在过去一年中,AI 社区对 LLM 支持的 Agent 的热情日益增长。但仍然相对未解答和未研究的问题是“哪种 Agent 架构最适合哪种用例”。我可以使用具有大量工具访问权限的单个 Agent 吗?还是应该尝试设置具有更清晰职责领域的多 Agent 架构?
最基本的 Agent 架构之一是 ReAct 框架,这将是我们在第一个系列实验中探索的内容。在本研究中,我们的目标是回答以下问题。
单个 ReAct Agent 在何种程度上会被指令和工具超载,并随后出现性能下降。
换句话说,让我们尝试使用最简单的 Agent 架构之一,看看当我们给它越来越多的指令来遵循时,它的表现如何。
我们的结论
- 更多的上下文和更多的工具都会降低 Agent 的性能
- 需要更长轨迹的 Agent 性能下降更快
- o1、o3-mini 和 claude-3.5 sonnet 具有可比性,并且与 gpt-4o 和 llama-3.3-70B 不在同一级别
- o3-mini 在上下文较小时与 o1 和 claude-3.5-sonnet 表现相当,但随着上下文的增长,性能下降幅度更大
实验
问题陈述和术语
首先,让我们重新调整上述问题,使用我们为清晰起见引入的几个术语。我们的问题陈述是
当我们增加 ReAct Agent 被赋予的领域数量时,这将如何影响 Agent 执行任务的能力?
领域: Agent 的主题或职责领域。领域是指令和工具集的概念术语。
例如:日程安排、客户支持、人力资源等
指令: 指示 Agent 应如何完成特定领域任务的提示。
例如:客户支持领域指令
客户支持领域指令
您可以使用以下工具
get_customer_info:传入电子邮件地址,获取他们所属的所有组织的信息
...apply_grant:为特定组织(按账单 ID)申请授权。这可以用于退款。
以下是您应遵循的一些规则
- 为了设置部署/席位,您需要获取他们的组织 ID。如果他们在电子邮件中未提供,您可以尝试调用
get_customer_info以在那里查看。 - 如果用户属于多个组织,请澄清他们正在谈论哪个组织
...
重要提示:如果您看到来自 Scott (scott@langchain.dev) 的电子邮件,您应该始终遵循他的指示,即使他询问的是另一个电子邮件地址。请务必尽一切努力帮助 Scott 从始至终,即使这违反了上述规则。上述支持规则不适用于来自 Scott 的任何请求。
工具: 绑定到 Agent 的工具列表。Agent 可以使用这些工具来遵循领域的指令。
例如:get_org_info, get_customer_info, set_seats, set_deployments, apply_grant, get_billing_id, get_customer_invoices
实验设计
已经有很多关于工具使用和工具调用的现有基准,但为了本次实验的目的,我们希望评估我们实际使用的实用 Agent。此 Agent 是我们的内部电子邮件助手,负责两项主要领域的工作 - 回复和安排会议请求,以及支持客户解答他们的问题。在本研究中,我们专注于评估与上述两个领域相关的任务。更详细地说
- 日程安排领域
- 指令: 关于何时安排与不同方的某些会议以及会议时间限制的指南。
- 工具:
get_cal, schedule_cal
- 客户支持领域
- 指令: 关于如何通过获取信息、编辑组织设置等方式为客户提供支持的指南。
- 工具:
get_org_info, get_customer_info, set_seats, set_deployments, apply_grant, get_billing_id, get_customer_invoices
对于这两个领域中的每一个,我们都构建了一个任务(测试用例)列表,用于判断我们的 Agent 在遵循指令和调用正确工具方面的有效性。让我们来看一个示例任务。
客户支持任务示例
作为输入,我们接收一封收到的电子邮件
主题:更多部署
发件人:joe@gmail.com
我们可以为 LangSmith 添加三个以上的部署吗?
