这篇博文介绍了我们在 LangSmith 中改进的回归测试体验。如果视频形式更符合您的风格,您可以查看我们的 YouTube 演示 此处。免费注册 LangSmith 此处 亲自试用!
快速可靠地评估您的 LLM 应用程序的能力使 AI 工程师能够充满信心地进行迭代。我们看到许多行动最快、最成功的团队都拥有高效的测试和实验流程。这通常包括(1)设置输入数据集和(可选)预期输出,(2)定义一些评估标准。从那里,您可以评估不同的提示、模型、认知架构等。
这种类型的测试与传统的软件测试之间存在一些关键差异。一个主要区别:在测试 AI 应用程序时,它们可能无法在评估数据集上获得满分。这与软件测试形成对比,在软件测试中,您期望测试始终通过。这种差异有两个下游影响。首先,跟踪测试结果随时间的变化变得很重要。这在软件测试中是不必要的,因为它始终是 100% 通过,但在 AI 工程中,跟踪这种性能随时间的变化对于确保您正在改进是必要的。其次,能够比较两次(或更多)运行之间各个数据点非常重要。您希望能够看到模型过去正确的数据点现在出错(反之亦然)。
我注意到一种模式,伟大的 AI 研究人员愿意手动检查大量数据。更重要的是,他们构建了允许他们快速手动检查数据的基础设施。 虽然不那么光鲜亮丽,但手动检查数据可以提供关于问题的宝贵直觉。
Jason Wei 的这句话完美地描述了查看数据的重要性,以及允许他们这样做的基础设施的重要性。在 LangSmith,我们努力构建这种基础设施,这导致了我们回归测试流程的重大改进。
