编者按:我们非常激动地重点介绍伯克利的 Ankush Garg 和 Shreya Shankar 的这项研究。在 LangChain,我们考虑的两个最大的问题是评估(evals)和智能体(agents),而这项研究正处于这两者的交叉点。您今天就可以在他们的 Python 包中试用它。
TLDR: 它帮助您在 LLM 链中找到性能不佳的节点。
它解决的问题
构建 LLM 驱动的应用程序具有挑战性,并且随着 LLM 链的复杂性增加而倍增,这些链条可能每个查询都有多个 LLM 调用。

虽然评估最终输出对于确保 AI 应用程序按设计工作至关重要,但中间输出的评估在很大程度上被忽略了。这很可能是由于应用程序开发人员可能存在的资源限制。
LLM 链中的单个节点可能会导致整个链发生故障,产生连锁反应,使其难以调试和修复。
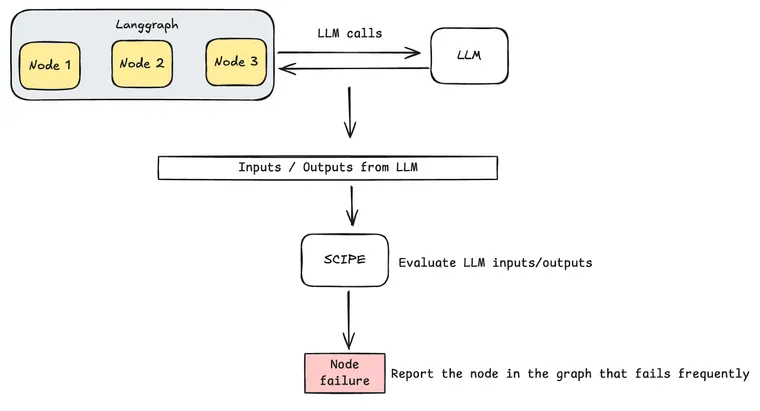
在这篇文章中,我们介绍 SCIPE,这是一个轻量级但功能强大的工具,可对 LLM 链执行错误分析。这个工具可以使任何创建依赖 LLM 进行决策和执行任务的应用程序的人受益。
SCIPE 的工作原理是分析 LLM 链中每个节点的输入和输出,并识别最重要的待修复节点——如果提高准确性,该节点将最大地提高最终或下游输出的准确性。
您可以在我们的 Colab Notebook 中试用 SCIPE。
技术细节 - 工作原理
SCIPE 的工作原理是分析应用程序图中节点的失败概率,以识别影响最大的故障来源。重要的是,它不需要标记数据或ground truth 示例即可执行此分析。它解决的核心问题是
哪个节点的失败对最下游节点的失败影响最大?
对于应用程序图中的每个节点,SCIPE 建模了可能发生的两种不同类型的故障
- 独立故障:当节点本身(或处理它的 LLM)可能是故障的主要原因时,就会发生这些故障(即,即使其上游依赖项正确,节点也会失败)。
- 依赖故障:当一个或多个上游依赖项失败时,节点失败时会发生这些故障。
为了在不需要 ground truth 数据的情况下检测这些故障,SCIPE 使用 LLM 作为裁判来评估图中的每个节点。
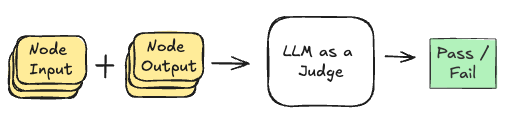
此评估过程为每个节点的每个输入和输出对创建一个通过/失败分数。然后,LLM 裁判确定在给定输入的情况下每个节点的输出是否有效,从而生成跨多个样本的节点评估的综合数据集。此数据集用于计算条件和独立失败概率,以查找有问题的节点。
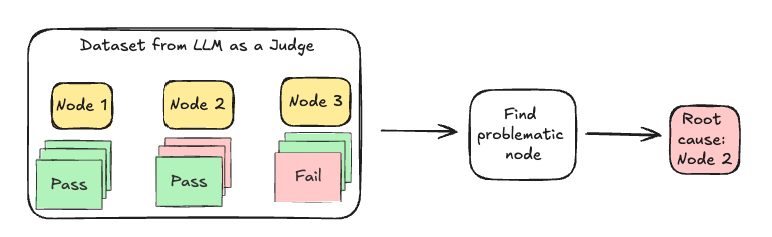
从最下游节点开始,SCIPE 计算条件失败概率,以了解每个节点的失败如何与其依赖项的失败相关。条件失败概率是节点失败率,而其依赖项(父节点)也失败。
如果一个节点没有依赖项,或者其独立失败概率在其本地邻域中最高,则它被识别为潜在的根本原因,从而结束分析。否则,分析将继续递归地向上游遍历图,直到找到真正的根本原因——即故障最有可能独立(源于自身而不是从其依赖项传播)的节点。
为了说明,以下是关于 SCIPE 如何查找有问题的节点的高级伪代码。
function find_root_cause(node, data, graph):
calculate probabilities for node (overall, independent, and dependent)
if node has no dependencies or independent failure probability is highest:
mark node as root cause
return node
else:
find dependency with highest conditional failure probability
recursively call find_root_cause on that dependency
function find_problematic_node(data, graph):
identify the most downstream node in the graph
root_cause = find_root_cause(downstream_node, data, graph)
calculate probabilities for all nodes in the graph
construct debug trace from downstream node to root cause
return EvaluationResult(root_cause, debug_path, node_results)
入门:先决条件
如果您在您自己的应用程序上使用 SCIPE,您将需要以下内容:
图
来自 Langgraph 的已编译图。我们需要访问内部图结构来运行 SCIPE。
应用程序响应
我们需要应用程序中所有节点的提示和 LLM 响应作为数据框。我们需要这个来运行验证并识别以最高速率失败的节点。
应用程序响应数据框的每一行都是一个通过整个 LLM 图级联的单个用户查询。以下是应用程序输入/输出响应数据框的几个示例行。

在这个例子中,我们有数据框的两行,其中包含 3 个 LLM 调用,每个调用负责一个步骤。
- 编辑 PII
- 提取有用信息
- 总结聊天内容
配置
- PATH_TO_SAVE_VALIDATIONS - 用于保存 LLM 作为裁判响应的路径
- MODEL_NAME - 此处要使用的模型。我们支持 LiteLLM 支持的所有模型
- node_input_output_mappings - 这创建了应用程序图和应用程序响应之间的关系。
