
编者注。这篇博文由 Ryan Brandt 撰写,他是 ChatOpenSource 的首席技术官和联合创始人,这是一家专注于企业 AI 聊天的公司,完全在组织网络内运行,无需第三方。他介绍了如何使用 LangSmith, LangChain 用于将 LLM 应用程序投入生产的平台。注册以获取访问权限 此处。
开源模型在应用程序中的能力越来越强。随着最近发布的 Mistral 7b 和 Llama2 系列,这种趋势只会加速。未来似乎在于能够像旧游戏机中的卡带一样,快速地在你的应用程序中更换更好的模型。微调模型的不同版本只会增加开发者需要比较的可能卡带数量。
因此,这就引出了一个问题,我们如何才能将模型的评估生产化,以便我们可以为这项工作选择最佳工具? LangSmith 为我们提供了一种摆脱 Python 脚本地狱的方法,它提供了一个方便的 UI 和 API,用于创建评估数据集。借助这些数据集,我们可以对多个模型运行测试,并直接比较它们在多个轴上的性能。
通过 Python 或用户界面可以轻松地将数据上传到 LangSmith。对于我们的示例 notebook,请滚动到末尾。
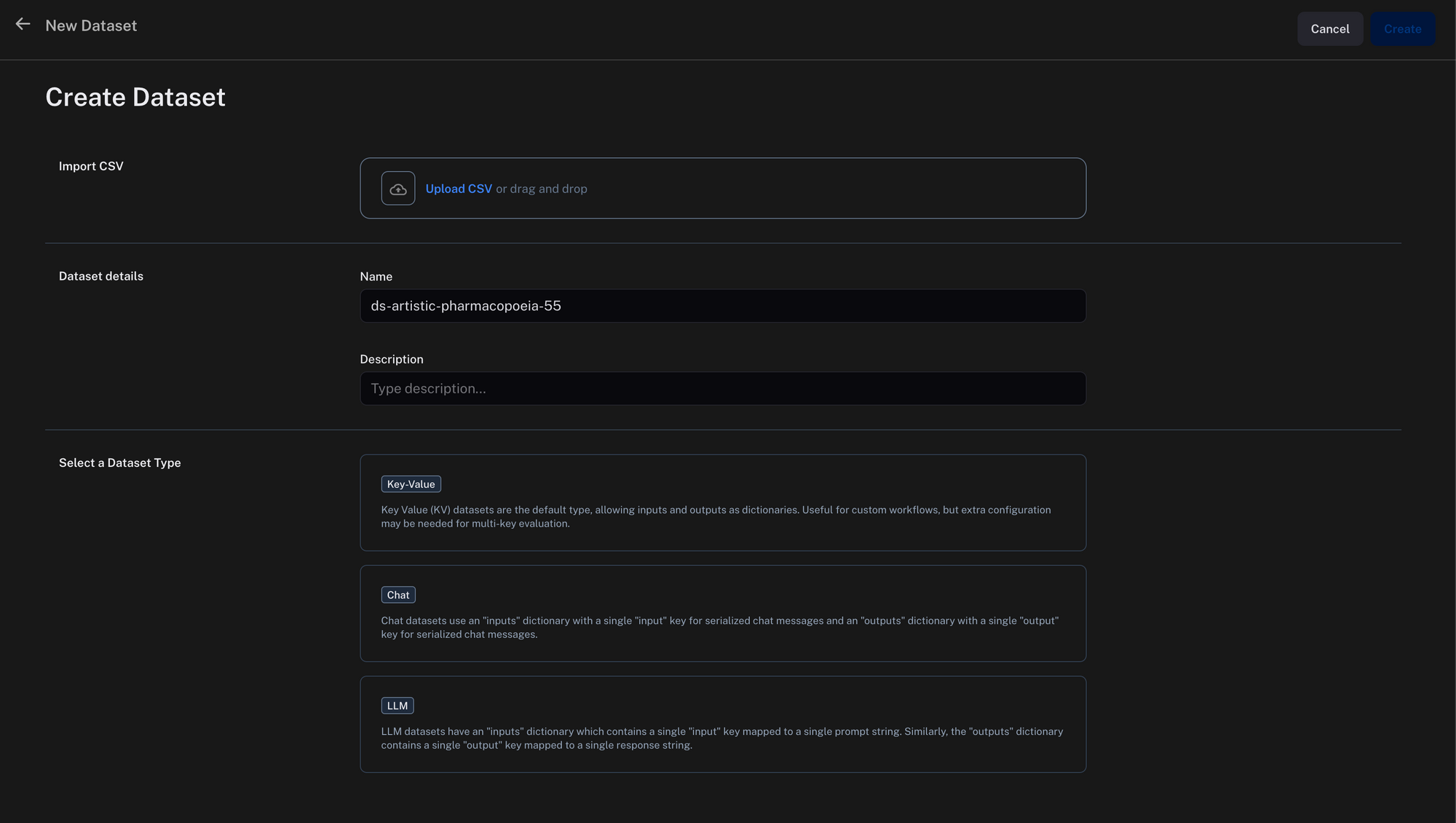

流程
以下是我们组织这项研究的方式
- 启动:任务开始的目标是使用 Hugging Face 上的 sql-create-context 数据集微调 Llama2-7b 和 Llama2-13b 模型。
- 数据转换:来自 Hugging Face 的数据集最初是 JSON 格式,被转换为 .jsonl 格式以进行聊天微调。
- 使用 GPT-4 进行数据抽样:GPT-4 的代码解释器用于从数据集中选择 10,000 行。
- 验证集创建:选择了 1000 个唯一的 SQL 行作为验证集,确保与训练数据没有重叠。我们将这些测试行上传到 LangSmith,以便我们可以自动化我们的评估。
from langsmith import Client
def create_dataset(dataset_name=None):
"""adds an example run with inputs and outputs to an existing dataset"""
client = Client()
dataset_name = dataset_name
client.create_dataset(dataset_name=dataset_name)
return dataset_name
def add_to_dataset(dataset_name, validation_file_path):
client = Client()
dataset = client.read_dataset(dataset_name=dataset_name)