那么我们认为基础设施包括什么?
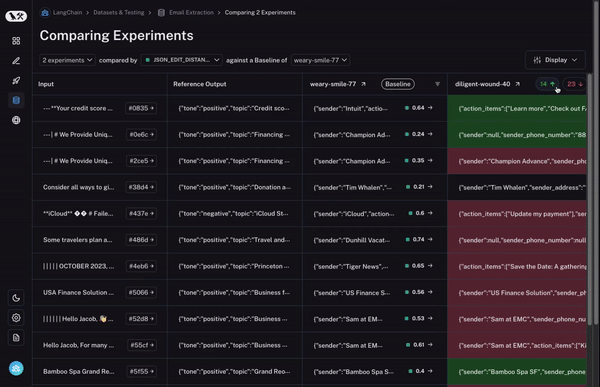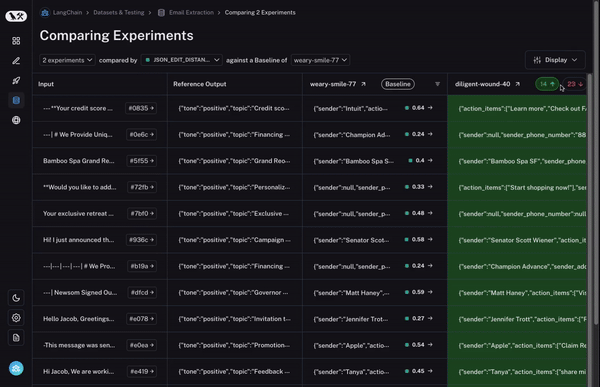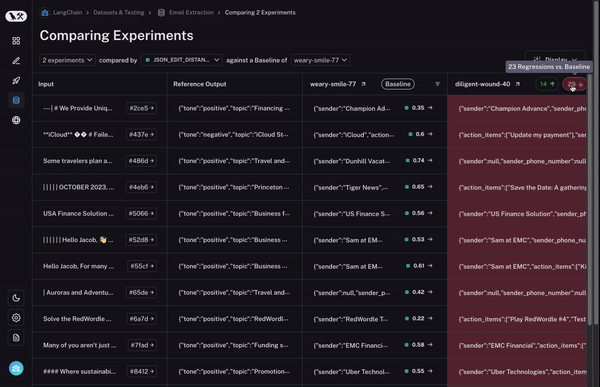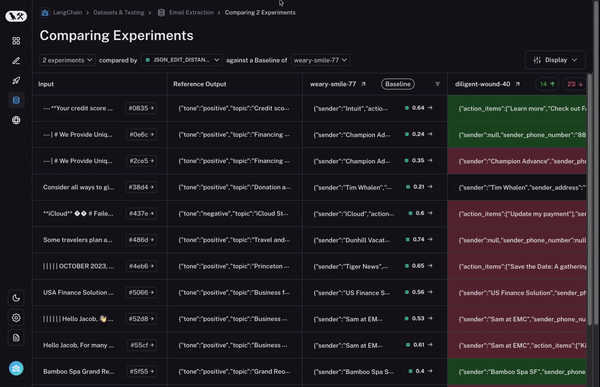
首先,您需要能够选择多个实验进行比较。至少两个,但通常能够同时查看三个或四个会很有用。为了实现这一点,我们构建了比较视图。这允许您选择任意数量的运行,并打开到一个视图中,您可以在其中同时查看所有结果。
其次,您需要对这种比较视图进行大量控制。您可能希望根据您要查找的内容以不同的方式查看信息。例如,有时您只想获得一个高级概述,有时您想查看所有文本,有时您想查看每次调用的延迟。通过我们的显示选项,您可以轻松选择您希望看到的信息。

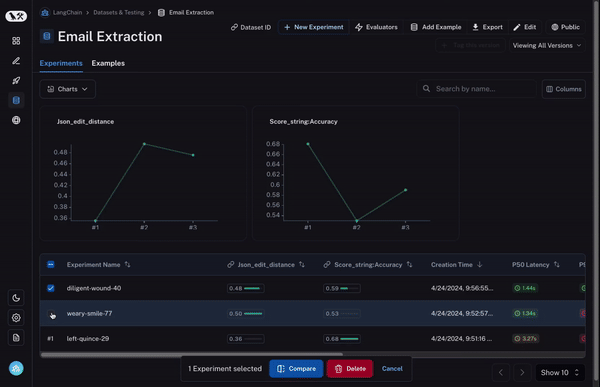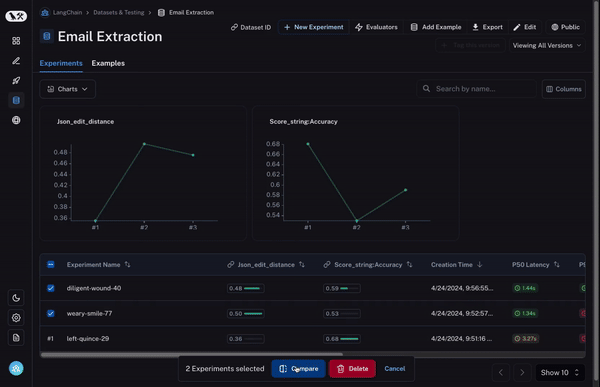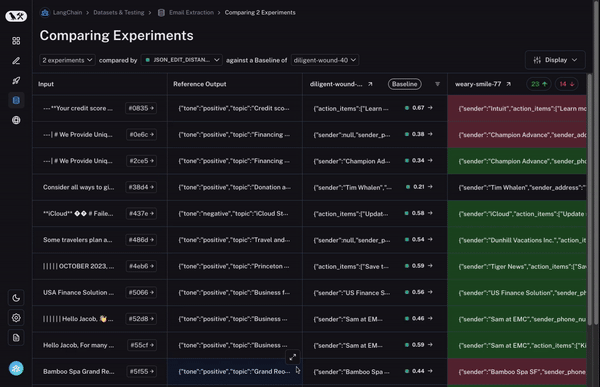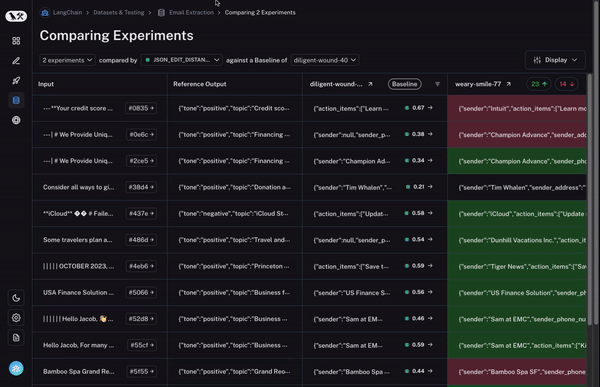
第三 - 也是最重要的 - 您希望能够快速深入研究在两次运行之间表现不同的数据点!如果它们的行为不同 - 那里肯定发生了有趣的事情!那么我们如何实现这一点?
