编者注:这篇文章由 Chris Pappalardo 撰写,他是 Alvarez & Marsal 的高级总监,Alvarez & Marsal 是一家全球领先的专业服务公司。使用 LLM 构建的标准流程非常适用于主要包含文本的文档,但对于包含表格数据(如电子表格)的文档效果不佳。我们在博客上撰写了关于我们最新的 CSV 数据问答思考几周前,我们很喜欢阅读 Chris 对使用代理、链、RAG 和元数据处理 CSV 和 LangChain 的探索。这里有很多很棒的学习内容!
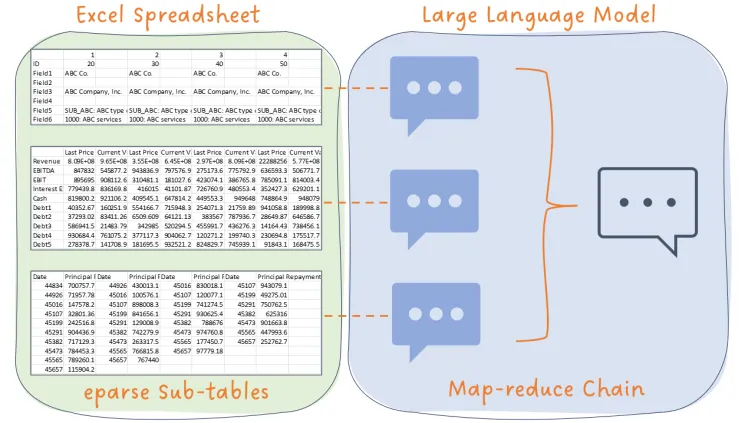
当我第一次坐下来编写 eparse 时,目标是创建一个库,它可以爬取和解析大量的 Excel 文件,并将上下文信息提取到存储中以供后续使用。为此,我们相当成功——eparse 可以使用基于规则的搜索算法提取子表格信息,并将标记的单元格存储为数据库中的行。假设用户对源文件中包含的内容有一个很好的了解,则可以使用 SQL 查询或 eparse CLI 来检索特定数据。
然而,文档提取、转换和加载(“ETL”)活动正变得越来越以生成式 AI 为导向,以促进文档摘要和检索增强生成(“RAG”)等活动。鉴于大多数文档主要包含文本,而大型语言模型(“LLM”)非常适合处理文本,因此许多 ETL 工具都是为此用例而构建的。这些目的的典型“快速入门”工作流程如下
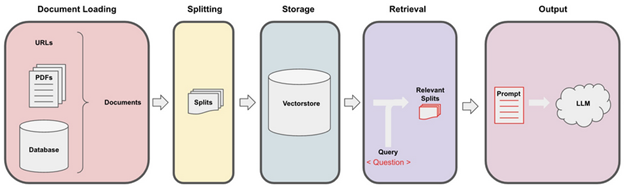
该过程首先使用像 unstructured 这样的 ETL 工具集,它识别文档类型,将内容提取为文本,清理文本,并返回一个或多个文本元素。第二个库,在本例中是 langchain,然后将文本元素“分块”为一个或多个文档,这些文档随后被存储,通常在向量数据库中,例如 Chroma。最后,可以使用 LLM 查询向量数据库以回答问题或总结文档的内容。
此过程对于主要包含文本的文档效果良好。但对于主要包含表格数据(例如电子表格)的文档效果不佳。
为了更好地理解这个问题,让我们考虑一个例子。在 eparse 代码仓库中,有一个名为 eparse_unit_test_data.xlsx 的单元测试数据文件,其中包含以下子表格,每个子表格都包含不同类型的财务数据
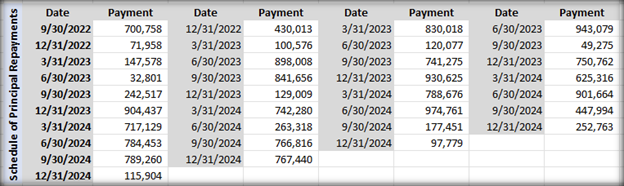
