这是一篇由 Unify 的 Sam 和 Connor 撰写的客座博客文章。 Unify 正在使用生成式 AI 重新定义市场团队的工作方式。作为此转型的一部分,他们今天推出了新的 Agent 功能(由 LangGraph 和 LangSmith 提供支持)。我们很高兴能够了解更多关于推出此功能所经历的工程历程,并认为这是一个非常值得分享的故事。
Agent 是我们与更广泛的自动化套件 Plays 一起推出的新功能。Agent 实际上是研究工具——它们可以通过搜索网络、访问网站、在页面之间导航以及执行标准的 LLM 合成和推理来回答问题,从而研究公司或人员。
对于首次发布,Agent 的目标用例是客户资格认定,即决定一家公司是否符合您的理想客户画像以进行销售的任务。给定一家公司和一组问题和标准,Agent 会进行一些研究,并决定他们是否“合格”。
示例研究问题
以下是一些资格认定问题的示例,不同用户可能会要求 Agent 研究并根据其进行资格认定
- 一家人力资源软件公司 ⇒
- 这家公司的招聘页面上是否有任何人力资源职位发布?
- 任何人力资源职位的招聘信息是否提及竞争对手的软件?
- 一家 AI 基础设施公司 ⇒
- 这家公司是否在其网站的任何地方提及使用 LLM?
- 该公司是否有任何开放的 ML 职位正在寻找语言或音频 Transformer 模型的经验?
- 网站或任何招聘信息是否提及开源 LLM?
Agent v0
我们使用 LangGraph 作为 Agent 状态机的框架,LangSmith 作为实验和追踪框架。我们的起点是一个非常简单的 Agent,它非常基础(甚至没有提示)

对于许多简单的任务,这实际上效果相当不错,但它也会出错并产生不一致的结果。分析答案背后的推理也很困难。
Agent v1
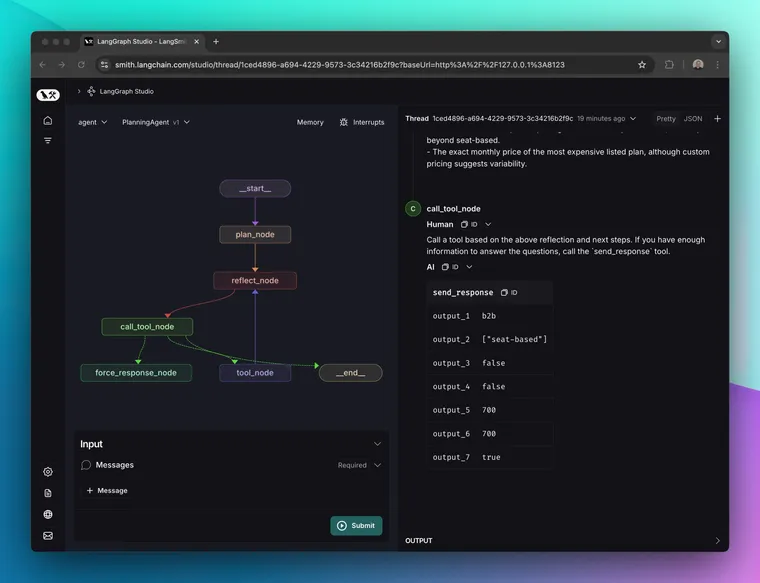
我们的下一次迭代是构建一个更复杂的 Agent 结构,其中包含初始计划步骤和反思步骤。图表如下所示

第一步涉及使用大型模型来生成计划。在我们的测试中,像 gpt-4o 这样的主流模型在没有非常具体的提示的情况下,无法构建特别全面的计划。我们在此阶段获得的最佳结果是使用 OpenAI 的 o1-preview 模型。o1 生成的计划之所以脱颖而出,以至于难以用其他模型复制,是因为它们具有
- 非常详细的逐步说明
- 正确且有用的潜在陷阱和要避免的错误
- 扩展了用户问题的含义,即使措辞不佳
o1 的主要缺点是速度。它可能需要长达 30-45 秒才能响应,这会显着减慢整个 Agent 的运行速度。我们目前积极实验的一个领域是用更快、更轻的模型复制等效的结果。
计划之后,Agent 随后开始在“反思”步骤和工具调用之间循环。为此,我们尝试了几种模型。像 GPT-4o 和 3.5 Sonnet 这样的“主流”模型效果相当好。反思模型最重要的特征之一是诚实地说明它不知道什么,以便适当地选择正确的下一步。
Agent v2
对于我们最新的迭代,我们仍然使用计划-反思-工具状态机结构。我们一直在最积极地调整和实验的领域是速度和用户体验。
速度
这种架构的主要缺点(尤其是在使用像 o1-preview 这样更重的计划模型时)是它会大幅增加整体运行时。我们找到了通过加速 Agent 循环和修改产品中使用 Agent 的 UI/UX 来处理这个问题的方法。
