
编者按:这篇文章由 Voyage AI 团队撰写。
这篇文章证明了嵌入模型的选择显著影响了基于 检索增强生成 (RAG) 的聊天机器人的整体质量。我们专注于 Chat LangChain 的案例,这是一款 LangChain 聊天机器人,用于回答关于 LangChain 文档的问题,目前在生产中使用微调的 Voyage 嵌入。最后,我们将展示如何通过 LangChain 访问通用的 Voyage 嵌入模型。
RAG、检索系统和嵌入的简要背景
检索增强生成,通常称为 RAG,是聊天机器人的强大设计模式,其中检索系统实时获取与查询相关的已验证来源/文档,并将它们输入到生成模型(例如 GPT-4)以生成响应。凭借高质量的检索数据,RAG 可以确保生成的响应不仅智能,而且在上下文中准确且信息灵通。
现代检索系统通过使用数据密集向量表示的语义搜索得到增强。嵌入模型,即神经网络模型,将查询和文档转换为向量,这些向量称为嵌入。然后,检索其嵌入与查询嵌入最接近的文档。因此,检索的质量完全取决于数据如何表示为向量;反之亦然,嵌入模型的有效性是根据它们在检索相关信息方面的准确性来评估的。
请查看这篇 RAG 介绍性文章以了解更多详情。

评估嵌入在 RAG 堆栈中的影响
方法论。 RAG 有两个主要的人工智能组件:嵌入模型和生成模型。我们通过保持生成模型组件为最先进的模型 GPT-4 来消融嵌入模型的影响。我们衡量两个指标:(1)检索质量,这是对嵌入模型的模块化评估;(2)RAG 响应的端到端质量。我们将展示检索质量直接影响端到端响应质量。
评估场景。 在这篇文章中,我们专注于 Chat LangChain 机器人回答关于 LangChain 文档的问题的场景。这个 开源 聊天机器人使用 RAG 堆栈,其中包含直接来自 LangChain 文档的 6,522 份文档。通过与 LangChain 的合作,我们获得了 50 对查询和相应的黄金标准答案的集合,这是评估响应质量的主要数据集。
模型。 我们考虑了三个嵌入模型:OpenAI 行业领先的嵌入模型 text-embedding-ada-002,Voyage 的通用模型 voyage-01,以及在 LangChain 文档上微调的增强版本 voyage-langchain-01。
衡量响应质量。 为了评估响应的质量,我们通过要求 GPT-4 评估与黄金标准答案的相似性(评分范围为 10 分),来比较生成响应与黄金标准响应之间的语义相似性。1 分表示生成的答案不正确,并且与黄金标准答案无关,而 10 分表示与黄金标准答案完全一致。
衡量检索质量。 对于 50 个查询,我们手动策划了与查询最相关的黄金标准文档。我们为每个查询检索 10 个文档,并使用标准的 NDCG@10 指标来计算检索到的文档与黄金标准文档的相关性。
结果。 下表显示,在检索质量和响应质量方面,voyage-01 都超过了 OpenAI 的 text-embedding-ada-002。此外,专门在 LangChain 文档上微调的 voyage-langchain-01 具有最高的检索和响应质量。数据表明,最终响应的质量确实与检索质量高度相关,并且 voyage-01 和 voyage-langchain-01 通过提高检索质量来提高最终响应的质量。
| 模型名称 | 响应质量 (1-10) ↑ | 检索质量 ↑ |
|---|---|---|
Voyage (voyage-langchain-01) | 6.25 | 52.40 |
Voyage ( | 5.08 | 47.55 |
OpenAI (text-embedding-ada-002) | 4.34 | 45.81 |
演示示例
我们通过展示一些直观的例子来支持上述定量结果,在这些例子中,使用 Voyage 嵌入进行更准确的检索能够实现更准确的响应。
示例 1:voyage-01 vs text-embedding-ada-002
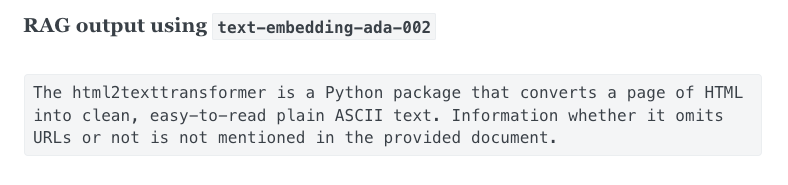
查询:“什么是 html2texttransformer?它会省略 url 吗?”
给定上述查询,voyage-01(左)获取了正确的文档,即 html2texttransformer 函数的详细描述,而 text-embedding-ada-002(右)检索到的文档相关性较低,即包含 html2texttransformer 作为方法的 html2text 的文档。后一个文档确实包含字符串 html2texttransformer,但仅在示例代码块中。


