
更新:一些读者指出,“认知架构”一词在神经科学和计算认知科学中有着丰富的历史。根据维基百科,“认知架构”指的是关于人类心智结构的理论,以及这种理论的计算实例化。该定义(以及关于该主题的相应研究和文章)比我在此尝试提供的任何定义都更全面,本博客应被解读为将我过去一年构建和帮助构建 LLM 驱动的应用程序的经验映射到这一研究领域。
在过去的六个月里,我经常使用(并且可能会更多地使用)一个短语“认知架构”。这个术语是我第一次从 Flo Crivello 那里听到的 - 提出这个词完全归功于他,我认为这是一个非常棒的术语。那么我说的到底是什么意思呢?
我所说的认知架构是指你的系统如何思考——换句话说,就是代码/提示/LLM 调用的流程,它接收用户输入并执行操作或生成响应。
我喜欢“认知”这个词,因为代理系统依赖于使用 LLM 来推理要做什么。
我喜欢“架构”这个词,因为这些代理系统仍然涉及大量的工程,类似于传统的系统架构。
将自主性水平映射到认知架构
如果我们回顾一下这张幻灯片(最初来自我的 TED 演讲)关于 LLM 应用程序中不同自主性水平的内容,我们可以看到不同认知架构的示例。
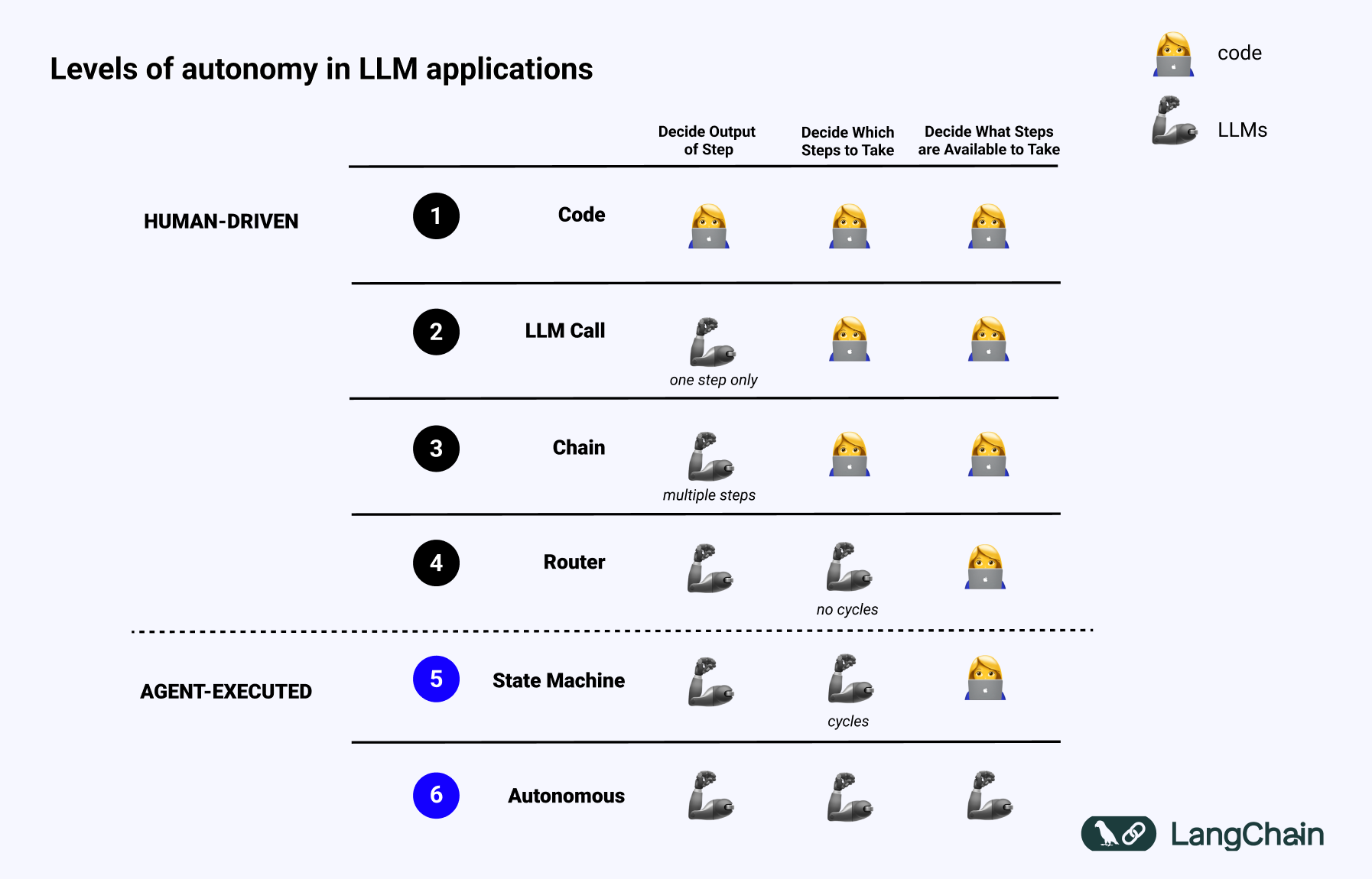
首先只是代码 - 一切都是硬编码的。甚至不能真正算作认知架构。
接下来只是一个 LLM 调用。之前和/或之后进行一些数据预处理,但单个 LLM 调用构成了应用程序的大部分。简单的聊天机器人可能属于这一类。
接下来是 LLM 调用链。这个序列可以是分解问题成不同的步骤,或者只是服务于不同的目的。更复杂的 RAG 管道属于这一类:使用第一个 LLM 调用生成搜索查询,然后使用第二个 LLM 调用生成答案。
在那之后,是一个路由器。在此之前,你提前知道应用程序将采取的所有步骤。现在,你不再知道了。LLM 决定采取哪些行动。这增加了一些随机性和不可预测性。
