摘要
跨越多种数据类型(图像、文本、表格)的无缝问答是 RAG 的圣杯之一。我们发布了三个新的 cookbook,展示了 多向量检索器 在包含多种内容类型文档上的 RAG 应用。这些 cookbook 还展示了一些将 多模态 LLM 与多向量检索器配对以解锁图像 RAG 的想法。
背景
LLM 可以通过至少两种方式获取新信息:(1)权重更新(例如,微调)和(2)RAG(检索增强生成),它通过提示将相关上下文传递给 LLM。RAG 在 事实性 召回 方面尤其有前景,因为它将 LLM 的推理能力与外部数据源的内容结合起来,这对于企业数据而言 尤其强大。

改进 RAG 的方法
已经开发了许多改进 RAG 的技术
| 想法 | 示例 | 来源 |
|---|---|---|
| 基础案例 RAG | 对嵌入的文档块进行 Top K 检索,返回文档块用于 LLM 上下文窗口 | LangChain 向量存储, 嵌入模型 |
| 摘要 嵌入 | 对嵌入的文档摘要进行 Top K 检索,但返回完整文档用于 LLM 上下文窗口 | LangChain 多向量检索器 |
| 窗口化 | 对嵌入的块或句子进行 Top K 检索,但返回扩展窗口或完整文档 | LangChain 父文档检索器 |
| 元数据过滤 | 使用按元数据过滤的块进行 Top K 检索 | 自查询检索器 |
| 微调 RAG 嵌入 | 在您的数据上微调嵌入模型 | LangChain 微调指南 |
| 两阶段 RAG | 第一阶段关键词搜索,然后是第二阶段语义 Top K 检索 | Cohere 重排序 |