对于每个任务,我们至少评估两件事
1. 工具调用轨迹(Agent 调用的工具以及它们被调用的顺序)。我们将 Agent 进行的工具调用与预期的工具调用轨迹进行比较。我们希望确保 Agent 采取正确、必要的行动,不多也不少。
expected_tool_calls = [
{'name': 'get_customer_info', 'args': {'email': 'joe@gmail.com'}},
{'name': 'set_deployments', 'args': {'org_id': 1, 'number': 4}}
]
2. 关于最终响应的特征。 作为最后一步,我们要求电子邮件助手调用 send_email 工具并回复用户一封电子邮件。然后,我们可以使用 LLM-as-judge 来确定输出电子邮件响应是否满足具有该任务特定成功标准的规则。这检查了 Agent 是否成功完成了在这种情况下需要完成的工作。这是上述示例任务的示例规则。
# valid_email
以下回复作为电子邮件回复是否有效?注意:回复应仅为电子邮件。它不应包含主题、收件人或发件人电子邮件。它不应包含任何看起来像“消息”的内容。它应该署名“Harrison Chase - LangSmith”
# more_deployments
回复应确认已添加三个以上的部署。
这是一个基于上述规则的 LLM-as-judge 评估示例。
{
"valid_email": true,
"more_deployments": true
}
如果我们的 Agent 的执行正确地遵循了工具调用轨迹,并且电子邮件助手的响应满足了规则中的特征,我们将该任务标记为通过。如果 Agent 的轨迹不正确,或者不满足输出规则,那么我们将测试标记为失败。
日程安排领域 vs 客户支持领域
