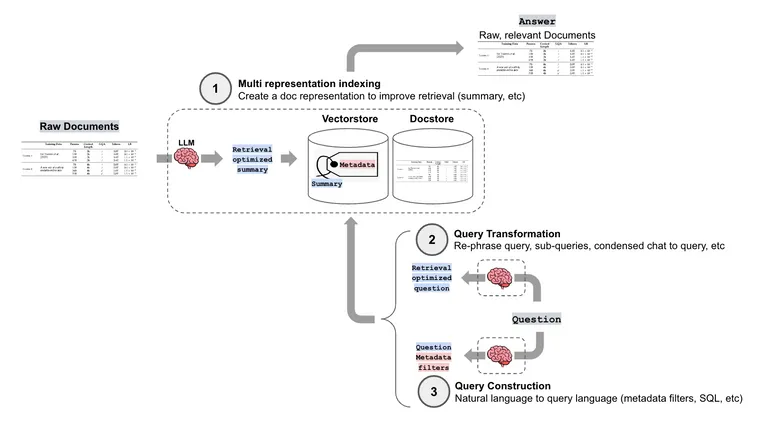
朴素 RAG 通常将文档分割成块,嵌入它们,并检索与用户问题具有高语义相似性的块。但是,这存在一些问题:(1)文档块可能包含不相关的降低检索质量的内容,(2)用户问题的措辞可能不利于检索,以及(3)可能需要从用户问题生成结构化查询(例如,用于查询具有元数据过滤的向量数据库或 SQL 数据库)。
LangChain 具有许多高级检索方法,以帮助应对这些挑战。(1) 多重表示索引:创建适合于检索的文档表示(如摘要)(使用多向量检索器阅读关于此内容的信息,请参阅上周的博客文章)。(2) 查询转换:在这篇文章中,我们将回顾几种转换人类问题以改进检索的方法。(3) 查询构建:将人类问题转换为特定的查询语法或语言,这将在未来的文章中介绍。
如果您考虑一个朴素的 RAG 管道,一般流程是您获取用户的问题并直接将其传递给嵌入模型。然后将该嵌入与向量数据库中存储的文档进行比较,并返回前 k 个最相似的文档。
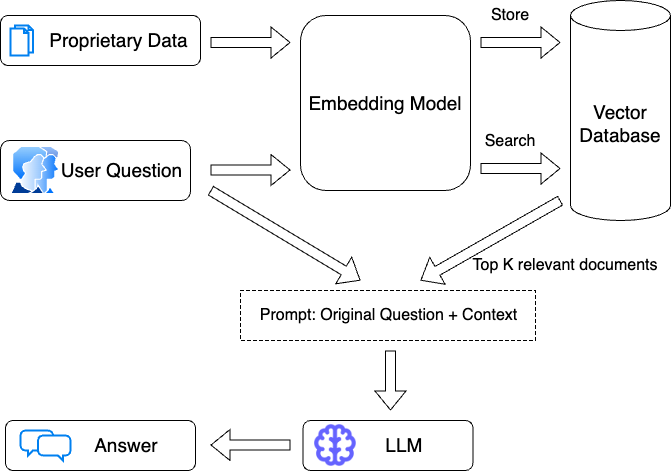
查询转换处理在传递给嵌入模型之前对用户问题进行的转换。