将 RAG 应用于多样化数据类型
然而,在包含半结构化数据(结构化表格和非结构化文本)和多种模态(图像)的文档上进行 RAG 仍然是一个挑战。随着 一些 多模态 模型 的出现,现在值得考虑统一的策略,以在跨模态和半结构化数据上实现 RAG。
多向量检索器
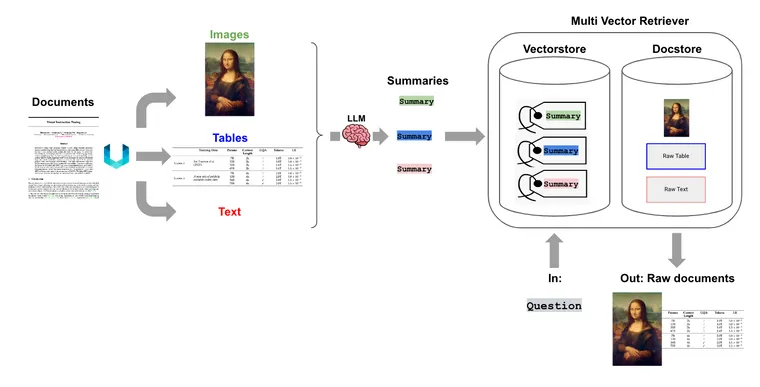
早在八月份,我们发布了 多向量检索器。它使用了一个简单而强大的 RAG 思想:将用于答案合成的文档与用于检索器的参考解耦。作为一个简单的例子,我们可以创建一个针对基于向量的相似性搜索优化的冗长文档摘要,但仍然将完整文档传递到 LLM 中,以确保在答案合成期间不会丢失任何上下文。在这里,我们展示了这种方法不仅对原始文本有用,而且可以普遍应用于表格或图像以支持 RAG。
文档加载
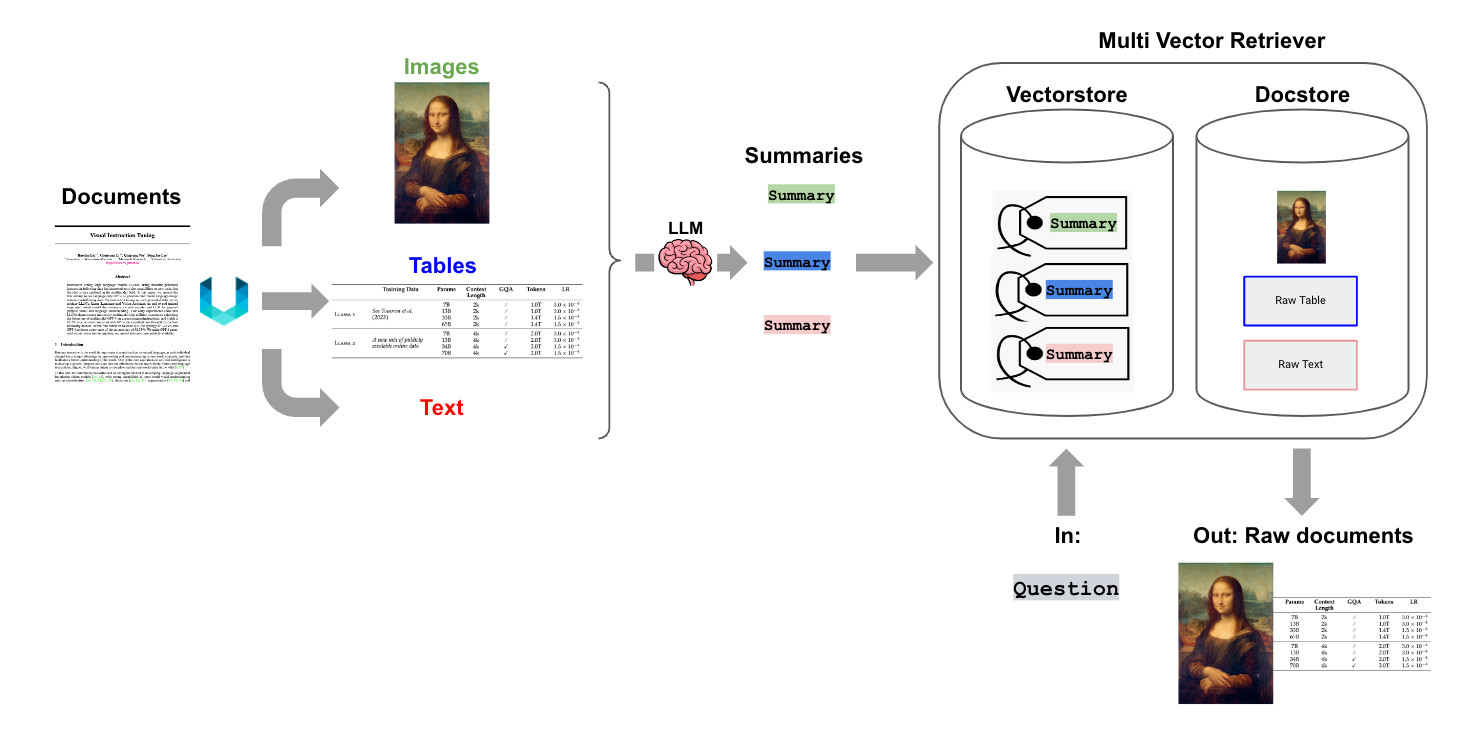
当然,为了实现这种方法,我们首先需要能够将文档划分为其各种类型。Unstructured 是一个非常适合此目的的 ELT 工具,因为它可以从多种文件类型中提取元素(表格、图像、文本)。
例如,Unstructured 将通过首先删除所有嵌入的图像块来 分割 PDF 文件。然后,它将使用布局模型(YOLOX)来获取边界框(用于表格)以及 titles,它们是文档的候选子章节(例如,Introduction 等)。然后,它将执行后处理以聚合每个 title 下的文本,并根据用户指定的标志(例如,最小块大小等)将文本进一步分块为文本块,以进行下游处理。
