背景
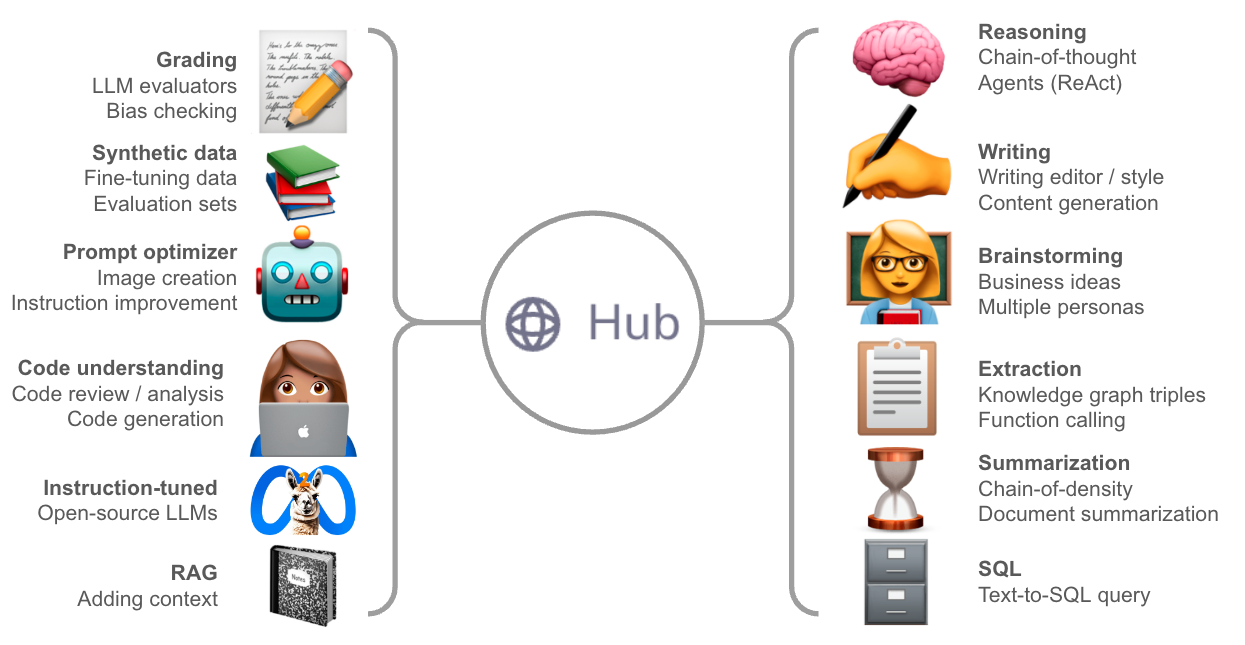
提示工程可以在不更新模型权重的情况下引导 LLM 的行为。已经出现了各种用于不同用例的提示(例如,参见 @dair_ai 的 提示工程指南 和 Lilian Weng 的 这篇精彩评论)。随着 LLM 的数量 和不同用例的扩展,越来越需要 提示管理 来支持提示的可发现性、共享、研讨和调试。一个多月前,我们推出了 LangChain Hub 以支持这些需求,它既是浏览社区提示的场所,也是管理您自己提示的场所。下面我们概述了自发布以来我们看到的提示中的主要主题,并重点介绍了一些有趣的示例。
推理
思维链 推理鼓励 LLM 将其“思考”分散到许多 tokens 中:它使 LLM 通过一个简单的语句(例如,Let's think step by step)来展示其工作原理。这已获得广泛欢迎,因为它在很大程度上 提高了 许多推理任务的性能,并且易于实现。更复杂的方法(例如,思维树)也值得考虑,但应评估 相对于开销 (tokens) 的好处。
Deepmind 最近使用 LLM 来优化提示,并收敛到 Take a deep breath and work on this problem step-by-step 作为 最佳 性能优化。展望未来,这指向了在人类指令和 LLM 优化提示之间进行 翻译模块 的一些有趣的潜力。

如上所示的推理提示 可以作为简单的指令附加到许多任务中,并且对于代理变得尤为重要。例如,ReAct 代理 以交错的方式将工具使用与推理相结合。代理提示可以以不同的方式编码多步骤推理,但通常目标是根据观察结果更新行动计划。请参阅 Lilian Weng 关于代理的 精彩文章,以全面了解代理设计和提示的各种方法。
示例
- https://smith.langchain.com/hub/hwchase17/react
