大多数复杂和知识密集型的 LLM 应用程序都需要运行时数据检索以实现检索增强生成 (RAG)。典型 RAG 堆栈的核心组件是向量存储,它用于支持文档检索。
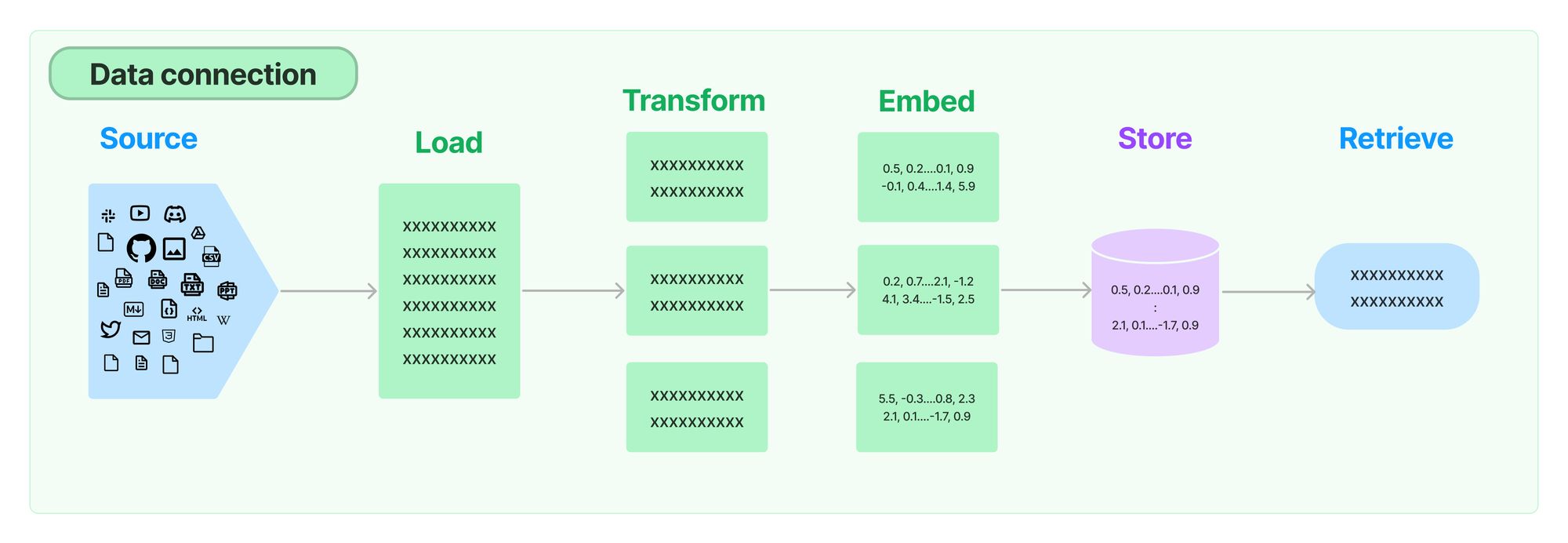
使用向量存储需要设置索引管道,以从源(网站、文件等)加载数据,将数据转换为文档,嵌入这些文档,并将嵌入和文档插入到向量存储中。
如果您的数据源或处理步骤发生更改,则需要重新索引数据。如果这种情况经常发生,并且更改是增量的,那么对正在索引的内容与向量存储中已有的内容进行去重就变得很有价值。这避免了在冗余工作上花费时间和金钱。设置向量存储清理流程以从向量存储中删除过时数据也变得很重要。
LangChain 索引 API
新的 LangChain 索引 API 可以轻松地将任何来源的文档加载并保持同步到向量存储中。具体来说,它可以帮助:
- 避免将重复内容写入向量存储
- 避免重写未更改的内容
- 避免在未更改的内容上重新计算嵌入
至关重要的是,即使文档相对于原始源文档经历了多个转换步骤(例如,通过文本分块),索引 API 仍然可以工作。
工作原理
LangChain 索引使用记录管理器 (RecordManager) 来跟踪文档写入向量存储的情况。
在索引内容时,会为每个文档计算哈希值,并将以下信息存储在记录管理器中:
- 文档哈希值(页面内容和元数据的哈希值)
- 写入时间
- 源 ID——每个文档应在其元数据中包含信息,以便我们确定此文档的最终来源
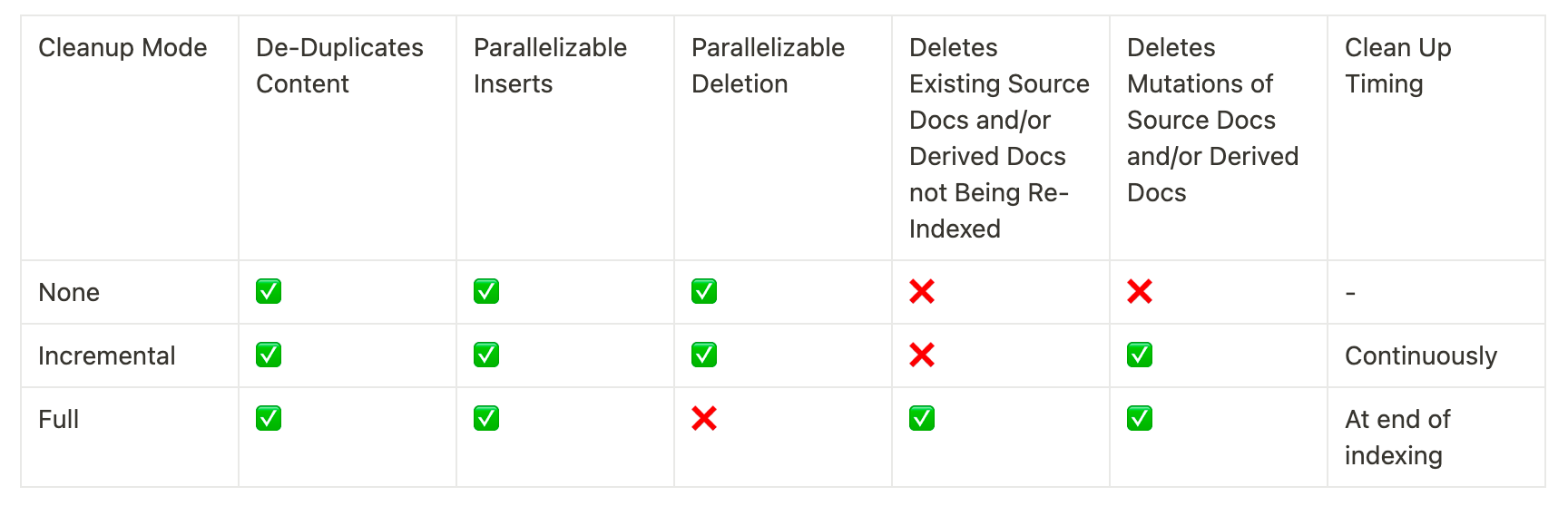
清理模式
当将文档重新索引到向量存储中时,向量存储中一些现有文档可能应该被删除。如果您更改了在插入之前处理文档的方式,或者源文档已更改,您将需要删除来自与正在索引的新文档相同来源的任何现有文档。如果某些源文档已被删除,您将需要删除向量存储中的所有现有文档,并将其替换为重新索引的文档。
索引 API 清理模式让您可以选择您想要的行为
有关 API 及其限制的更详细文档,请查看文档:https://python.langchain.ac.cn/docs/modules/data_connection/indexing
实际应用示例
首先,让我们初始化我们的向量存储。我们将使用 ElasticsearchStore 进行演示,因为它满足支持插入和删除的先决条件。有关向量存储要求的更多信息,请参阅要求文档部分。
# !pip install openai elasticsearch
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import ElasticsearchStore
