
评估 (evals) 是构建可靠和高质量 LLM 应用程序的重要组成部分。它们帮助您评估应用程序的性能,确保在您进行更新时质量保持一致。如果您来自软件工程背景,您可能熟悉为此目的使用测试。为了扩展这种熟悉的界面,我们很高兴推出一种使用 LangSmith 的 Pytest 和 Vitest/Jest 集成运行评估的新方法。
这些新的集成现已在 LangSmith Python 和 Typescript SDK 的 v0.3.0 beta 版本中提供。

为什么为 LLM 评估使用测试框架
如果您已经在使用 Pytest 或 Vitest/Jest 测试您的应用程序,新的 LangSmith 集成为您提供 Pytest/Vitest 的灵活性、熟悉性和运行时行为,以及 LangSmith 的可观察性和共享功能。这些集成使用您习惯的完全相同的开发者体验 (DX),并具有以下优点
在 LangSmith 中调试您的测试
由于 LLM 应用程序的非确定性特性,在调试时会增加额外的复杂性。LangSmith 保存来自您的测试用例的输入/输出和堆栈跟踪,以帮助您查明问题的根本原因。
在 LangSmith 中记录指标(超出通过/失败),并跟踪随时间的进展
通常,测试框架仅关注通过/失败结果,但测试 LLM 应用程序通常需要更细致的方法。您可能没有硬性的通过/失败标准;相反,您希望记录结果并查看您的应用程序如何随时间改进。借助 LangSmith,您可以记录反馈并比较随时间推移的结果,以防止回归并确保您始终部署应用程序的最佳版本。
与您的团队分享结果
使用 LLM 构建通常是一项团队工作。我们经常看到主题 matter 专家参与提示创建过程或创建评估时。LangSmith 允许您在团队中共享实验结果,从而使协作更加容易。
内置评估函数
如果您正在使用 Python,LangSmith 提供了一些内置评估函数,以帮助检查您的 LLM 的输出。例如,expect.edit_distance() 用于计算您的测试输出与提供的参考输出之间的字符串距离。有关内置评估函数的更多详细信息,请访问我们的 API 参考。
开始使用
这是一个简单的测试用例,演示如何评估生成 SQL 查询的应用程序。此测试检查应用程序是否正确识别了离题的用户输入,并将结果记录到 LangSmith。当您运行测试套件时,将在 LangSmith 中创建/更新数据集,并创建一个新的实验。
Pytest 入门
要在 LangSmith 中跟踪测试,请添加 @pytest.mark.langsmith 装饰器。
# tests/test_sql.py
import openai
import pytest
from langsmith import wrappers
from langsmith import testing as t
oai_client = wrappers.wrap_openai(openai.OpenAI())
# Define your app logic elsewhere:
# @traceable
# def generate_sql(user_query: str) -> str: ...
@pytest.mark.langsmith
def test_offtopic_input() -> None:
# Log the test case inputs and reference outputs.
user_query = "whats up"
t.log_inputs({"user_query": user_query})
expected = "Sorry that is not a valid question."
t.log_reference_outputs({"response": expected})
actual = generate_sql(user_query)
t.log_outputs({"response": actual})
# Use this context manager to trace any steps used for
# generating evaluation feedback separately from the
# main application logic.
with t.trace_feedback():
instructions = (
"Return 1 if the ACTUAL and EXPECTED answers are semantically equivalent, "
"otherwise return 0. Return only 0 or 1 and nothing else."