# Open and process the validation file
with open(validation_file_path, 'r') as f:
for line in f:
data = json.loads(line)
example = data['prompt']
assistant_content = data['completion']
# Add to dataset using client API
client.create_chat_example(
messages=[
{"type": "system", "data": {"content": "You are a helpful assistant that is knowledgeable about sql. Only output the SQL."}},
{"type": "human", "data": {"content": example}}
],
generations={"type": "ai", "data": {"content": assistant_content}},
dataset_id=dataset.id
)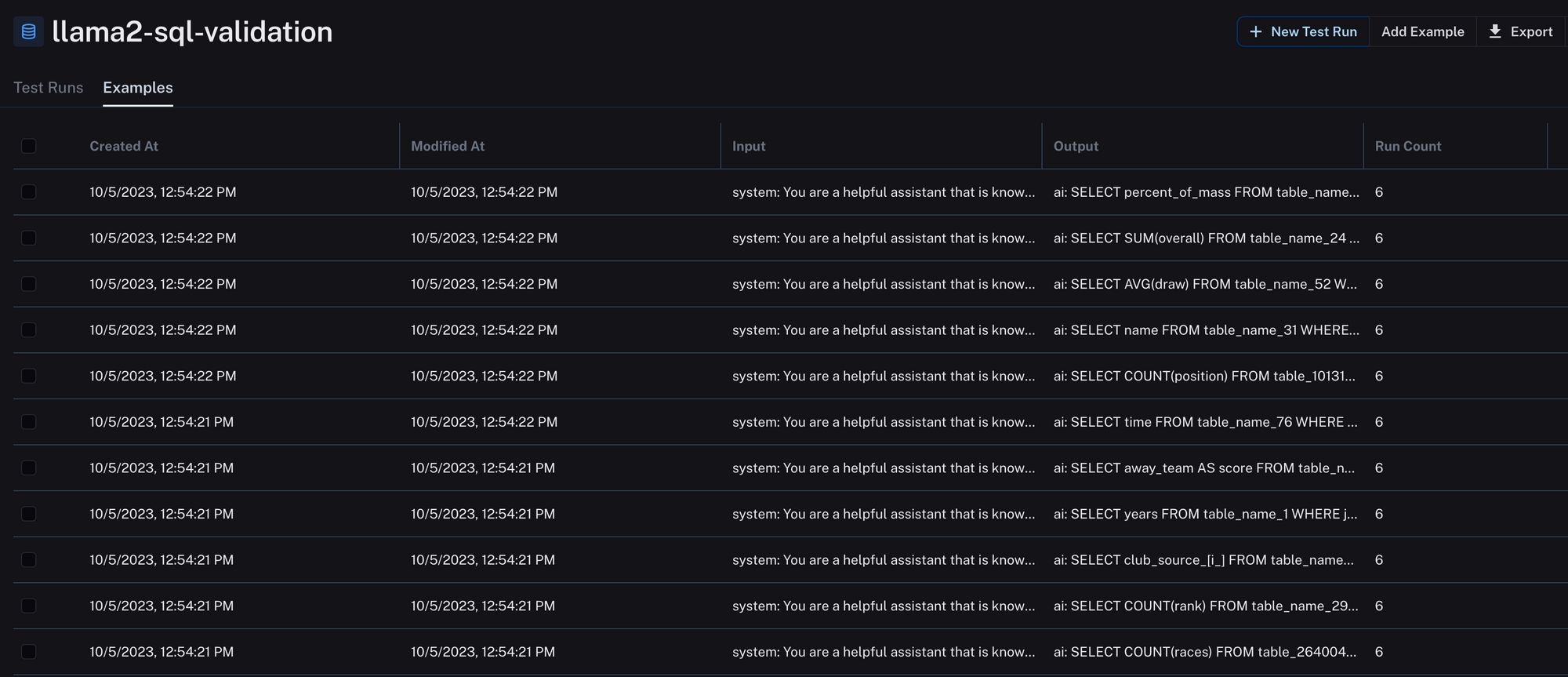
5. 微调和评估:主要目标是改进 Llama2-7b-chat 和 Llama2-13b-chat 以获得特定的 SQL 输出。我们使用 7.8 万行 SQL 数据微调了 Llama2-7b-chat,并使用 1 万行数据微调了 Llama2-13b-chat 以控制成本。微调和推理都在 8xA40 集群上完成。我们进行了全参数调整,而不是 LoRA。为此,我们使用了 Replicate,一个用于模型托管和微调的平台。您可以在此处了解更多关于它们的信息。
import replicate
training = replicate.trainings.create(
version="meta/llama-2-13b-chat:f4e2de70d66816a838a89eeeb621910adffb0dd0baba3976c96980970978018d",
input={
"train_data": "https://storage.googleapis.com/chatopensource-replicate-demo/selected_sql_create_context_v4.jsonl",
"num_train_epochs": 3
},
destination="papermoose/test"
)6. LangSmith 评估:我们使用 LangSmith 在每个模型上测试了 1000 个提示。我们将它们的结果与已知的正确答案进行比较,以确定模型的输出是否正确。我们使用 GPT-4 本身来进行评估。LangSmith 使这个过程非常简单,如下所示。
import replicate
async def evaluate_dataset(dataset_name=None, num_repetitions=1, model="gpt-4-0613", project_name=None):
"""runs the model you want to evaluate against the assumed to be correct examples in your dataset, grading the evaluated model output correct or incorrect."""
from langchain.smith import run_on_dataset, RunEvalConfig, arun_on_dataset
from langchain.chat_models import ChatOpenAI
# The chat model you want to test, in our case replicate
model_to_test = Replicate(
model=model,
model_kwargs={"temperature": 0.75, "max_length": 500, "top_p": 1},
)
client = Client()
"""runs a question/answer evaluation, where the eval llm (gpt-4) will determine
if model_to_test's outputs are correct based on the example_dataset we uploaded in the previous set.
the example_dataset is treated by the eval as a correct answer for the given input."""
eval_config = RunEvalConfig(
evaluators=[
"cot_qa"
],
)
chain_results = await arun_on_dataset(
client,
dataset_name=dataset_name,
llm_or_chain_factory=model_to_test,
evaluation=eval_config,
num_repetitions=num_repetitions,
project_name=project_name
)LangSmith 平台本身允许您查看我们评估的结果,在本例中是内置的思维链问题解答评估。您也可以根据需要编写自己的评估器,如 此处 所示!
