
作者:Shreya Shankar (加州大学伯克利分校),与 Haotian Li (香港科技大学), Will Fu-Hinthorn (LangChain), Harrison Chase (LangChain), J.D. Zamfirescu-Pereira (加州大学伯克利分校), Yiming Lin (加州大学伯克利分校), Sam Noyes (LangChain), Eugene Wu (哥伦比亚大学), Aditya Parameswaran (加州大学伯克利分校) 合作撰写
许多组织非常希望在自动化流水线或链中使用 LLM,用于生产环境。如果提示词设计得当,LLM 可以在各种领域的大规模应用中理解和生成数据及代码。
但是,评估针对自定义任务的 LLM 链 真的很难:提示词工程是一个临时的、迭代的过程,大多数人在没有明确的进展感以及链在生产环境中表现如何的情况下,摸索着部署链。当我们围绕 LLM 构建链时,很难扩展我们正在评估 LLM 的 “主观感受评估”。研究表明,强大的模型(如 GPT-4)在被指示评估什么时可以作为有用的评估器,但提出要评估的指标评分卡(以及相应的提示词)并非易事。
在伯克利,我们一直在思考如何为自定义 LLM 链自动编写有用的评估函数。我们意识到,当人们迭代提示词时,他们经常会将关键的评估标准、护栏和约束编码到他们对提示词的优化或更改中。理解提示词版本历史——或者我们喜欢称之为提示词优化分析——有一些明显的应用,例如自动编写提示词或生成用于微调的数据集。但是,如果提示词优化分析也可以识别有用的评估函数呢?这似乎是一项超级艰巨的任务,但事实证明,通过一些巧妙的分解,我们可以使用 LLM!
我们正在构建一个名为 SPADE ♠️,或提示词分析与基于增量评估系统 (System for Prompt Analysis and Delta-based Evaluation) 的工具,以自动推荐评估方法。我们很高兴与 LangChain 合作进行这个项目,并发布 SPADE 的原型。您可以粘贴您的提示词或链接到您的 LangSmith 提示词版本历史,基于您的提示词优化,SPADE 可能会建议您可以对所有链输入-输出(即,提示词-响应)对运行的自动评估函数(以 Python 编写)。评估函数的复杂程度各不相同,从断言 LLM 响应遵循特定格式(即,JSON 对象中包含某些键或 Markdown 对象中的标头)到验证 LLM 响应不会幻觉超出提示词中提供的来源。
在这篇博客文章中,我将解释该工具的工作原理。
使用 SPADE ♠ 深入挖掘 LLM 评估
在解释 SPADE 的工作原理之前,我将描述 LLM 链的一个具体应用和评估挑战。今年 5 月,当我开始与 Alta 合作时,我开始了解 LLM 链部署挑战,Alta 是一家构建人工智能驱动的个人造型师和购物助手的初创公司,旨在帮助解决一些 MLOps 问题。Alta 使用 LLM 链为用户指定的活动(如商务会议或工作活动)推荐一套搭配(即,上衣、下装、鞋子等)。
