随着 2023 年接近尾声,Graphite 希望庆祝 GitHub 用户在过去一年中的贡献。目标是在年末为开发者们献上一份礼物,让他们回顾、反思,并为新的一年感到鼓舞。
作为 GitHub Wrapped 的创建者,这是我们在 2021 年构建并扩展到 1 万用户的项目,我们在 Rubric 的团队完全有能力承担这项任务。
然而,2023 年与往年不同。2023 年是 LLM 变得普遍可用的一年。
与 2021 年相比,我们感觉机会之门已经为我们敞开,我们希望超越之前所做的静态图像和模板化故事情节。相反,我们想创造真正个性化、对最终用户完全独特的东西。我们也希望它是沉浸式的。因此,Year in code 诞生了——个性化的 AI 生成视频!
我们最终利用 LangChain 来构建这个,这并不令人意外。LangChain 开箱即用的辅助功能帮助我们在几天而不是几周内完成产品上线。
重要链接
技术栈
- GitHub GraphQL API 用于获取 GitHub 统计数据
- LangChain.js & OpenAI GPT-4-turbo 用于生成
video_manifest(视频脚本) - Remotion 用于创建和播放视频
- AWS Lambda 用于渲染视频
- AWS S3 用于存储视频
- Three.js 用于 3D 对象
- Supabase 用于数据库和身份验证
- Next.js 13 用于前端
- Vercel 用于托管
- Tailwind 用于样式设计
- Zod 用于模式验证
架构
概述
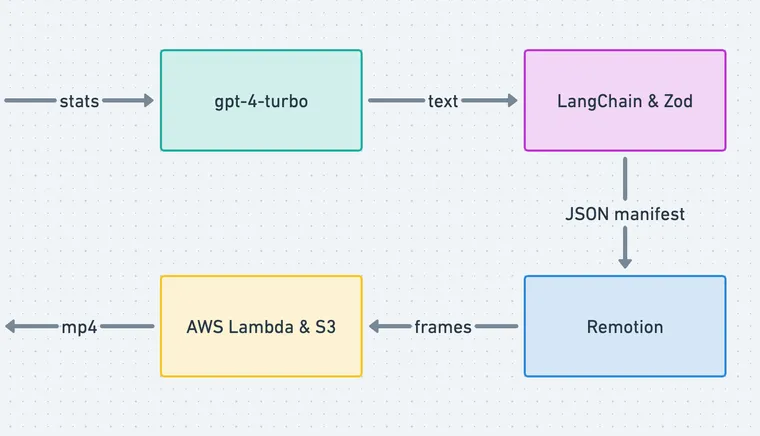
让我们用图表总结一下架构
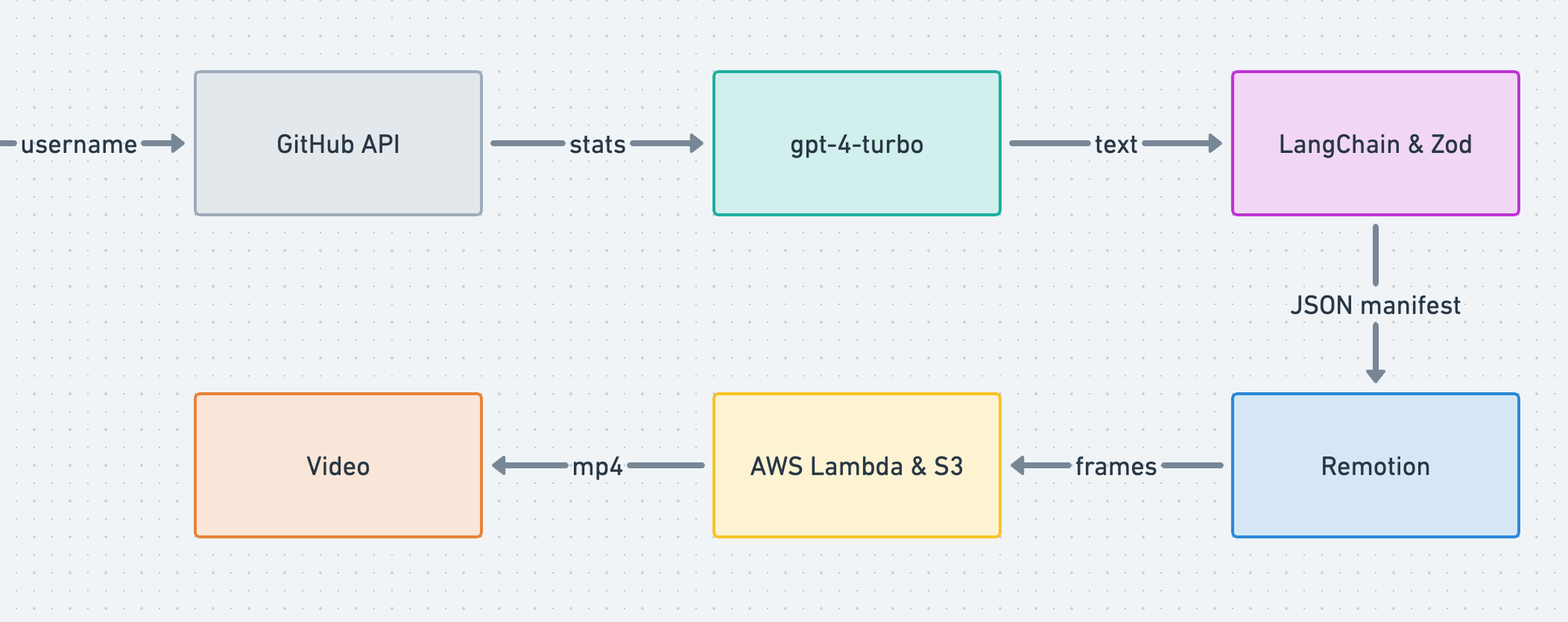
我们首先使用 Supabase auth 对 GitHub 用户进行身份验证。身份验证后,我们从 GitHub GraphQL API 获取用户特定数据,并将其存储在 Supabase 上托管的 PostgreSQL 数据库中。Supabase 提供了一个开箱即用的 API,带有 行级安全性 (RLS),可简化数据库的读取/写入操作。
此时,我们使用 LangChain 将用户统计数据传递给 LLM (gpt-4-turbo)。利用提示工程、函数调用 和 Zod 模式验证,我们能够生成名为 video_manifest 的结构化输出。可以将其视为视频的脚本。
此 manifest 被传递给 Remotion player,它允许在运行时轻松地将 Remotion 视频嵌入到 React 应用程序中。该 manifest 映射到一组 React 组件。
此时,用户可以在客户端播放视频,也可以与朋友分享他们的 URL。Next.js 13 服务器渲染模式 使最终用户体验流畅。此外,用户可以通过使用 AWS lambda 在云端渲染视频并将视频存储在 S3 存储桶中来下载 .mp4 文件以便于共享。
让我们更详细地探讨这一点。
获取统计数据
当您使用 GitHub 登录应用程序时,我们会立即获取您的一些统计数据。这些包括
- 您最常编写的语言
- 您贡献过的仓库
- 您给予和收到的 star,以及
- 您最新的朋友。
我们还获取您的提交总数、拉取请求和已打开的 issue。查看下面的类型以了解我们获取的数据。我们希望在此处注意 scope,因此我们请求最必要的权限,不包括任何代码访问权限。该项目也是完全开源的,以增强最终用户的信任。
interface Stats {
username: string
year: number
email: string