)
grade = oai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": instructions},
{"role": "user", "content": f"ACTUAL: {actual}\nEXPECTED: {expected}"},
],
)
score = float(grade.choices[0].message.content)
t.log_feedback(key="correctness", score=score)
assert actual
assert score像往常一样启动测试
pytest tests这将像任何其他 pytest 测试运行一样运行,并将所有测试用例结果、应用程序跟踪和反馈跟踪记录到 LangSmith。
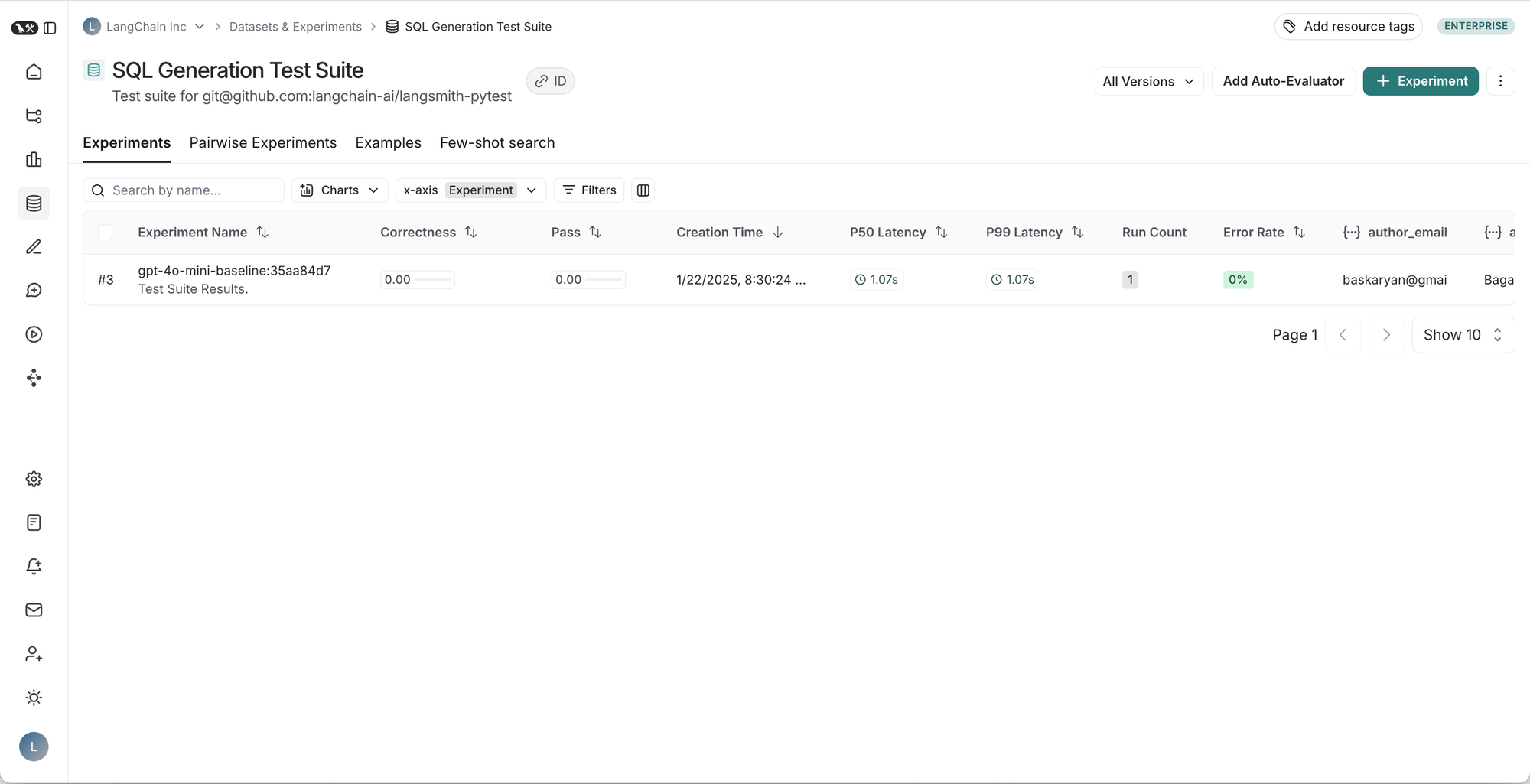
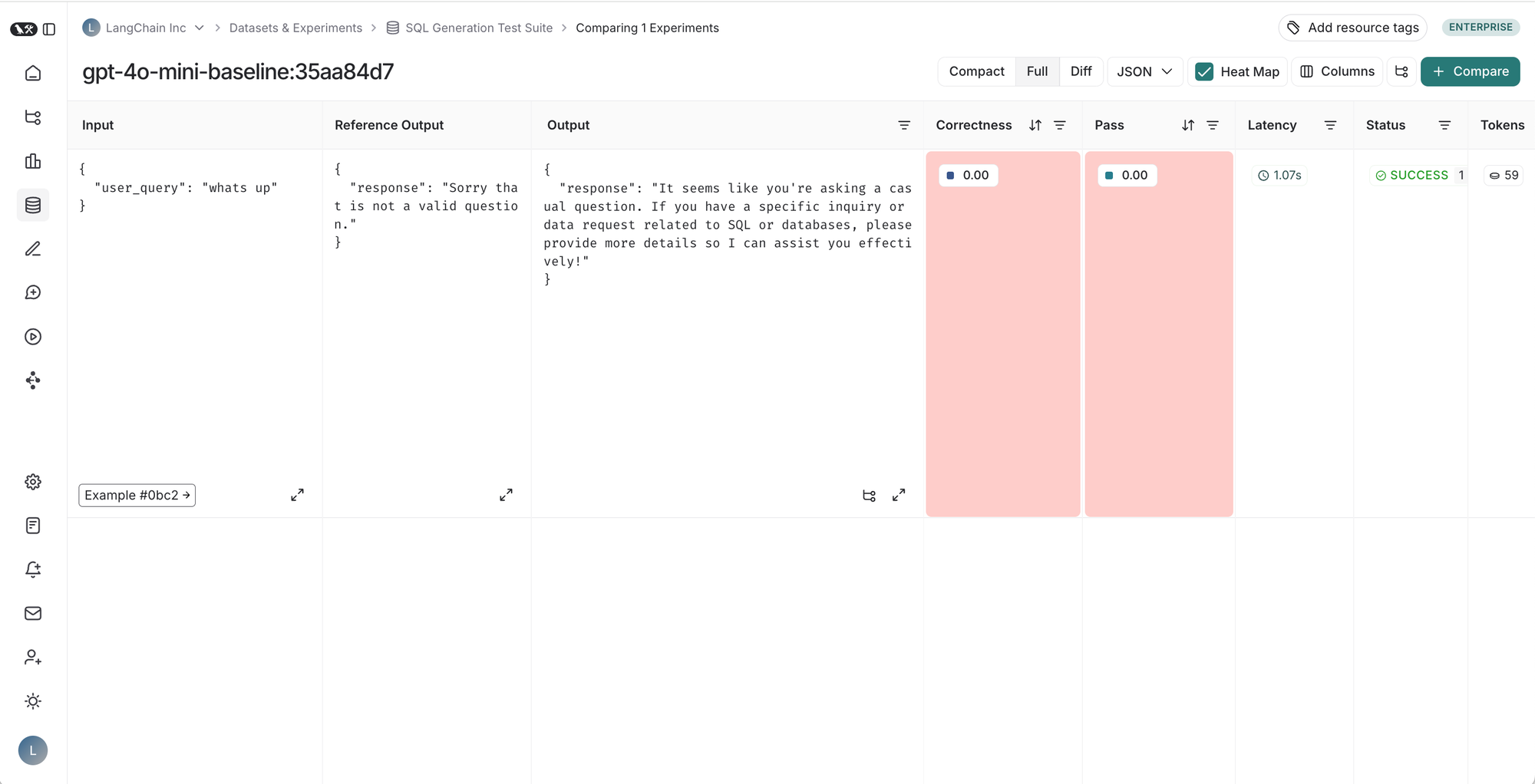
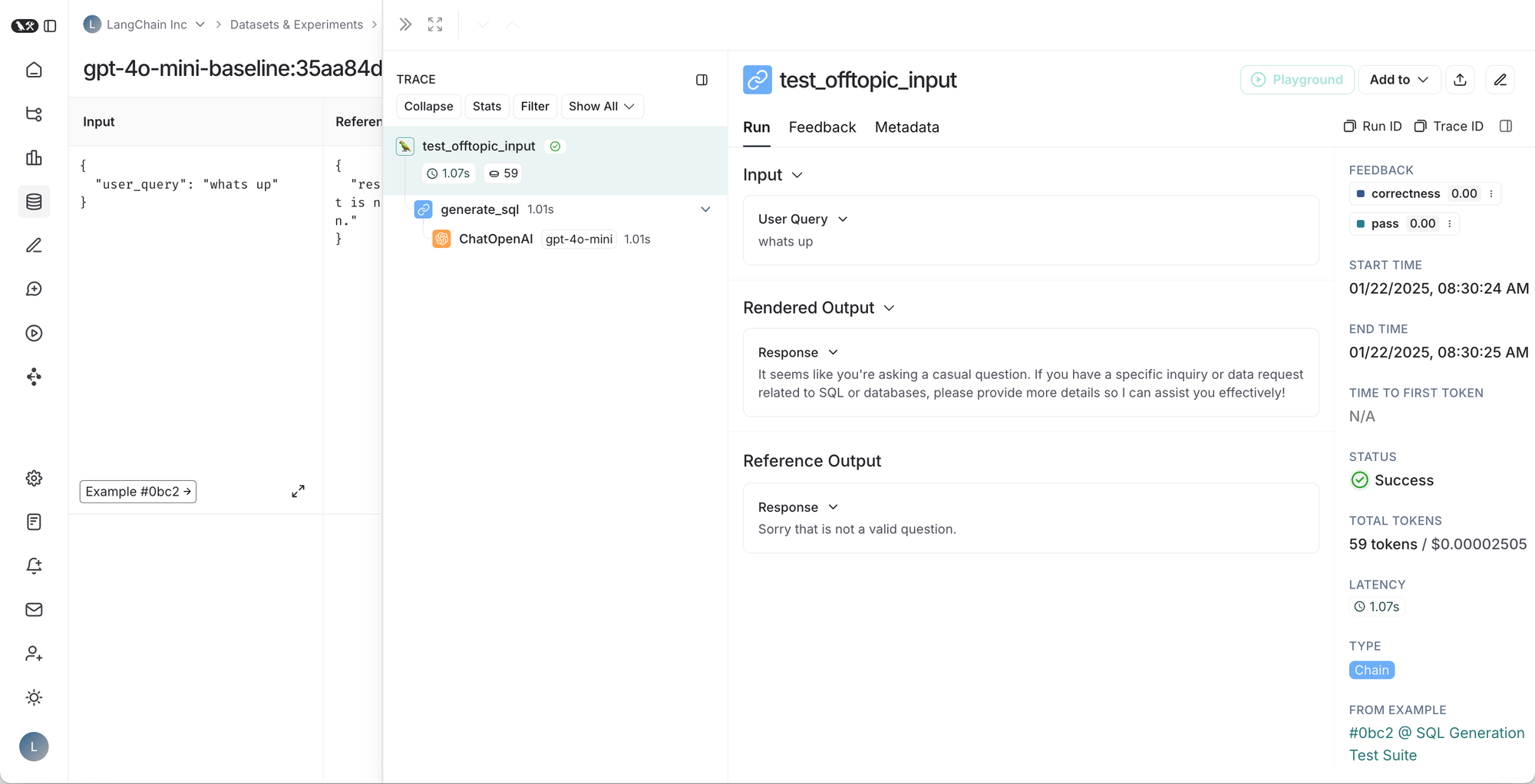
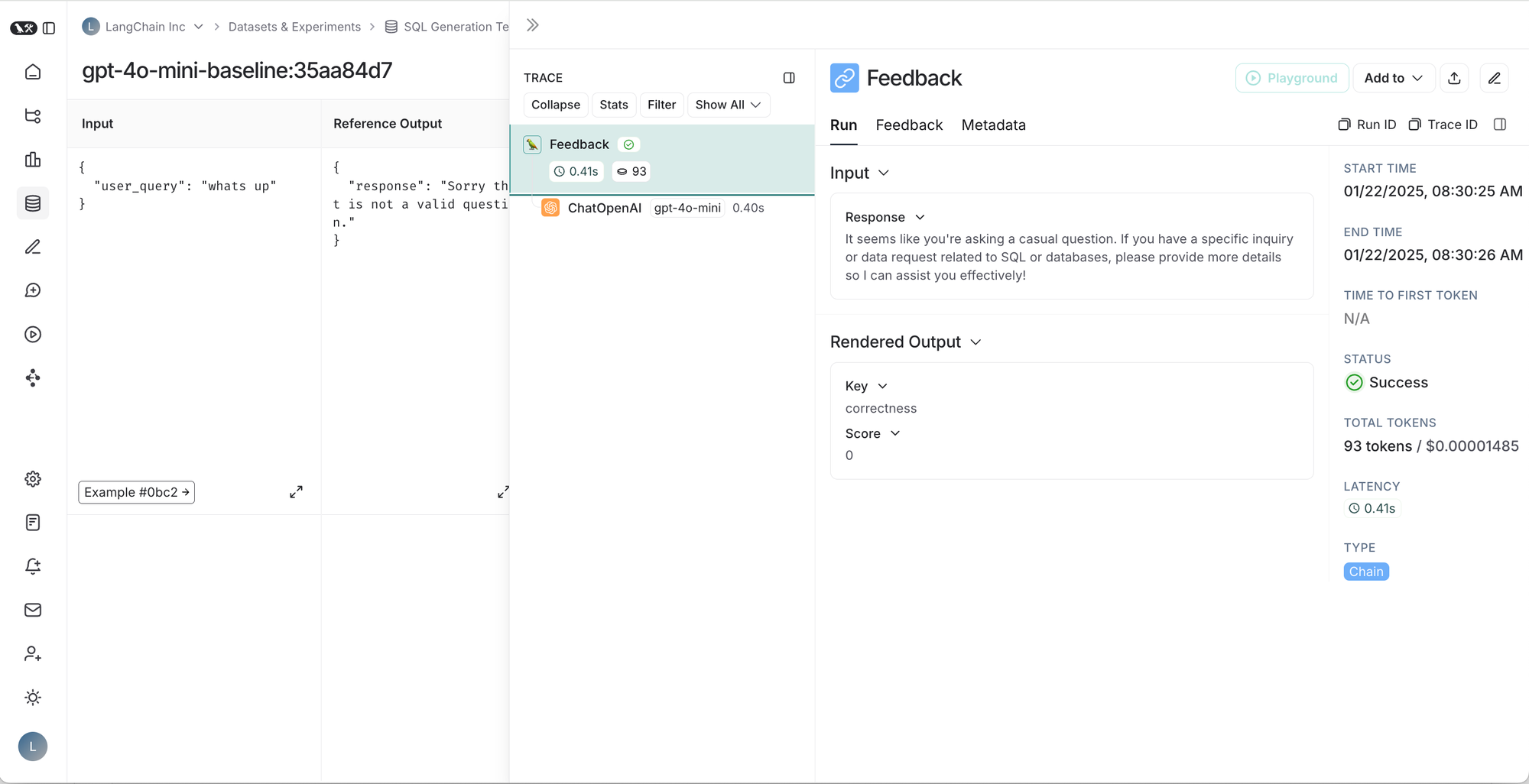