以下是一些利用这一点的论文和检索方法的变体。它们都使用 LLM 来生成新的(或多个新的)查询,主要的区别在于它们用于生成查询的提示。
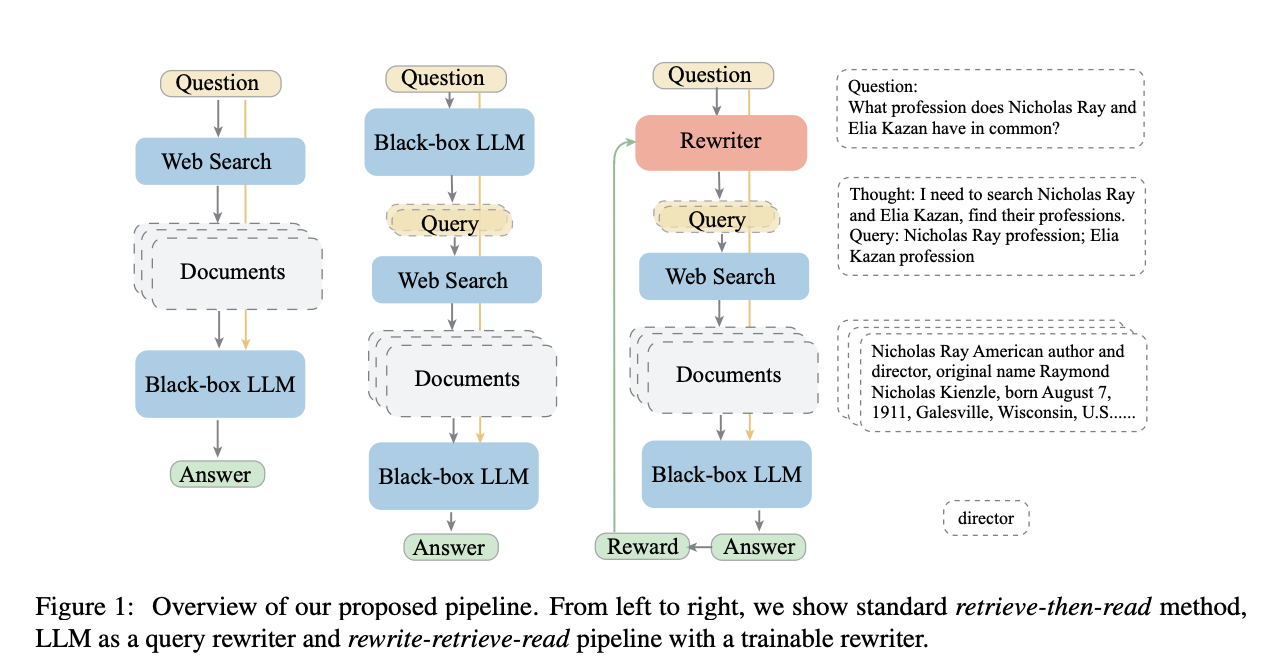
重写-检索-阅读
本文使用 LLM 来重写用户查询,而不是使用原始用户查询直接检索。
因为原始查询可能并不总是 LLM 检索的最佳选择,尤其是在现实世界中……我们首先提示 LLM 重写查询,然后进行检索增强阅读。
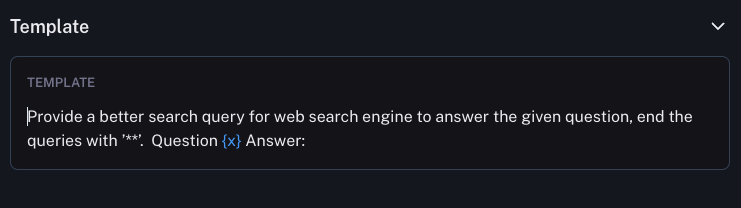
使用的提示相对简单(在 Hub 这里)
链接
退后一步提示
本文使用 LLM 生成“退后一步”问题。这可以与检索一起使用或不与检索一起使用。对于检索, “退后一步”问题和原始问题都用于进行检索,然后两个结果都用于作为语言模型响应的基础。
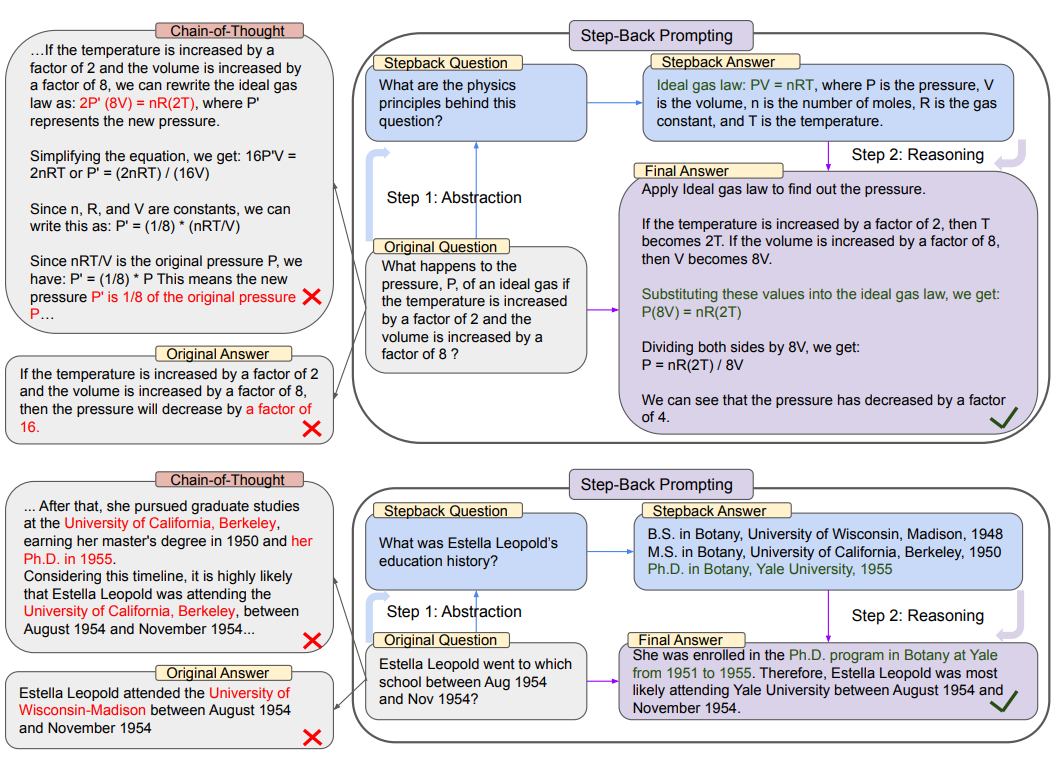
这里是使用的提示
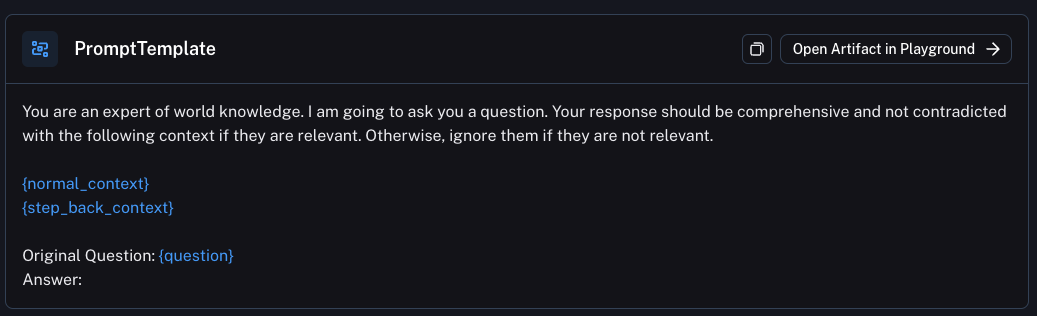
链接
后续问题
查询转换最基本和核心的应用场景是在对话链中处理后续问题。在处理后续问题时,基本上有三种选择