- https://smith.langchain.com/hub/shoggoth13/react-chat-agent
- https://smith.langchain.com/hub/jacob/langchain-tsdoc-research-agent
写作
鉴于 LLM 令人印象深刻 的创造力展示,改进写作的提示具有广泛的吸引力。@mattshumer_ 流行的 GPT4 提示提供了改进写作清晰度或自定义 LLM 生成文本风格的方法。利用 LLM 的语言翻译能力是写作的另一个良好应用。
示例
- https://smith.langchain.com/hub/rlm/matt-shumer-writing
- https://smith.langchain.com/hub/rlm/matt-shumer-writing-style
- https://smith.langchain.com/hub/agola11/translator
还有大量用于生成各种内容的提示(例如,入职电子邮件、博客文章、推文、教育 的学习材料)。
示例
- https://smith.langchain.com/hub/gitmaxd/onboard-email
- https://smith.langchain.com/hub/hardkothari/blog-generator
- https://smith.langchain.com/hub/gregkamradt/test-question-making
- https://smith.langchain.com/hub/bradshimmin/favorite_prompts
- https://smith.langchain.com/hub/hardkothari/tweet-from-text
- https://smith.langchain.com/hub/julia/podcaster-tweet-thread
SQL
由于企业数据通常捕获在 SQL 数据库中,因此人们对使用 LLM 作为 SQL 的自然语言界面非常感兴趣(请参阅我们的 博客文章)。许多论文 报道称,LLM 可以根据有关表的某些特定信息生成 SQL,包括每个表的 CREATE TABLE 描述,后跟 SELECT 语句中的三个示例行。LangChain 具有许多用于查询 SQL 数据库的工具(请参阅我们的 用例指南 和 cookbook)。
示例
头脑风暴
许多人与 LLM 进行了有启发性和/或娱乐性的对话。LLM 已被证明在头脑风暴中非常有用:一个技巧是创建多个用户角色,让他们共同思考一个想法,如 @mattshumer_ 商业计划构思提示所示。该原则可以广泛应用。例如,BIDARA(生物启发设计和研究助手)是一个 GPT-4 聊天机器人,旨在帮助科学家和工程师理解、学习和模仿生物使用的策略,以用于新的设计和技术。
示例
- https://smith.langchain.com/hub/hwchase17/matt-shumer-validate-business-idea
- https://smith.langchain.com/hub/bruffridge/bidara
提取
LLM 可以成为以特定格式提取文本的强大工具,通常借助 函数调用。这是一个丰富的领域,开发了框架来支持它,例如 @jxnlco 的 Instructor(请参阅他们的 提示工程指南)。我们还看到了专为特定提取任务设计的提示,例如知识图谱三元组提取(如 Instagraph 或 text-to-graph playground 等工具所示)。

示例
- https://smith.langchain.com/hub/langchain/knowledge-triple-extractor
- https://smith.langchain.com/hub/homanp/superagent
RAG