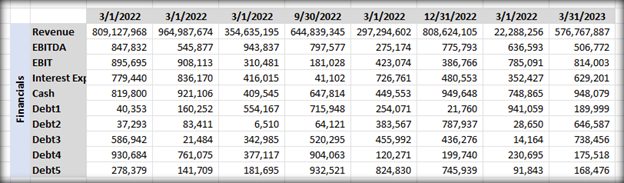
为了演示,我编写了一个 Gradio 应用程序来显示提取和分块的文本数据,以便更容易弄清楚库在幕后做什么。如果我们不进行任何修改就使用 unstructured 和 langchain,ETL 工作流程将从此文件中生成如下所示的文本块
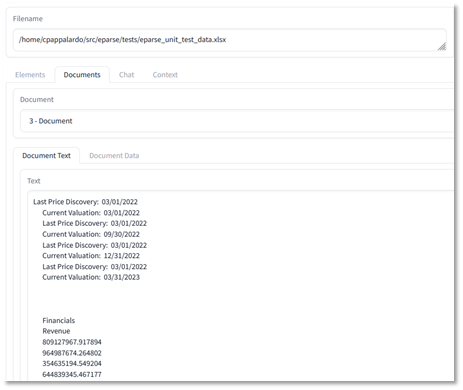
Unstructured 生成一个文本元素,LangChain 将其分成 14 块,其中第 3 块(“3 – 文档”)包含我上面描述的第一个子表格。此表中的每个单元格都是单独的一行,第 3 块包含大约 40 行,这不是整个表格。
当我第一次尝试要求 LLM 使用向量数据库总结文档时,我收到了上下文窗口溢出错误,原因是 token(大致相当于单词)的数量超过了 LLM 的上下文窗口大小(在本例中为 2k token)。这是使用 LLM 时常见的问题,我将在本文后面介绍。因此,为了解决这个问题,我使用了在更大的服务器上运行的更大的上下文窗口 LLM,并将 API 超时时间延长至 10 分钟。这次我们得到了不错的结果
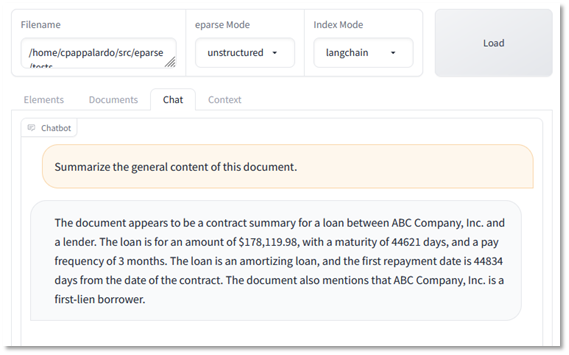
使用默认实现,LLM 理解了文件的某些方面,但没有对内容有一个很好的总体把握。此外,金额也不准确,贷款金额似乎比文件中的金额高出 10 倍,忽略了其他贷款,并且 LLM 误解了未格式化的 Excel 日期值(44,621 天的到期日将超过 122 年)。
eparse 在同一任务上的表现如何?
eparse 的做法略有不同。eparse 不会将整个工作表传递给 LangChain,而是会查找并传递子表格,这似乎在 LangChain 中产生了更好的分段效果。使用 eparse,LangChain 返回 9 个文档块,其中第 2 块(“2 – 文档”)包含整个第一个子表格。要求 LLM 使用这些向量总结电子表格,可以更全面地了解电子表格中包含的内容,包括子表格的细微差别,并且没有任何错误数据。
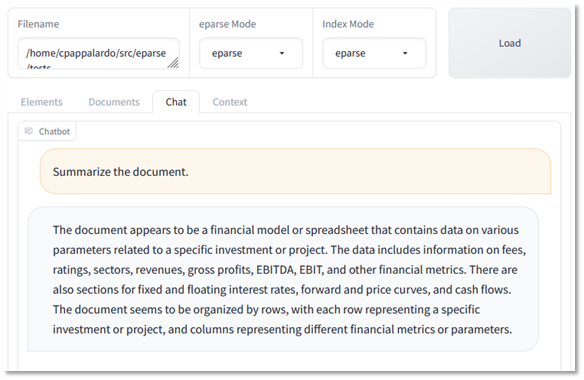
然而,LLM 会因单表上的行结构等吹毛求疵的事情而分心,并且仍然会弄错关于金额的基本问题

日期格式仍然不正确

更好的方法。