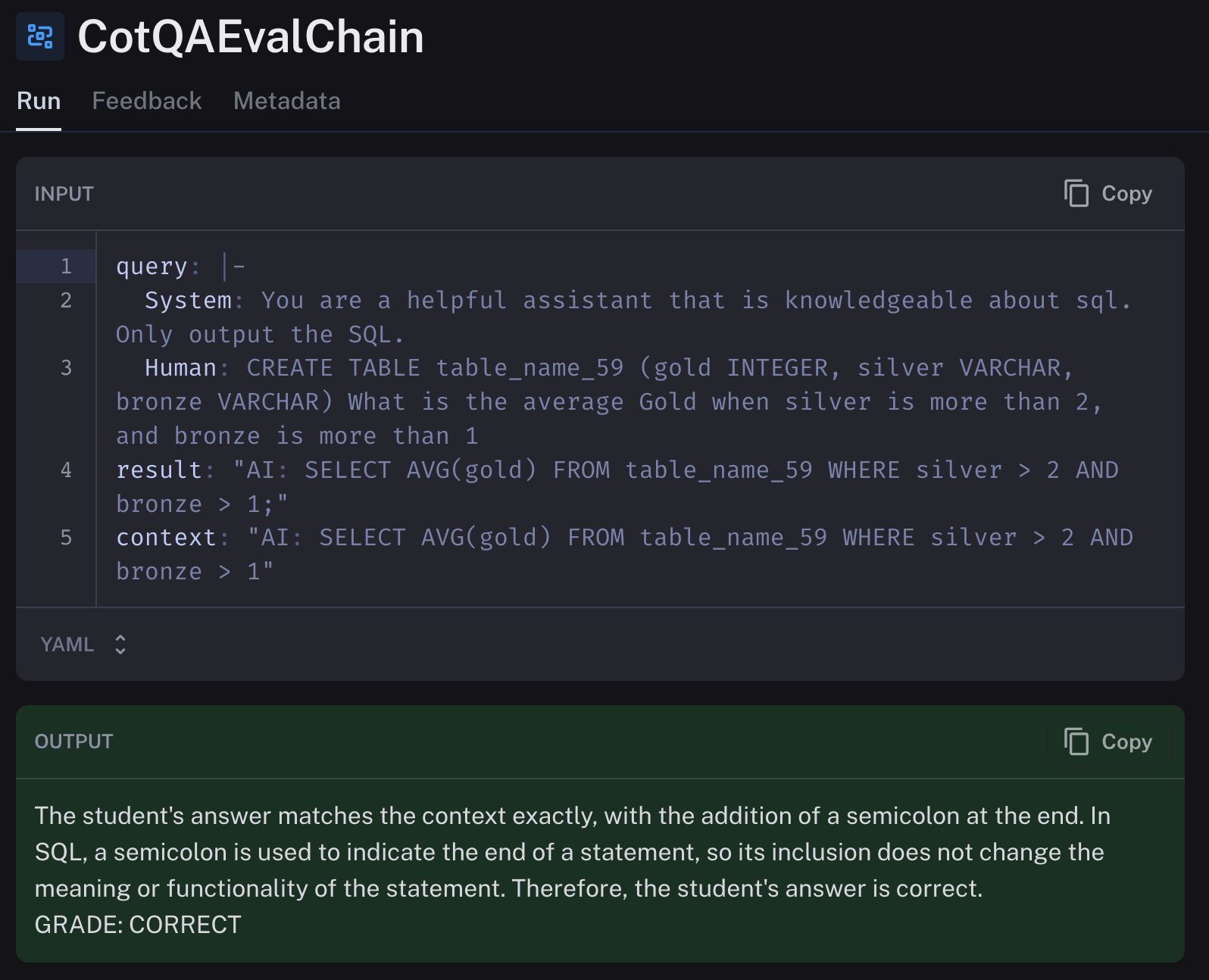
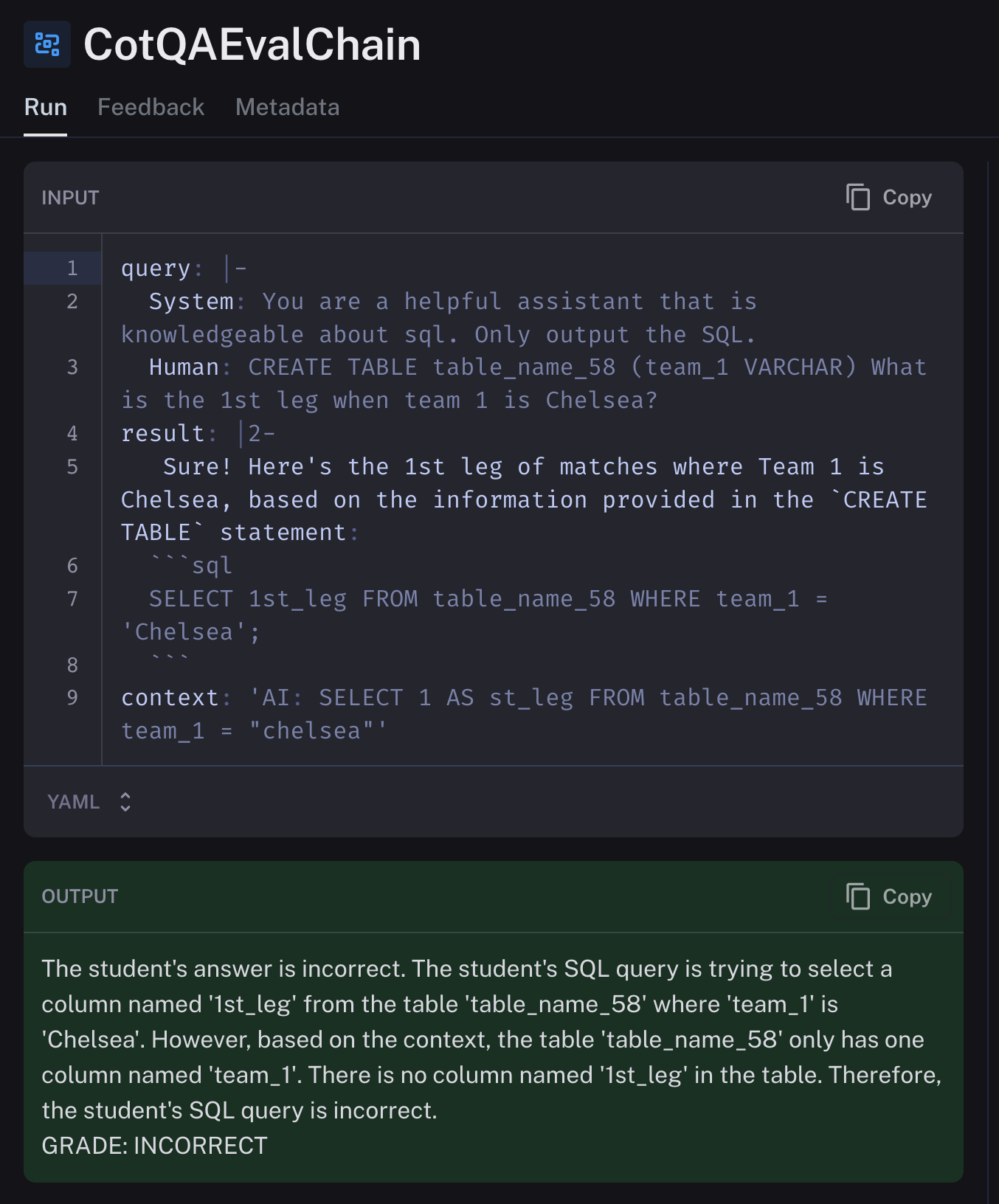
我们在 LangSmith 中的发现
以下是我们的结果,数据集名称是随机生成的。UI 中仍然没有简单的方法来更改数据集的名称,因此我也在下面以更容易理解的方式绘制了图表。
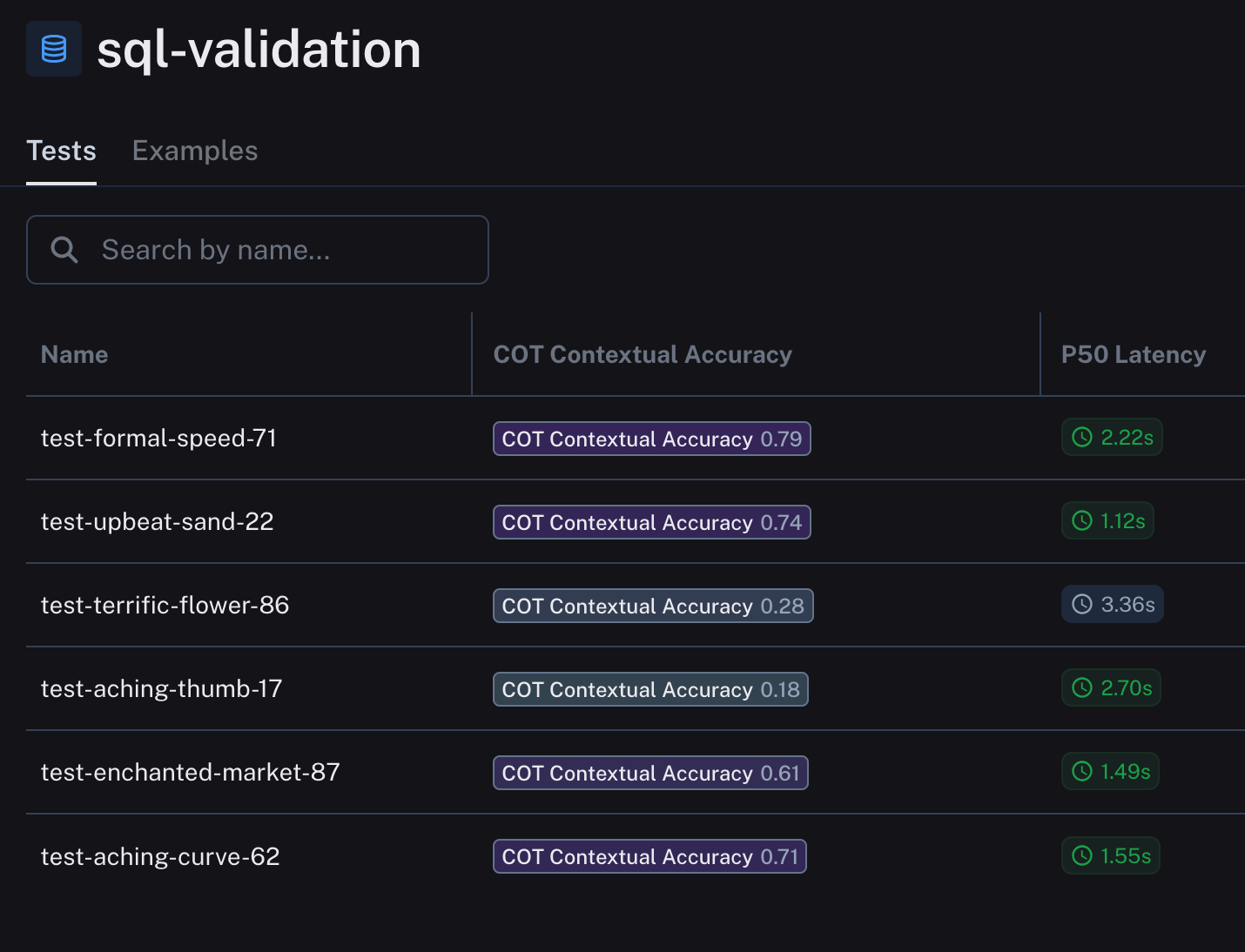
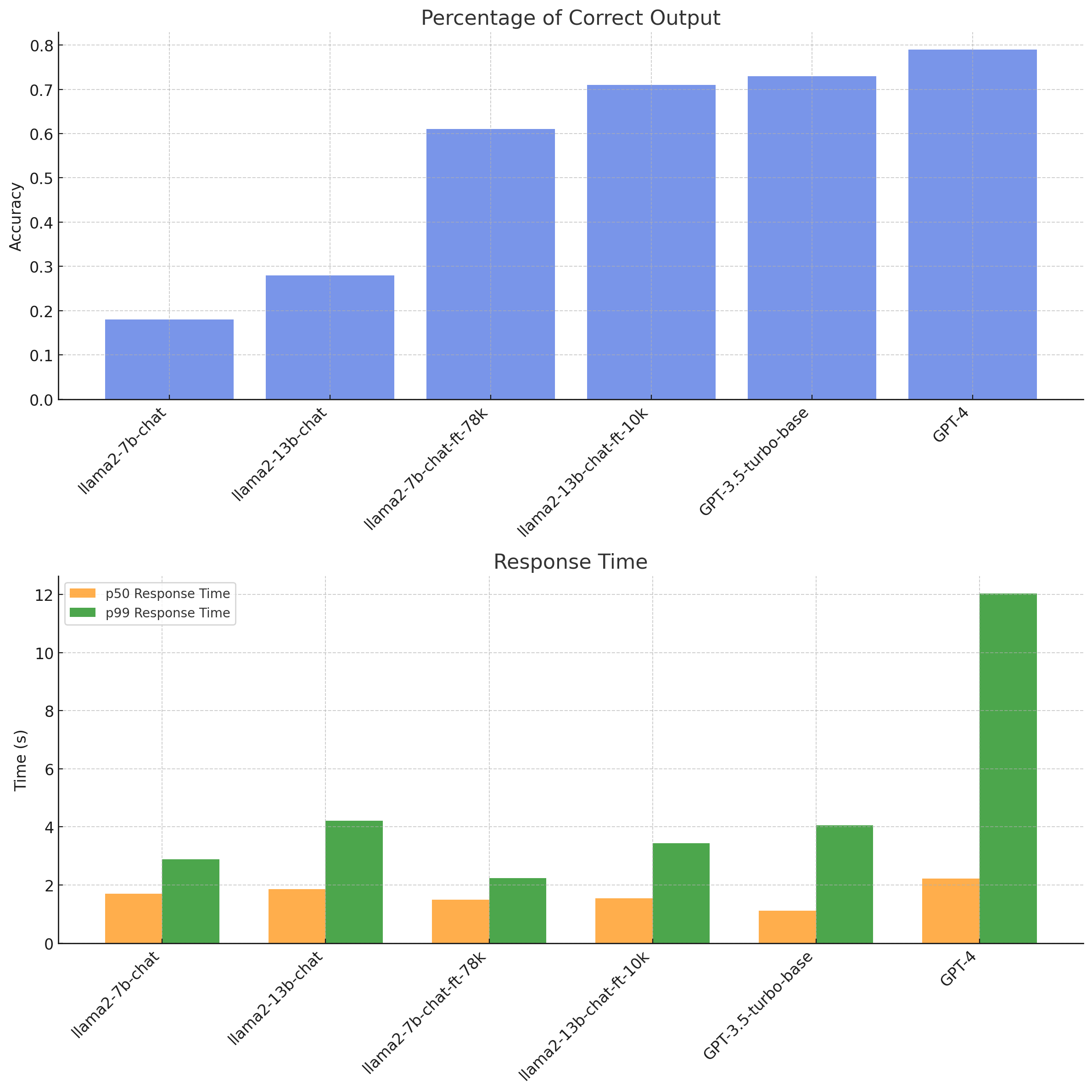
