我们从开发者那里听到的关于将应用程序投入生产的最大痛点是测试和评估。由于不断涌现的新模型、新的检索技术、新的代理类型和新的认知架构,这种困难显得尤为突出。
在过去的几个月里,我们已将 LangSmith 打造成进行 LLM 架构评估的最佳平台(测试对比视图,数据集管理)。今天,我们使共享评估数据集和结果成为可能,从而更轻松地实现社区驱动的评估和基准测试。我们还很高兴分享新的 langchain-benchmarks 包,以便您可以重现这些结果并轻松地试验您的架构。
测试共享使 LangSmith 上的任何人都可以轻松发布关于不同架构在同一组任务上表现的所有数据和指标。额外的好处是,我们不仅记录最终结果——每个评估结果都包含已测试链的完整伴随追踪信息。这意味着您可以超越聚合统计数据和系统级输出,查看不同系统在同一数据点上的逐步执行过程。
背景
在过去的一年中,使用 LLM 构建应用的工具和模型质量持续以惊人的速度提高。每周,开发者和研究人员都会提出数十种新的提示和组合技术,都声称具有卓越的性能特征。LangChain 社区实施了其中许多技术,从简单的提示技术(如 密度链 和 退后提示)到 高级 RAG 技术,一直到 RL 链、生成式代理和自主代理(如 BabyAGI)。仅对于结构化生成,我们(谢天谢地)已经从 情感提示 技术发展到微调的 API,如 函数调用 和 基于语法的采样。
随着 Hub 和 LangChain 模板 的发布,新架构的发布速度持续加快。但是,这些方法中哪一种能够转化为您的应用程序的性能提升?每种技术都假设了哪些权衡?
可能很难从噪音中分离出信号,而大量的选择使得可靠且相关的基准测试变得更加重要。在评估语言模型在通用任务上的表现时,公共基准测试(如 HELM 或 EleutherAI 的 Test Harness)是不错的选择。为了衡量 LLM 推理速度和吞吐量,AnyScale 的 LLMPerf 基准测试 可以作为指路明灯。这些工具非常适合比较语言模型的底层能力,但它们不一定能反映其在您的应用程序中的真实行为。
LangChain 的使命是尽可能简化 LLM 的构建过程,这意味着帮助您及时了解该领域相关的进展。LangSmith 的评估和追踪体验可帮助您轻松地在总体和样本级别比较各种方法,并使您可以轻松地深入研究每个步骤,以找出行为变化的根本原因。
借助公共数据集和评估,您可以查看任何参考架构在相关数据集上的性能特征,从而轻松地从噪音中分离出信号。
📑 LangChain 文档问答数据集
我们包含的第一个基准测试任务是 关于 LangChain 文档的问答数据集。这是一组我们根据 LangChain 的 python 文档 手工编写的问答对。编写这些问题是为了测试 RAG 系统正确回答问题的能力,即使答案需要来自多个文档的信息,或者当问题与文档的知识相冲突时。
作为初始版本的一部分,我们评估了在几个维度上有所不同的各种实现
- 使用的语言模型(OpenAI、Anthropic、OSS 模型)
- 使用的“认知架构”(对话式检索链、代理)
您可以查看上面的 链接 来查看结果,或继续阅读以下信息!
🦜💪 LangChain 基准测试
为了帮助您在问答数据集上试验自己的架构,我们发布了一个新的 langchain-benchmarks 包(文档 链接)。此软件包有助于在使用 LLM 构建应用时对关键功能进行实验和基准测试。除了正在发布的基准测试之外,还有 提取、代理工具使用 和 基于检索的问答。
对于每个数据集,我们都提供易于测试不同 LLM、提示、索引技术和其他工具的功能,以便您可以快速权衡不同设计决策中的利弊,并为您的应用程序选择最佳解决方案。
在这篇文章中,我们将回顾一些问答任务的结果,以展示它的工作原理!