回顾一下,这些是使用 unstructured、eparse 和 LangChain 的默认实现以及这些工具的当前状态将 Excel 文件馈送到 LLM 时出现的问题
- Excel 工作表作为单个表格传递,默认的分块方案会打破逻辑集合
- 较大的块会给上下文窗口大小、GPU 内存和超时设置等约束带来压力
- 破碎的逻辑集合和默认的检索方案会产生不完整的摘要
- LLM 对向量化数据的离散值查找性能较差
- 默认数据清理无法处理某些事项,例如 Excel 数字日期编码
摘要的基本问题是,它是从多件事物到一句陈述的简化。单个文档检索问答应用程序的默认配置是查找文档的 4 个相似部分,并将它们“填充”到上下文窗口中,然后再请求摘要。
为了提高电子表格的检索和摘要性能,我们需要考虑其他检索策略。Damien Benveniste 最近在 LinkedIn 上发布了以下图表,该图表解决了处理太大而无法放入上下文窗口的多个文档的摘要问题
在我的 Gradio 应用程序中添加了链类型、搜索类型和 k-文档设置的选项后,我现在能够针对不同的 LLM 在不同的配置中测试这些策略中的每一种
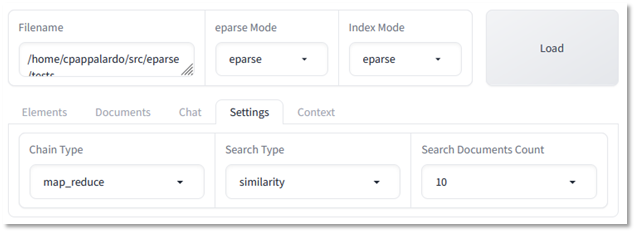
将链类型设置为“map reduce”(图 7 中的第二种策略)并增加检索文档的数量会产生更好的结果
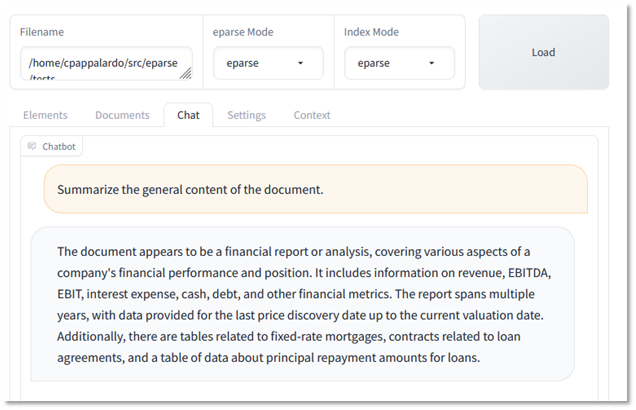
LLM 涵盖了各种提取的子表格中的所有主要主题,承认文档中的工具类型(债务),甚至提到了摊销计划。所有这些都没有无意义的数据元素。
打开链详细程度,我们可以了解幕后发生的事情(抱歉文本太小)
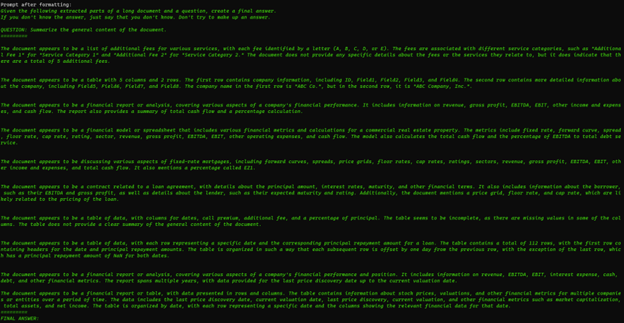
每个提取的子表格都由 LLM 总结,然后再将其注入到末尾的最终提示中以进行集体摘要,就像 map-reduce 图表所描述的那样。扩展 K-文档大小可确保考虑文件的较小细微差别。
您可能想知道“refine”策略,也可能想知道我们最初使用的小型上下文模型发生了什么。我尝试了使用较小模型的各种策略和组合,包括 refine,虽然我最终能够处理上下文窗口限制,但无论有没有 refine 策略,该模型都无法提供高质量的响应。我认为这个结果是较差的基础模型和 8 位量化的结合。最重要的是,至少要有一个 LLM 在超大型硬件上运行,并具有坚实的基础来进行测试,这是值得的。
那么特定数据检索呢?