fullName: string
avatarUrl: string
company: string
commits: number
pulls: number
contributions: number
contributionsHistory: Week[]
repos: number
reviews: number
stars: Star
topRepos: Repo[]
topLanguages: Language[]
topFollows: Follows
firstContributionDate: string
codingStreakInDays: number
}生成 manifest
然后,我们通过 LangChain 将这些统计数据传递给 OpenAI 的 gpt-4-turbo 模型,以及关于如何格式化其响应的提示。这是提示
const prompt = ChatPromptTemplate.fromMessages([
[
'system',
`You are Github Video Maker, an AI tool that is responsible for generating
a compelling narative video based on a users year in code.
It is very important that this video feels personal, motivated by their
real activities and highlights what was special about that users year in code.
The goal of this video is to make the end user feel seen, valued and have a
nostalgic moment of review. You do not need to touch on everything, rather
hone in on and focus on the key elements that made this year special.
Make sure there is a story arch that builds over time, and that the video
has a clear beginning, middle and end. When choosing colors, make sure to hone in
on a definitive and aesthetically pleasing color palette, chosing complimentary
colors that aren't aggressively different.'
Videos must always have exactly 12 scenes.
Today's date (UTC) is ${new Date().toLocaleDateString()}.`
],
['human', `The GitHub stats are as follows: ${stats}`]
]);根据用户统计数据,AI 生成一个 video_manifest,它类似于视频的脚本。该 manifest 以 12 个序列(如提示中所定义)讲述一个独特的故事。假设每个序列持续 5 秒,这将始终生成一个 60 秒的视频。
在这里,我们遇到了一个具有挑战性的问题:我们是给予 AI 完全的创作自由,还是使用模板作为 AI 的护栏?
