关键链接
人们对将自然语言与各种类型的数据(结构化、非结构化和半结构化)无缝连接抱有浓厚的兴趣。但是,这种新兴的“LUI”(语言用户界面)对于每种数据类型都有特定的挑战/考虑因素
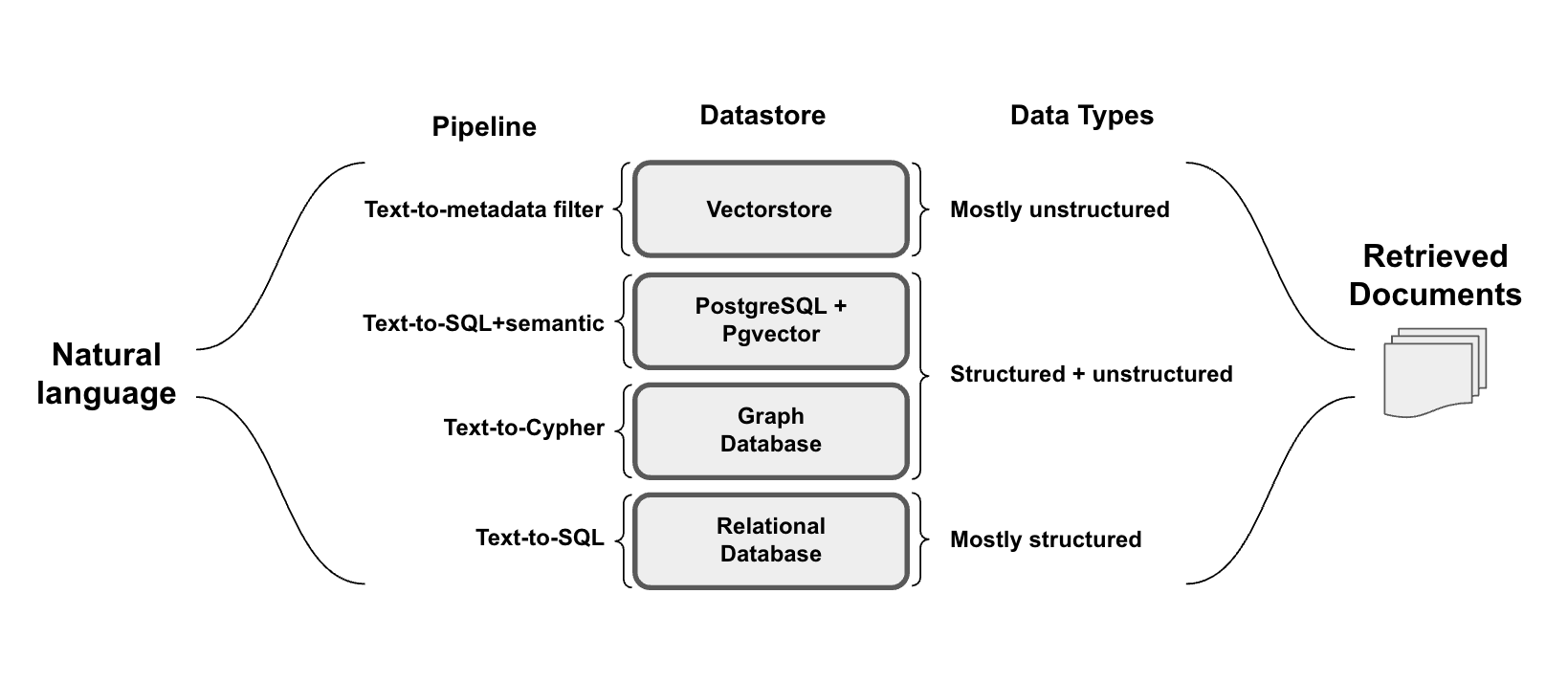
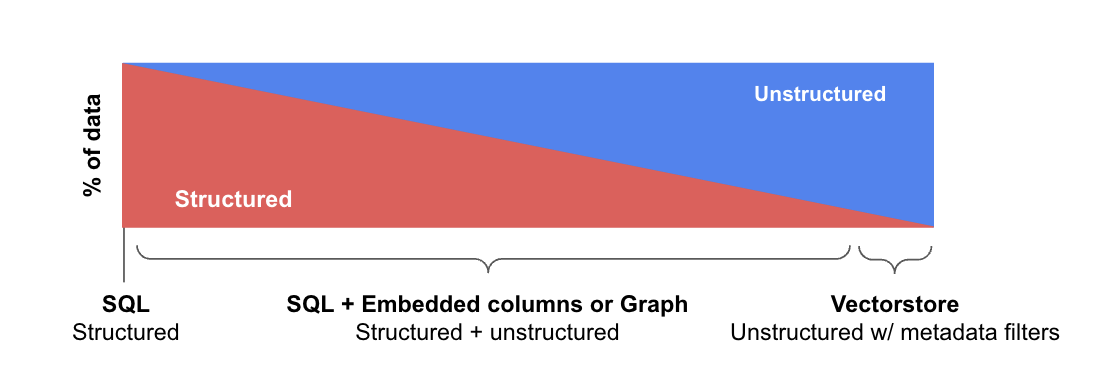
- 结构化数据:结构化数据主要存储在 SQL 或图数据库中,其特点是预定义的模式,并以表格或关系形式组织,使其适用于精确的查询操作。
- 半结构化数据:半结构化数据混合了结构化元素(例如,文档或关系数据库中的表格)和非结构化元素(例如,关系数据库中的文本或嵌入列)。