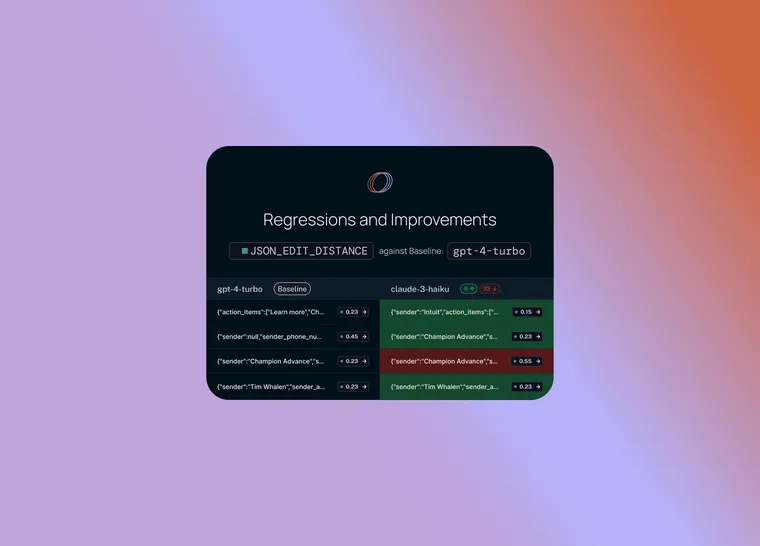
首先,我们设置一个基准运行。然后,我们采用您计算的评估指标之一,并自动突出显示与基准相比在该指标上增加或减少的数据点。这将使一些单元格变为绿色或红色。

但这还不是全部!您可以通过选择列顶部的切换按钮轻松过滤到仅增加/减少的数据点。如果您有大量数据点,这可以让您快速深入研究最有趣的数据点。
最后,一旦您确定了您感兴趣的行,您可以轻松展开该行,以更全面和具体地查看该数据点以及不同运行在其上的表现。
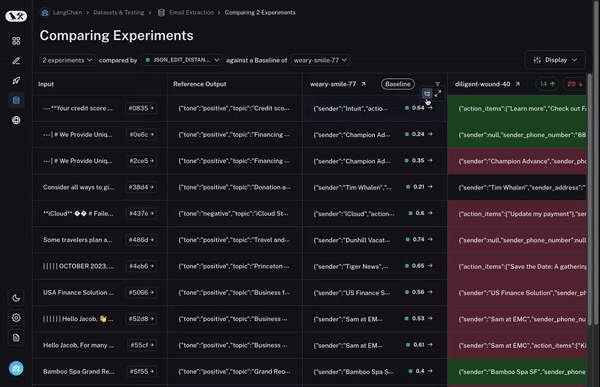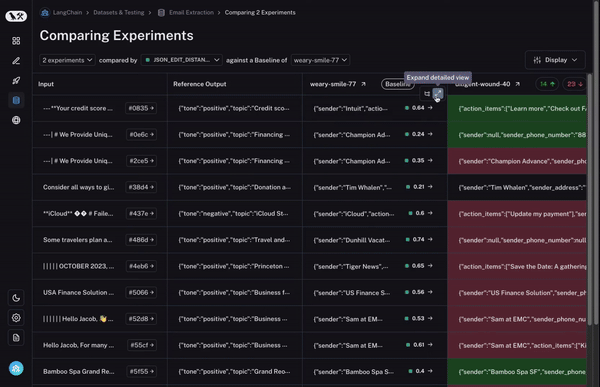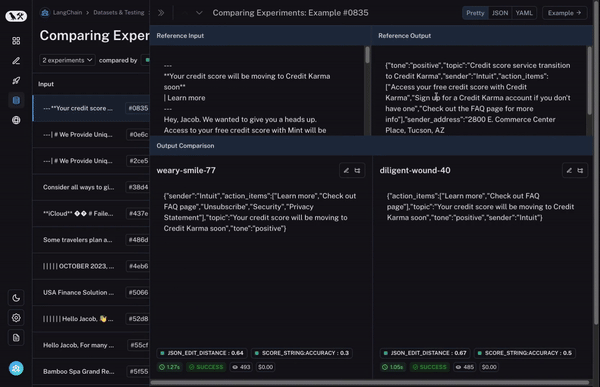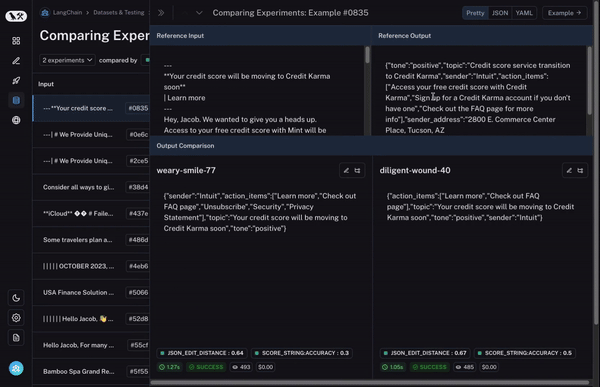
这些功能使您可以轻松地跨多个评估运行探索数据。这种类型的探索对于能够快速迭代至关重要。比较多次运行的概念是 AI 和软件测试之间不同的现象,我们还有一些更强大的功能(即将推出!)使这变得更加容易!
如果视频形式更符合您的风格,您可以查看我们的 YouTube 演示 此处。免费注册 LangSmith 此处 亲自试用!