collection_name = "test_index"
# Set env var OPENAI_API_KEY
embedding = OpenAIEmbeddings()
# Run an Elasticsearch instance locally:
# !docker run -p 9200:9200 -e "discovery.type=single-node" -e "xpack.security.enabled=false" -e "xpack.security.http.ssl.enabled=false" docker.elastic.co/elasticsearch/elasticsearch:8.9.0
vector_store = ElasticsearchStore(
collection_name,
es_url="<https://:9200>",
embedding=embedding
)
现在我们将初始化并为我们的记录管理器创建一个模式,为此我们将只使用一个 SQLite 表
from langchain.indexes import SQLRecordManager
namespace = f"elasticsearch/{collection_name}"
record_manager = SQLRecordManager(
namespace, db_url="sqlite:///record_manager_cache.sql"
)
record_manager.create_schema()
假设我们要索引 reuters.com 首页。我们可以使用以下方式加载和拆分 url 内容:
# !pip install beautifulsoup4 tiktoken
import bs4
from langchain.document_loaders import RecursiveUrlLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
raw_docs = RecursiveUrlLoader(
"<https://www.reuters.com>",
max_depth=0,
extractor=lambda x: BeautifulSoup(x, "lxml").text
).load()
processed_docs = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=200
).split_documents(raw_docs)