比较简单的 RAG 方法
在我们的初始基准测试中,我们基于以下模板评估了 LLM 架构
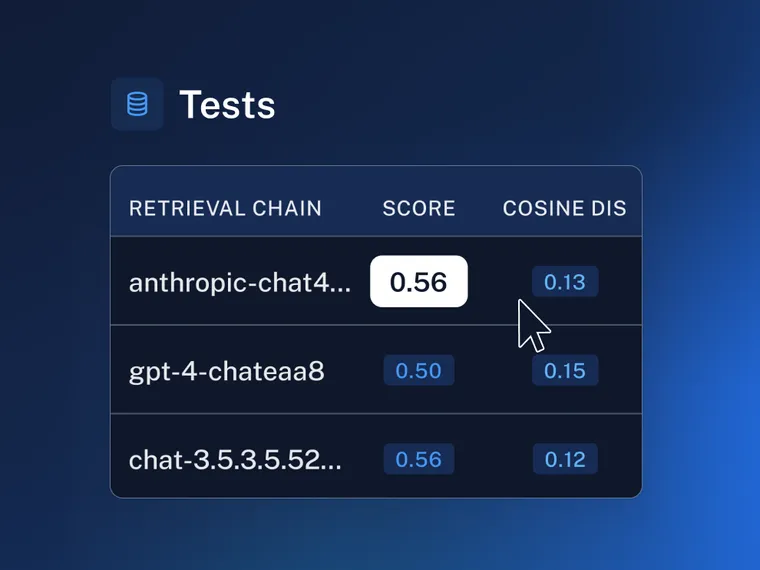
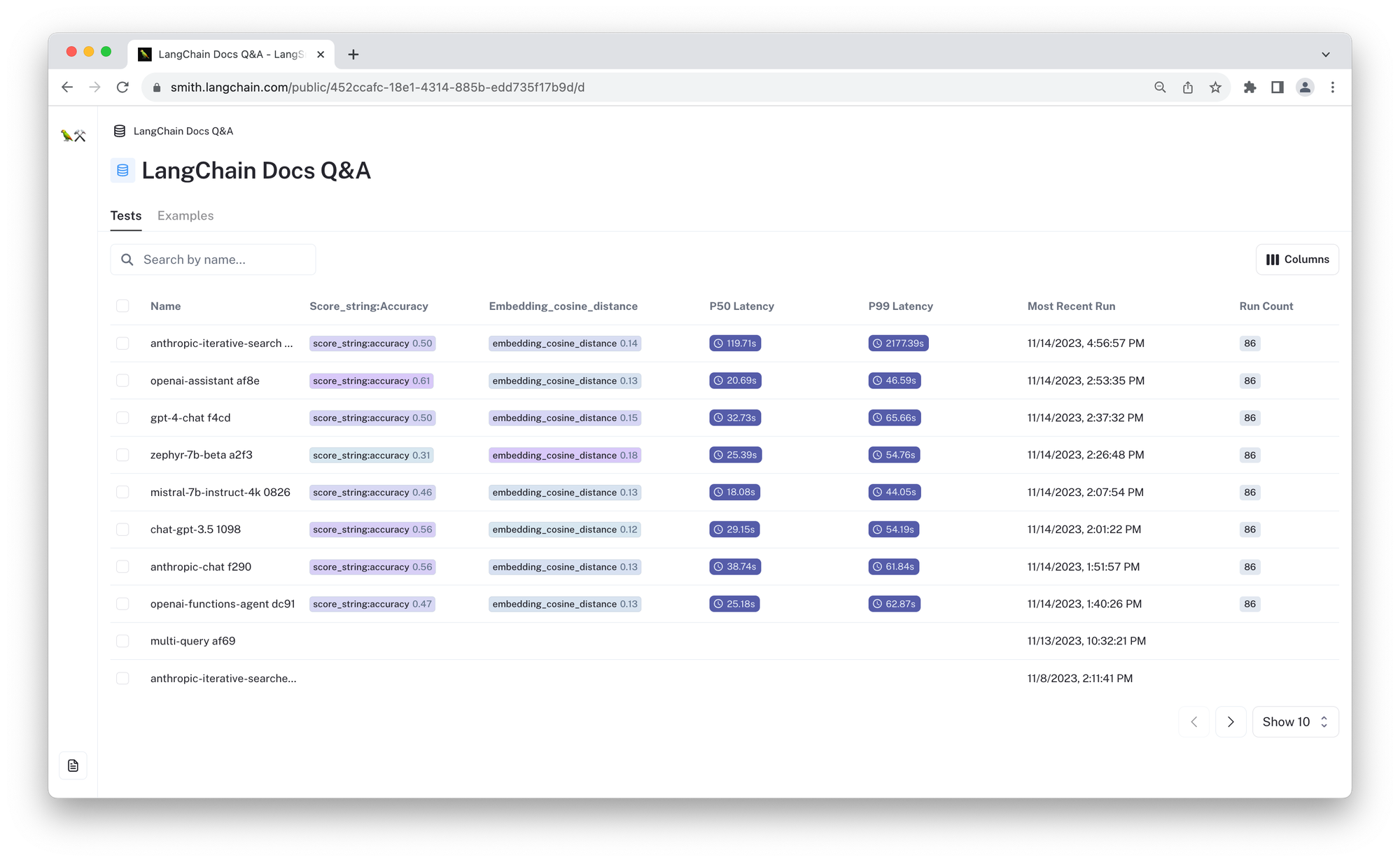
| 认知架构 | 测试 | 得分 ⬆️ | 余弦距离 ⬇️ | 🔗 |
|---|---|---|---|---|
| 对话式检索链 | zephyr-7b-beta a2f3 | 0.31 | 0.18 | 链接 |
| mistral-7b-instruct-4k 0826 | 0.46 | 0.13 | 链接 | |
| gpt-4-chat f4cd | 0.50 | 0.15 | 链接 | |
| chat-gpt-3.5 1098 | 0.56 | 0.12 | 链接 | |
| anthropic-chat f290 | 0.56 | 0.13 | 链接 | |
| 代理 | openai-functions-agent dc91 | 0.47 | 0.13 | 链接 |
| gpt-4-preview-openai-functions-agent 5832 | 0.58 | 0.142 | 链接 | |
| anthropic-iterative-search 1fdf | 0.50 | 0.14 | 链接 | |
