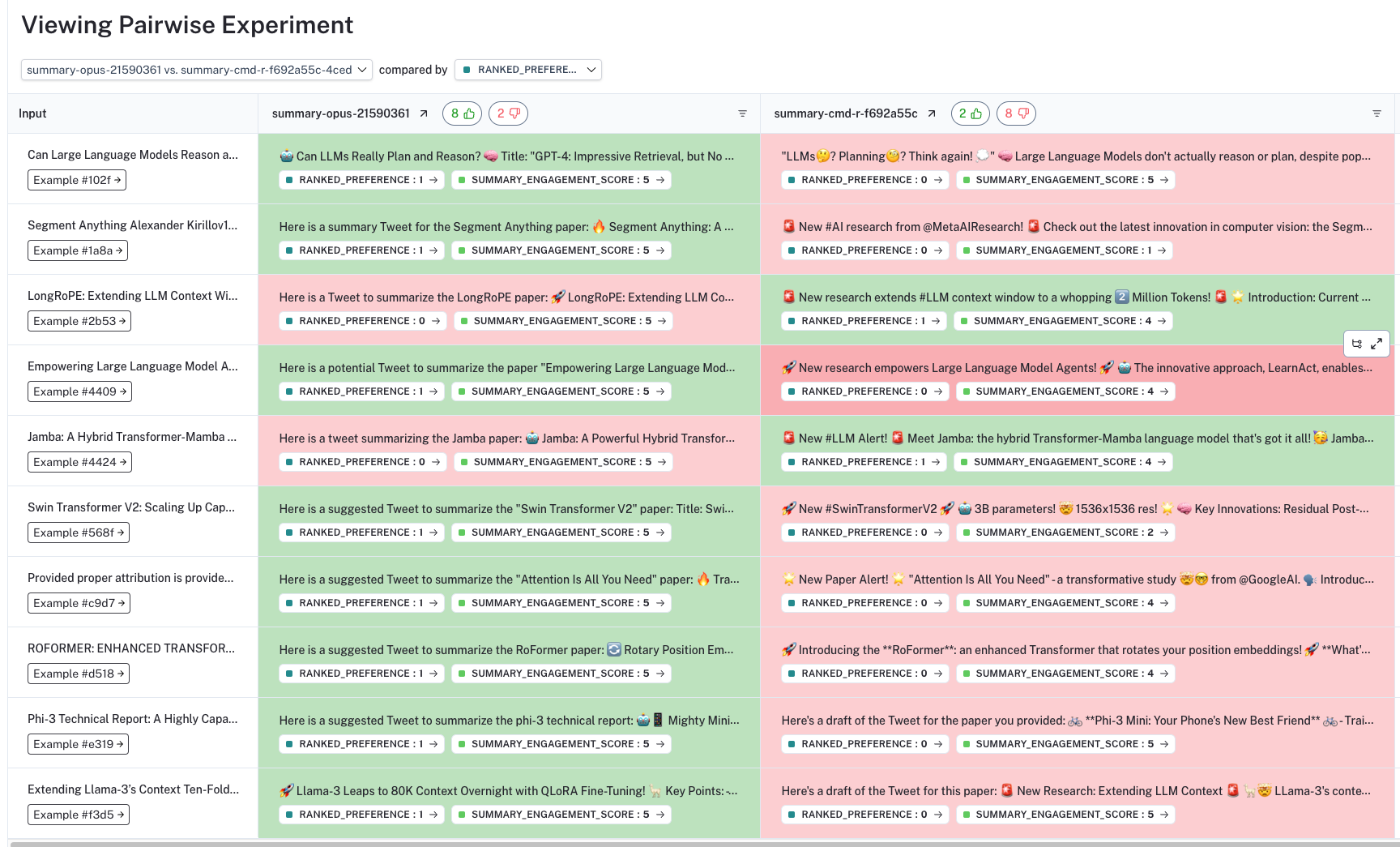
在 UI 中,我们将在数据集的“成对实验”选项卡中看到所有成对评估的结果。重要的是,我们看到成对评估显示出对某些 LLM 的明显偏好,这与独立的标准评估不同,后者几乎没有区分度。
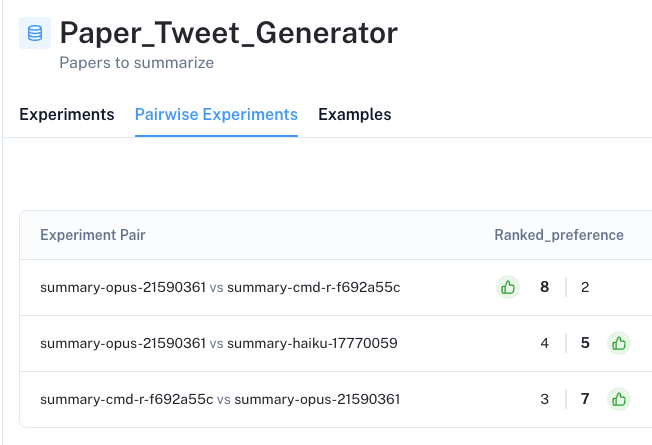
UI 允许我们深入研究每个成对实验,显示根据我们的标准首选哪个 LLM 生成结果(在列的顶部带有颜色和拇指)。通过单击每个答案下的 ranked_preference 分数,我们可以进一步深入到每个评估跟踪(请参见 此处 示例),其中提供了排名的解释(如 在我们的提示中 定义的)。
结论
许多 LLM 用例,例如文本生成或聊天,对于评估中使用的“正确”答案没有单一或特定的答案。在这些情况下,使用人类或 LLM 选择首选响应的成对评估是一种强大的方法。
在这篇博文中,我们展示了我们如何能够测试评估推文摘要生成的模糊任务,并揭示了独立评估标准的缺点。我们的 自定义成对评估器 允许我们直接比较我们的生成结果,从而突出显示模型之间的明显偏好。
要深入了解,请查看 我们的视频 和 关于成对评估的文档。您可以立即 试用 LangSmith,以进行强大的实验和评估,并支持提示版本控制、调试和人工注释 - 这样您就可以在构建 LLM 应用程序时获得生产可观察性。