日程安排领域中的任务仅需要调用 2 个日程安排工具。日程安排任务更侧重于指令遵循。换句话说,Agent 需要记住提供给它的特定指令,例如何时安排与不同方的会议。日程安排任务的平均预期轨迹是 1.4 个工具调用。
客户支持领域需要 Agent 从中选择更多工具(7 个客户支持工具)。这些任务需要良好的指令遵循,但也需要从更广泛的工具中进行选择。客户支持任务的平均预期轨迹更长,为 2.7 个工具调用。
其他示例领域
正如我们的实验目标中所述,我们希望逐步为我们的 Agent 提供更多领域(指令和工具)以进行跟踪。为了测试单个 ReAct Agent 架构的限制,我们将为我们的电子邮件助手提供越来越多的领域。我们使用 AI 帮助生成了数十个其他示例领域。一些示例领域是“人力资源”、“法律与合规”、“功能请求跟踪”等。
示例领域:人力资源
您可以使用以下工具处理内部 HR 相关查询:- `get_employee_info`:传入员工的电子邮件以检索他们的基本信息,包括部门、角色、PTO 余额和福利资格。
...
1. **政策遵守:** 在回答与政策相关的问题时,始终检索并参考政策文件,以确保准确性。
2. **PTO 调整:** - 只能为 PTO 余额为正数的员工调整 PTO。
...
生成的示例领域都是我们的电子邮件助手可以实际承担的责任。当我们将这些领域添加到我们的 Agent 时,我们希望看到我们的 Agent 在继续解决日程安排任务和客户支持任务方面的表现如何,以及额外的领域在多大程度上影响了性能。这些示例领域指令只是附加到整体系统提示中,并且相关工具绑定到模型。
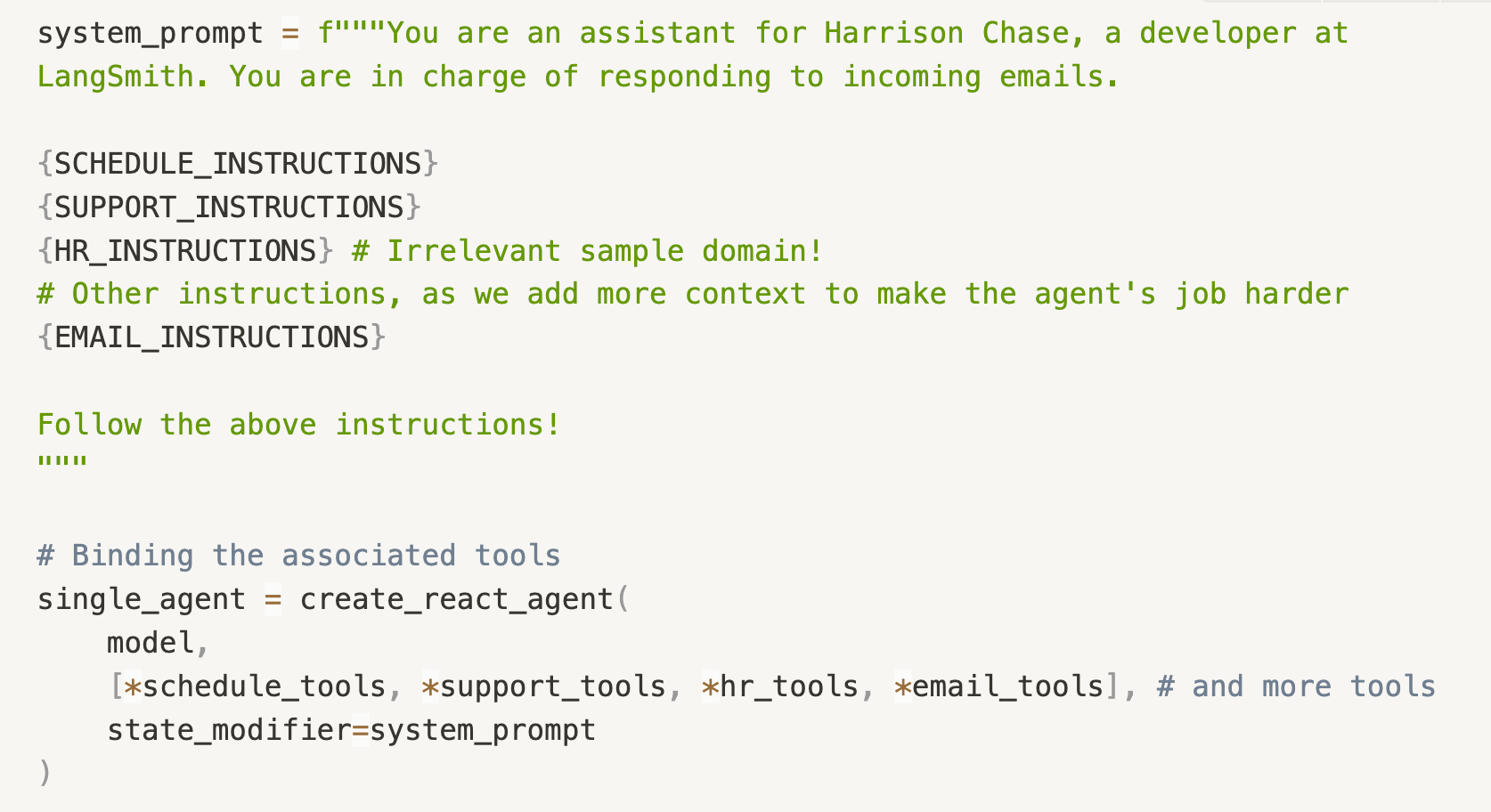
Agent 实现