一旦我们有了应用程序响应、已编译的图并设置了配置文件,我们就可以运行验证并找到具有高失败率的节点。
示例:如何使用 SCIPE
SCIPE 使用来自 LangGraph 的已编译 StateGraph,我们将通过使用 convert_edges_to_dag 函数将其转换为轻量级格式。
from scipe.middleware import convert_edges_to_dag
# Convert a compiled langgraph into a lightweight dag
converted_graph = convert_edges_to_dag(graph=graph)为评估器定义配置。
config = {
PATH_TO_SAVE_VALIDATIONS’: ‘validations.csv’,
‘MODEL_NAME’: ‘claude-3-5-sonnet-20240620’,
# Input and Output mappings for SCIPE
‘node_input_output_mappings’: {
‘pii_agent’: [‘pii_agent_input’, ‘pii_agent_output’],
‘extractor’:[‘extractor_input’, ‘extractor_output’],
‘Summarizer’: [‘summarizer_input’, ‘summarizer_output’]
}
}
然后,我们可以从 scipe 导入 LLMEvaluator,并通过传入 config、responses(应用程序响应)和我们转换的图来实例化一个对象。
from scipe import LLMEvaluator
evaluator = LLMEvaluator(
config=config,
responses=application_responses, # DataFrame input/output pairs
graph=converted_graph # Converted Langgraph
)LLMEvaluator 简化了在应用程序响应上管理/运行基于 LLM 的评估,然后在应用程序图中查找有问题的节点。首先,它基于 configs 中的 node_input_output_mappings 从应用程序响应中构建输入和输出对。然后,它使用 LLM 作为裁判运行验证,并将验证保存到 config 中的 PATH_TO_SAVE_VALIDATIONS。
results = evaluator.run_validation(
special_instructions=None
).find_problematic_node()
注意:run_validation 方法可以接收 special_instructions,我们可能希望将其传递给 LLM 裁判。这些指令将附加到 SCIPE 内部使用的 LLM 裁判提示中。
find_problematic_node() 方法遍历图以找出哪个节点的失败率最高。一旦找到有问题的节点,算法就会停止并返回结果。
输出是一个 EvaluationResult,其中包含根本原因、调试路径(从终端节点向后)以及每个节点的失败率。
您可以通过将结果转换为 JSON 来查看算法的结果。
results.to_json()Output:
{'root_cause': 'pii_agent',
'debug_path': ['summarizer', 'extractor', 'pii_agent'],
'node_results': {'summarizer': {'overall_failure_probability': 1.0,
'independent_failure_probability': 0.0,
'conditional_failure_probabilities': {'extractor': 1.0},
'dependencies': ['extractor'],
'is_root_cause': False},
'extractor': {'overall_failure_probability': 1.0,
'independent_failure_probability': 0.0,
'conditional_failure_probabilities': {'pii_agent': 1.0},
'dependencies': ['pii_agent'],
'is_root_cause': False},
'pii_agent': {'overall_failure_probability': 1.0,
'independent_failure_probability': 1.0,
'conditional_failure_probabilities': {},
'dependencies': [],
'is_root_cause': True}}}
应用程序开发人员可以使用 LLM 链中有问题的节点的失败概率来进一步探索导致此节点失败的原因以及可以采取哪些措施来修复它。此处的结果输出告诉我们,pii_agent 节点是根本原因,与其他节点相比,它以更高的速率独立失败,应该对其进行修复/改进。
结论
总之,SCIPE 分析独立和依赖失败概率,以识别系统中影响最大的有问题的节点。这有助于开发人员查明和修复其基于 LLM 的应用程序图中的问题,从而提高整体性能和可靠性。
我们正在积极开发 SCIPE,并期待收到您的来信!如果您有兴趣参与我们的用户研究、对该工具提供反馈或希望随时了解未来的发展,请发送电子邮件至 ankush-garg@berkeley.edu。