使用 LLM 从电子表格表格中提取特定数据的解决方案将涉及代理设计模式,其中教导 LLM 使用它们可以调用的函数。代理的演示超出了本文的范围。但是,我们最近在 eparse 中添加了一些有助于这项工作的功能,我很兴奋与大家分享。
在 eparse 的 0.7.0 版本中,我们引入了实用程序函数和一个新接口,以实现从 HTML 表格到由 Sqlite 支持的 eparse 数据接口的无缝过渡。这意味着用户可以将他们的 LLM 连接到由 ETL 过程捕获的结构化表格数据,这些数据作为元数据存储在上传到向量存储的对象中。例如,以下 HTML 表格是 eparsing 单元测试电子表格的副产品
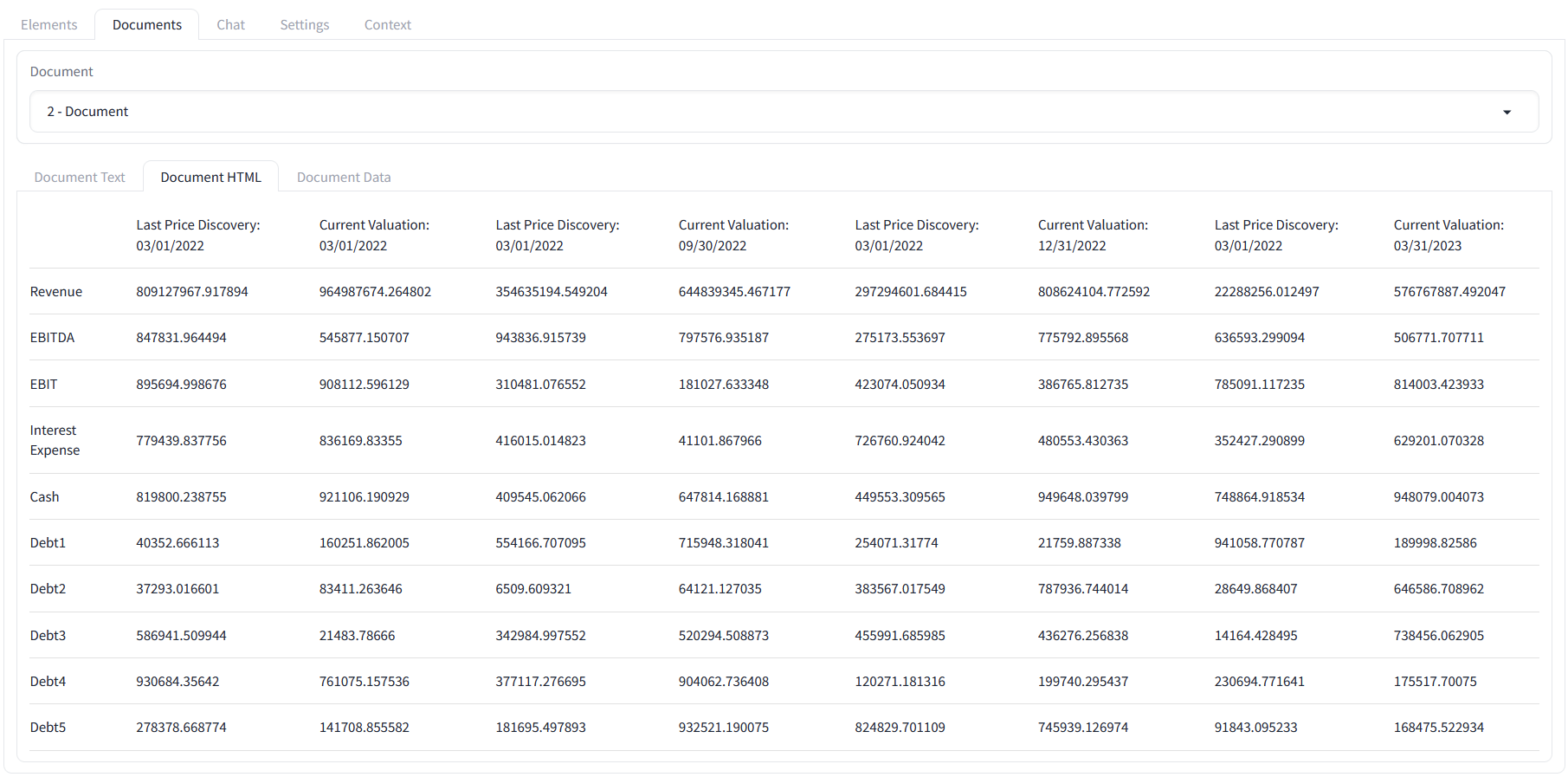
为了方便由 eparse 驱动的 ETL 管道,从 v0.7.1 开始提供了 unstructured 自动分区器和 Excel 分区器的直接替换(有关如何将这些函数合并到项目中的更多详细信息,请参阅 README)
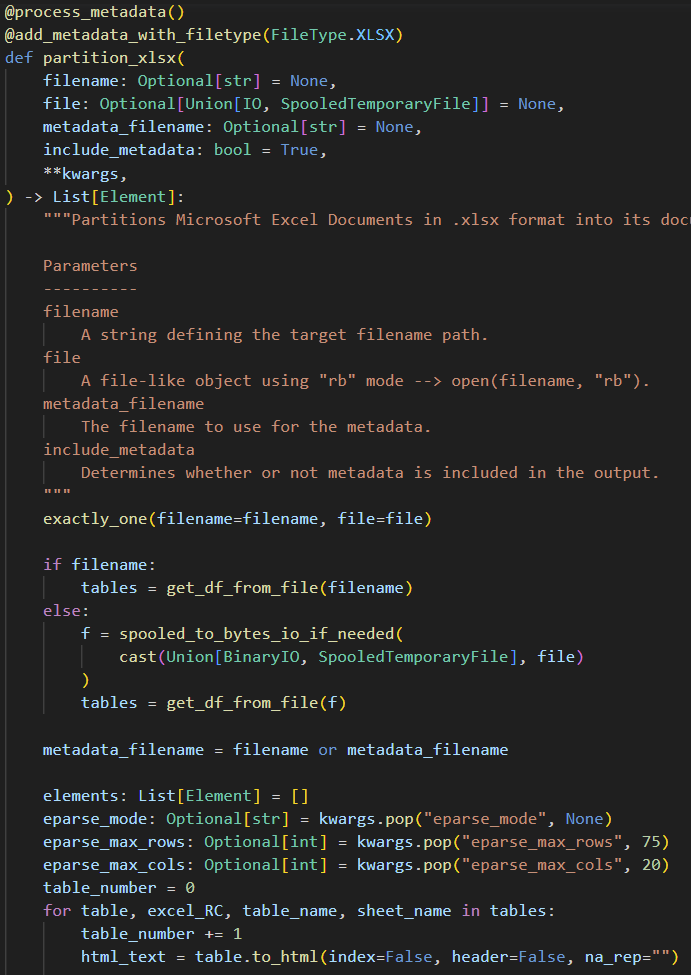