| 助手 | openai-assistant af8e | 0.62 | 0.13 | 链接 |
上面的链接允许您查看每个配置的结果,并使用自动指标进行比较。对于这些测试,我们测量预测响应和参考响应之间的 余弦距离,以及使用 LangChain 基于 LLM 的 评分评估器 的准确性“得分”。对于准确性得分,数字越大越好 (⬆️),对于余弦距离,数字越小越好 (⬇️)。下面,我们将更详细地描述这些测试。请参阅此处用于评估器的提示 here。
对话式检索链
以下实验在简单的检索链实现中使用了不同的模型。输入查询直接使用 OpenAI 的 text-embedding-ada-002 进行嵌入,并从基于语义相似度的 ChromaDB 向量存储中检索出四个最相关的文档。我们在下面比较了以下 LLM
mistral-7b-instruct-4k 0826:应用开源 Mistral 7B 模型(具有 4k 上下文窗口)使用检索到的文档进行响应。此模型已使用指令调整进行适配。zephyr-7b-beta a2f3:应用开源 Zephyr 7B Beta 模型,它是 Mistral 7B 的指令调整版本,使用检索到的文档进行响应。chat-3.5-3.5 1098:使用 OpenAI 的gpt-3.5-turbo-16k使用检索到的文档进行响应。gpt-4-chat f4cd:使用 OpenAI 的gpt-4基于检索到的文档进行响应。anthropic-chat f290:使用 Anthropic 的claude-2基于检索到的文档进行响应。