左:voyage-01 检索到的 Top-1 文档。右:text-embedding-ada-002 检索到的 Top-1 文档。
因此,使用 voyage-01 (左) 的 RAG 生成的响应是准确的,而使用 text-embedding-ada-002 (右) 的响应则将 html2texttransformer 与包含它的类混淆了。

示例 2:voyage-01 vs voyage-langchain-01
微调模型 voyage-langchain-01 比 voyage-01 具有更高的检索质量和响应质量。下面的示例演示了给定以下查询,voyage-langchain-01 如何获取具有更相关信息的文档。
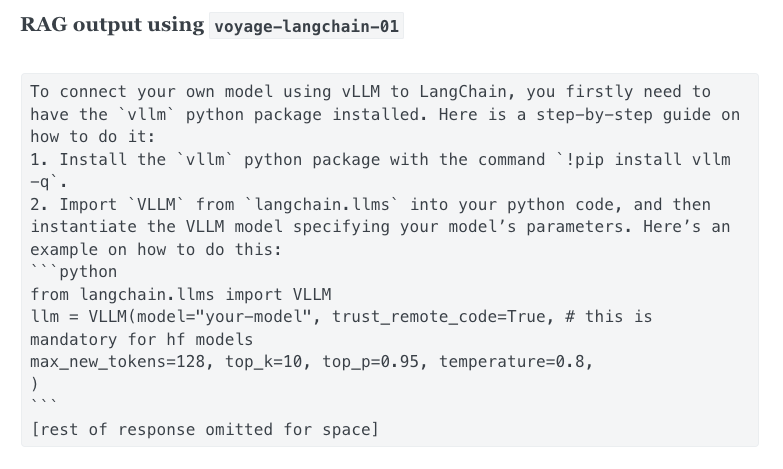
查询:“我正在使用 vLLM 运行自己的模型。如何将其连接到 LangChain?”
正如我们在下面看到的,voyage-01(左)没有提供与 vLLM 相关的文档,而 voyage-langchain-01(右)检索到了正确的文档。这里的原因是 vLLM 是一个高度专业的概念,通用嵌入模型很难掌握;但是微调模型已经看过 LangChain 文档,因此可以跟上术语和概念。

左:voyage-01 检索到的 Top-1 文档。右:voyage-langchain-01 检索到的 Top-1 文档。
毫不奇怪,使用 voyage-langchain-01(右)的 RAG 准确地回答了问题。另一方面,在没有检索到正确文档的情况下,使用 voyage-01(左)的 RAG 产生了幻觉答案。

在 LangChain 中使用 Voyage
从 langchain >= 0.0.327 开始,Voyage 已集成到 LangChain Python 包中,允许任何人访问 voyage-01 模型以用于自己的应用程序。
您可以 在此处 获取 Voyage API 密钥,该密钥应设置为环境变量
export VOYAGE_API_KEY="..."安装最新版本的 LangChain
pip install -U langchain然后您可以开始使用 VoyageEmbeddings。这是一个如何使用 Voyage 为 KNN 检索提供支持的简单示例
from langchain.embeddings import VoyageEmbeddings
from langchain.retrievers import KNNRetriever
texts = [
"Caching embeddings enables the storage or temporary caching of embeddings, eliminating the necessity to recompute them each time.",
"The agent executor is the runtime for an agent. This is what actually calls the agent and executes the actions it chooses",
"A Runnable represents a generic unit of work that can be invoked, batched, streamed, and/or transformed."
]
embeddings = VoyageEmbeddings(model="voyage-01", batch_size=8)
retriever = KNNRetriever.from_texts(texts, embeddings, k=1)
result = retriever.get_relevant_documents(
"How do I build an agent?"
)
print(result[0].page_content)The agent executor is the runtime for an agent. This is what actually calls the agent and executes the actions it chooses
您可以在 LangChain 集成文档此处 和 Voyage 文档此处 找到完整信息。
要点
嵌入模型的检索质量与最终响应的质量高度相关——为了使您的 RAG 更加成功,您应该考虑改进您的嵌入!尝试 Voyage 嵌入 voyage-01,或联系我们获取早期访问微调模型的权限,邮箱:contact@voyageai.com。在 Twitter 和/或 LinkedIn 上关注我们,获取更多更新!