对于 Alta 的 LLM 链,虽然最初的提示词工程展示了令人印象深刻的搭配,但用户在部署过程中发现了很多错误。有时,LLM 会在一套搭配中返回两个相同类别的物品。有时,LLM 会返回不完整的搭配(例如,没有鞋子),或者不合适的搭配(例如,在晴朗的日子里为精致的搭配推荐雨靴)。“修复” bug 最快的方法是在提示词中添加新的指令,例如“不下雨时不要推荐雨靴。” 但是,这些优化最终堆积起来,使提示词变得冗长,并且无法真正保证 LLM 遵循每一条指令。
更智能地监控 LLM 响应——基于开发者在提示词优化中隐含编码的内容——将显著提高 LLM 部署的可靠性。SPADE 位于提示词版本历史之上,根据提示词优化本身建议评估函数。以下是在 Alta 如何完成此操作的示例。考虑提示词的 V1 和 V2 版本
V1:“为 {event} 建议 5 件服装。以 Python 字符串列表的形式返回您的答案”
V2:“一位客户({client_genders}) 希望为 {event} 进行造型。为 {client_pronoun} 建议 5 件服装。对于与婚礼相关的活动,不要推荐任何白色物品,除非客户明确表示他们希望为自己的婚礼进行造型。以 python 字符串列表的形式返回您的答案”
SPADE 首先找到版本之间的差异,即 v1 中不存在的任何新指令。在本例中,SPADE 将找到 两个新的占位符(性别和代词),以及一个 排除 婚礼相关活动白色物品的指令。然后,SPADE 使用 LLM 根据我们创建的描述提示词如何更改的分类体系(图 1)对该差异进行分类。
对于识别出的每个类别,SPADE 提示 LLM 编写相关的 Python 评估函数。SPADE 建议的评估函数接受提示词和响应对作为参数,并返回布尔值(即 True 或 False),以便可以在许多链运行中聚合和可视化它们。这些函数可以在没有 LLM 的情况下运行(例如,检查响应是否可以解析为 JSON 或具有特定键),或者利用辅助函数向 LLM 或人类专家提交是/否问题。
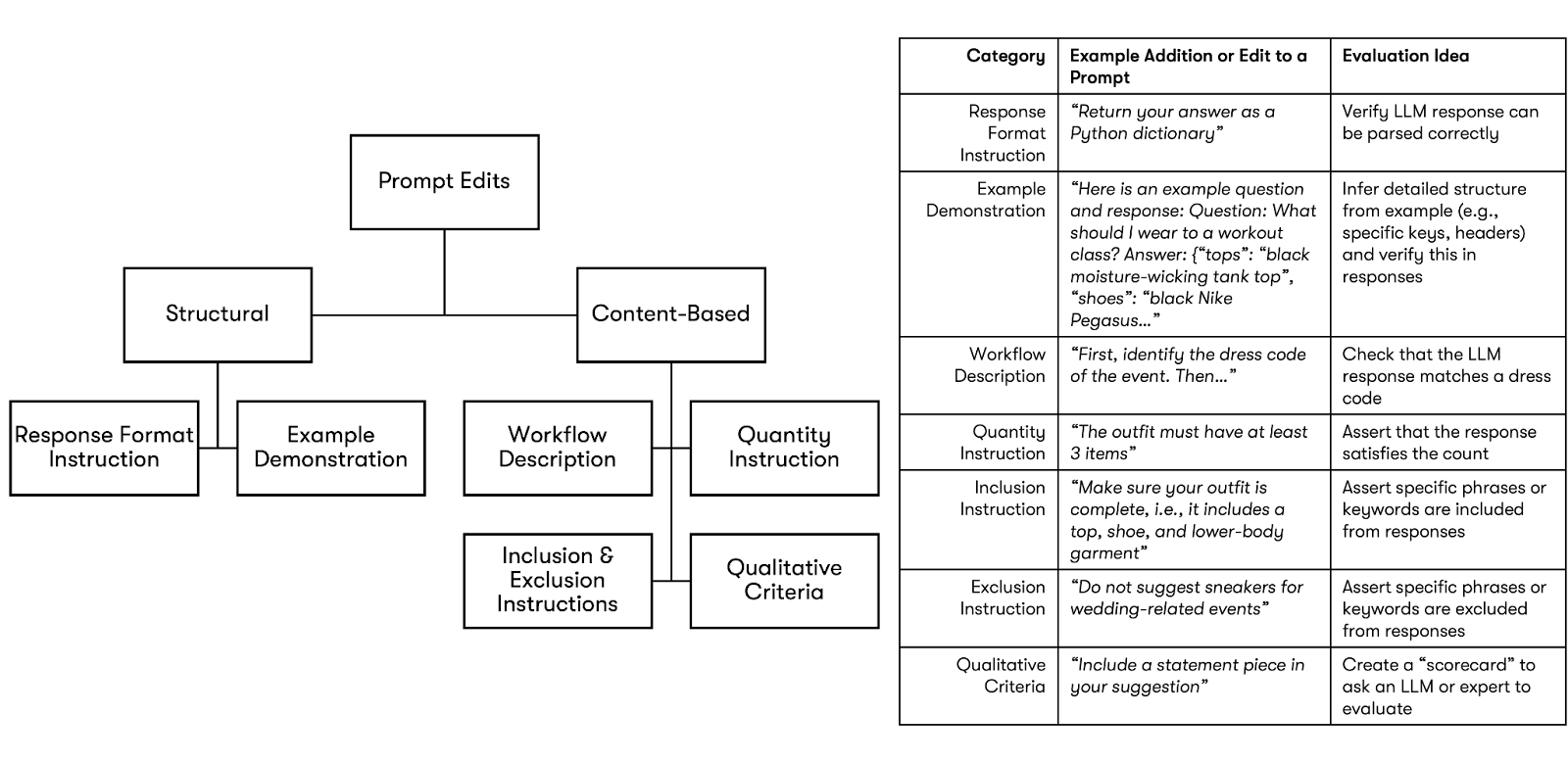
将所有这些放在一起,对于我们的示例,SPADE 会用数据集成和排除指令类别标记差异。由于在我们的分类体系中只有排除指令类别暗示了新的评估函数,因此 SPADE 将仅建议一个评估:一个检查提示词是否包含与婚礼相关的事件的函数,如果是,则检查响应中是否未包含颜色“白色”。
# Needs LLM: False
def check_excludes_white_wedding(prompt: str, response: str) -> bool:
"""
This function checks if the response does not include white items for wedding-related events,
unless explicitly stated by the client.