现在我们准备好索引了!假设当我们第一次索引时,只有前 10 个文档在首页上
from langchain.indexes import index
index(
processed_docs[:10],
record_manager,
vector_store,
cleanup="full",
source_id_key="source"
)
{'num_added': 10, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 0}
如果我们在一小时后索引,可能其中 2 个文档已更改
index(
process_docs[2:10] + processed_docs[-2:],
record_manager,
vector_store,
cleanup="full",
source_id_key="source",
)
{'num_added': 2, 'num_updated': 0, 'num_skipped': 8, 'num_deleted': 2}
查看输出,我们可以看到虽然索引了 10 个文档,但我们实际完成的工作是 2 个添加和 2 个删除——我们添加了新文档,删除了旧文档,并跳过了所有重复的文档。
有关更深入的示例,请访问:https://python.langchain.ac.cn/docs/modules/data_connection/indexing
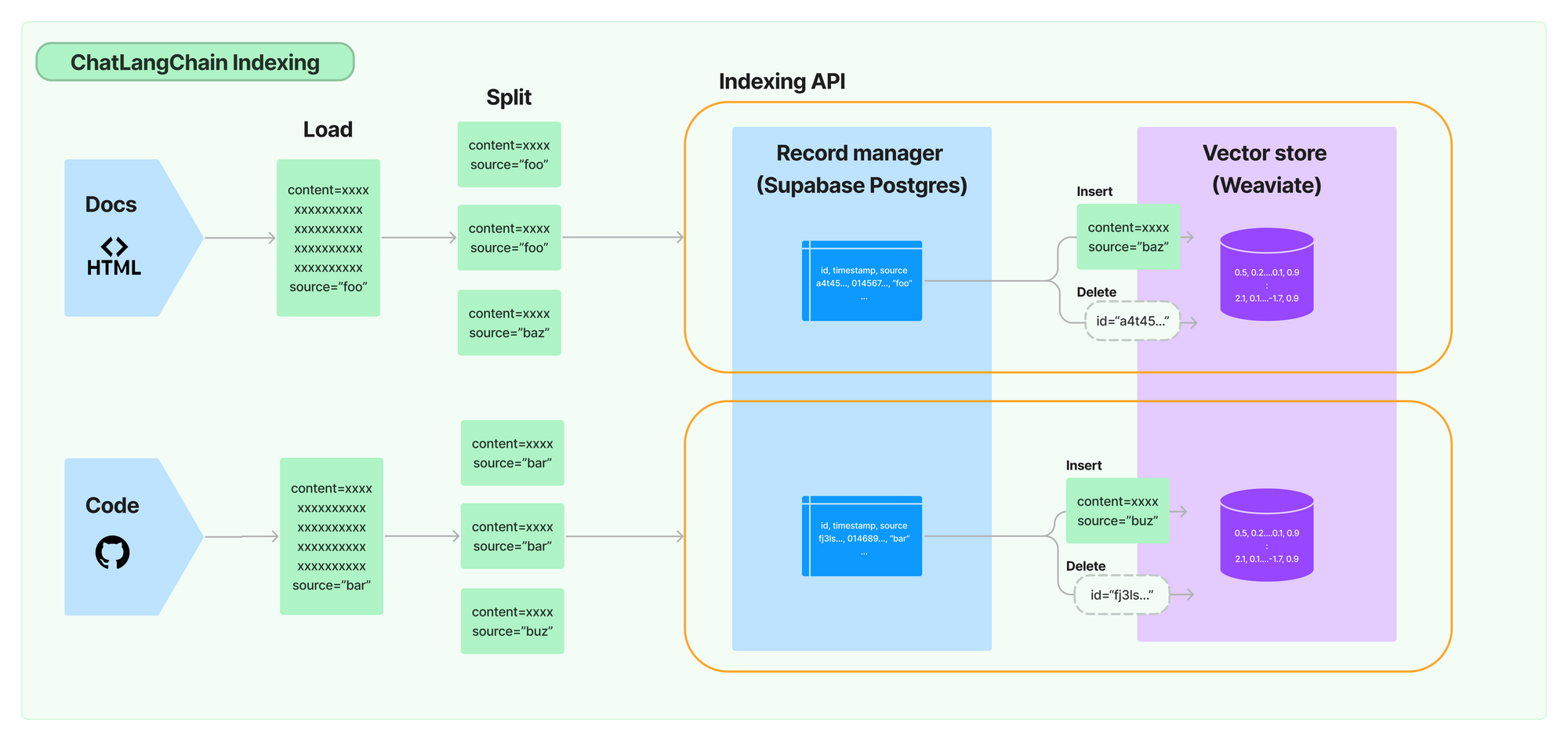
ChatLangChain + 索引 API
我们最近改进了 https://github.com/langchain-ai/chat-langchain 聊天机器人,用于解答有关 LangChain 的问题。作为改进的一部分,我们恢复了托管版本 https://chat.langchain.com,并使用新的 API 设置了每日索引作业,以确保聊天机器人与最新的 LangChain 开发保持同步。
这样做非常简单——我们所要做的就是:
- 设置一个 Supabase Postgres 数据库用作记录管理器,
- 更新我们的摄取脚本,以使用索引 API 而不是直接将文档插入向量存储,
- 设置一个计划的 Github Action 以每天运行摄取脚本。您可以在此处查看 GHA 工作流程。
结论
当您将应用程序从原型转移到生产环境时,能够高效地重新索引并保持向量中的文档与其来源同步变得非常重要。LangChain 的新索引 API 提供了一种简洁且可扩展的方式来做到这一点。
试用一下,让我们知道您的想法!