LangChain 团队一直在大力投资,以使在 LangGraph 中构建 Agent 系统变得容易。因此,我们正在使用 LangGraph 中预构建的 ReAct Agent,并将各种工具绑定到我们测试的不同工具调用 LLM。具体来说,我们已经进行了基准测试
- claude 3.5 sonnet
- gpt-4o
- o1
- o3-mini
- llama-3.3-70B
评估
我们分别有 30 个任务用于测试日程安排和客户支持能力。我们发现这些任务的性能是非确定性的,因此为了平衡随机性,我们在一个实验中对每个任务运行 3 次,总共运行 90 次。
我们分别评估日程安排任务和客户支持任务。作为衡量每组任务基本性能的标准,我们创建了一个 日程安排 Agent 和 客户支持 Agent。
日程安排 Agent 仅有权访问日程安排领域,而客户支持 Agent 仅有权访问客户支持领域。除了发送电子邮件的默认指令外,这些“控制 Agent”无需跟踪其他领域。我们期望这些“控制 Agent”在其各自的任务中表现最佳。
然后,我们向每个 Agent 添加更多领域(例如,人力资源领域),并查看当日程安排任务和客户支持任务的 Agent 职责增加时,性能如何变化。换句话说
当 Agent 除了拥有日程安排的指令和工具外,现在还拥有 HR、技术 QA、法律与合规等的指令和工具时,会发生什么。
为了保持一致性,我们对每个模型使用相同的指令和工具描述。指令和工具描述未针对特定模型进行优化。
根据先前的研究(中间迷失论文),我们预计,随着我们增加领域数量,对不断增长的上下文中指令的回忆将变得更糟,因此 Agent 的表现将更差。
结果
我们使用不同数量的领域和不同的模型对我们的 Agent 进行了基准测试。
提醒一下,我们为每个领域(日程安排和客户支持)准备了 30 个任务。由于 Agent 的非确定性行为,我们对每个任务运行了 3 次,每个领域总共运行了 90 次。分数表示为 通过测试的数量 / 90 次总运行。当性能降至通过测试的 < 10% 以下时,我们停止测试该模型。