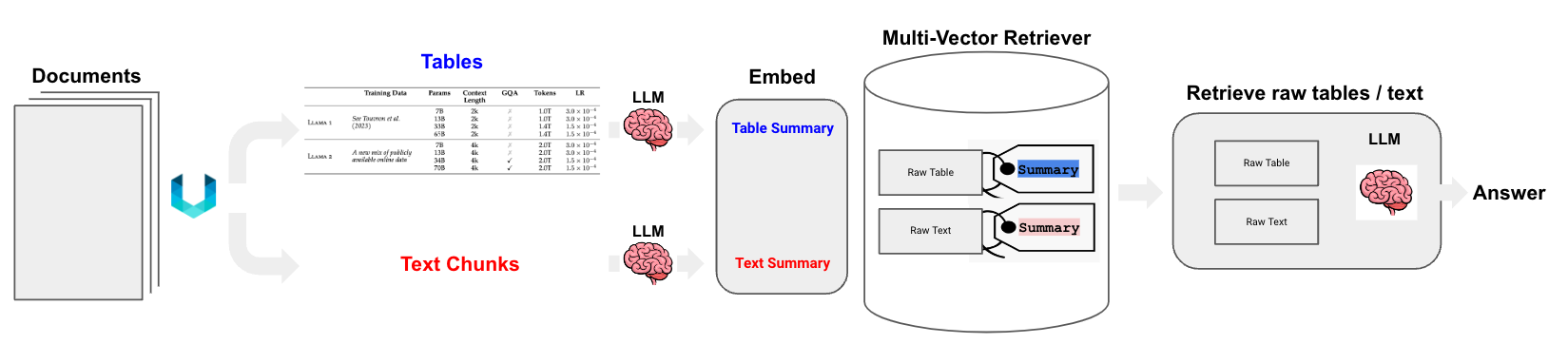
半结构化数据
Unstructured 文件解析和多向量检索器的结合可以支持在半结构化数据上进行 RAG,这对于可能分割表格的朴素分块策略来说是一个挑战。我们生成表格元素的 摘要,这更适合自然语言检索。如果通过与用户问题的语义相似性检索到表格摘要,则原始表格将如上所述传递给 LLM 以进行答案合成。请参阅下面的 cookbook 和图表
多模态数据
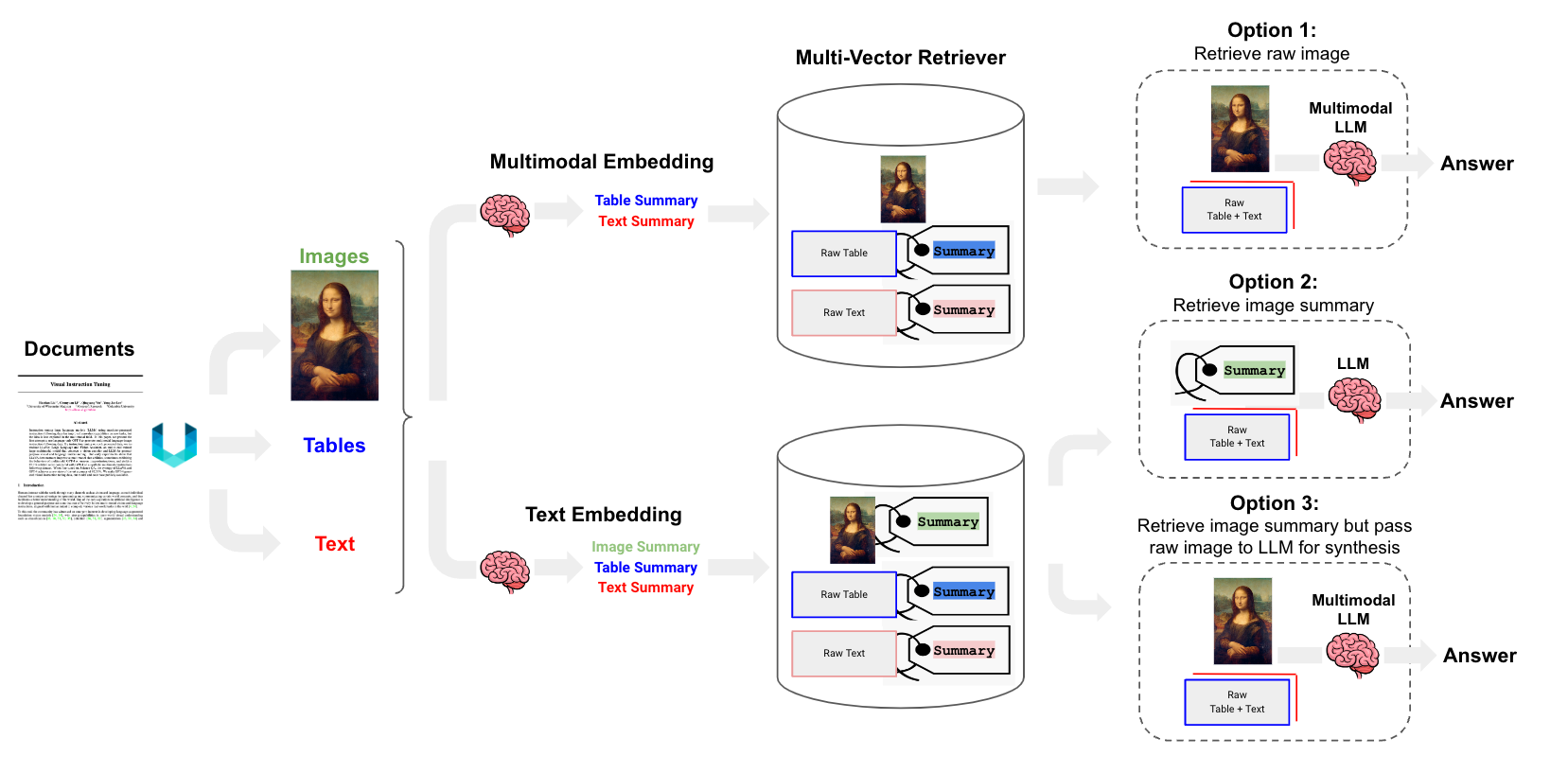
我们可以更进一步考虑图像,随着 GPT4-V 和 LLaVA 以及 Fuyu-8b 等开源多模态 LLM 的发布,图像正迅速成为可能。至少有三种方法可以解决这个问题,它们都利用了上面讨论的 多向量检索器 框架
选项 1: 使用多模态嵌入(例如 CLIP)将图像和文本一起嵌入。使用相似性搜索进行检索,但只需链接到文档存储中的图像。将原始图像和文本块传递给多模态 LLM 进行合成。
选项 2: 使用多模态 LLM(例如 GPT4-V、LLaVA 或 FUYU-8b)从图像生成文本摘要。使用文本嵌入模型嵌入和检索文本摘要。并且,再次,从文档存储中引用原始文本块或表格,以供 LLM 进行答案合成;在这种情况下,我们将图像从文档存储中排除(例如,因为无法实际使用多模态 LLM 进行合成)。