下一个级别是我称之为状态机的级别。这是将 LLM 进行一些路由与循环结合起来。这更加不可预测,因为通过将路由器与循环结合起来,系统(理论上)可以调用无限数量的 LLM 调用。
最终的自主性级别是我称之为代理的级别,或者更确切地说是一个“自主代理”。对于状态机,对于可以采取哪些操作以及采取该操作后执行哪些流程仍然存在约束。对于自主代理,这些护栏被移除。系统本身开始决定哪些步骤是可用的,以及指令是什么:这可以通过更新用于驱动系统的提示、工具或代码来完成。
选择认知架构
当我谈论“选择认知架构”时,我的意思是选择你想要采用的这些架构中的哪一个。这些架构都不是绝对“更好”的 - 它们都有各自针对不同任务的用途。
在构建 LLM 应用程序时,你可能会像尝试提示一样频繁地尝试不同的认知架构。我们正在构建 LangChain 和 LangGraph 以实现这一点。我们在过去一年中的大部分开发工作都投入到构建低级别、高度可控的编排框架(LCEL 和 LangGraph)中。
这与早期的 LangChain 有点不同,早期的 LangChain 专注于易于使用、开箱即用的链。这些对于入门非常棒,但很难自定义和实验。这在早期是可以接受的,因为每个人都只是想开始,但随着这个领域的成熟,这种设计很快就达到了它的极限。
我为我们在过去一年中所做的更改感到非常自豪,这些更改使 LangChain 和 LangGraph 更加灵活和可定制。如果你只使用过 LangChain 的高级封装器,请查看低级部分。它们更可定制,并且真的可以让你控制应用程序的认知架构。
如果你正在构建简单的链和检索流程,请查看 Python 中的 LangChain Python 和 JavaScript 中的 LangChain JavaScript。对于更复杂的代理工作流程,请尝试 Python 中的 LangGraph Python 和 JavaScript 中的 LangGraph JavaScript。