- 非结构化数据:非结构化数据通常存储在向量数据库中,由没有预定义模型的信息组成,通常伴随着结构化元数据,从而实现过滤。
为了应对这些挑战,LLM 在查询构建方面具有强大的能力,查询构建是将自然语言转换为每种数据类型的特定查询语法的过程。作为我们关于高级检索的博客系列的第三部分,我们将介绍各种查询构建策略(有关更多信息,请参阅我们关于 多表示索引 和 查询转换 的博客文章。)
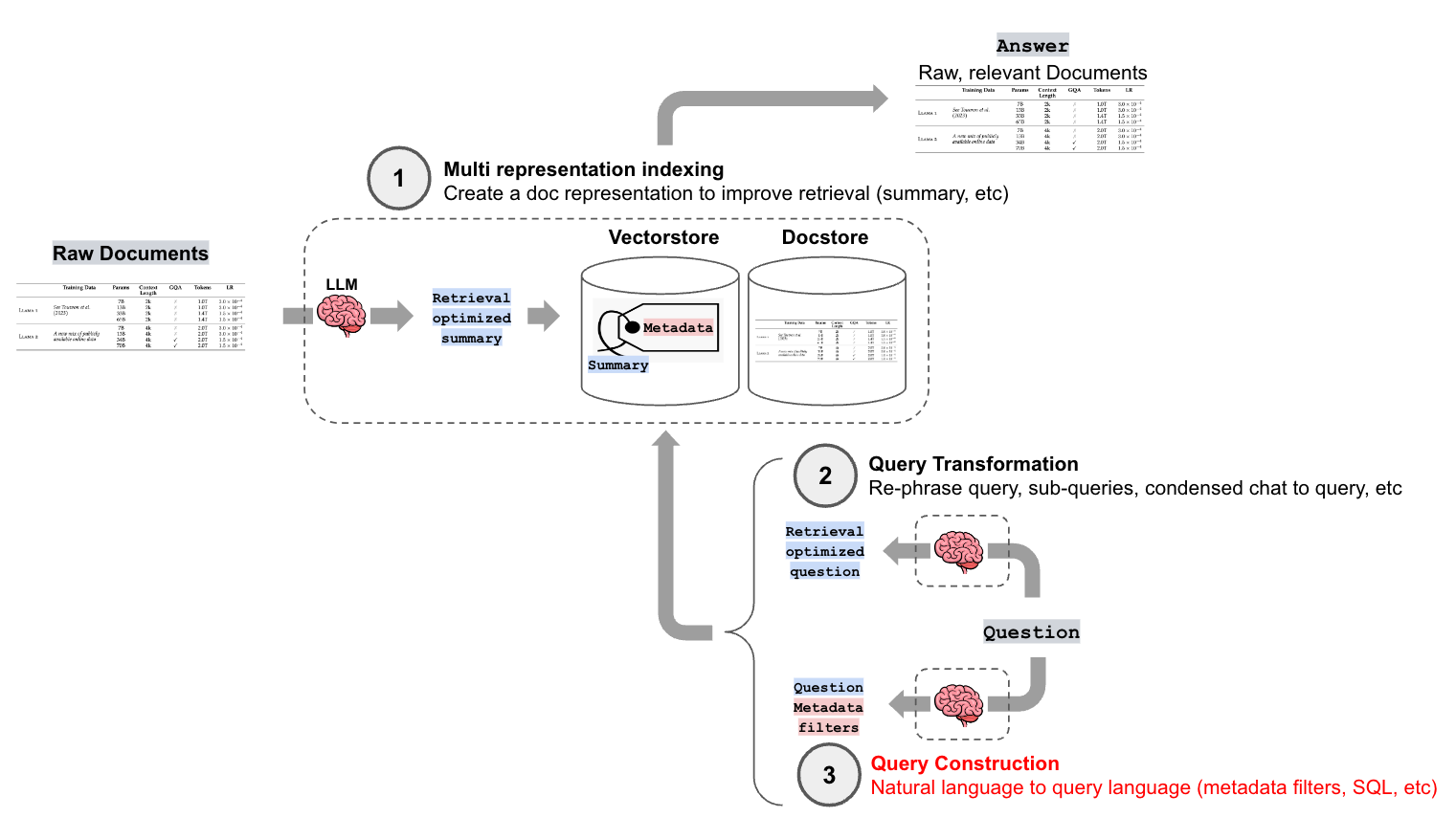
什么是查询构建?