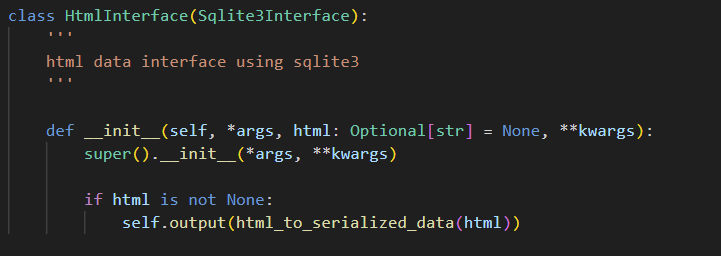
在带有代理工具的 LLM 链中使用 HTML 表格数据就像实例化以下新的 HTML 接口,然后像使用任何其他数据库 ORM 一样使用它一样简单
如何处理数字 Excel 格式化数据的转换?
处理诸如将 Excel 数字日期信息重新转换为正确格式之类的问题的最佳解决方案是使用 unstructured 库的自定义清理或暂存砖。有关清理砖以及如何应用它们的讨论在此。
结论
总之,从 Excel 电子表格中提取信息会带来许多 ETL 系统和典型的 LLM 工具集未考虑的独特问题。设计自己的解决方案时,需要考虑的关键点包括
- 电子表格在摄取/分块方面和检索方面都存在独特的问题
- 链的选择很重要,默认设置可能(且通常)效果不佳
- LLM 擅长文本,但不擅长数据,因此您可能需要代理解决方案才能从查询中获得准确的信息
- 并非所有 LLM 在摘要性能方面都相同
- 元数据很有价值,您可能低估了向量数据库中的数据