- 仅嵌入后续问题。这意味着,如果后续问题建立在或引用了之前的对话,它将丢失该问题。例如,如果我首先问“在意大利我可以做什么”,然后问“那里有什么类型的食物” - 如果我只嵌入“那里有什么类型的食物”,我将没有“那里”是哪里的上下文。
- 嵌入整个对话(或最后
k条消息)。这样做的问题是,如果后续问题与之前的对话完全无关,那么它可能会返回完全不相关的结果,从而在生成过程中分散注意力。 - 使用 LLM 进行查询转换!
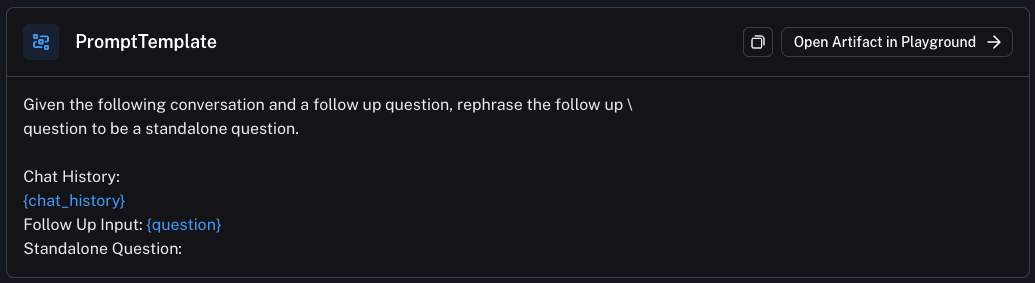
在最后一个选项中,您将迄今为止的整个对话(包括后续问题)传递给 LLM,并要求它生成搜索词。这就是我们在 WebLangChain 中所做的,也是大多数基于聊天的检索应用程序可能做的事情。
然后问题就变成了:我使用什么提示将整个对话转换为搜索查询?这是需要进行大量提示工程的地方。以下是我们为 WebLangChain 使用的提示(它将“查询生成”部分措辞为构建一个独立的问题)。在 Hub 这里查看。
多查询检索
在这种策略中,LLM 用于生成多个搜索查询。然后可以并行执行这些搜索查询,并将检索到的结果一起传递。当单个问题可能依赖于多个子问题时,这非常有用。
例如,考虑以下问题
红袜队还是爱国者队最近一次赢得冠军?