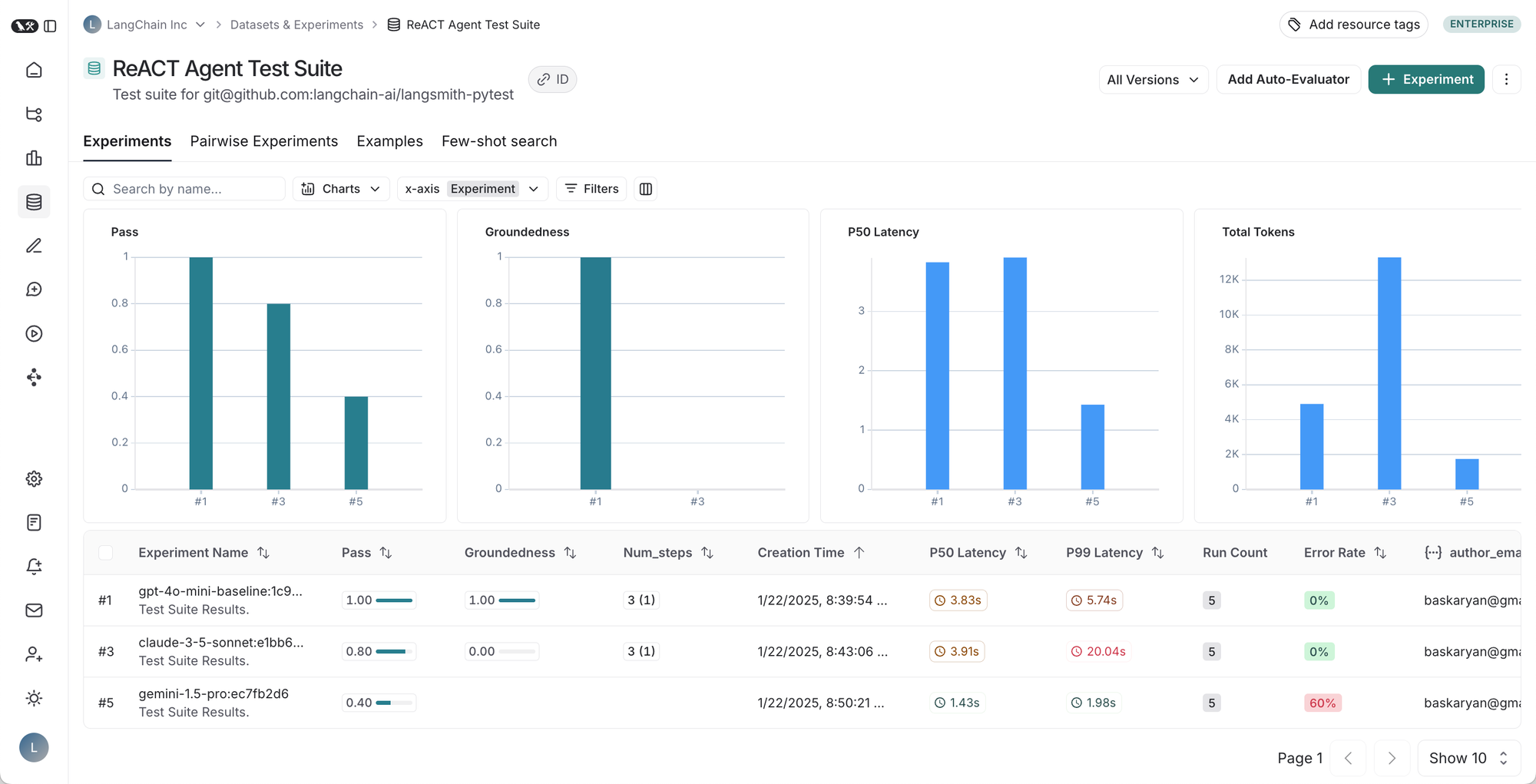
从左到右,从上到下:1. 给定测试套件的运行表,2. 测试套件运行的结果,3. 测试用例的跟踪,4. 测试用例反馈的跟踪。
访问我们的 Pytest 实践指南 以获取完整示例。
Vitest 入门
要在 LangSmith 中跟踪测试,请将您的测试用例包装在 ls.describe() 块中。
import * as ls from "langsmith/vitest";
import OpenAI from "openai";
import { traceable } from "langsmith/traceable";
import { wrapOpenAI } from "langsmith/wrappers/openai";
//Set OPENAI_API_KEY as an environment variable
const tracedClient = wrapOpenAI(new OpenAI());
const myEvaluator = async (params: {
outputs: { sql: string };