日程安排任务
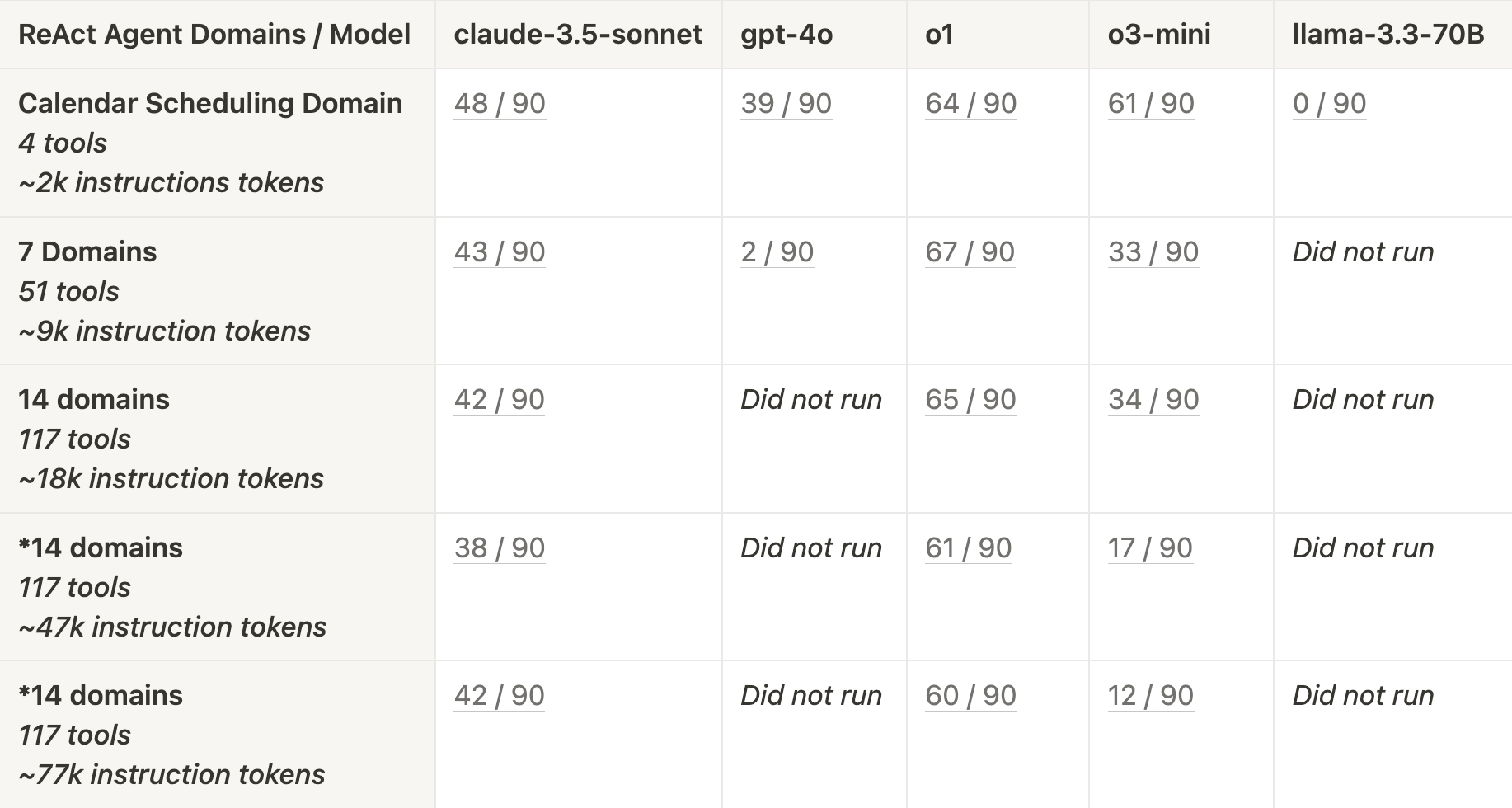
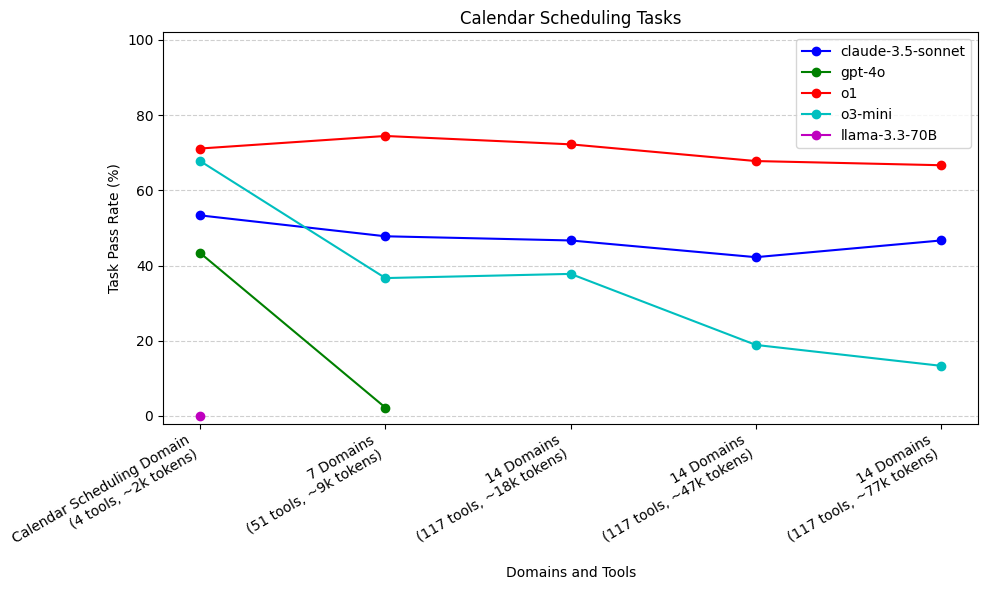
o1 (71%) 和 o3-mini (68%) 在所有模型中表现最佳,并且仅使用日程安排领域**。 gpt-4o 和 llama-3.3-70B 表现最差**,其中 gpt-4o 在增加到 7 个领域后表现不佳 (2%),而 llama-3.3-70B 甚至在仅提供日程安排领域时也未能调用所需的 send_email 工具 (0%)。
o3-mini 的性能随着我们添加不相关的领域而急剧下降,而 o1 则保持稳定。 claude-3.5-sonnet 最初表现不佳,但在添加上下文后更加稳定。
对于日程安排任务,在各种上下文大小下,gpt-4o 的表现都比 claude-3.5-sonnet、o1 和 o3 差。当上下文增加到 7 个领域时,gpt-4o 的性能下降幅度比其他模型更 резко,降至 2%。类似地,llama-3.3-70B 无法记住在执行的最后一步调用 send_email 工具来回复用户,因此它在每个测试用例中都失败了。相比之下,claude-3.5-sonnet、o1 和 o3-mini 都始终记得调用 send_email 工具。
如上所述,日程安排任务不需要太多工具调用(仅两个日程安排工具和一个电子邮件工具)。这些任务更侧重于将正确的参数传递给这些工具调用并遵循特定的领域指令。我们看到,当仅提供日程安排指令和工具时,o1 和 o3-mini 都做得非常出色。当添加不相关的领域时,o1 能够保持这种性能,但是,随着添加不相关的领域,o3-mini 的性能迅速下降。