在典型的检索增强生成 (RAG) 中,用户查询被转换为向量表示。然后将此向量与源文档的向量表示进行比较,以找到最相似的文档。这对于非结构化数据效果相当好(请参阅我们关于 多表示索引 和 查询转换 的博客文章),但是结构化数据呢?
世界上大多数数据都具有某种结构。这些数据中的大部分存在于关系型(例如,SQL)或图数据库中。甚至非结构化数据通常也关联结构化元数据(例如,作者、类型、发布日期等)。
例如,考虑查询 what are movies about aliens in the year 1980。其中一部分 (aliens) 我们可能想要进行语义查找,但也有一部分 ("year == 1980") 我们想要以精确的方式查找。
下面我们将重点介绍几个查询构建的示例,并为每个示例提供相关的 Cookbook、模板和文档
文本到元数据过滤器
配备 元数据过滤 的向量存储使结构化查询能够过滤嵌入的非结构化文档。自查询检索器可以使用几个步骤将自然语言查询转换为这些结构化查询
- 数据源定义:自查询检索器的核心是由相关元数据文件的明确规范锚定的(例如,在歌曲检索的上下文中,这可能是艺术家、时长和类型)。
- 用户查询解释:给定一个自然语言问题,自查询检索器将隔离查询(用于语义检索)和用于元数据过滤的过滤器。例如,对
songs by Taylor Swift or Katy Perry about teenage romance under 3 minutes long in the dance pop genre的查询被分解为过滤器和查询。 - 逻辑条件提取:过滤器本身由向量存储定义的比较器和运算符(例如,
eq表示等于或lt表示小于)构成。 - 结构化请求形成:最后,自查询检索器组装结构化请求,将语义搜索词(查询)与简化文档检索过程的逻辑条件(过滤器)分开。
我们可以定义一个链来执行上述步骤,该链接受用户问题并返回一个 StructuredQuery 对象,该对象封装了必要的过滤器
# Generate a prompt and parse output
prompt = get_query_constructor_prompt(document_content_description, metadata_field_info)
output_parser = StructuredQueryOutputParser.from_components()
query_constructor = prompt | llm | output_parser
# Invoke the query constructor with a sample query
query_constructor.invoke({
"query": "Songs by Taylor Swift or Katy Perry about teenage romance under 3 minutes long in the dance pop genre"
})
结构化请求将如下所示
{
"query": "teenager love",
"filter": "and(or(eq(\"artist\", \"Taylor Swift\"), eq(\"artist\", \"Katy Perry\")), lt(\"length\", 180), eq(\"genre\", \"pop\"))"
}
当与向量数据库交互时,这种方法可以显着提高 RAG 答案质量,因为直接从用户问题推断出的逻辑过滤器条件控制传递给 LLM 以进行最终答案综合的文本块。
阅读更多
文本到SQL
在数据连续体的另一端,SQL / 关系数据库是主要结构化数据的重要来源。大量努力集中在将自然语言转换为 SQL 请求,但存在一些明显的挑战,例如
- 幻觉:LLM 容易“幻觉”出虚构的表或字段,从而创建无效的查询。方法必须将这些 LLM 扎根于现实,确保它们生成与实际数据库模式对齐的有效 SQL。
- 用户错误:文本到 SQL 的方法应该对用户输入中的拼写错误或其他不规范之处具有鲁棒性,这些错误可能导致无效的查询。
考虑到这些挑战,出现了一些技巧
- 数据库描述:为了使 SQL 查询有依据,必须为 LLM 提供数据库的准确描述。一种常见的文本到 SQL 提示 采用了多篇 论文 中报道的想法:为每个表提供一个