代理
以下测试应用 agent 架构来回答问题。这些代理被赋予一个检索器工具,该工具包装了上面描述的相同向量存储检索器。代理可以直接响应或多次调用检索器并使用自己的查询来回答问题。在实践中,我们发现代理通常调用工具一次然后响应。
openai-functions-agent dc91:使用 OpenAI 的 函数调用 API(现在称为“工具调用”API)与文档检索器进行交互。在这种情况下,代理由gpt-3.5-turbo-16k模型驱动。gpt-4-preview-openai-functions-agent 5832:与上述相同,但使用新的gpt-4-1106-preview模型,该模型比 gpt-3.5 更大、功能更强大。anthropic-iterative-searche 1fdf:应用 迭代搜索 代理,该代理提示 Anthropic 的claude-2模型调用检索工具,并使用 XML 格式来提高结构化文本生成的可靠性。
Assistant API
最后,我们在 openai-assistant af83 中测试了 OpenAI 的新助手 API。它仍然使用我们相同的检索工具,但它使用 OpenAI 的执行逻辑来决定查询和最终响应。此代理最终在我们所有测试中获得了最高的性能。
查看结果
比较视图还使您可以轻松手动查看输出,以更好地了解模型的行为方式,以便您可以调整认知架构并更新评估技术以解决您发现的任何故障模式。
为了说明这一点,让我们比较由 Mistral-7b RAG 应用程序驱动的对话式检索链和由 GPT-3.5 驱动的类似架构的应用程序:(比较链接)。在使用测试的提示时,就为此示例生成的聚合指标而言,GPT-3.5 的性能明显优于 Mistral 7B 模型(平均余弦距离相差 0.01,但平均“准确性”得分落后 0.1)。
注意:尽管额外的提示工程可能会缩小差距,但在这些实验中测试的开源模型均未达到现成的专有 API 的总体性能。
这很有趣,但是为了决定如何改进,您需要查看数据。LangSmith 使这变得容易。以下面这个具有挑战性的示例为例
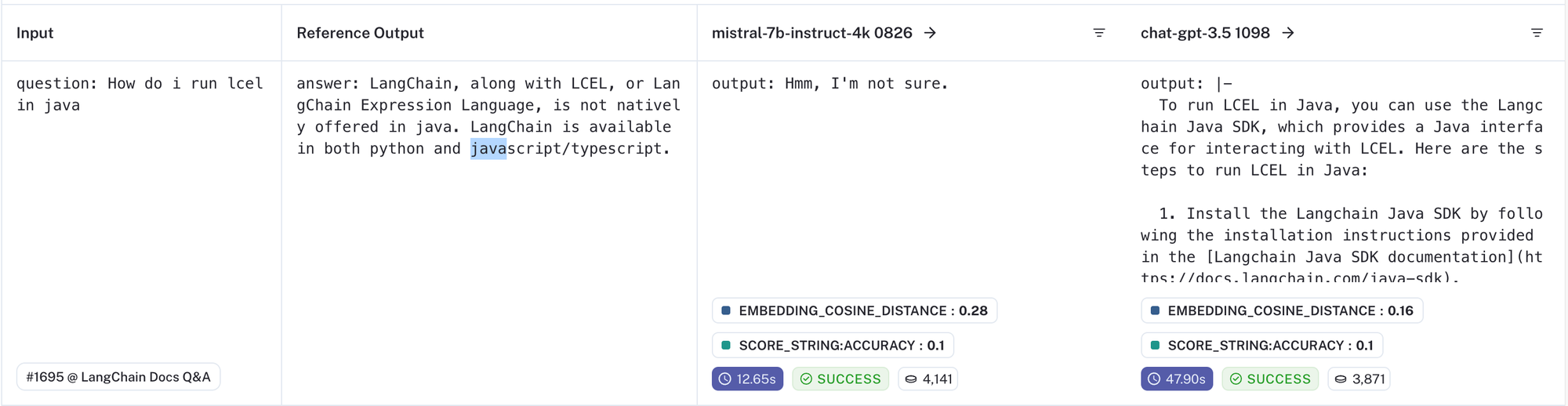
对于此数据点,两个模型都无法正确回答;问题本身需要了解缺失,这对于经常导致幻觉的 RAG 应用程序来说是一项具有挑战性的任务。
通过肉眼检查,gpt-3.5-turbo 模型显然产生了幻觉,甚至提供了一个不错的虚构链接 (https://docs.langchain.com/java-sdk)。mistral 模型的响应更可取,因为它不会产生不准确的信息(没有官方的 LangChain java SDK)。