检索增强生成 (RAG) 是一种流行的 LLM 应用:它通过提示将相关上下文传递给 LLM。RAG 在 事实 召回 方面特别有前景,因为它将 LLM 的推理能力与外部数据源的内容相结合,这对于企业数据而言 尤其强大。

示例
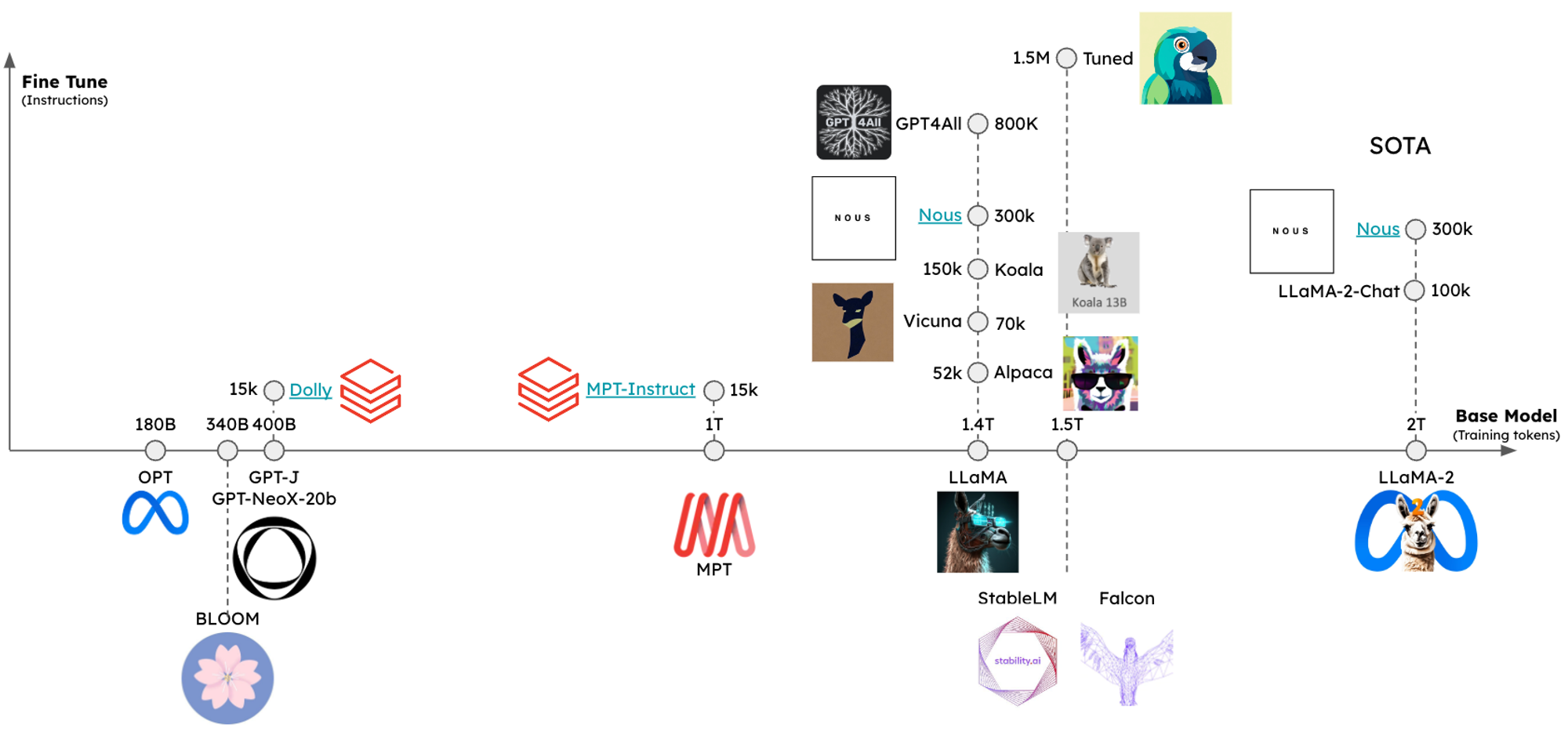
指令调优的 LLM
开源 指令调优的 LLM 的格局在过去一年中呈爆炸式增长。随之而来的是各种流行的 LLM,每个 LLM 都有特定的提示指令(例如,请参阅 LLaMA2 和 Mistral 的指令)。检索增强生成 (RAG) 等流行任务可以从特定于 LLM 的提示中受益。
示例
- https://smith.langchain.com/hub/rlm/rag-prompt-llama
- https://smith.langchain.com/hub/rlm/rag-prompt-mistral
LLM 评分器
使用 LLM 作为评分器是一个强大的想法,已在 OpenAI cookbook 和 开源 项目 中得到广泛展示:核心思想是利用 LLM 的辨别能力来对响应相对于标准答案(或相对于参考材料(如检索到的上下文)的一致性)进行排名或评分。LangSmith 的许多工作都 侧重于 评估 支持。
示例
- https://smith.langchain.com/hub/simonp/model-evaluator
- https://smith.langchain.com/hub/wfh/automated-feedback-example
- https://smith.langchain.com/hub/smithing-gold/assumption-checker
合成数据生成
微调 LLM 是引导 LLM 行为的主要方法之一(与 RAG 一起)。然而,收集用于微调的训练数据是一个挑战。大量 工作 都集中在 使用 LLM 生成合成数据集。
示例