我们实现的最大速度提升之一来自并行化工具调用。例如,我们允许模型一次抓取多个网页。这非常有帮助,因为每个网页可能需要几秒钟才能加载。这在直觉上也很有效,因为人类通常也会做同样的事情——快速在新标签页中打开多个 Google 搜索结果。
用户体验
在不牺牲准确性和功能的情况下,Agent 的速度最终是有限制的。我们决定重新设计产品中构建和测试 Agent 的 UI。最初的设计在 Agent 运行时向用户显示一个微调器(几秒钟后会变得非常痛苦)。我们更新后的界面改为实时显示 Agent 运行时的操作和决策过程。(请参阅本文顶部的视频)
实现这一点还需要一些工程变更。我们最初有一个简单的预测端点,它会在 Agent 运行时保持请求打开状态。为了处理更长的 Agent 运行时并完成新的逐步 UI,我们将其转换为“异步”端点,该端点启动 Agent 执行并返回一个可用于轮询进度的 ID。我们在 Agent 图和工具中添加了钩子,以将进度“记录”到我们的数据库中。然后,前端轮询更新并显示新完成的步骤,直到获得最终结果。
最终学习
拥抱实验
使用 Agent 肯定需要弄清楚新的东西。研究领域目前非常新颖,并且在其他领域(如视觉或音频)中我们认为的 SOTA 方式中,还没有明确的 SOTA Agent 架构。
鉴于此,我们必须大力投入到良好的传统 ML 实验和评估周期中,才能取得实质性进展。
我们对 LangSmith 在这方面的表现非常满意(我们还在 Unify 的另一个 LLM 驱动的功能 Smart Snippets 中使用了 LangSmith)。特别是,版本化数据集正是我们所希望的那样。运行和比较实验非常简单,并且追踪也非常出色。我们能够在数百个示例上运行新的 Agent 版本,并在给定的数据集上快速将其与以前的版本进行比较,而无需进行很少的内部 ML 基础设施工作。
将 Agent 视为暑期实习生
例如,许多具有 Agent 构建功能的工具的 UX 都围绕编写提示、在某些测试用例上运行它、等待黑盒 Agent 运行、检查结果,然后猜测如何修改提示以尝试改进它。
现在想象一下,Agent 实际上是一个容易疏忽和犯错的暑期实习生。如果您给实习生一项任务,他们返回了错误的答案,您会仅仅尝试修改您的指示,然后再次让他们自己去完成吗?不会——您会要求他们展示他们如何完成任务,以便您可以找出他们哪里做错了。一旦您发现他们的错误,就更容易调整您的指示以防止错误再次发生。
回到 Agent,我们最终得到的 UX 是用户可以清楚地看到 Agent 正在逐步做什么,以分析其决策过程,并弄清楚他们需要提供哪些额外的指导。
o1-preview 是一个可靠的模型,但速度非常慢
尽管 OpenAI 的 o1-preview 模型速度较慢,但它比我们实验过的其他用于计划制定的模型更进一步。它倾向于冗长,但这种冗长通常是有价值的内容,而不仅仅是填充物或样板文件。它始终如一地返回我们(尚未)无法使用其他模型重现的结果,但等待时间非常痛苦。我们能够通过 UX 改进来解决速度慢的问题,但随着我们扩展这个系统,o1 可能会成为瓶颈。
授权最终用户进行实验
我们看到用户在使用 LLM 驱动的功能时面临的最大挑战是弄清楚如何迭代。许多用户很少接触 LLM 或提示策略。作为用户,如果我点击“生成”,但结果只是部分正确,那么我下一步该怎么办?我如何以一种在已经正确的示例中取得进展而不会退步的方式进行迭代?
我们认为 UX 和 LLM 的结合正处于颠覆的风口浪尖。虽然我们对迄今为止开发的 UI 感到兴奋,但让用户更容易实验和纠正 Agent 的错误将是我们未来最大的关注点之一。