选项 3: 使用多模态 LLM(例如 GPT4-V、LLaVA 或 FUYU-8b)从图像生成文本摘要。嵌入和检索图像摘要,并引用原始图像,就像我们在选项 1 中所做的那样。并且,再次,将原始图像和文本块传递给多模态 LLM 进行答案合成。如果我们不想使用多模态嵌入,这个选项是明智的。
我们使用 7b 参数 LLaVA 模型 (权重在 这里 可用)测试了 选项 2,以生成图像摘要。LLaVA 最近被添加到 llama.cpp 中,这使其可以在消费级笔记本电脑(Mac M2 max,32gb ~45 token / 秒)上运行,并生成合理的图像摘要。例如,对于下面的图像,它捕捉到了幽默感:图像特写了一个装满各种炸鸡块的托盘。鸡块的排列方式类似于世界地图,一些块被放置成大陆的形状,另一些则被放置成国家的形状。鸡块的排列创造了一个视觉上吸引人且有趣的的世界 representation。

我们将这些与表格和文本摘要一起存储在 多向量检索器 中。
如果数据隐私是一个问题,则可以使用开源组件在消费级笔记本电脑上本地运行此 RAG 管道,使用 LLaVA 7b 进行图像摘要,Chroma 向量存储,开源嵌入 (Nomic’s GPT4All),多向量检索器,以及通过 Ollama.ai 的 LLaMA2-13b-chat 进行答案生成。
结论
我们表明,多向量检索器可以用于支持半结构化 RAG 以及带有模态数据的半结构化 RAG。我们还表明,这个完整的管道可以使用开源组件在消费级笔记本电脑上本地运行。最后,我们提出了三种用于多模态 RAG 的通用方法,这些方法利用多向量检索器概念,将在未来的 cookbook 中作为特色。