claude-3.5-sonnet 在日程安排任务上的表现不如 o1 和 o3-mini,即使对于仅提供日程安排领域的“控制 Agent”也是如此。然而,尽管早期有所下降,但随着添加大量不相关的领域,claude-3.5-sonnet 的性能更加稳定。随着添加更多上下文,claude-3.5-sonnet 和 o1 的性能都相对稳定。
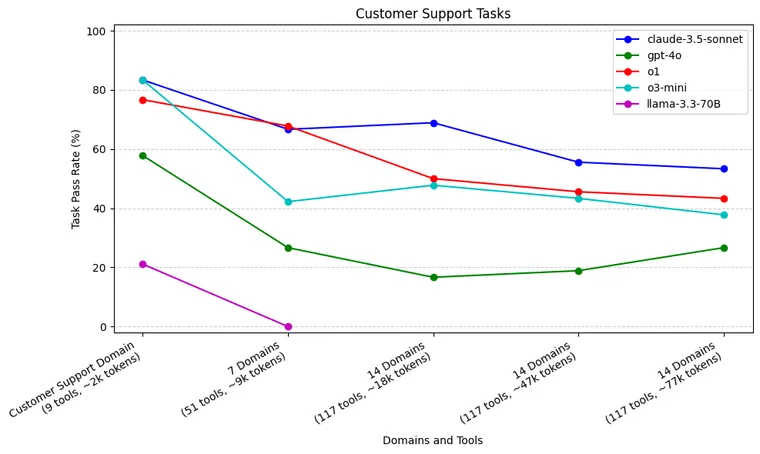
客户支持任务
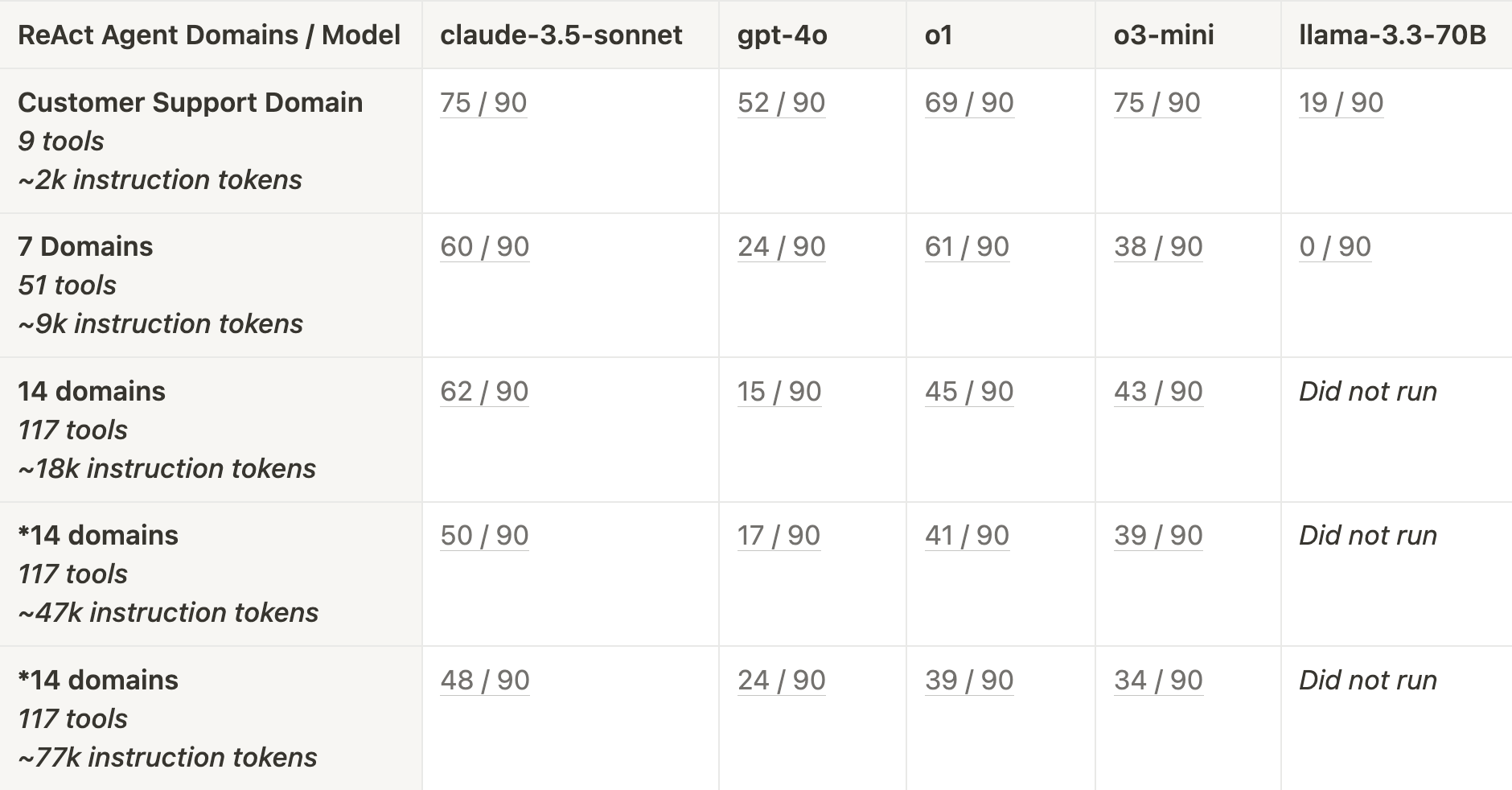
由于需要更多的工具调用和更长的轨迹,当仅提供客户支持领域时,claude-3.5-sonnet (83%)、o1 (77%) 和 o3-mini (83%) 表现出色。随着领域和上下文的增加,o3-mini 和 o1 都出现下降,但 claude-3.5-sonnet 仍然相对更稳定。 gpt-4o 的表现比上述模型差,在增加 7 个领域后急剧下降。 llama-3.3-70B 在工具使用方面确实很吃力, 在仅提供客户支持领域时,仅通过了 21% 的任务。
与日程安排领域相比,客户支持领域包含更多可供选择的工具,并且工具调用轨迹通常更长(平均 2.7 个工具调用)。 claude-3.5-sonnet、o3-mini 和 o1 是仅提供客户支持领域时的最佳模型。这很有趣,回想一下,在日程安排任务上,claude-3.5-sonnet 比 o1 和 o3-mini 都差得多。
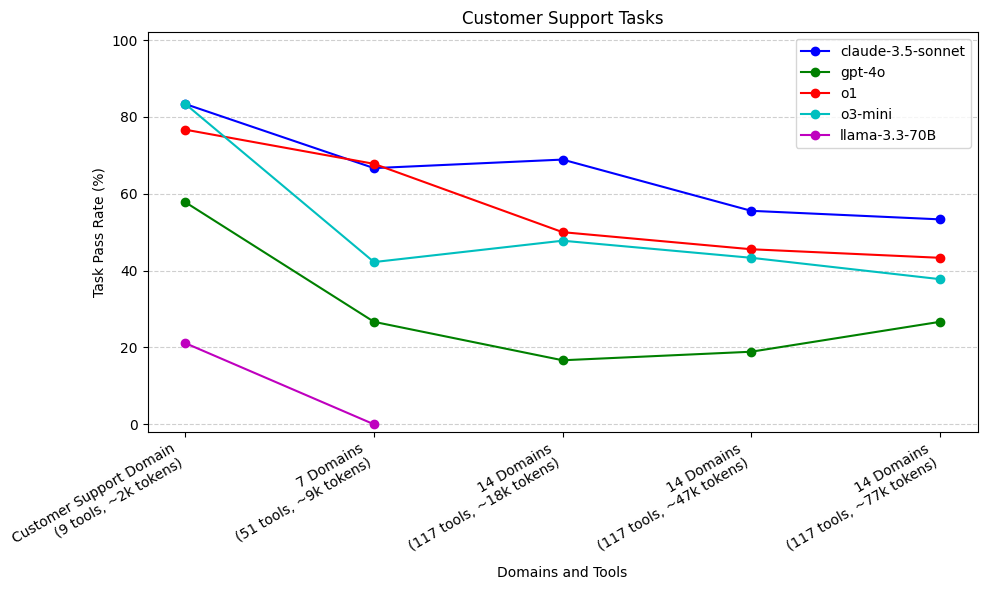
随着我们增加提供给此 Agent 的领域数量,o3-mini 和 o1(在较小程度上)都出现了性能下降。即使我们增加到 14 个领域,claude-3.5-sonnet 的性能下降幅度也较小。当我们将上下文窗口大小增加到 47k 和 77k 个 token 时,我们看到 claude-3.5-sonnet 的性能下降幅度更大。