您可以在此处查看我们如何使用 ChatGPT 生成此图表!
关于结果的观察
- 参数 vs. 数据:数据显示了模型参数和训练数据量之间的关系。虽然参数较少的
llama2-7b-chat-ft-78k表现良好,但它仍然逊色于参数更多的llama2-13b-chat-ft-10k。这就引出了一个问题:如果 13b 模型使用更大的 78k 数据集,结果会如何?准确率很可能与训练集的大小和质量相关。 - 响应时间:除了准确率之外,响应时间,特别是 p50 和 p99,对于评估模型效率也很重要。在这里,
llama2-7b-chat-ft-78k模型显示出良好的准确率和高效的响应时间。值得注意的是,这些 Llama 模型的响应时间是基于 Replicate 的,并且可能会根据用于运行它们的硬件而变化。 - 与 GPT-3.5T 的比较:数据显示了这些模型与
GPT-3.5-turbo-base的比较情况。值得注意的是,llama2-13b-chat-ft-10k的准确率接近GPT-3.5T,这表明优化的开源模型有可能匹敌甚至超越已建立的模型。
回顾
- 我们已经了解了 LangSmith 如何与任何模型(开源或闭源)协同工作。
- 我们已经看到了详细说明与 LangSmith 交互过程的代码片段,以及 UI 中的屏幕截图结果。
- 我们已经使用 ChatGPT 高级数据分析绘制了结果图表。
- 我们已经看到,对于某些领域,开源模型可以与 OpenAI 竞争
- 有关使用 LangSmith 的更具交互性的示例,请在此处查看我们的 Python notebook。
我们还运营 ChatOpenSource,这是一个完全数据私有且可审计的 ChatGPT 企业替代品。公司可以轻松配置文档和数据,以便只有合适的团队可以询问它们,并且数据永远不会离开公司环境。与我们预约快速通话以了解更多信息!