- https://smith.langchain.com/hub/homanp/question-answer-pair
- https://smith.langchain.com/hub/gitmaxd/synthetic-training-data
提示优化
Deepmind 的工作表明,LLM 可以优化提示,这为人类指令和 LLM 优化提示之间的 翻译模块 提供了广阔的潜力。我们已经看到了许多与这些思路相关的有趣提示;一个很好的例子是 Midjourney,它具有令人难以置信的创造潜力,可以通过提示和参数标志来解锁。对于一个通用的输入想法(Freddie Mercury performing at the 2023 San Francisco Pride Parade hyper realistic),它可以生成一系列 N 个提示来修饰这个想法,如下所示
Freddie Mercury 在旧金山骄傲游行舞台上激情四射,身穿闪闪发光的金色服装,手持标志性的麦克风支架,唤起卡拉瓦乔的超现实主义风格,生动而充满活力 --ar 16:9 --q 2)

示例
- https://smith.langchain.com/hub/hardkothari/prompt-maker
- https://smith.langchain.com/hub/aemonk/midjourney_prompt_generator
代码理解和生成
代码分析是最流行的 LLM 用例之一,GitHub co-pilot 和 Code Interpreter 以及微调的 LLM (Code LLaMA) 的普及就证明了这一点。我们已经看到了许多与此主题相关的提示
示例
- https://smith.langchain.com/hub/chuxij/open-interpreter-system
- https://smith.langchain.com/hub/homanp/github-code-reviews