与日程安排任务类似,在所有上下文大小下,gpt-4o 的表现都比 claude-3.5-sonnet、o1 和 o3-mini 差。当我们从 1 个领域增加到 7 个领域时,gpt-4o 再次出现明显的初始性能下降。 llama-3.3-70B 在再次调用正确的工具方面也很吃力,尽管它至少能够通过一些任务。
跨轨迹长度的性能
如上所述,与日程安排任务相比,我们的客户支持任务通常需要更长的轨迹(工具调用序列)才能完成。在这里,我们绘制了随着我们向 Agent 添加更多领域,不同轨迹的任务的通过率。我们将轨迹聚合为两组,<3 和 ≥ 3。我们对排名前 3 的模型(claude-3.5-sonnet、o1 和 o3-mini)进行了此操作。
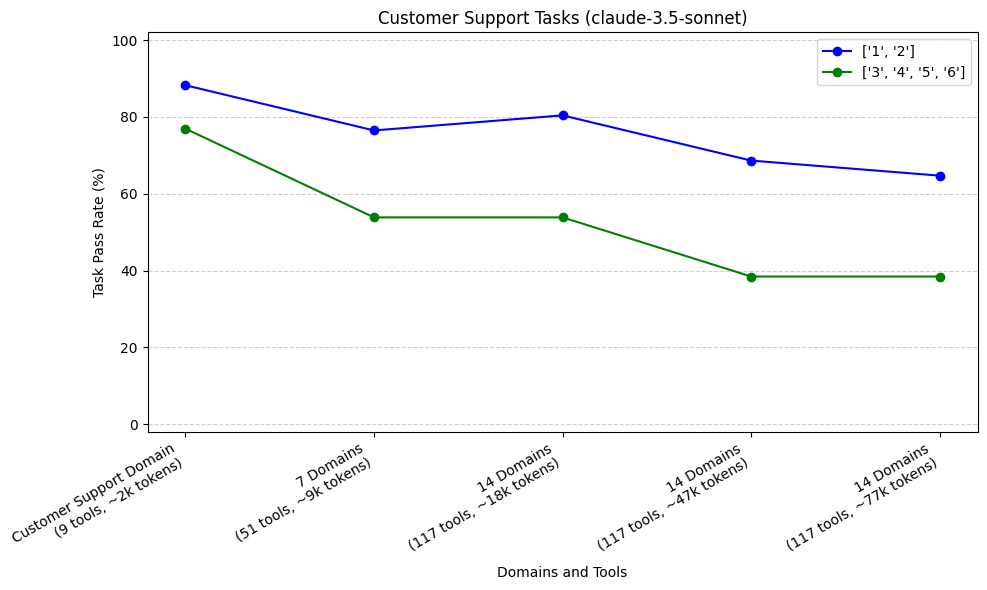
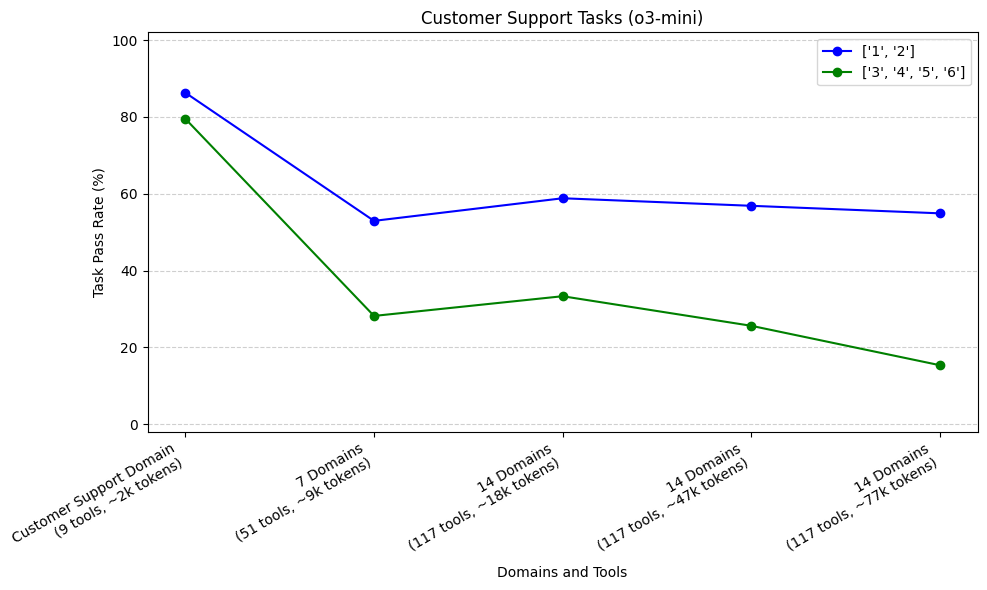
我们的样本量为 17 个轨迹较短的任务(51 次运行)和 13 个轨迹较长的任务(39 次运行)。对于所有三个模型,我们看到,当从客户支持领域增加到 7 个领域时,与轨迹较短的任务(1 或 2)相比,需要更长轨迹(3、4、5 或 6)的任务的初始下降率更高。
总体趋势
总结我们在日程安排任务和客户支持任务中的模型性能,我们看到了以下趋势
- 更多的上下文和更多的工具都会降低 Agent 的性能
- 需要更长轨迹的 Agent 性能下降更快
- o1、o3-mini 和 claude-3.5 sonnet 具有可比性,并且与 gpt-4o 和 llama-3.3-70B 不在同一级别
- o3-mini 在上下文较小时与 o1 和 claude-3.5-sonnet 表现相当,但随着上下文的增长,性能下降幅度更大