"""
# Check if event is wedding-related
if "wedding" in prompt.lower() and "my wedding" not in prompt.lower():
# Check if the response includes the word "white"
return "white" not in response.lower()
else:
return True
评估函数示例
当前原型和反馈
SPADE 的当前原型 建议您在链的输入和输出上运行评估函数。在应用程序中,您可以粘贴您想要为其生成评估的提示词模板(我们假设提示词的 V0 版本是一个空字符串),或者您可以指向您的 LangSmith 提示词模板(其中通过提交自动包含您的提示词版本历史)。我们会向您展示您的提示词在版本之间如何更改的所有类别,并根据这些类别为您的链建议特定的评估函数。
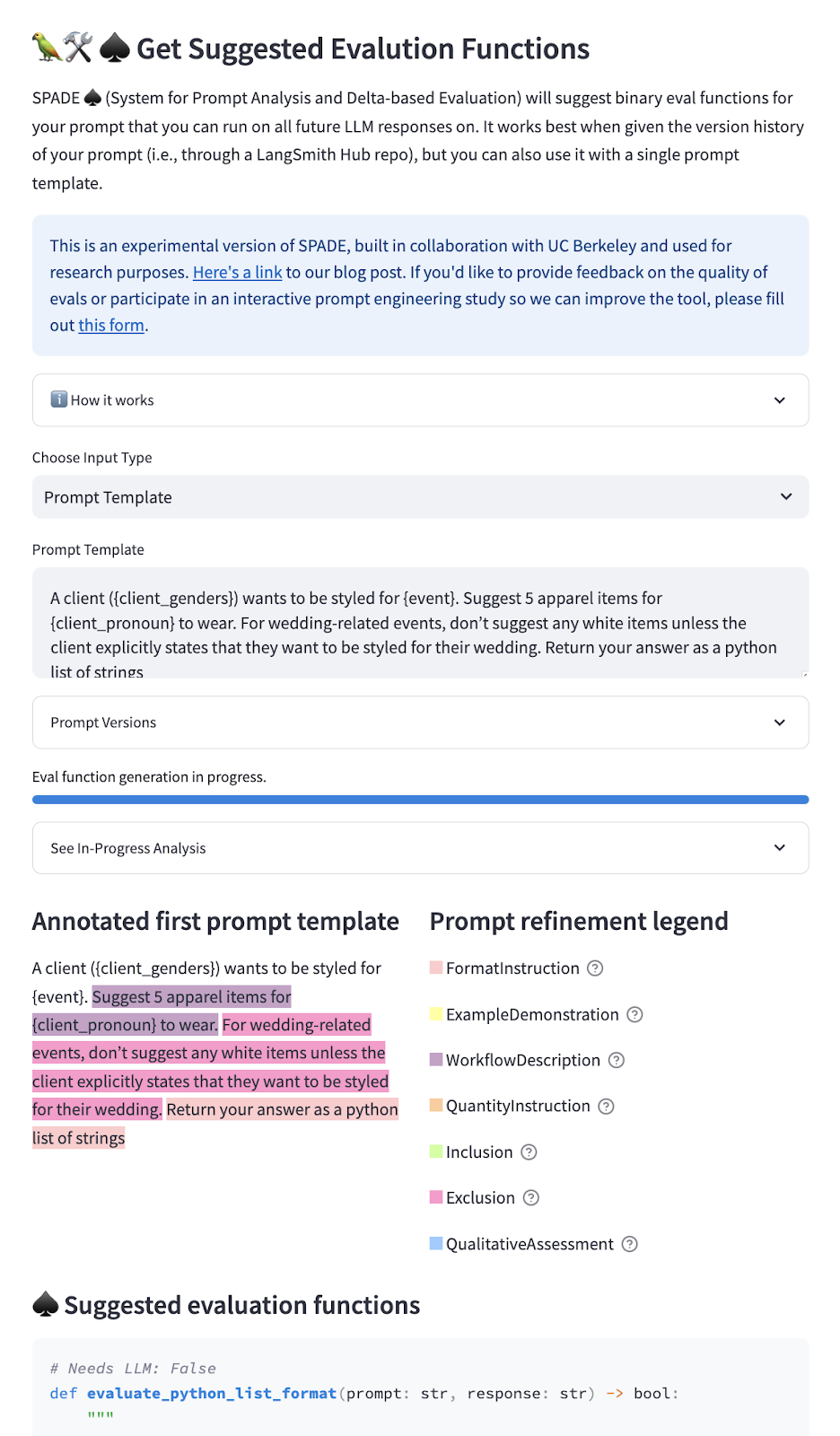
SPADE 的当前原型是一个非常初步的研究原型——有很多改进空间!它识别所有可能的提示词优化类别(来自我们的分类体系),并为指示相关评估的每个类别生成一个 Python 函数。因此,随着提示词版本的数量增加,建议的函数数量可能会激增。我们正在单独努力减少建议的函数数量,同时仍然涵盖失败模式,但对于当前原型,我们感兴趣的是,即使函数的含义有用,但函数的语法有点错误,建议的函数是否对开发人员有用。
虽然您可以对为您生成的函数提供明确的反馈,但如果您对更广泛的研究领域感兴趣,或者您想在可观测性工具中部署这些评估函数,请填写此 Google 表单,我们将与您联系。否则,我们感谢任何工具的使用和反馈。试用一下,让我们知道您的想法!