重要链接
我们看到,语言模型最大的用例之一是 提取。 在这里,语言模型用于从非结构化文档中提取多条结构化信息。 开发者在此面临的最大挑战是让语言模型正确输出有效的 JSON。
OpenAI 在 2023 年初推出函数调用时,为此提供了巨大帮助。 从宏观层面来看,函数调用鼓励模型以结构化格式响应。 这主要被强调为语言模型正确调用函数的一种方式(当调用函数时,您需要正确格式的响应)。 然而,在许多其他地方,拥有正确结构化的响应也很有用 - 例如提取。 我们最近与吴恩达一起在 DeepLearningAI 课程 中详细介绍了这一点。
在 11 月 6 日的 OpenAI 开发者日上,他们发布了一种更新的函数调用方式,允许进行 并行函数调用。 这项新功能允许语言模型同时调用多个函数。 有关更多背景信息,您可以查看他们的发布博客 此处。
并行函数调用使提取 显著更容易。 在这篇博文的其余部分,我们将深入探讨什么是提取,使用旧的函数调用方式之前的样子,以及现在使用并行函数调用后的样子,为什么它 显著更容易 且 更强大(尽管它确实有一个缺点)。
什么是提取
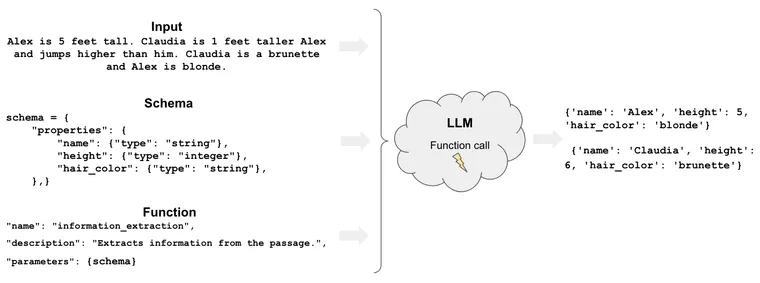
提取是从非结构化数据中提取结构化数据的过程。 一个具体的例子是实体提取。 正如 Sematext 解释 的那样
实体提取在搜索的上下文中,是找出查询应针对哪些字段的过程,而不是始终命中所有字段。 我们可能希望在搜索中引入实体提取的原因是为了提高准确率。 例如:当我们用户输入“Apple iPhone”时,我们如何判断其意图是运行“company:Apple”和“product:iPhone”? 而不是返回苹果形状的手机贴纸?
至关重要的是,这涉及到提取 多个 信息片段,可能属于 不同类型。
旧的函数调用
使用旧的函数调用,您一次只能获得一个函数调用返回。 这使得如果您想一次提取多条信息,您必须进行一些变通方法。 例如,假设您想提取以下信息片段
class Person(BaseModel):
name: str
age: int(请注意,我将其表示为 Pydantic 类 - 这只是构造最终传递到函数调用参数中的 JSON 的一种便利方法)
如果我只是将其直接作为函数传递给旧的 OpenAI 模型,它将永远只返回一条信息! 如果我想提取多条信息,这显然是不可接受的。
为了提取多条信息,我必须进行类似这样的变通方法
class Information(BaseModel):
people: List[Person]这将构造一个新的对象,该对象具有一个字段,该字段是 Person 对象列表。 这样,当 OpenAI 模型构造函数调用时,它将构造一个参数,该参数是人员列表。
这使得可以提取同一类型的多个元素,但它也带来了一个缺点。 如果我们想同时提取 Person 和不同类型的对象(例如 Location),我们将不得不进行更多更复杂的类型逻辑。 例如,它看起来会像这样
class Information(BaseModel):
info: List[Union[Person, Location]]这也将需要对语言模型的响应进行更复杂的解析逻辑。
并行函数调用
那么并行函数调用如何改进这一点呢?
它消除了我们必须做的许多复杂性和变通方法。 您不再需要创建那个丑陋的、多余的 Information 类 - 您只需将 Person 和 Location 直接作为函数传入,模型就会将它们作为单独的函数调用输出。 这是一个改进,因为它意味着
- 创建 LLM 输入所需的逻辑更少(更好的开发者体验)
- 传递给 LLM 的函数定义更简单(节省 token,不太可能混淆 LLM)
- LLM 需要产生的输出更简单(LLM 搞砸并输出不正确的 json 的机会更小)
- 解析 LLM 输出所需的逻辑更少(更好的开发者体验)
我们已将所有这些整合到一个简单的提取链中 - 您可以在此处查看。 该链的完整逻辑如下所示
# Create a prompt telling the LLM to extract information
prompt = ChatPromptTemplate.from_messages({
("system", _EXTRACTION_TEMPLATE),
("user", "{input}")
})
# Convert Pydantic objects to the appropriate schema
tools = [convert_pydantic_to_openai_tool(p) for p in pydantic_schemas]
# Give the model access to these tools
model = llm.bind(tools=tools)
# Create an end to end chain
chain = prompt | model | PydanticToolsParser(tools=pydantic_schemas)使用此链,我们现在可以执行以下操作
# Make sure to use a recent model that supports tools
model = ChatOpenAI(model="gpt-3.5-turbo-1106")
chain = create_extraction_chain_pydantic(Person, model)
chain.invoke({"input": "jane is 2 and bob is 3"})并获得
[Person(name='jane', age=2), Person(name='bob', age=3)]结论
虽然大多数人对使用函数调用创建代理感到兴奋,但在更通用地使用它来构建 LLM 的输出方面,存在一个非常真实(且非常有用)的用例。 其中一个用例是提取,但使用旧的函数调用,您必须进行一些变通方法才能使其工作。 使用并行函数调用,它变得显著更容易。 试试看!