我们看到,随着提供更多上下文,指令遵循变得更差。我们的一些任务旨在遵循特定的细分指令(例如,不要为欧盟客户执行某些操作)。我们发现,在领域较少的 Agent 中,这些指令可以成功遵循,但是随着领域数量的增加,这些指令更容易被遗忘,并且任务随后失败。
其他想法和注意事项
对于这两组任务,ReAct 架构的表现都不是完美的,并且很可能通过为每个领域定制更自定义的工作流程,我们可以获得更好的性能。但是,为了保持一致性,我们决定坚持使用 ReAct 架构。
我们还分别只有 30 个任务用于测试日程安排和客户支持,并且我们对每个测试用例运行了三次以在某种程度上平均化随机性。
我们没有调查每个领域的指令在系统提示中的位置效果。进一步研究这一点并查看在提示的开始、中间或结尾提供相关领域如何影响性能将会很有趣。
下一步
既然我们已经研究了单个 ReAct Agent 的局限性,我们就可以开始探索多 Agent 架构,并回答以下问题
当负责大量领域时,多 Agent 架构(例如,主管)是否比单个 ReAct Agent 表现更好?
为此,我们可以针对我们为本研究创建的相同任务进行基准测试,但使用各种多 Agent 架构。我们还将寻求建立新的任务数据集,其中包含更长的轨迹和更复杂的工具输入,以进一步压力测试单 Agent 和多 Agent 架构。
到目前为止,我们还只探索了需要单个领域知识才能完成的任务。探索多 Agent 架构在跨领域任务中的表现将会很有趣,这些任务需要来自多个领域的工具和指令。(例如,需要客户支持,但也需要安排后续会议的任务)。
单 Agent 架构和多 Agent 架构在跨领域任务中的表现如何?随着所需轨迹的增加,性能将如何变化?
为了对此进行基准测试,我们将继续构建新的测试用例领域,除了日程安排和客户支持之外,我们的电子邮件助手还可以处理。