在进行了一些实验后,我们很快意识到,在给定的时间范围内,通过给予 AI 完全的创作自由,我们无法生成高质量的视频。虽然输出结果还不错,并且可以改进,但它还不足以产生那种怀旧的时刻,尤其是在我们拥有的工程时间内。
因此,我们采取了折衷方案,创建了一个“场景”库,并尽可能地对它们进行参数化。这使得 AI 能够根据用户的场景描述来选择最相关的场景。通过使用这些 AI 选择的场景,并传递用户特定的数据,我们能够生成个性化帧的独特序列。
这可以通过使用 OpenAI 的 Function Calling 来实现,它使 AI 能够输出可解析的文本,符合 Zod 模式。该模式使用 Zod 可辨别联合(不是摇滚乐队的名字)来区分场景
import z from 'zod'
export const videoSchema = z.object({
scenes: z
.array(
z.object({
text: z.string().describe('Displays on screen'),
animation: z
.discriminatedUnion('type', [
z
.object({
type: z.enum(['intro']),
planet: z
.enum([
'mars',
// ...
'venus',
'moon'
])
.describe('Pick a random planet!')
})
.describe(
'Text in front of a planet'
)
// ...
])
.describe('Animation to be used to display alongside the text')
})
)
.describe('Scenes in the video')
})
export type Manifest = z.infer<typeof videoSchema>让我们看一个示例输出视频 manifest。
[
{
"text": "Sarim Malik's Year in Code",
"animation": {
"type": "intro",
"planet": "mars"
}
},
{
"text": "A journey through time and code...",
"animation": {
"type": "flashback",
"dateTo": "2023-01-25T00:00:00Z",
"dateFrom": "2023-12-19T00:00:00Z"
}
},
...
]示例视频 manifest
manifest 中的每个条目(场景)都是一个对象,它具有文本字段和动画字段。每个场景的文本都是唯一的,场景的顺序也是唯一的,而每个场景的动画是从预构建组件库中选择的。
播放视频
现在是有趣的部分:播放实际视频。这部分具有挑战性,因为我们实际上是让 AI 指导我们将要剪辑在一起的视频。从导演剪辑版中,我们将场景映射到 React 组件,Remotion 使用这些组件生成视频。看看
export const Video = ({video}) => {
const {fps} = useVideoConfig()
return video.scenes.map(({text, animation}, i) => {
switch (animation?.type) {
case 'languages':
return (
<Languages from={i * fps * 5} languages={animation.languages} />
)
case 'people':
return (
<People from={i * fps * 5} people={animation.people} />
)
// ...
default:
return (
<Conclusion from={i * fps * 5} text={text} />
)
}
})
}在客户端播放视频
在这里,from 属性决定了此场景何时出现的第一帧。
为了生成 3D 对象,我们利用了 Three.js。例如,为了从扁平的星系图像中塑造出这种虫洞效果,我们将 Three 的 TubeGeometry 推向了极限,使用了高多边形计数和低半径。

现在,我们希望这种体验能够通过尽可能轻量化来实现扩展。通过保存 video_manifest 而不是实际视频,我们将项目的大部分带宽和存储空间减少了 100 倍。这种方法的另一个好处是视频实际上是交互式的。
渲染视频
由于我们在客户端使用 React 组件映射 manifest,因此要将视频下载为 .mp4,我们必须先渲染视频。这是通过使用 Remotion lambda 利用 10,000 个并发 AWS Lambda 实例并将文件存储在 S3 存储桶中来实现的。每个用户只需渲染一次视频,之后我们将他们的下载 URL 存储在 Supabase 中以便后续下载。
这一步是整个过程中最昂贵的,我们有意在此步骤中增加了一些摩擦,以便只有最关心分享视频的用户最终执行此步骤。
结论
这个项目使用了所有最新的技术:服务器端渲染、开源数据库、LLM、3D、生成式视频。这些听起来像是流行语,但每项技术都在这个项目中得到了非常有意的使用。我们希望它能激发您在 2024 年构建新事物的灵感!
准备好起飞了吗?试试 Year in code。将您的击键转化为星尘。在您的回顾中找到慰藉,让其他人加入您的旅程,并与星际旅行者建立联系。
您的编年史等待着您。
感谢阅读!如果您对此帖子有反馈,请通过 hello@rubriclabs.com 与我们联系。