CREATE TABLE描述,其中包括列名、它们的类型等,后跟 SELECT 语句中的三个示例行。 - 少样本示例:在提示中输入问题-查询匹配的少样本示例可以 提高查询生成准确性。 这可以通过简单地将标准静态示例附加到提示中来指导代理如何根据问题构建查询来实现。
- 错误处理:当面临错误时,数据分析师不会放弃——他们会迭代。我们可以使用像 SQL 代理(此处)这样的工具来从错误中恢复。

- 查找专有名词中的拼写错误:当查询名称等专有名词时,用户可能会不小心写错(例如
Franc Sinatra)。我们可以允许代理针对向量存储搜索专有名词,向量存储中包含 SQL 数据库中相关专有名词的正确拼写。
阅读更多
文本到SQL+语义
在数据连续体的中间,混合类型(结构化和非结构化)数据存储越来越普遍。向关系数据库添加向量支持是支持混合检索方法的一个关键推动因素(请参阅 AI 工程师峰会的最新视频 此处)。特别是,PostgreSQL 的 开源 pgvector 扩展将 SQL 的表达能力与语义搜索提供的细致入微的语义理解相结合。据报道,Pgvector 在性能和成本方面相对于 Pinecone 等向量存储具有优势。
Pgvector 使您可以使用 <-> 运算符在嵌入向量列上执行相似性搜索(例如,余弦、L2 距离、内积)
SELECT * FROM tracks ORDER BY "name_embedding" <-> {sadness_embedding}
从上面的查询中,我们可以使用 LIMIT 3 来获得前 3 首最悲伤的曲目(类似于标准 kNN 中的 top_k 值),以及更复杂的操作,例如挑选最悲伤的一首,以及出于某种原因的第 90 和第 50 百分位数。这解锁了两个重要的新功能
- 我们可以执行向量存储无法实现的语义搜索
- 我们可以增强文本到 SQL 的语义运算符知识。例如,它解锁了文本到语义的搜索(例如,查找标题传达特定感受的歌曲)和 SQL 查询(例如,按类型过滤)。
以下面的专辑歌曲示例为例,使用这种方法,我们可以找到包含最多歌曲的专辑,这些歌曲与某种情感相匹配(使用语义相似性作为表格数据的过滤器或计数),或者从标题为“lovely”的专辑中找到悲伤的歌曲(在一个查询中组合两个 语义搜索,这在使用带有元数据过滤的向量数据库时是不可能的)。
阅读更多
文本到Cypher
虽然向量存储很容易处理非结构化数据,但它们不理解向量之间的关系。虽然 SQL 数据库可以对关系进行建模,但模式更改可能会造成破坏且成本高昂。知识图可以通过对数据之间的关系进行建模并在不进行重大修改的情况下扩展关系类型来应对这些挑战。它们对于具有难以用表格形式表示的多对多关系或层次结构的数据是理想的。
就像关系数据库通常使用 SQL 一样,图数据库通常使用一种特定的查询语言,称为 Cypher,它旨在提供一种可视化方式来匹配模式和关系。它依赖于以下 ascii-art 类型的语法
(:Person {name:"Tomaz"})-[:LIVES_IN]->(:Country {name:"Slovenia"})
此模式描述了一个带有标签 Person 和名称属性 Tomaz 的节点,该节点与 Slovenia 的 Country 节点具有 LIVES_IN 关系。与上述示例类似,文本到 Cypher 可以将自然语言翻译为 Cypher 查询
from langchain.chains import GraphCypherQAChain
graph.refresh_schema()
cypher_chain = GraphCypherQAChain.from_llm(
cypher_llm = ChatOpenAI(temperature=0, model_name='gpt-4'),
qa_llm = ChatOpenAI(temperature=0), graph=graph, verbose=True,
)
由于生成有效的 Cypher 可能是一项复杂的任务,因此建议使用像 GPT-4 这样的高性能 LLM 来生成 Cypher 语句作为 cypher_llm。如上所示,然后我们可以用自然语言提问。
cypher_chain.run(
"How many open tickets there are?"
)
请参阅文档
结论
跨各种数据源无缝检索结构化和非结构化数据对于释放 LLM 的潜力至关重要。我们总结了四种流行的“自然语言到结构化查询”管道,这些管道已针对各种类型的数据存储出现,并为用户提供了入门模板和 Cookbook。