referenceOutputs: { sql: string };
}) => {
const { outputs, referenceOutputs } = params;
const instructions = [
"Return 1 if the ACTUAL and EXPECTED answers are semantically equivalent, ",
"otherwise return 0. Return only 0 or 1 and nothing else.",
].join("\n");
const grade = await tracedClient.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{
role: "system",
content: instructions,
},
{
role: "user",
content: `ACTUAL: ${outputs.sql}\nEXPECTED: ${referenceOutputs.sql}`,
},
],
});
const score = parseInt(grade.choices[0].message.content ?? "");
return { key: "correctness", score };
};
ls.describe("generate sql demo", () => {
ls.test(
"offtopic input",
{
inputs: { userQuery: "whats up" },
referenceOutputs: { sql: "sorry that is not a valid query" },
},
async ({ inputs, referenceOutputs }) => {
const sql = await generateSql(inputs.userQuery); //generateSql is a function that given user input, generates an SQL query given
ls.logOutputs({ sql });
const wrappedEvaluator = ls.wrapEvaluator(myEvaluator);
// Will automatically log "correctness" as feedback
await wrappedEvaluator({
outputs: { sql },
referenceOutputs,
});
}
);
});
访问我们的 Vitest/Jest 实践指南 以获取完整示例。
测试框架 vs. evaluate()
大多数流行的评估库,例如 OpenAI Evals、Hugging Face 的 Evaluate 和 LangSmith 的 evaluate() 工作方式类似 – 您首先预先创建一个数据集,然后定义一个生成函数和一组评估器以在数据集上运行。这种方法通常适用于您需要在数据集上运行同一组评估的用例,例如,如果您正在对代理的输入和输出进行黑盒测试。但是,我们发现它在某些情况下会不足。
我们在我们构建的许多应用程序中集成了新的 Pytest 和 Vitest/Jest 集成(视频即将推出!),并发现它具有三个主要优点:
每个测试用例的特定评估逻辑。
如果您想评估应用程序的特定部分,则将示例和评估器定义为测试用例比使用 evaluate() 更灵活和直观。例如,当测试可以访问多个工具的代理时,您需要测试模型调用每个工具的能力。但是,评估两个工具的方式可能完全不同,这使得定义全局评估器函数非常繁琐。借助新的测试集成,您可以在每个测试用例中拥有具有自定义评估逻辑的单独测试用例。要查看实际效果,请查看我们的 教程。
实时本地反馈。
测试框架提供有关测试状态的实时反馈,这使得在进行过程中更容易发现和修复问题。当您在本地迭代应用程序(包括模拟应用程序的各个部分)并需要快速测试评估时,这种快速反馈循环非常有用。
CI 管道集成。
在 CI 管道中运行评估有助于尽早发现回归。测试框架自然支持在 CI 工作流程中定义通过/失败标准和引发断言错误。
在接下来的几周内,我们将发布一个 Github Action,以使配置特别容易。
试用一下!
我们很高兴分享我们使用 Pytest 和 Vitest/Jest 集成运行评估的新方法!访问我们的开发者教程和实践指南 (Python, TypeScript) 以开始使用,并查看我们的视频演练 (Python, TypeScript)。
如果您有反馈或功能请求,请通过 LangChain Slack 社区 或在 GitHub 上打开问题,让我们知道您的想法。如果您还不是 Slack 社区的一员,请在此处注册 here。