要诊断模型做出如此响应的原因,您可以点击查看该架构的完整追踪信息。
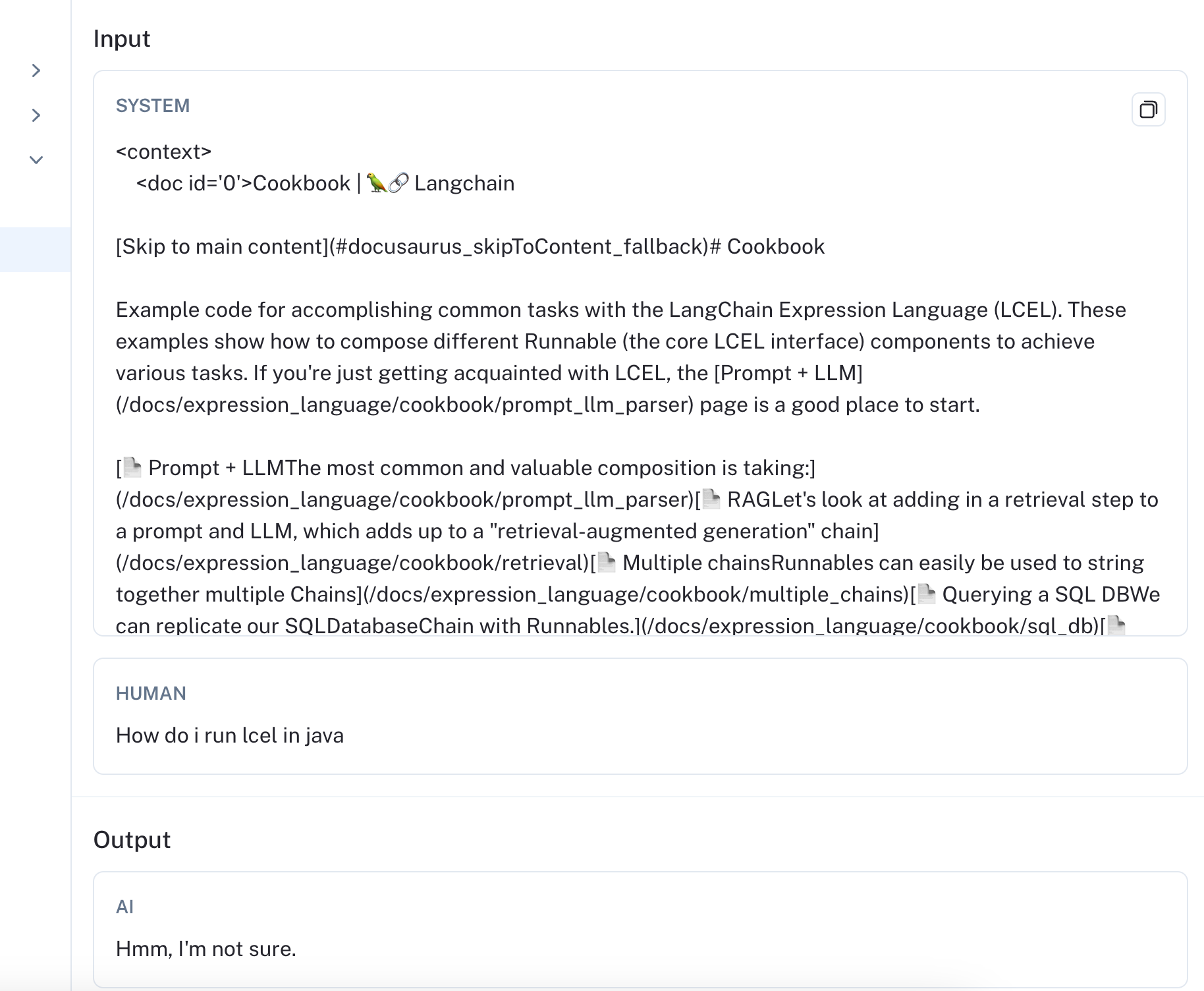
从追踪信息 (链接) 中可以清楚地看出,检索到的文档与原始查询完全无关。如果您正在使用像 gpt-3.5 这样的模型并遇到这样的幻觉,您可以尝试添加一个额外的系统提示,提醒模型仅根据检索到的内容进行响应,并且您可以努力改进检索器以过滤掉不相关的文档。
让我们回顾另一个数据点,在这个数据点中,gpt-3.5 响应正确,但 mistral 没有。如果您 比较输出,您可以看到 mistral 受文档内容的影响太大,并提到了文档中的类,而不是直接答案。
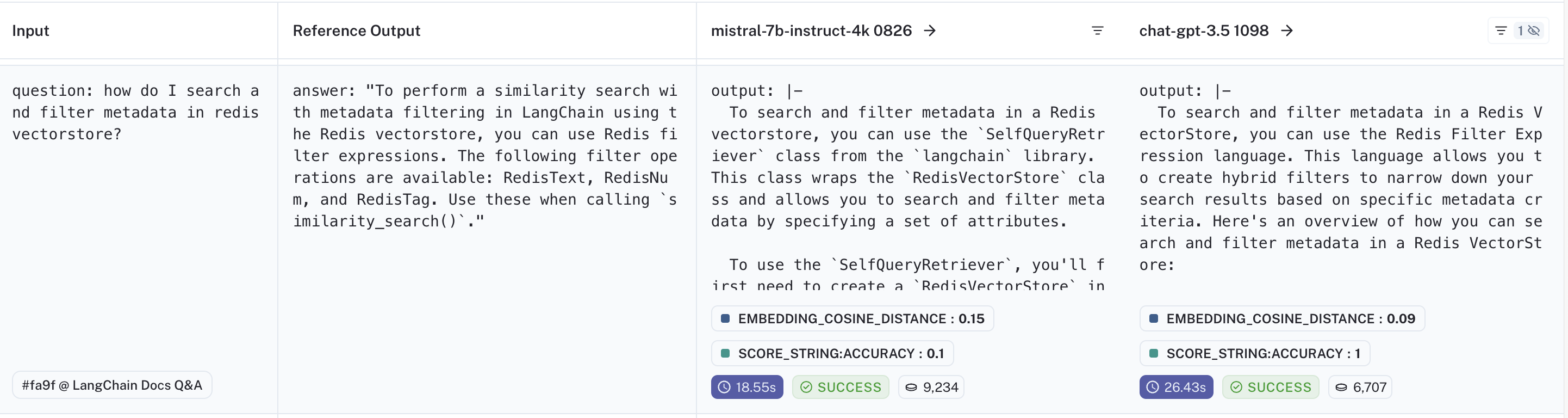
如果您查看 追踪信息,您可以看到“SelfQueryRetriever”仅在检索到的文档 5 中被提及,这意味着它是最不相关的文档。LLM 基于此文档来决定其响应表明,或许我们可以通过重新排序输入来提高其性能。
要检查此假设,您可以 在 Playground 中打开 LLM 运行。通过交换文档 1 和 5,我们可以看到 LLM 响应了正确的答案。基于此检查,我们可以更新我们呈现文档的顺序并重新运行评估!