- https://smith.langchain.com/hub/muhsinbashir/text-to-streamlit-webap
摘要
内容摘要 是一种强大的 LLM 用例。更长上下文的 LLM,例如 Anthropic Claude2,可以吸收超过 70 页的内容以进行直接摘要。提示技术(如 密度链)提供了一种互补方法,可生成密集但更符合人类偏好的摘要。
示例
- https://smith.langchain.com/hub/lawwu/chain_of_density
- https://smith.langchain.com/hub/hwchase17/anthropic-paper-qa
- https://smith.langchain.com/hub/muhsinbashir/youtube-transcript-to-article
- https://smith.langchain.com/hub/hwchase17/anthropic-chain-of-density
此外,摘要可以应用于各种内容类型,例如聊天对话(例如,压缩内容 以作为上下文传递到聊天 LLM 内存中)或特定领域的数据(财务表格摘要)
示例
- https://smith.langchain.com/hub/langchain-ai/weblangchain-search-query
- https://smith.langchain.com/hub/hwchase17/financial-table-insights
结论
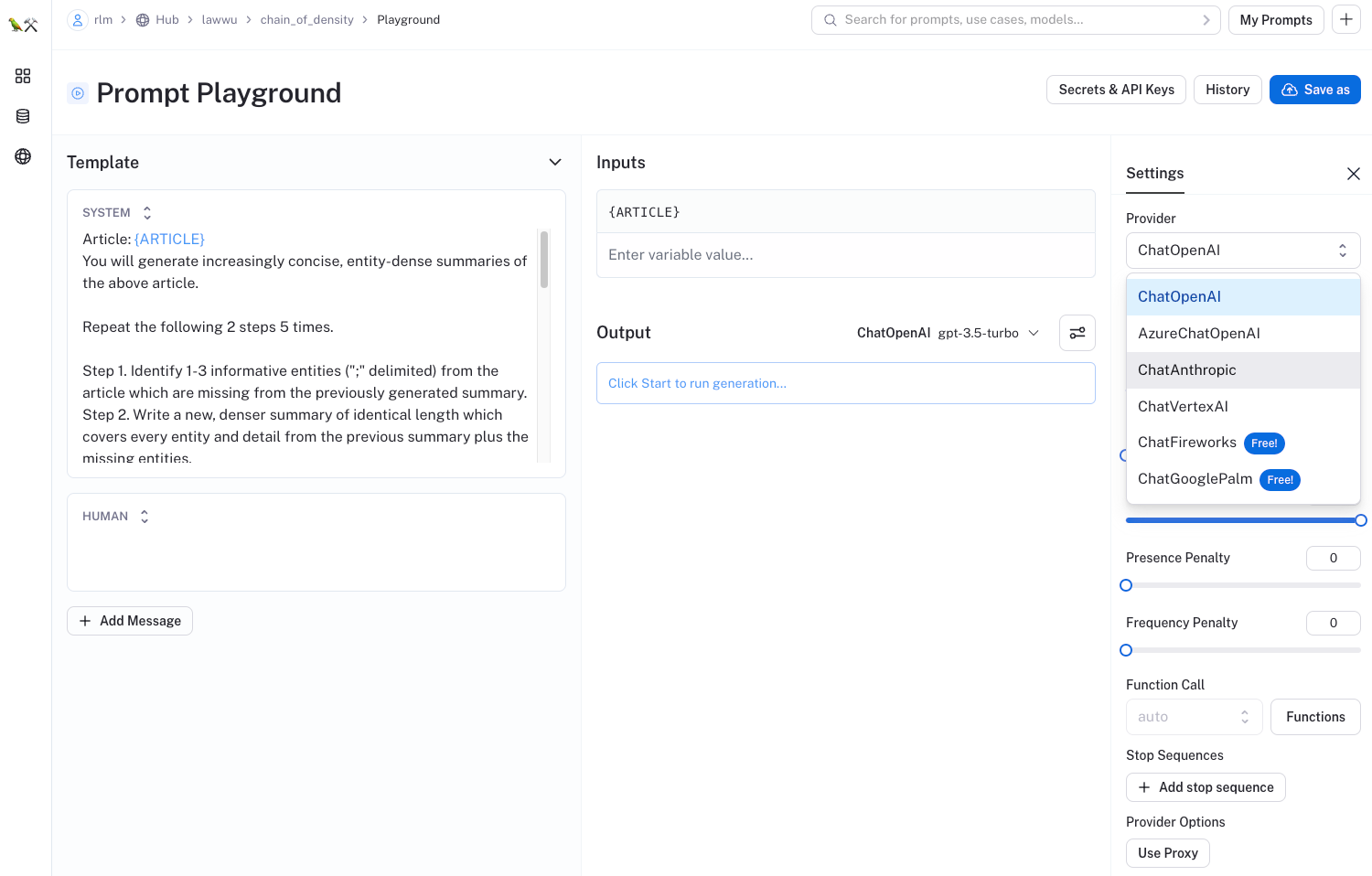
您可以使用“Try It”按钮轻松测试所有这些提示
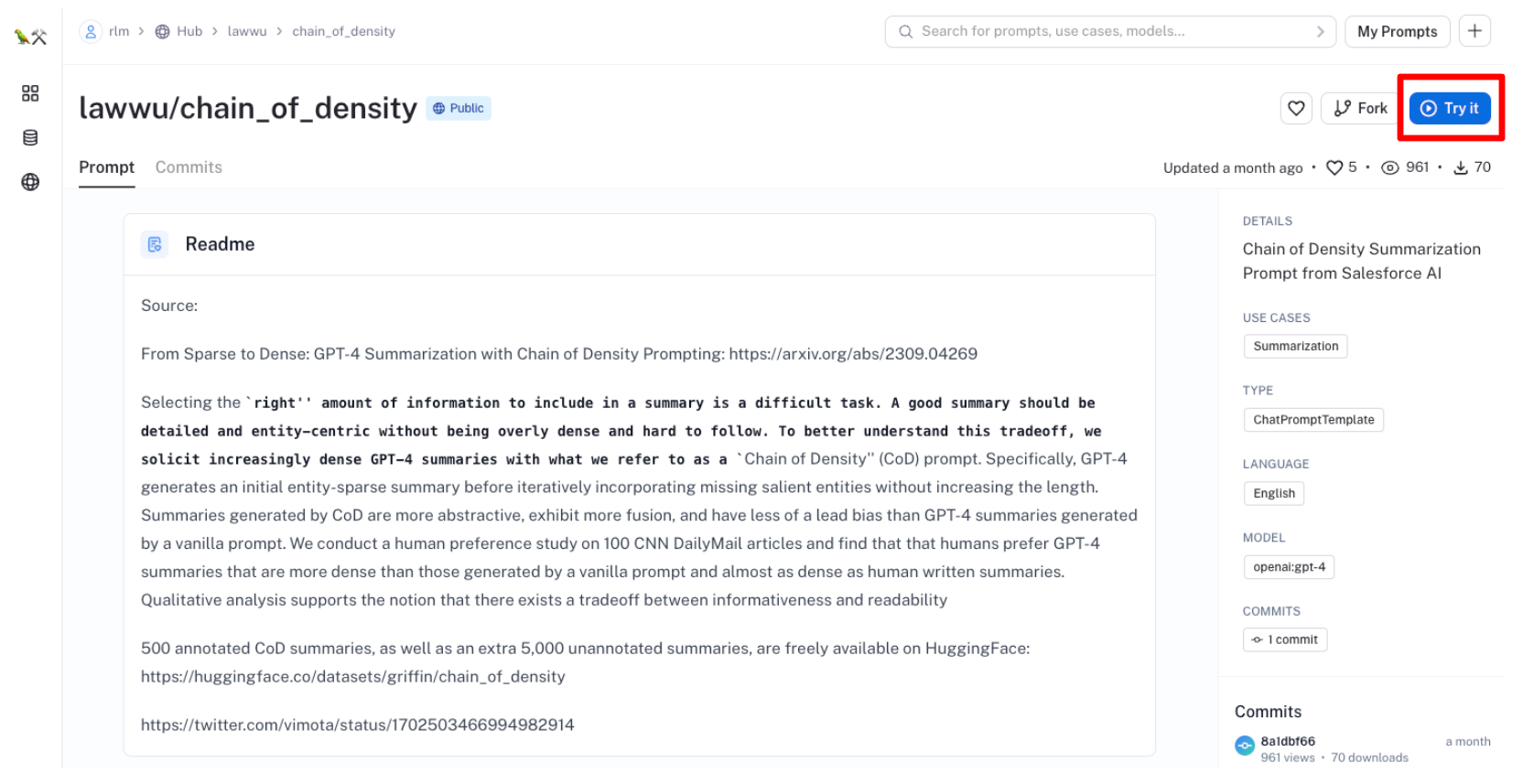
这将打开一个 playground,用于使用各种不同的 LLM 进行提示的研讨和调试,其中许多 LLM 可以免费使用