这实际上需要两个子问题
- “红袜队上次赢得冠军是什么时候?”
- “爱国者队上次赢得冠军是什么时候?”
链接
RAG-Fusion
最近的一篇文章建立在多查询检索的思想之上。然而,他们没有传递所有文档,而是使用倒数排名融合来重新排序文档。
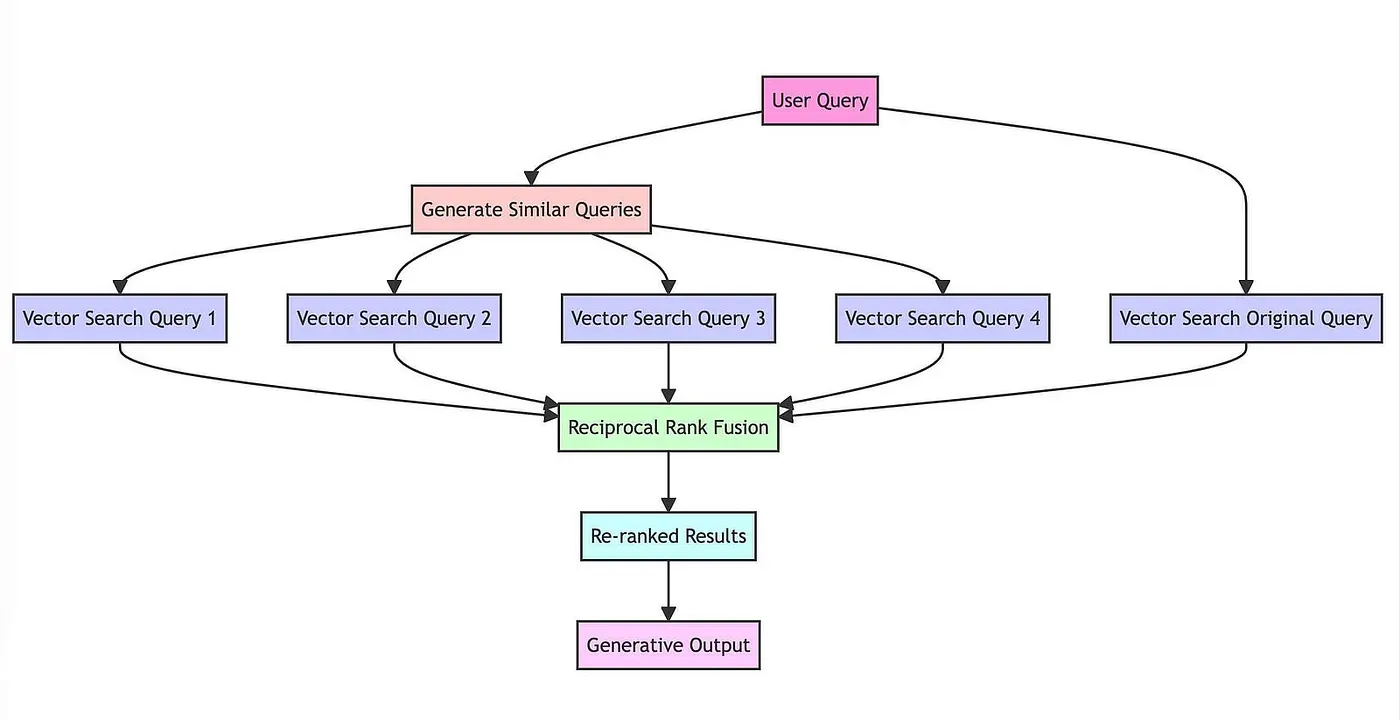
链接
结论
如您所见,有很多不同的方法可以进行查询转换。同样,这不是一个新话题 - 但新的是使用 LLM 来做到这一点。方法上的差异归结为使用的提示。编写提示非常容易 - 几乎和想到它们一样容易。这就引出了一个问题 - 您将提出哪些查询转换?请告诉我们!