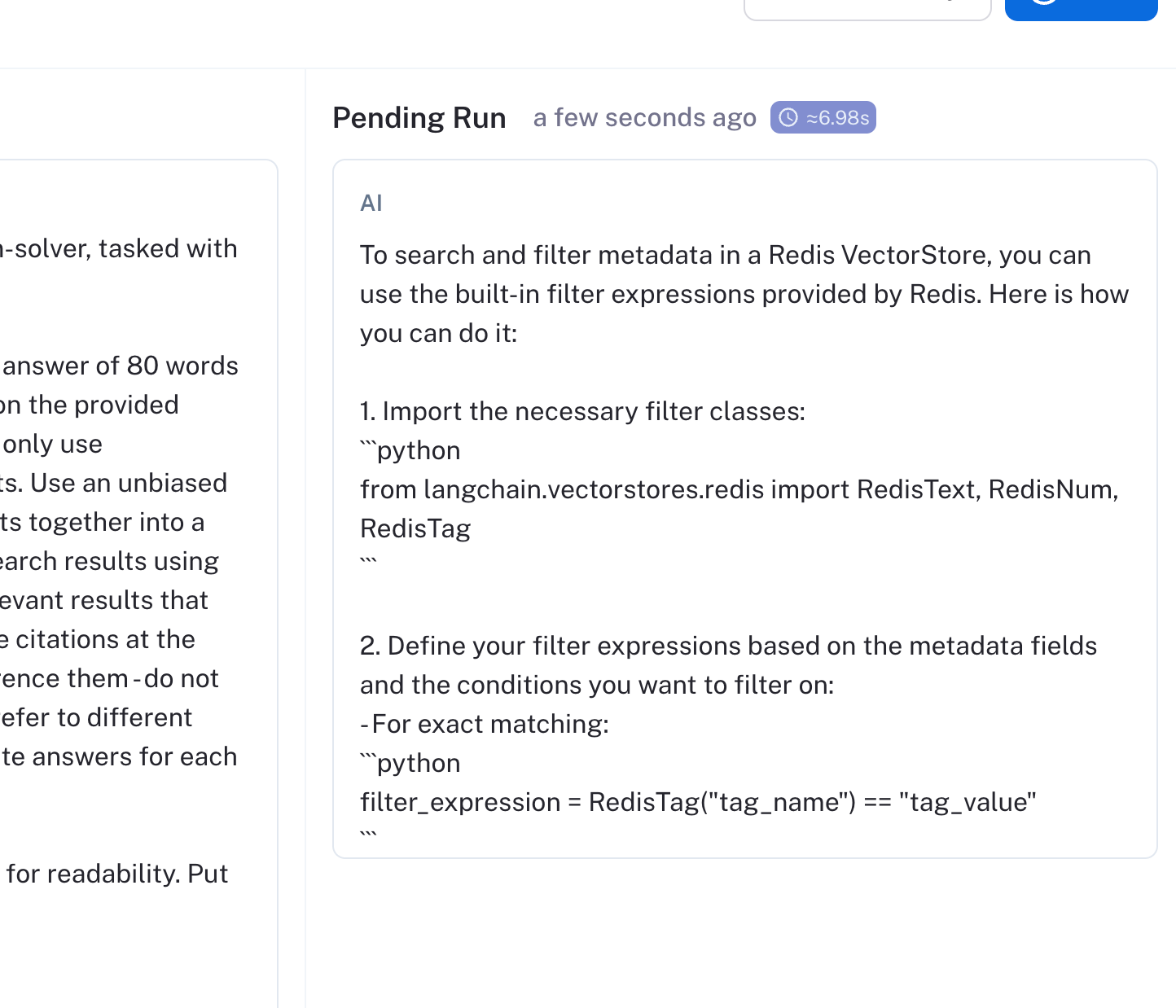
除了响应准确性之外,延迟是构建 LLM 应用程序时的另一个重要指标。在我们的例子中,mistral-7b 的中位响应时间为 18 秒,比 gpt-3.5 的快 11 秒。

同时衡量质量指标和“系统指标”可以帮助您为工作选择“大小合适”的模型和架构。
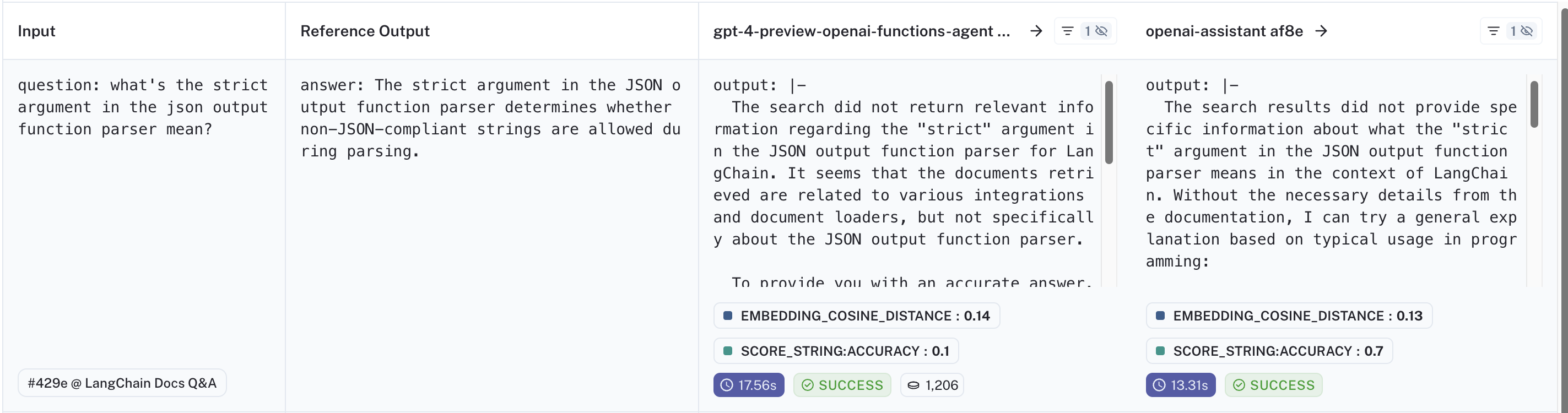
最后,让我们将 openai-assistant af83 与类似的 gpt-4-preview-openai-functions-agent 5832 测试进行比较。它们使用相同的底层模型和检索器工具,并且作为代理工作,但前一个测试使用 OpenAI 的助手 API。您可以在此处查看比较:链接。
助手优于代理的一个数据点示例是这个 (示例)。两者都表示他们看不到问题的明确答案(因为检索器是相同的),但助手愿意提供关于 strict 如何在其他上下文中使用的背景信息,作为用户的指示。
更多内容即将推出
在接下来的几周内,我们计划为 LangChain 最受欢迎的每个 用例 添加基准测试,以使其更易于使用。请查看 LangChain 基准测试存储库以获取更新,并打开功能请求以确保涵盖您的用例。
您还可以下载 langchain-benchmarks 包,以便在这个和其他任务上试用您的 RAG 应用程序。